As consultas precisam ser armazenadas em cache em todos os bancos de dados muito carregados, simplesmente não há como um banco de dados lidar com todo o tráfego com desempenho razoável. Existem vários mecanismos nos quais um cache de consulta pode ser implementado. A partir do cache de consulta do MySQL, que costumava funcionar muito bem para cargas de trabalho de baixa simultaneidade e somente leitura e que não tem lugar em cargas de trabalho simultâneas altas (na medida em que a Oracle o removeu no MySQL 8.0), para armazenamentos externos de valores-chave como Redis, memcached ou CouchBase.
O principal problema com o uso de um armazenamento de dados dedicado externo (já que não recomendamos o uso do cache de consulta MySQL para ninguém) é que este é mais um armazenamento de dados para gerenciar. É mais um ambiente para manter, dimensionar problemas para lidar, bugs para depurar e assim por diante.
Então, por que não matar dois coelhos com uma cajadada só aproveitando seu proxy? A suposição aqui é que você está usando um proxy em seu ambiente de produção, pois ele ajuda a balancear a carga de consultas entre instâncias e mascara a topologia de banco de dados subjacente fornecendo um endpoint simples para aplicativos. O ProxySQL é uma ótima ferramenta para o trabalho, pois também pode funcionar como uma camada de cache. Nesta postagem do blog, mostraremos como armazenar em cache consultas no ProxySQL usando o ClusterControl.
