Caso você não tenha visto, acabamos de lançar o ClusterControl 1.7.5 com grandes melhorias e novos recursos úteis. Alguns dos recursos incluem Cluster Wide Maintenance, suporte para a versão CentOS 8 e Debian 10, suporte para PostgreSQL 12, suporte para MongoDB 4.2 e Percona MongoDB v4.0, bem como o novo MySQL Freeze Frame.
Espere, mas o que é um quadro congelado do MySQL? Isso é algo novo para o MySQL?
Bem, não é algo novo dentro do próprio Kernel do MySQL. É um novo recurso que adicionamos ao ClusterControl 1.7.5 que é específico para bancos de dados MySQL. O MySQL Freeze Frame no ClusterControl 1.7.5 cobrirá o seguinte:
- Instantâneo do status do MySQL antes da falha do cluster.
- Instantâneo da lista de processos do MySQL antes da falha do cluster (em breve).
- Inspecione incidentes de cluster em relatórios operacionais ou na ferramenta de linha de comando s9s.
Estes são conjuntos valiosos de informações que podem ajudar a rastrear bugs e corrigir seus clusters MySQL/MariaDB quando as coisas derem errado. No futuro, planejamos incluir também instantâneos dos valores de status do SHOW ENGINE InnoDB. Então, por favor, fique atento aos nossos futuros lançamentos.
Observe que esse recurso ainda está em estado beta, esperamos coletar mais conjuntos de dados à medida que trabalhamos com nossos usuários. Neste blog, mostraremos como aproveitar esse recurso, especialmente quando você precisar de mais informações ao diagnosticar seu cluster MySQL/MariaDB.
ClusterControl ao lidar com falha de cluster
Para falhas de cluster, o ClusterControl não faz nada, a menos que a Recuperação Automática (Cluster/Node) esteja habilitada como abaixo:

Uma vez ativado, o ClusterControl tentará recuperar um nó ou recuperar o cluster por trazendo toda a topologia do cluster.
Para MySQL, por exemplo em uma replicação mestre-escravo, ele deve ter pelo menos um mestre ativo a qualquer momento, independentemente do número de escravos disponíveis. O ClusterControl tenta corrigir a topologia pelo menos uma vez para clusters de replicação, mas fornece mais tentativas para replicação multimestre, como NDB Cluster e Galera Cluster. A recuperação de nó tenta recuperar um nó de banco de dados com falha, por exemplo, quando o processo foi encerrado (desligamento anormal) ou o processo sofreu um OOM (out-of-memory). O ClusterControl se conectará ao nó via SSH e tentará abrir o MySQL. Anteriormente, publicamos no blog sobre Como o ClusterControl executa recuperação automática de banco de dados e failover, então visite esse artigo para saber mais sobre o esquema de recuperação automática do ClusterControl.
Na versão anterior do ClusterControl <1.7.5, essas tentativas de recuperação disparavam alarmes. Mas uma coisa que nossos clientes perderam foi um relatório de incidente mais completo com informações de estado logo antes da falha do cluster. Até percebermos esse déficit e adicionarmos esse recurso no ClusterControl 1.7.5. Nós o chamamos de "MySQL Freeze Frame". O MySQL Freeze Frame, no momento da redação deste artigo, oferece um breve resumo dos incidentes que levaram a alterações de estado do cluster pouco antes do travamento. Mais importante, ele inclui no final do relatório a lista de hosts e suas variáveis e valores de Status Global do MySQL.
Como o MySQL Freeze Frame difere da recuperação automática?
O MySQL Freeze Frame não faz parte da recuperação automática do ClusterControl. Independentemente de a Recuperação Automática estar desabilitada ou habilitada, o MySQL Freeze Frame sempre fará seu trabalho enquanto uma falha de cluster ou nó for detectada.
Como funciona o MySQL Freeze Frame?
