A replicação mestre-escravo do MySQL é bastante fácil e direta de configurar. Esta é a principal razão pela qual as pessoas escolhem essa tecnologia como o primeiro passo para obter uma melhor disponibilidade do banco de dados. No entanto, tem o preço da complexidade no gerenciamento e manutenção; cabe ao administrador manter a integridade dos dados, especialmente durante failover, failback, manutenção, atualização e assim por diante.
Existem muitos artigos por aí descrevendo como executar a operação de failover para configuração de replicação. Também abordamos esse tópico nesta postagem do blog, Introdução ao Failover para Replicação do MySQL - o Blog 101. Nesta postagem do blog, abordaremos as tarefas pós-desastre ao restaurar para a topologia original - executando a operação de failback.
Por que precisamos de failback?
O líder de replicação (mestre) é o nó mais crítico em uma configuração de replicação. Ele requer boas especificações de hardware para garantir que possa processar gravações, gerar eventos de replicação, processar leituras críticas e assim por diante de maneira estável. Quando o failover é necessário durante a recuperação de desastres ou manutenção, pode não ser incomum nos encontrarmos promovendo um novo líder com hardware inferior. Essa situação pode ficar bem temporariamente, no entanto, por um longo período, o mestre designado deve ser trazido de volta para liderar a replicação depois que for considerado íntegro.
Ao contrário do failover, a operação de failback geralmente acontece em um ambiente controlado por meio de alternância, raramente acontece no modo de pânico. Isso dá à equipe de operação algum tempo para planejar cuidadosamente e ensaiar o exercício para uma transição suave. O objetivo principal é simplesmente trazer de volta o bom e velho mestre ao estado mais recente e restaurar a configuração de replicação para sua topologia original. No entanto, há alguns casos em que o failback é crítico, por exemplo, quando o mestre recém-promovido não funcionou conforme o esperado e afetando o serviço geral do banco de dados.
Como realizar o failback com segurança?
Após o failover, o antigo mestre estaria fora da cadeia de replicação para manutenção ou recuperação. Para realizar a transição, deve-se fazer o seguinte:
- Provisione o antigo mestre para o estado correto, tornando-o o escravo mais atualizado.
- Pare o aplicativo.
- Verifique se todos os escravos foram capturados.
- Promova o antigo mestre como o novo líder.
- Reencaminhe todos os escravos para o novo mestre.
- Inicie o aplicativo escrevendo para o novo mestre.
Considere a seguinte configuração de replicação:
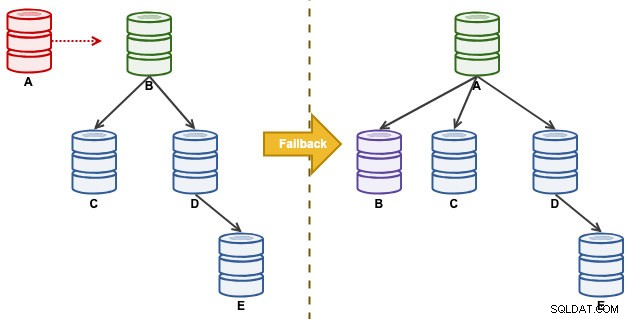
"A" era um mestre até um evento de disco cheio causando estragos na cadeia de replicação. Após um evento de failover, nossa topologia de replicação foi liderada por B e replicada em C até E. O exercício de failback trará de volta A como líder e restaurará a topologia original antes do desastre. Observe que todos os nós estão sendo executados no MySQL 8.0.15 com GTID ativado. Uma versão principal diferente pode usar comandos e etapas diferentes.