Como funciona o cache de consulta no ProxySQL?
Em primeiro lugar, um pouco de fundo. O ProxySQL gerencia o tráfego por meio de regras de consulta e pode realizar o cache de consulta usando o mesmo mecanismo. O ProxySQL armazena consultas em cache em uma estrutura de memória. Os dados armazenados em cache são despejados usando a configuração de tempo de vida (TTL). O TTL pode ser definido para cada regra de consulta individualmente, portanto, cabe ao usuário decidir se as regras de consulta devem ser definidas para cada consulta individual, com TTL distinto ou se ele precisa apenas criar algumas regras que correspondam à maioria dos o transito.
Existem duas definições de configuração que definem como um cache de consulta deve ser usado. Primeiro, mysql-query_cache_size_MB que define um limite flexível no tamanho do cache de consulta. Não é um limite rígido, portanto, o ProxySQL pode usar um pouco mais de memória do que isso, mas é suficiente para manter a utilização de memória sob controle. A segunda configuração que você pode ajustar é mysql-query_cache_stores_empty_result . Ele define se um conjunto de resultados vazio é armazenado em cache ou não.
O cache de consulta ProxySQL foi projetado como um armazenamento de valor-chave. O valor é o conjunto de resultados de uma consulta e a chave é composta por valores concatenados como:usuário, esquema e texto da consulta. Em seguida, um hash é criado a partir dessa string e esse hash é usado como chave.
Configurando o ProxySQL como um cache de consulta usando o ClusterControl
Como configuração inicial, temos um cluster de replicação de um mestre e um escravo. Também temos um único ProxySQL.
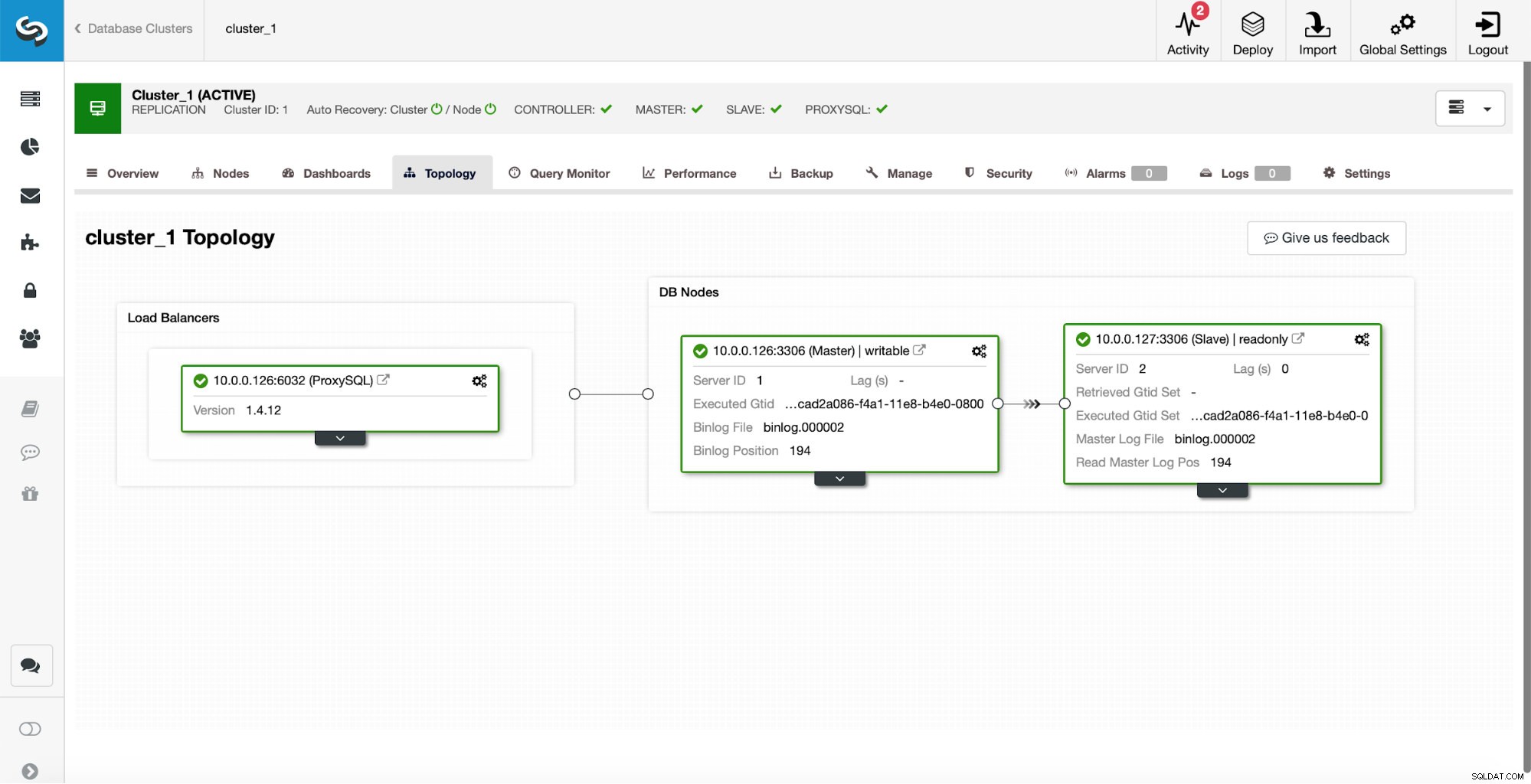
Esta não é de forma alguma uma configuração de nível de produção, pois teríamos que implementar algum tipo de alta disponibilidade para a camada de proxy (por exemplo, implantando mais de uma instância ProxySQL e, em seguida, mantendo-a ativa em cima delas para IP virtual flutuante), mas será mais do que suficiente para nossos testes.
Primeiro, vamos verificar a configuração do ProxySQL para garantir que as configurações do cache de consulta sejam o que queremos.
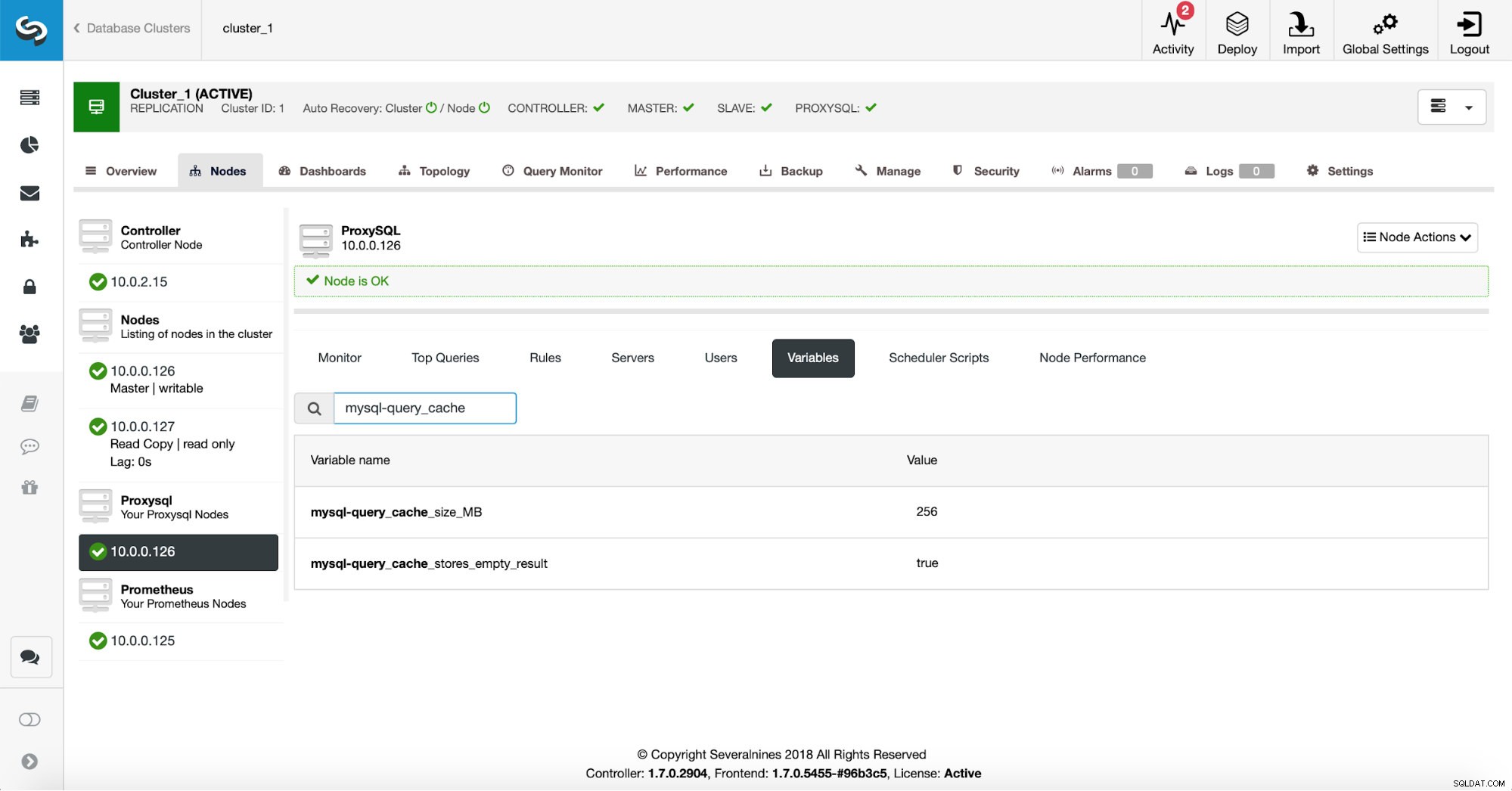
256 MB de cache de consulta devem estar corretos e queremos armazenar em cache também os conjuntos de resultados vazios - às vezes, uma consulta que não retorna dados ainda precisa fazer muito trabalho para verificar se não há nada para retornar.
A próxima etapa é criar regras de consulta que correspondam às consultas que você deseja armazenar em cache. Há duas maneiras de fazer isso no ClusterControl.