No ClusterControl, existem certos estados que classificamos como diferentes tipos de Status do Cluster. O MySQL Freeze Frame gerará um relatório de incidente quando esses dois estados forem acionados:
- CLUSTER_DEGRADED
- CLUSTER_FAILURE
No ClusterControl, um CLUSTER_DEGRADED é quando você pode gravar em um cluster, mas um ou mais nós estão inativos. Quando isso acontecer, o ClusterControl gerará o relatório de incidentes.
Para CLUSTER_FAILURE, embora sua nomenclatura se explique, é o estado em que seu cluster falha e não consegue mais processar leituras ou gravações. Então esse é um estado CLUSTER_FAILURE. Independentemente de um processo de recuperação automática estar tentando corrigir o problema ou estar desabilitado, o ClusterControl gerará o relatório de incidentes.
Como você habilita o MySQL Freeze Frame?
O MySQL Freeze Frame do ClusterControl é habilitado por padrão e só gera um relatório de incidente somente quando os estados CLUSTER_DEGRADED ou CLUSTER_FAILURE são acionados ou encontrados. Portanto, não há necessidade do usuário definir qualquer configuração do ClusterControl, o ClusterControl fará isso por você automaticamente.
Localizando o relatório de incidentes do MySQL Freeze Frame
No momento em que este artigo foi escrito, existem 4 maneiras de localizar o relatório de incidente. Estes podem ser encontrados fazendo as seguintes seções abaixo.
Usando a guia Relatórios operacionais
Os Relatórios Operacionais das versões anteriores são usados apenas para criar, agendar ou listar os relatórios operacionais gerados pelos usuários. Desde a versão 1.7.5, incluímos o relatório de incidente gerado pelo nosso recurso MySQL Freeze Frame. Veja o exemplo abaixo:
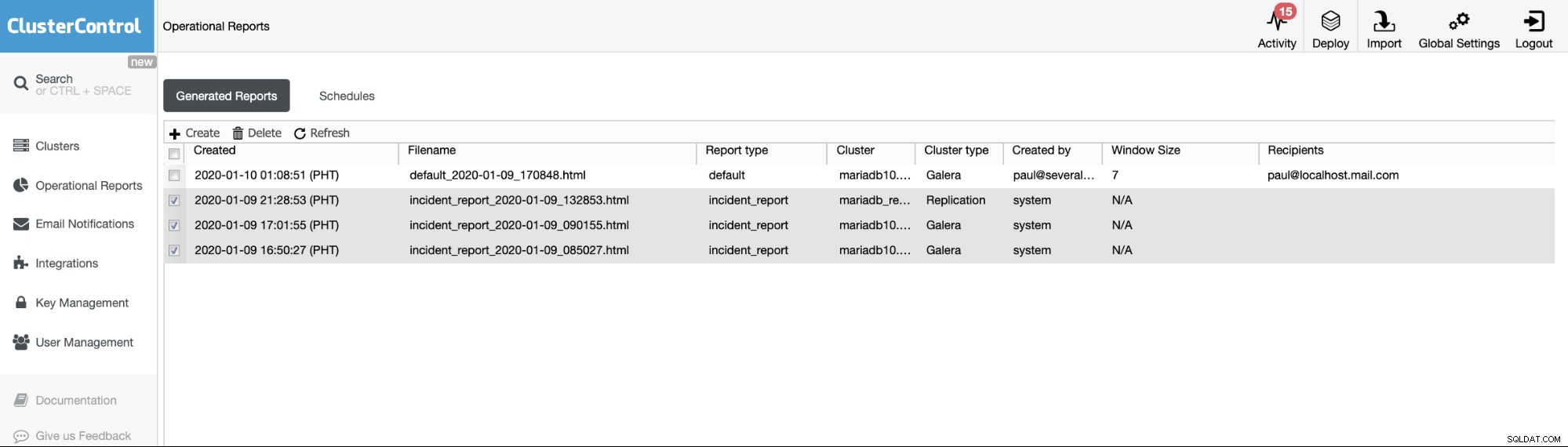
Os itens verificados ou itens com tipo de relatório ==incident_report, são o incidente relatórios gerados pelo recurso MySQL Freeze Frame no ClusterControl.