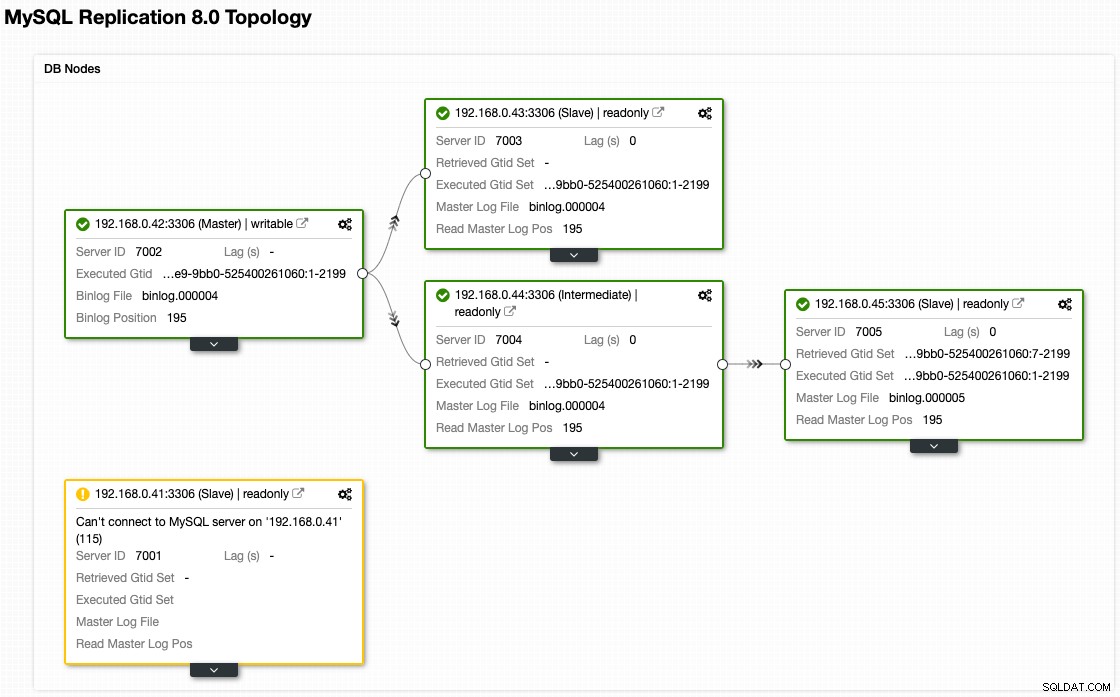
Embora seja assim que nossa arquitetura se parece agora após o failover (retirado da visualização de topologia do ClusterControl):
Aprovisionamento de nós
Antes que A possa ser um mestre, ele deve ser atualizado com o estado atual do banco de dados. A melhor maneira de fazer isso é transformar A como escravo para o mestre ativo, B. Como todos os nós são configurados com log_slave_updates=ON (significa que um escravo também produz logs binários), podemos escolher outros escravos como C e D como a fonte da verdade para a sincronização inicial. No entanto, quanto mais próximo do mestre ativo, melhor. Lembre-se da carga adicional que isso pode causar ao fazer o backup. Esta parte leva a maior parte das horas de failback. Dependendo do estado do nó e do tamanho do conjunto de dados, a sincronização do mestre antigo pode levar algum tempo (pode levar horas e dias).
Uma vez que o problema em "A" esteja resolvido e pronto para ingressar na cadeia de replicação, o melhor primeiro passo é tentar replicar de "B" (192.168.0.42) com a instrução CHANGE MASTER:
mysql> SET GLOBAL read_only = 1; /* enable read-only */
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.42', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1; /* master information to connect */
mysql> START SLAVE; /* start replication */
mysql> SHOW SLAVE STATUS\G /* check replication status */Se a replicação funcionar, você deverá ver o seguinte no status da replicação:
Slave_IO_Running: Yes
Slave_SQL_Running: YesSe a replicação falhar, observe o Last_IO_Error ou Last_SQL_Error da saída de status do escravo. Por exemplo, se você vir o seguinte erro:
Last_IO_Error: error connecting to master 'example@sqldat.com:3306' - retry-time: 60 retries: 2Então, temos que criar o usuário de replicação no mestre ativo atual, B:
mysql> CREATE USER example@sqldat.com IDENTIFIED BY 'p4ss';
mysql> GRANT REPLICATION SLAVE ON *.* TO example@sqldat.com;Em seguida, reinicie o escravo em A para iniciar a replicação novamente:
mysql> STOP SLAVE;
mysql> START SLAVE;Outro erro comum que você veria é esta linha:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: ...Isso provavelmente significa que o escravo está tendo problemas para ler o arquivo de log binário do mestre atual. Em algumas ocasiões, o escravo pode estar muito atrasado, pois os eventos binários necessários para iniciar a replicação estão ausentes do mestre atual ou o binário no mestre foi eliminado durante o failover e assim por diante. Nesse caso, a melhor maneira é realizar uma sincronização completa fazendo um backup completo em B e restaurando-o em A. Em B, você pode usar mysqldump ou Percona Xtrabackup para fazer um backup completo:
$ mysqldump -uroot -p --all-databases --single-transaction --triggers --routines > dump.sql # for mysqldump
$ xtrabackup --defaults-file=/etc/my.cnf --backup --parallel 1 --stream=xbstream --no-timestamp | gzip -6 - > backup-full-2019-04-16_071649.xbstream.gz # for xtrabackupTransfira o arquivo de backup para A, reinicialize a instalação existente do MySQL para uma limpeza adequada e execute a restauração do banco de dados:
$ systemctl stop mysqld # if mysql is still running
$ rm -Rf /var/lib/mysql # wipe out old data
$ mysqld --initialize --user=mysql # initialize database
$ systemctl start mysqld # start mysql
$ grep -i 'temporary password' /var/log/mysql/mysqld.log # retrieve the temporary root password
$ mysql -uroot -p -e 'ALTER USER example@sqldat.com IDENTIFIED BY "p455word"' # mandatory root password update
$ mysql -uroot -p < dump.sql # restore the backup using the new root passwordUma vez restaurado, configure o link de replicação para o mestre ativo B (192.168.0.42) e ative somente leitura. Em A, execute as seguintes instruções:
mysql> SET GLOBAL read_only = 1; /* enable read-only */
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.42', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1; /* master information to connect */
mysql> START SLAVE; /* start replication */
mysql> SHOW SLAVE STATUS\G /* check replication status */Para o Percona Xtrabackup, consulte a página de documentação sobre como restaurar para A. Ela envolve uma etapa de pré-requisito para preparar o backup antes de substituir o diretório de dados do MySQL.