Adicionando regras de consulta manualmente
A primeira maneira requer um pouco mais de ações manuais. Usando o ClusterControl, você pode criar facilmente qualquer regra de consulta que desejar, incluindo regras de consulta que fazem o armazenamento em cache. Primeiro, vamos dar uma olhada na lista de regras:
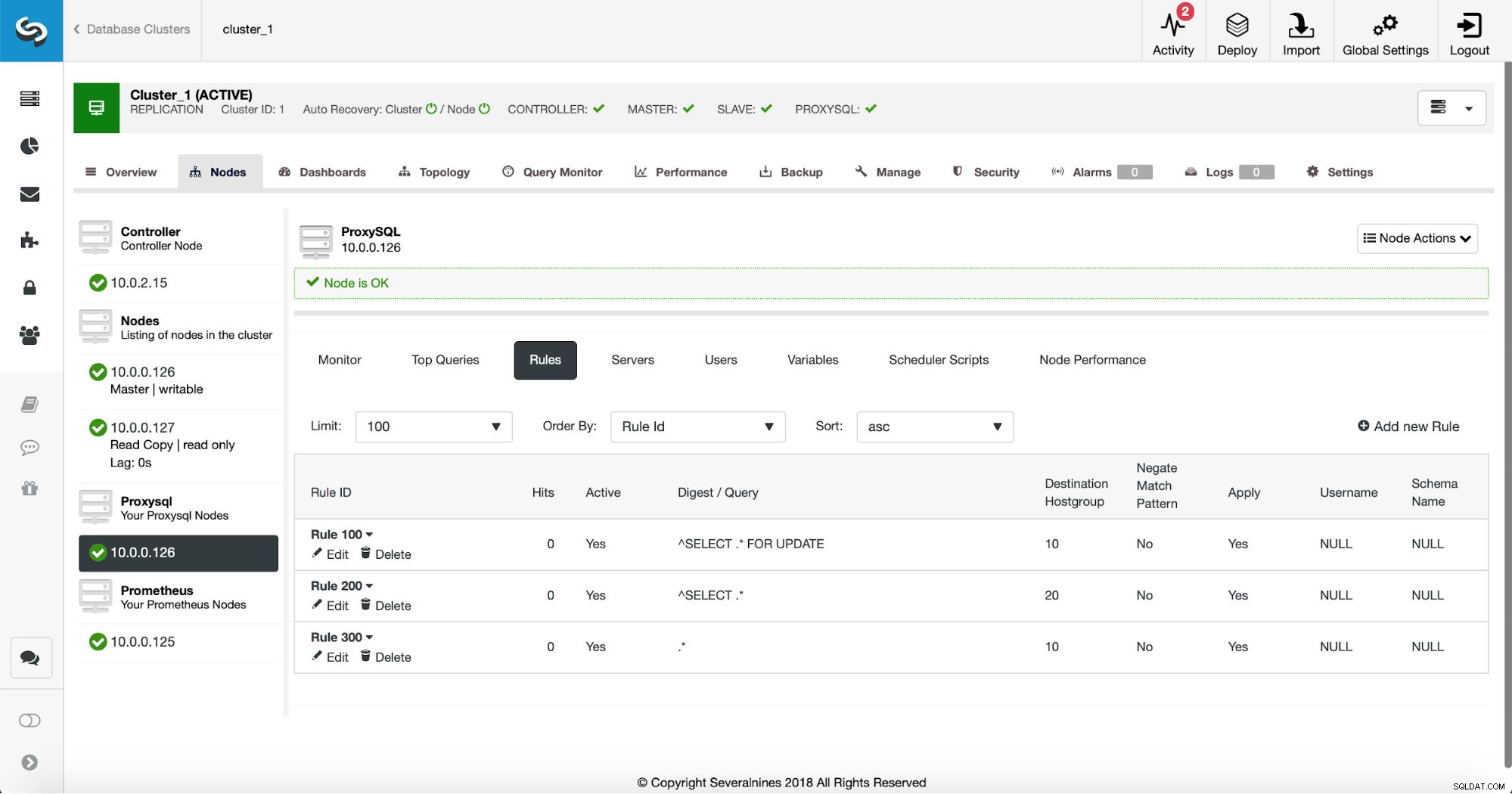
Neste ponto, temos um conjunto de regras de consulta para realizar a divisão de leitura/gravação. A primeira regra tem um ID de 100. Nossa nova regra de consulta deve ser processada antes dessa, então usaremos um ID de regra menor. Vamos criar uma regra de consulta que fará o cache de consultas semelhante a esta:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN 5041 AND 5140 ORDER BY c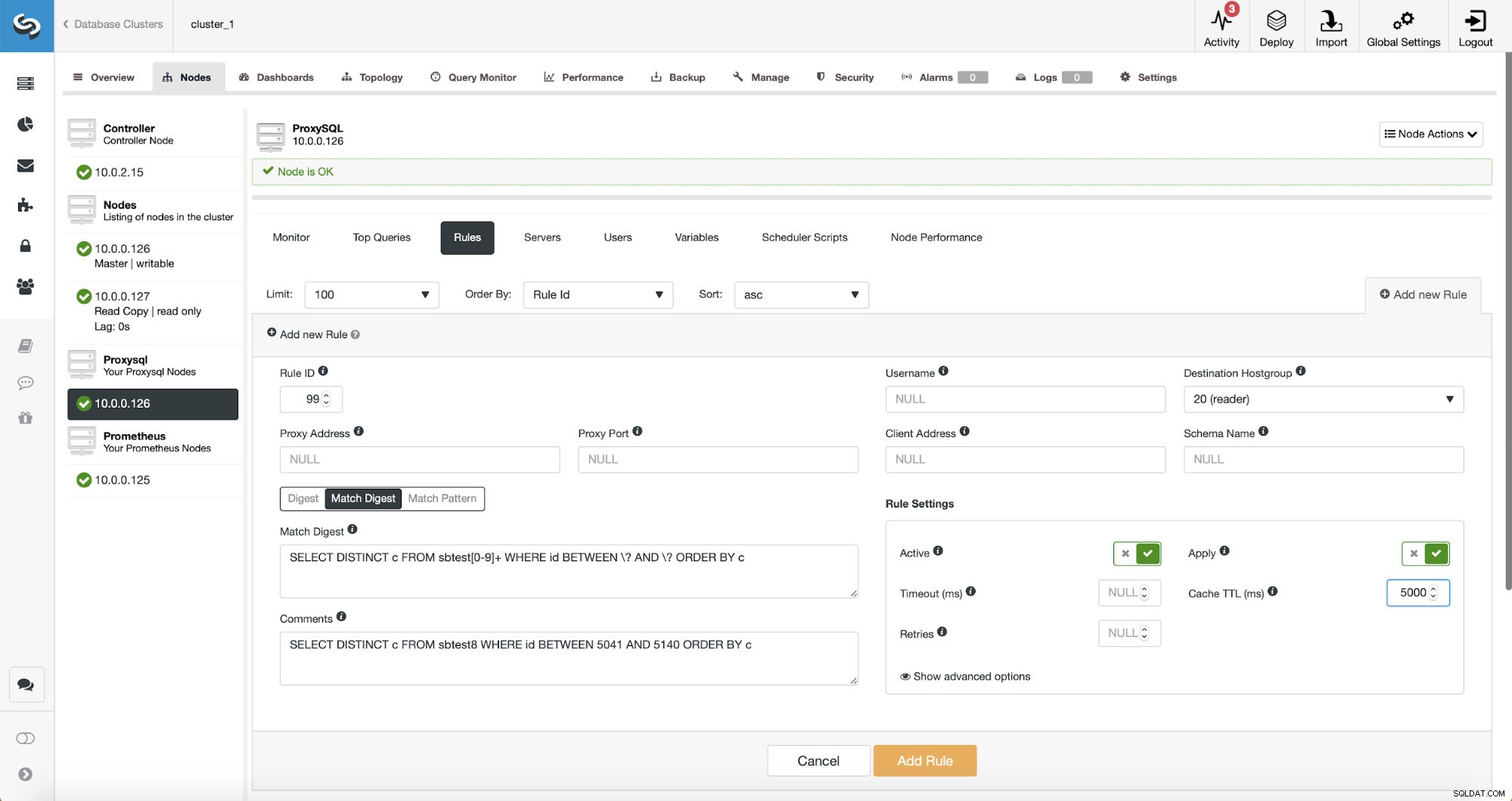
Existem três maneiras de combinar a consulta:Digest, Match Digest e Match Pattern. Vamos falar um pouco sobre eles aqui. Primeiro, Match Digest. Podemos definir aqui uma expressão regular que corresponderá a uma string de consulta generalizada que representa algum tipo de consulta. Por exemplo, para nossa consulta:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN 5041 AND 5140 ORDER BY cA representação genérica será:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN ? AND ? ORDER BY cComo você pode ver, ele removeu os argumentos para