Na seção de comentários de um de nossos blogs um leitor perguntou sobre o impacto de wsrep_slave_threads no desempenho e escalabilidade de E/S do Galera Cluster. Naquela época, não conseguíamos responder facilmente a essa pergunta e fazer backup com mais dados, mas finalmente conseguimos configurar o ambiente e executar alguns testes.
Nosso leitor apontou para benchmarks que mostraram que o aumento de wsrep_slave_threads não teve nenhum impacto no desempenho do cluster Galera.
Para explicar qual é o impacto dessa configuração, configuramos um pequeno cluster de três nós (m5d.xlarge). Isso nos permitiu utilizar o SSD nvme conectado diretamente para o diretório de dados do MySQL. Ao fazer isso, minimizamos a chance de o armazenamento se tornar o gargalo em nossa configuração.
Configuramos o buffer pool do InnoDB para 8 GB e redo logs para dois arquivos, 1 GB cada. Também aumentamos innodb_io_capacity para 2000 e innodb_io_capacity_max para 10000. Isso também foi feito para garantir que nenhuma dessas configurações afetasse nosso desempenho.
Todo o problema com esses benchmarks é que existem tantos gargalos que você precisa eliminá-los um por um. Somente depois de fazer alguns ajustes de configuração e depois de ter certeza de que o hardware não será um problema, pode-se esperar que alguns limites mais sutis apareçam.
Geramos ~ 90 GB de dados usando o sysbench:
sysbench /usr/share/sysbench/oltp_write_only.lua --threads=16 --events=0 --time=600 --mysql-host=172.30.4.245 --mysql-user=sbtest --mysql-password=sbtest --mysql-port=3306 --tables=28 --report-interval=1 --skip-trx=off --table-size=10000000 --db-ps-mode=disable --mysql-db=sbtest_large prepareEm seguida, o benchmark foi executado. Testamos duas configurações:wsrep_slave_threads=1 e wsrep_slave_threads=16. O hardware não era poderoso o suficiente para se beneficiar de aumentar ainda mais essa variável. Lembre-se também de que não fizemos um benchmarking detalhado para determinar se wsrep_slave_threads deve ser definido como 16, 8 ou talvez 4 para obter o melhor desempenho. Estávamos interessados em ver se podemos mostrar um impacto no cluster. E sim, o impacto foi claramente visível. Para começar, alguns gráficos de controle de fluxo.
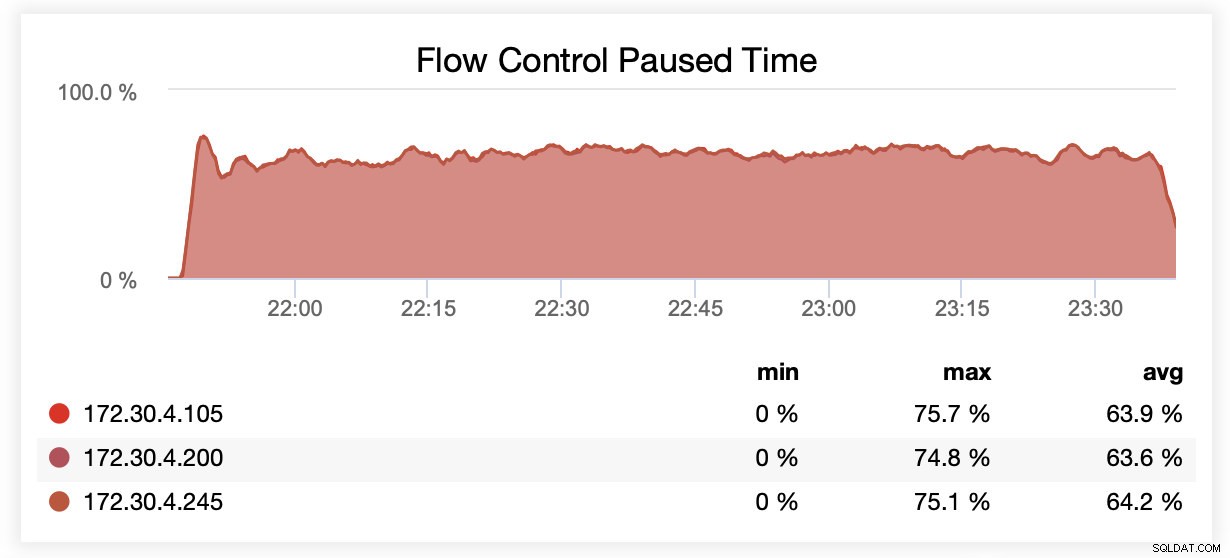
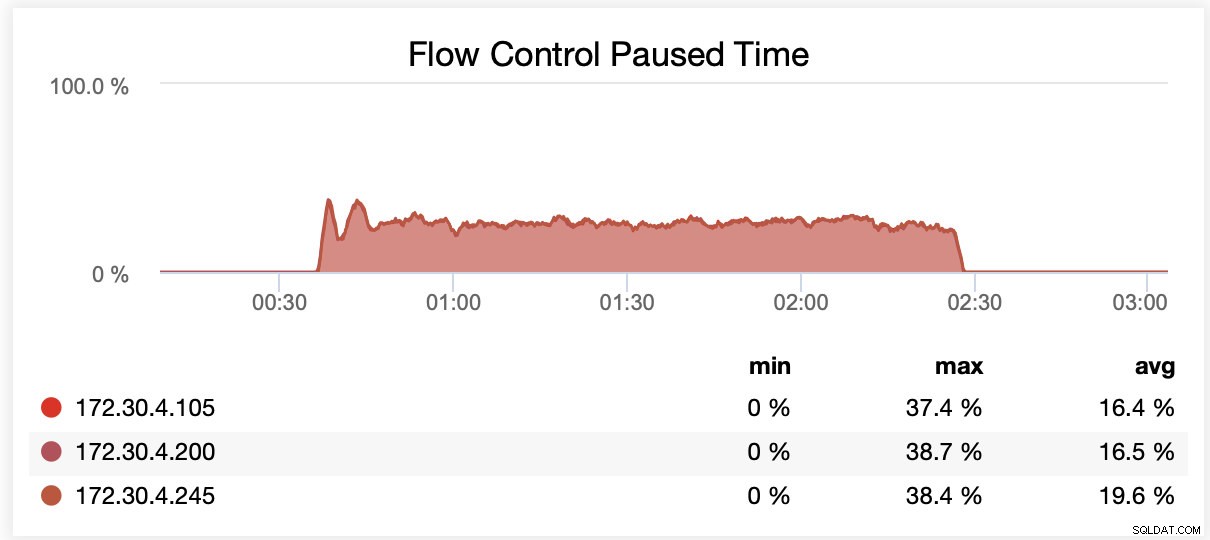