Usando relatórios de erros
Selecionando o cluster e gerando um relatório de erros, ou seja, passando por este processo: Em um relatório de incidente gerado, ele inclui instruções ou dicas sobre como você pode usar isso com o comando s9s CLI. Abaixo está o que é mostrado no relatório de incidentes: Dica! O uso da ferramenta s9s CLI permite que você facilmente grep dados neste relatório, por exemplo: Então, se você deseja localizar e gerar um relatório de erros, pode usar esta abordagem: Se eu quiser grep as variáveis wsrep_* em um host específico, posso fazer o seguinte: O ClusterControl gera esses relatórios de incidentes no host em que o ClusterControl é executado. O ClusterControl cria um diretório em /home/ ClusterControl não altera nem modifica nada em seus nós ou cluster do MySQL. O MySQL Freeze Frame apenas lerá SHOW GLOBAL STATUS (a partir deste momento) em intervalos específicos para salvar registros, pois não podemos prever o estado de um nó ou cluster MySQL quando ele pode travar ou quando pode ter problemas de hardware ou disco. Não é possível prever isso, então salvamos os valores e, portanto, podemos gerar um relatório de incidentes caso um determinado nó fique inativo. Nesse caso, o perigo de ter isso é quase nenhum. Ele teoricamente pode adicionar uma série de solicitações de clientes ao(s) servidor(es) caso alguns bloqueios sejam mantidos no MySQL, mas ainda não notamos isso. A série de testes não mostra isso, então ficaríamos felizes se você pudesse deixar ou registre um ticket de suporte caso surjam problemas. Existem certas situações em que um relatório de incidente pode não conseguir reunir variáveis de status globais se um problema de rede for o problema antes do ClusterControl congelar um quadro específico para coletar dados. Isso é completamente razoável porque não há como o ClusterControl coletar dados para diagnóstico adicional, pois não há conexão com o nó em primeiro lugar. Por último, você pode se perguntar por que nem todas as variáveis são mostradas na seção GLOBAL STATUS? Por enquanto, definimos um filtro em que valores vazios ou 0 são excluídos no relatório de incidentes. A razão é que queremos economizar algum espaço em disco. Quando esses relatórios de incidentes não forem mais necessários, você poderá excluí-los na guia Relatórios operacionais. Acreditamos que você está ansioso para experimentar este e ver como ele funciona. Mas, por favor, certifique-se de não estar executando ou testando isso em um ambiente ao vivo ou de produção. Abordaremos 2 fases do cenário no MySQL/MariaDB, uma para configuração mestre-escravo e outra para configuração do tipo Galera. Em uma configuração mestre-escravo, é fácil e simples de tentar. Certifique-se de ter desativado os modos de recuperação automática (cluster e nó), como abaixo: para que não tente corrigir o cenário de teste. Vá para seu nó mestre e tente configurar como somente leitura: Desta vez, um alarme foi acionado e, portanto, um relatório de incidente gerado. Veja abaixo como fica meu cluster: e o alarme foi acionado: e o relatório do incidente foi gerado: Para a configuração baseada no Galera, precisamos ter certeza de que o cluster não estará mais disponível, ou seja, uma falha em todo o cluster. Ao contrário do teste Master-Slave, você pode deixar o Auto Recovery ativado, pois vamos brincar com as interfaces de rede. Observação:para esta configuração, certifique-se de ter várias interfaces se estiver testando os nós em uma instância remota, pois não é possível ativar a interface ao desativar a interface em que você está conectado. Crie um cluster Galera de 3 nós (por exemplo, usando vagrant) Emita o comando (como abaixo) para simular o problema de rede e faça isso em todos os nós Agora, desativou meu cluster e ficou com este estado: acionou um alarme, e gera um relatório de incidente: Para um exemplo de relatório de incidente, você pode usar este arquivo bruto e salvá-lo como html. É bem simples tentar, mas, novamente, faça isso apenas em um ambiente não ativo e sem produção.