a cláusula WHERE, portanto, todas as consultas desse tipo são representadas como uma única string. Essa opção é muito boa de usar porque corresponde a todo o tipo de consulta e, o que é ainda mais importante, remove todos os espaços em branco. Isso torna muito mais fácil escrever uma expressão regular, pois você não precisa considerar quebras de linha estranhas, espaços em branco no início ou no final da string e assim por diante.
Digest é basicamente um hash que o ProxySQL calcula sobre o formulário Match Digest.
Por fim, Match Pattern corresponde ao texto de consulta completo, conforme enviado pelo cliente. No nosso caso, a consulta terá uma forma de:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN 5041 AND 5140 ORDER BY cVamos usar Match Digest, pois queremos que todas essas consultas sejam cobertas pela regra de consulta. Se quiséssemos armazenar em cache apenas essa consulta específica, uma boa opção seria usar o Match Pattern.
A expressão regular que usamos é:
SELECT DISTINCT c FROM sbtest[0-9]+ WHERE id BETWEEN \? AND \? ORDER BY cEstamos correspondendo literalmente a string de consulta generalizada exata com uma exceção - sabemos que essa consulta atingiu várias tabelas, portanto, adicionamos uma expressão regular para corresponder a todas elas.
Feito isso, podemos ver se a regra de consulta está em vigor ou não.