Durante a execução com wsrep_slave_threads=1, em média, os nós foram pausados devido ao controle de fluxo ~64% do tempo.
Durante a execução com wsrep_slave_threads=16, em média, os nós foram pausados devido ao controle de fluxo ~ 20% do tempo.
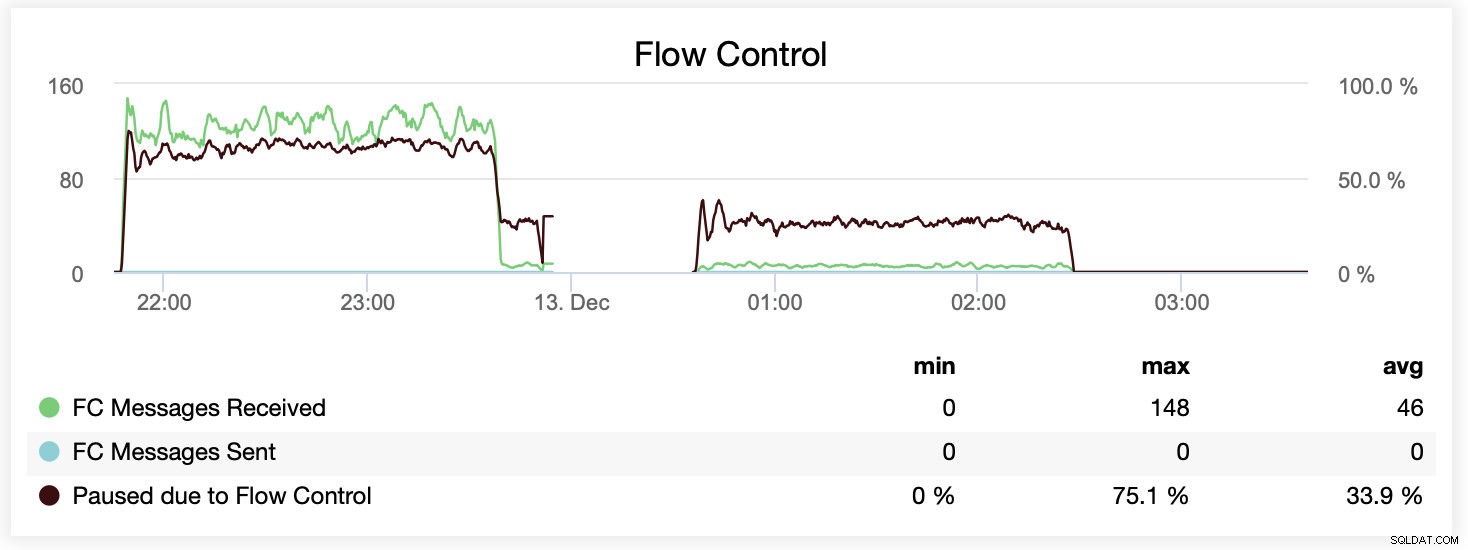
Você também pode comparar a diferença em um único gráfico. A queda no final da primeira parte é a primeira tentativa de execução com wsrep_slave_threads=16. Os servidores ficaram sem espaço em disco para logs binários e tivemos que executar novamente esse benchmark mais tarde.
Como isso se traduz em termos de desempenho? A diferença é visível, embora definitivamente não seja tão espetacular.
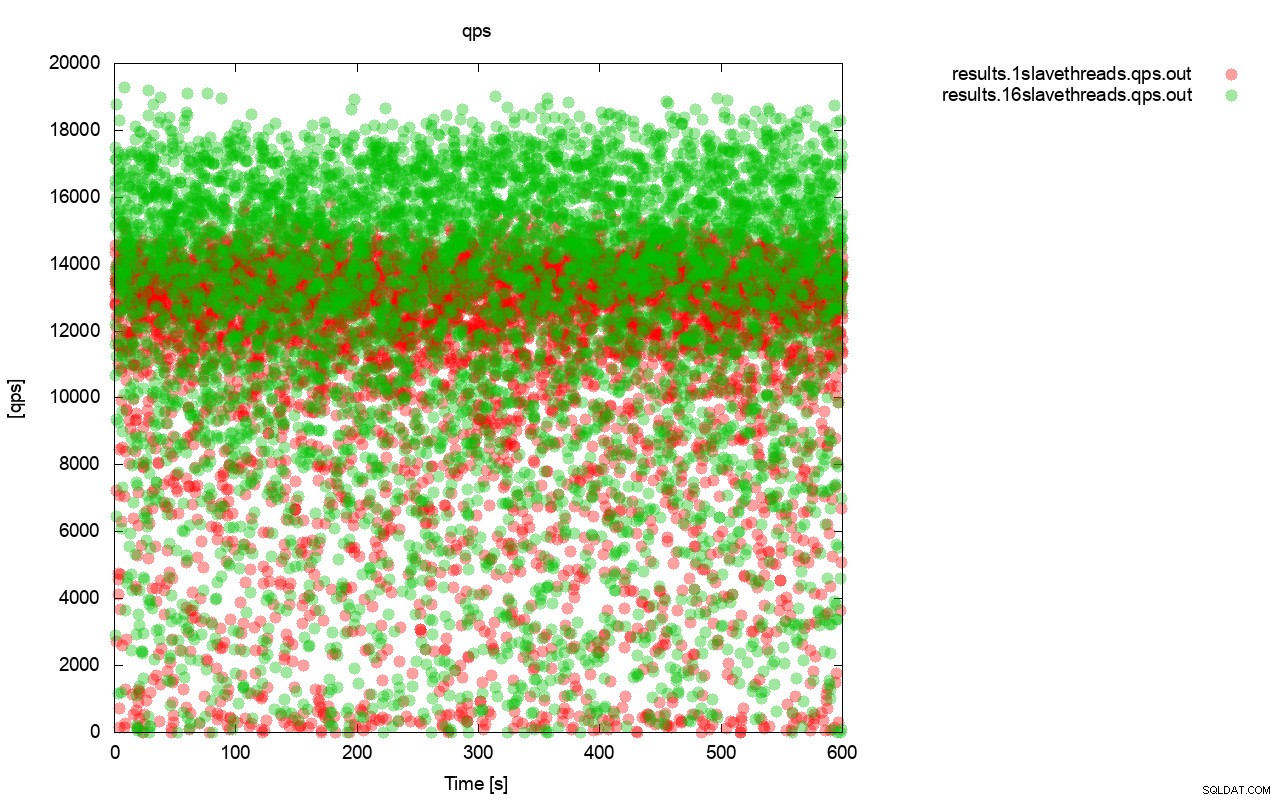
Primeiro, o gráfico de consulta por segundo. Em primeiro lugar, você pode notar que em ambos os casos os resultados estão por toda parte. Isso está relacionado principalmente ao desempenho instável do armazenamento de E/S e ao controle de fluxo acionado aleatoriamente. Você ainda pode ver que o desempenho do resultado “vermelho” (wsrep_slave_threads=1) é bem inferior ao do “verde” ( wsrep_slave_threads=16).