Usando a linha de comando s9s CLI
s9s report --list --long
s9s report --cat --report-id=N
[example@sqldat.com ~]$ s9s report --list --long --cluster-id=60
ID CID TYPE CREATED TITLE
19 60 incident_report 16:50:27 Incident Report - Cluster Failed
20 60 incident_report 17:01:55 Incident Report
[example@sqldat.com ~]$ s9s report --cat --report-id=20 --cluster-id=60|sed -n '/WSREP.*/p'|sed 's/ */ /g'|grep '192.168.10.80'|uniq -d
| WSREP_APPLIER_THREAD_COUNT | 4 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_CONF_ID | 18446744073709551615 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_SIZE | 1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_STATE_UUID | 7c7a9d08-2d72-11ea-9ef3-a2551fd9f58d | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_EVS_DELAYED | 27ac86a9-3254-11ea-b104-bb705eb13dde:tcp://192.168.10.100:4567:1,9234d567-3253-11ea-92d3-b643c178d325:tcp://192.168.10.90:4567:1,9234d567-3253-11ea-92d4-b643c178d325:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b25e-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b25f-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b260-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b261-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b262-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b263-cfcbda888ea9:tcp://192.168.10.90:4567:1,b0b7cb15-3241-11ea-bdbc-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbd-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbe-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbf-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdc0-1a21deddc100:tcp://192.168.10.100:4567:1,dea553aa-32b9-11ea-b321-9a836d562a47:tcp://192.168.10.100:4567:1,dea553aa-32b9-11ea-b322-9a836d562a47:tcp://192.168.10.100:4567:1,e27f4eff-3256-11ea-a3ab-e298880f3348:tcp://192.168.10.100:4567:1,e27f4eff-3256-11ea-a3ac-e298880f3348:tcp://192.168.10.100:4567:1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_GCOMM_UUID | 781facbc-3241-11ea-8a22-d74e5dcf7e08 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LAST_COMMITTED | 443 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_CACHED_DOWNTO | 98 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_RECV_QUEUE_MAX | 2 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_STATE_UUID | 7c7a9d08-2d72-11ea-9ef3-a2551fd9f58d | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_PROTOCOL_VERSION | 10 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_PROVIDER_VERSION | 26.4.3(r4535) | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_RECEIVED | 112 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_RECEIVED_BYTES | 14413 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPLICATED | 86 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPLICATED_BYTES | 40592 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_DATA_BYTES | 31734 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_KEYS | 86 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_KEYS_BYTES | 2752 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_ROLLBACKER_THREAD_COUNT | 1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_THREAD_COUNT | 5 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
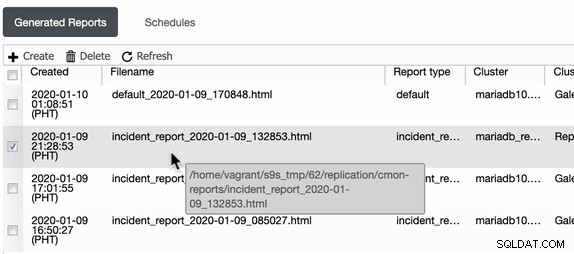
| WSREP_EVS_REPL_LATENCY | 4.508e-06/4.508e-06/4.508e-06/0/1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |Localização manual via caminho do arquivo do sistema
Existem perigos ou advertências ao usar o MySQL Freeze Frame?
Testando o recurso MySQL Freeze Frame
Cenário de teste de configuração mestre-escravo
Primeiro passo

Passo Dois
example@sqldat.com[mysql]> set @@global.read_only=1;
Query OK, 0 rows affected (0.000 sec)Passo Três



Cenário de teste de configuração de cluster do Galera
Primeiro passo
Passo Dois
[example@sqldat.com ~]# ifdown eth1
Device 'eth1' successfully disconnected.Etapa Três



Conclusão
MySQL Freeze Frame no ClusterControl pode ser útil ao diagnosticar travamentos. Ao solucionar problemas, você precisa de uma grande quantidade de informações para determinar a causa e é exatamente isso que o MySQL Freeze Frame fornece.