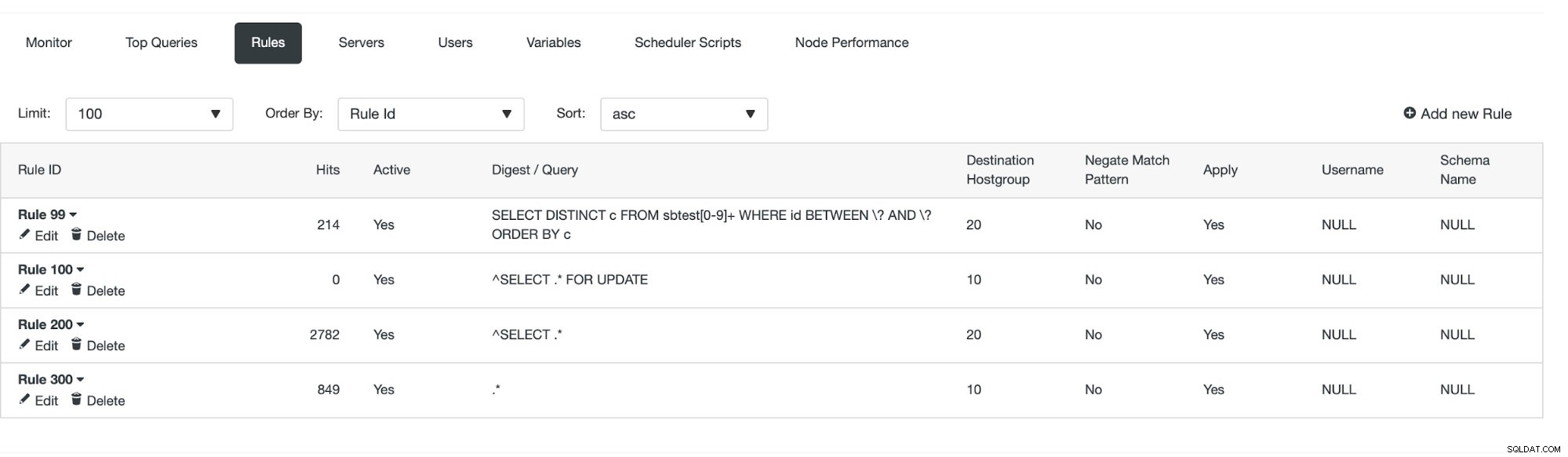
Podemos ver que os 'Hits' estão aumentando, o que significa que nossa regra de consulta está sendo usada. Em seguida, veremos outra maneira de criar uma regra de consulta.
Usando o ClusterControl para criar regras de consulta
O ProxySQL possui uma funcionalidade útil de coleta de estatísticas das consultas que ele roteou. Você pode rastrear dados como tempo de execução, quantas vezes uma determinada consulta foi executada e assim por diante. Esses dados também estão presentes no ClusterControl:
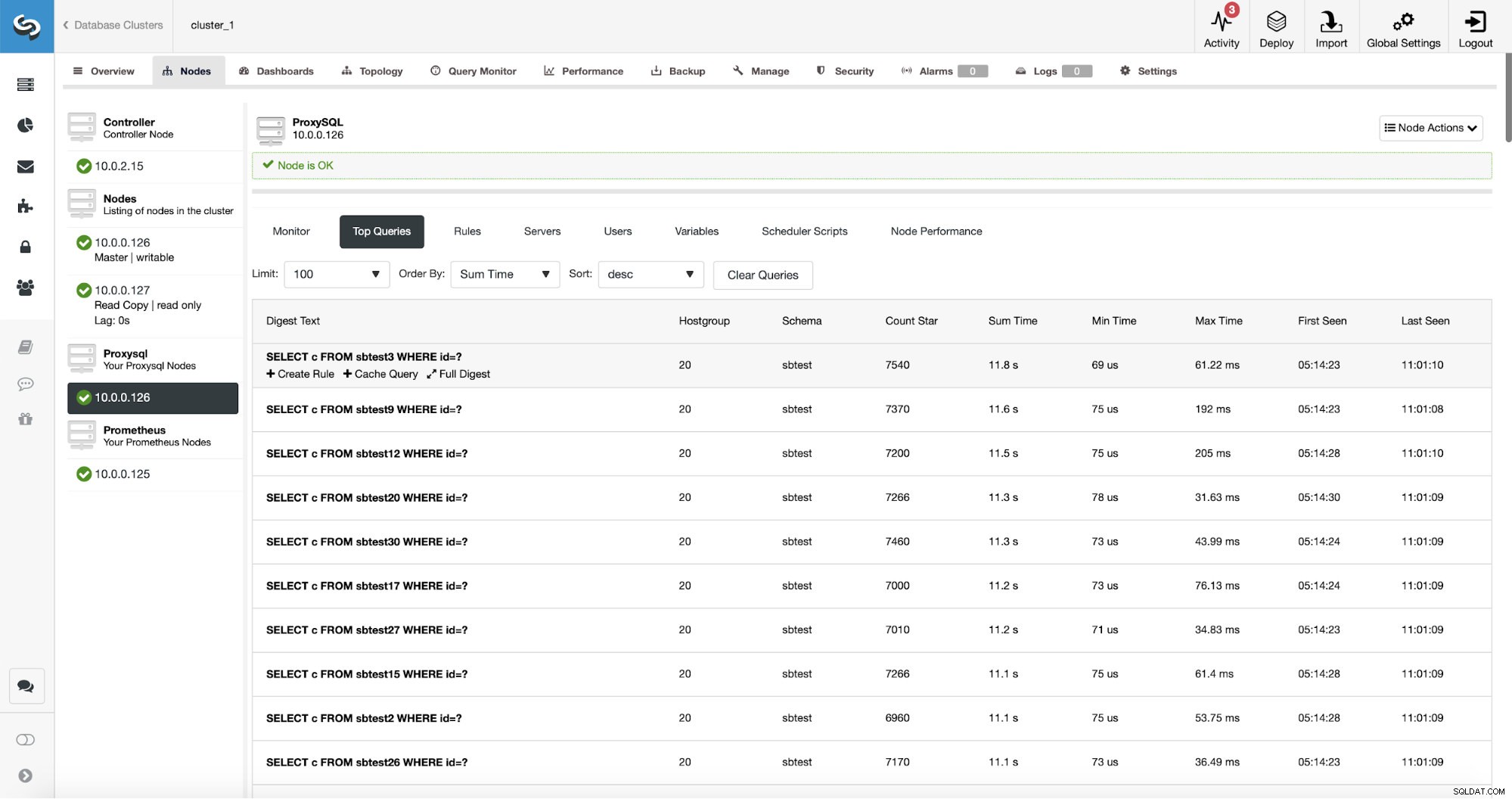
O que é ainda melhor, se você apontar para um determinado tipo de consulta, poderá criar uma regra de consulta relacionada a ele. Você também pode armazenar em cache facilmente esse tipo de consulta específico.