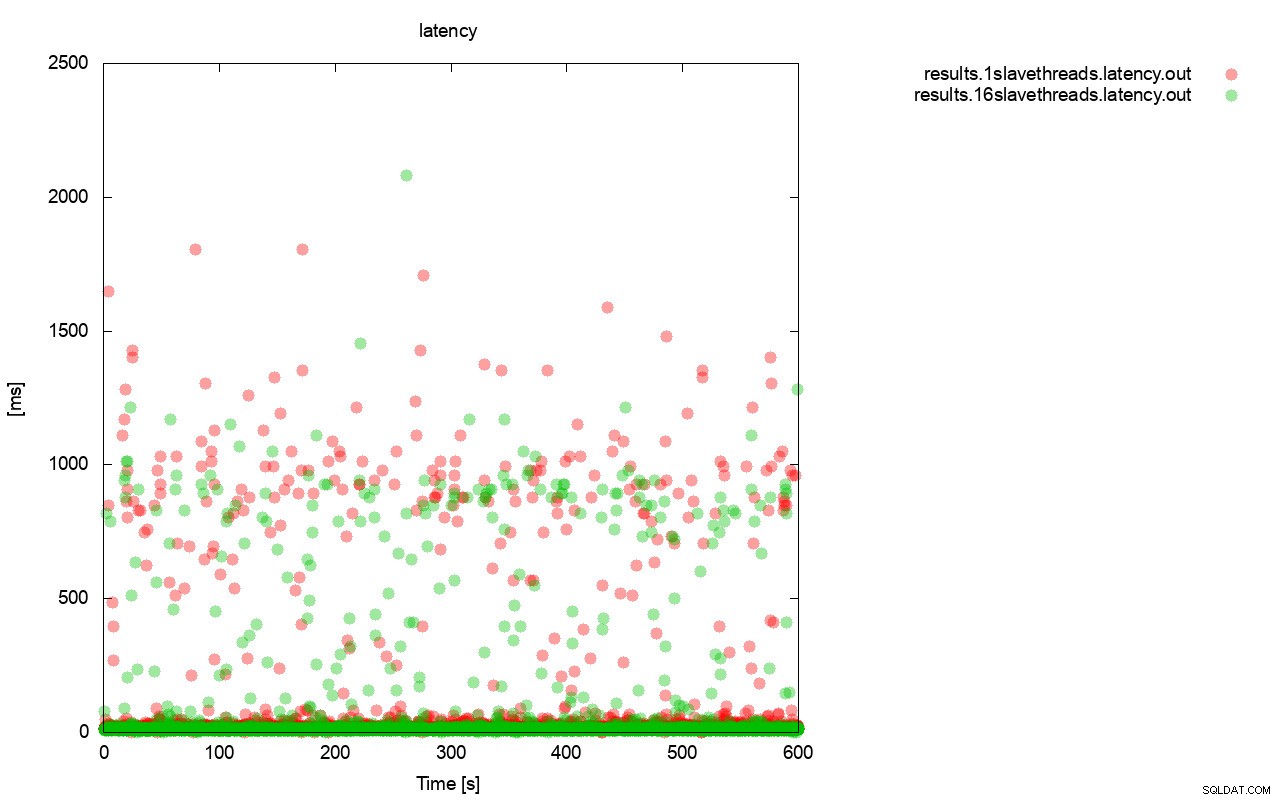
Imagem bastante semelhante é quando olhamos para a latência. Você pode ver mais paradas (e geralmente mais profundas) para a execução com wsrep_slave_thread=1.