Uma vez que A começou a replicar corretamente, monitore o Seconds_Behind_Master no status do escravo. Isso lhe dará uma ideia de quanto o escravo deixou para trás e quanto tempo você precisa esperar antes de alcançá-lo. Neste ponto, nossa arquitetura está assim:
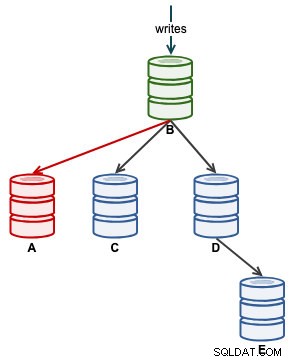
Uma vez que Seconds_Behind_Master volta a 0, esse é o momento em que A alcança como um escravo atualizado.
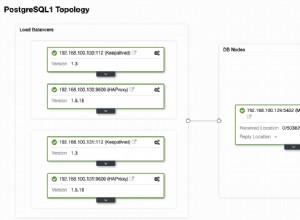
Se estiver usando o ClusterControl, você tem a opção de ressincronizar o nó restaurando a partir de um backup existente ou criar e transmitir o backup diretamente do nó mestre ativo:
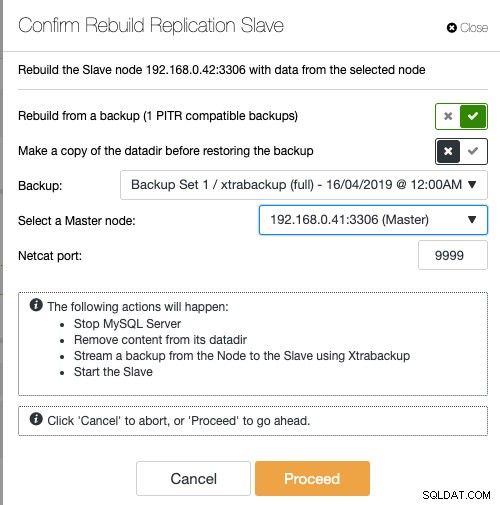
Staging o slave com backup existente é a forma recomendada de se fazer para construir o slave, pois não traz nenhum impacto no servidor master ativo na hora de preparar o nó.
Promova o Velho Mestre
Antes de promover A como o novo mestre, a maneira mais segura é interromper todas as operações de gravação em B. Se isso não for possível, basta forçar B a operar em modo somente leitura:
mysql> SET GLOBAL read_only = 'ON';
mysql> SET GLOBAL super_read_only = 'ON';Em seguida, em A, execute SHOW SLAVE STATUS e verifique o seguinte status de replicação:
Read_Master_Log_Pos: 45889974
Exec_Master_Log_Pos: 45889974
Seconds_Behind_Master: 0
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updatesO valor de Read_Master_Log_Pos e Exec_Master_Log_Pos deve ser idêntico, enquanto Seconds_Behind_Master é 0 e o estado deve ser 'Slave has read all relay log'. Certifique-se de que todos os escravos tenham processado alguma instrução em seu log de retransmissão, caso contrário você correrá o risco de que as novas consultas afetem as transações do log de retransmissão, desencadeando todos os tipos de problemas (por exemplo, uma aplicação pode remover algumas linhas que são acessadas por transações do registro do relé).