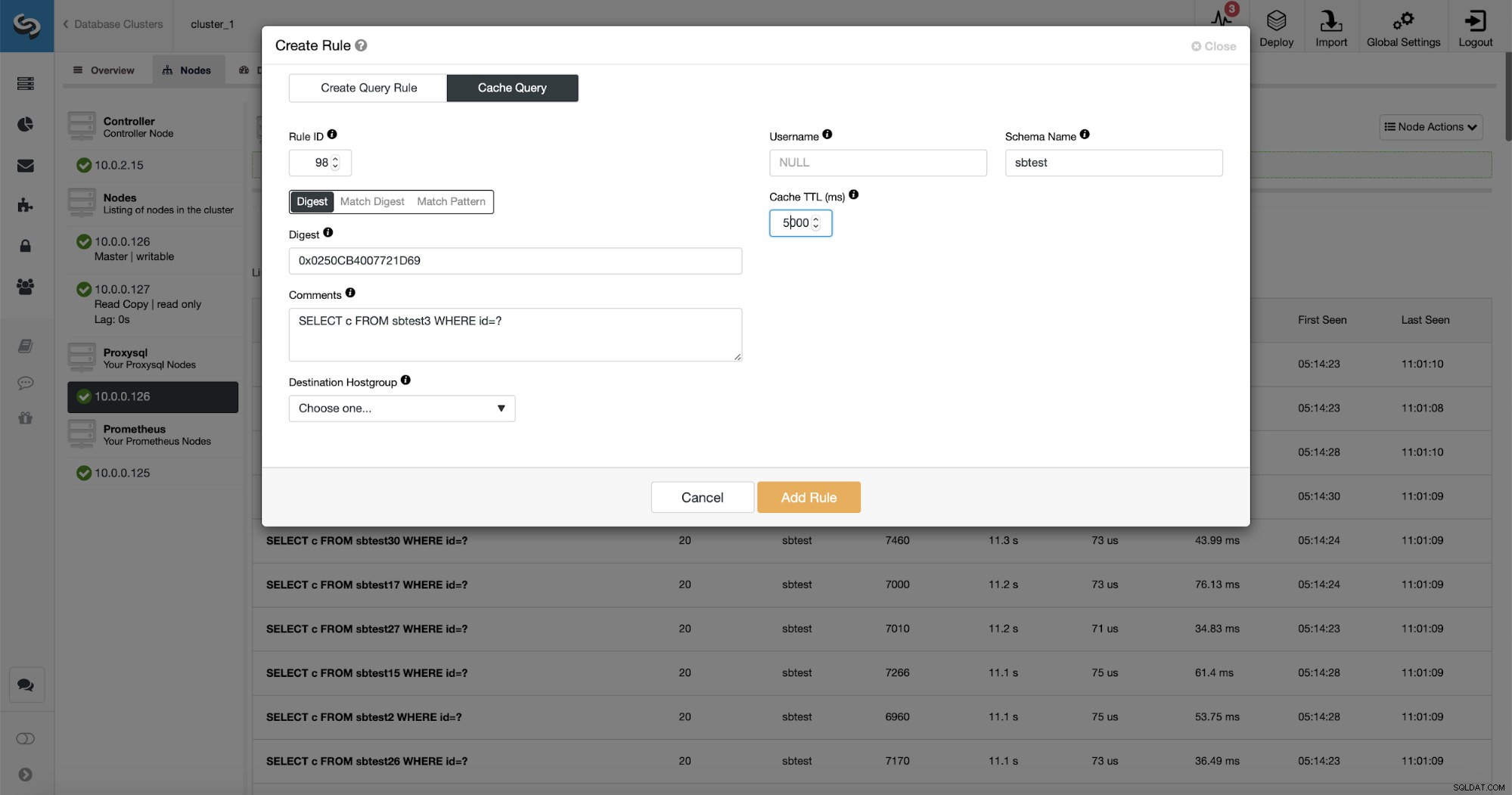