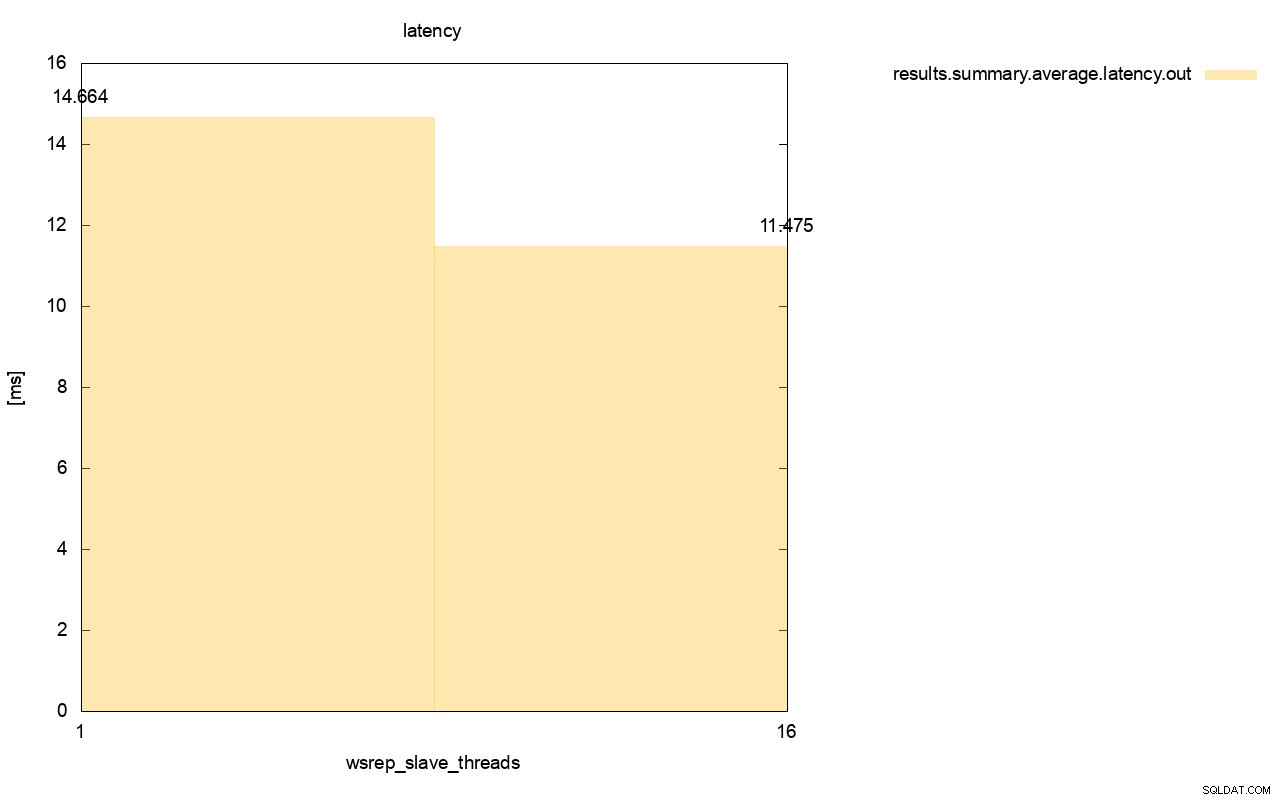
A diferença é ainda mais visível quando calculamos a latência média em todas as execuções e você pode ver que a latência de wsrep_slave_thread=1 é 27% maior que a latência com 16 encadeamentos escravos, o que obviamente não é bom, pois queremos que a latência seja menor , não superior.