Em A, pare a replicação e use a instrução RESET SLAVE ALL para remover todas as configurações relacionadas à replicação e desabilitar somente leitura:
mysql> STOP SLAVE;
mysql> RESET SLAVE ALL;
mysql> SET GLOBAL read_only = 'OFF';
mysql> SET GLOBAL super_read_only = 'OFF';Neste ponto, A está pronto para aceitar gravações (read_only=OFF), porém os escravos não estão conectados a ele, conforme ilustrado abaixo:
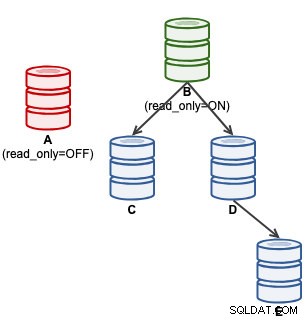
Para usuários do ClusterControl, a promoção de A pode ser feita usando o recurso "Promote Slave" em Node Actions. O ClusterControl rebaixará automaticamente o mestre ativo B, promoverá o escravo A como mestre e redirecionará C e D para replicar de A. B será colocado de lado e o usuário terá que escolher explicitamente "Alterar mestre de replicação" para se juntar a B replicando de A em um estágio posterior .
Reapontamento de escravos
Agora é seguro alterar o mestre em escravos relacionados para replicar de A (192.168.0.41). Em todos os escravos, exceto E, configure o seguinte:
mysql> STOP SLAVE;
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.41', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;Se você for um usuário do ClusterControl, ignore esta etapa, pois o redirecionamento está sendo executado automaticamente quando você decidiu promover A anteriormente.
Podemos então iniciar nosso aplicativo para escrever em A. Neste ponto, nossa arquitetura está parecida com isto:
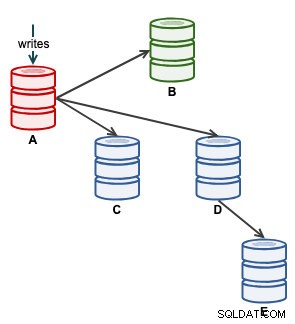
Na visualização de topologia do ClusterControl, restauramos nosso cluster de replicação para sua arquitetura original, que se parece com isso:
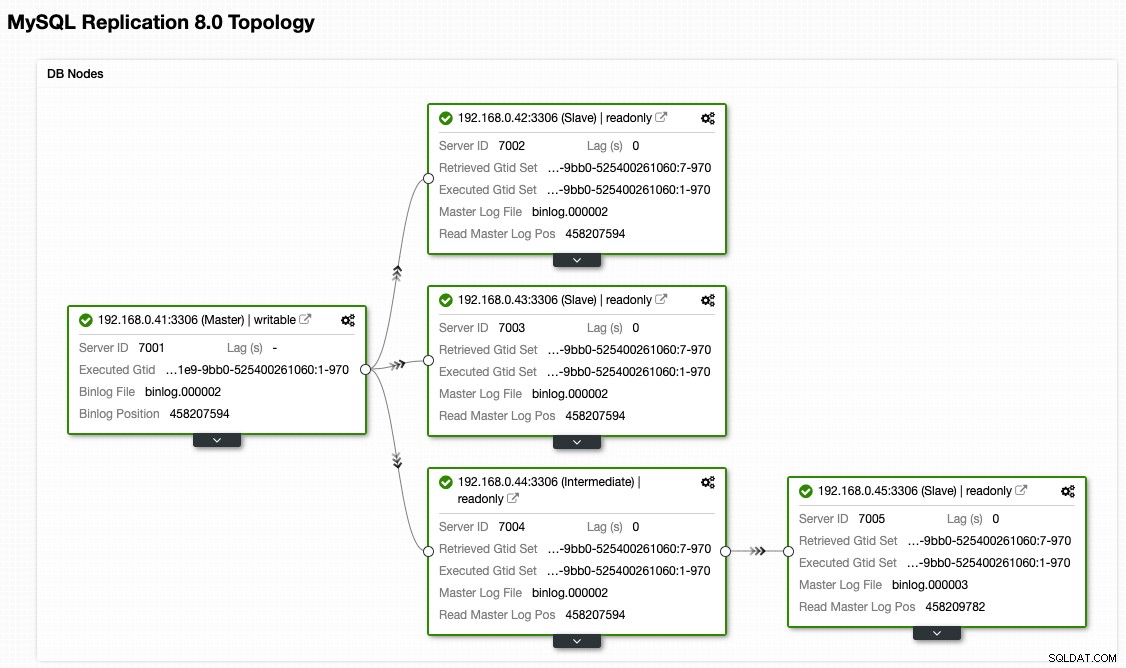
Observe que o exercício de failback é muito menos arriscado se comparado ao failover. É importante agendar este exercício fora do horário de pico para minimizar o impacto em seus negócios.
Considerações finais
A operação de failover e failback deve ser executada com cuidado. A operação é bastante simples se você tiver um pequeno número de nós, mas para vários nós com cadeia de replicação complexa, pode ser um exercício arriscado e propenso a erros. Também mostramos como o ClusterControl pode ser usado para simplificar operações complexas executando-as por meio da interface do usuário, além de a visualização da topologia ser visualizada em tempo real para que você entenda a topologia de replicação que deseja construir.