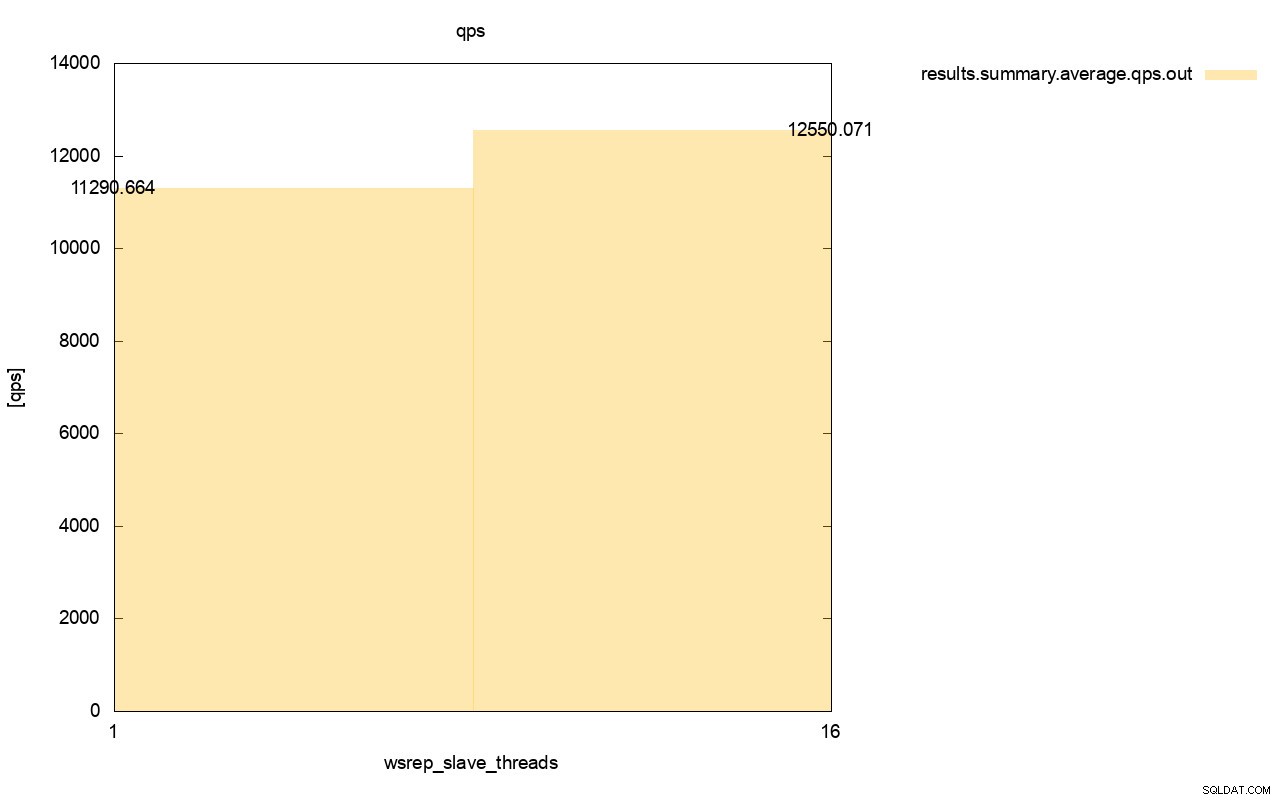
A diferença na taxa de transferência também é visível, cerca de 11% da melhoria quando adicionamos mais wsrep_slave_threads.
Como você pode ver, o impacto está lá. Não é de forma alguma 16x (mesmo que seja assim que aumentamos o número de threads escravos no Galera), mas é definitivamente proeminente o suficiente para que não possamos classificá-lo apenas como uma anomalia estatística.
Por favor, tenha em mente que no nosso caso nós usamos nós bem pequenos. A diferença deve ser ainda mais significativa se estivermos falando de grandes instâncias executadas em volumes EBS com milhares de IOPS provisionadas.
Então seríamos capazes de executar o sysbench de forma ainda mais agressiva, com maior número de operações simultâneas. Isso deve melhorar a paralelização dos conjuntos de gravação, melhorando ainda mais o ganho do multithreading. Além disso, hardware mais rápido significa que Galera poderá utilizar esses 16 threads de maneira mais eficiente.
Ao executar testes como este, você deve ter em mente que precisa levar sua configuração quase ao limite. A replicação single-thread pode lidar com uma grande quantidade de carga e você precisa executar tráfego pesado para realmente torná-la não eficiente o suficiente para lidar com a tarefa.
Esperamos que esta postagem do blog forneça mais informações sobre as habilidades do Galera Cluster para aplicar conjuntos de escrita em paralelo e os fatores limitantes em torno dele.