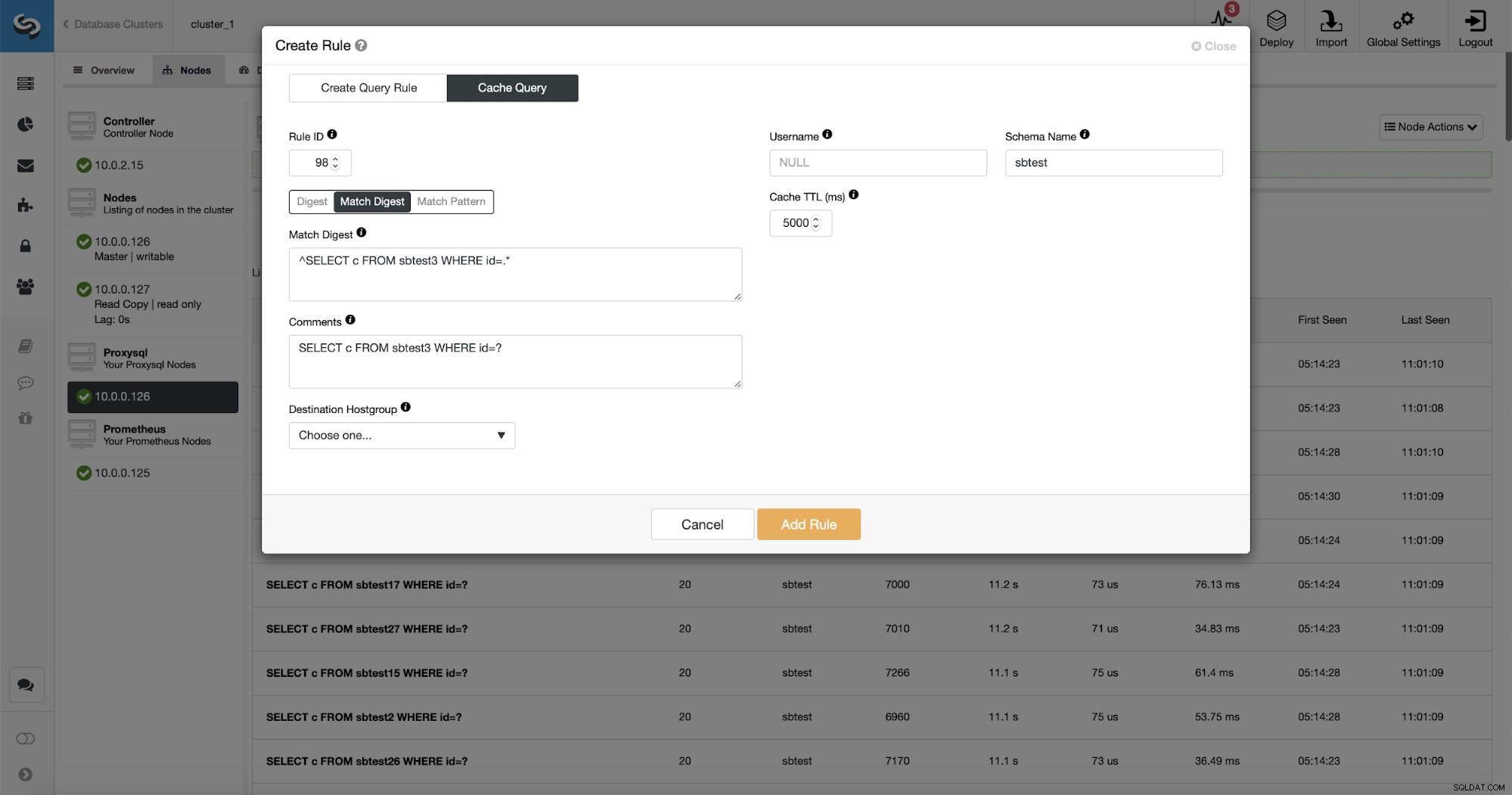
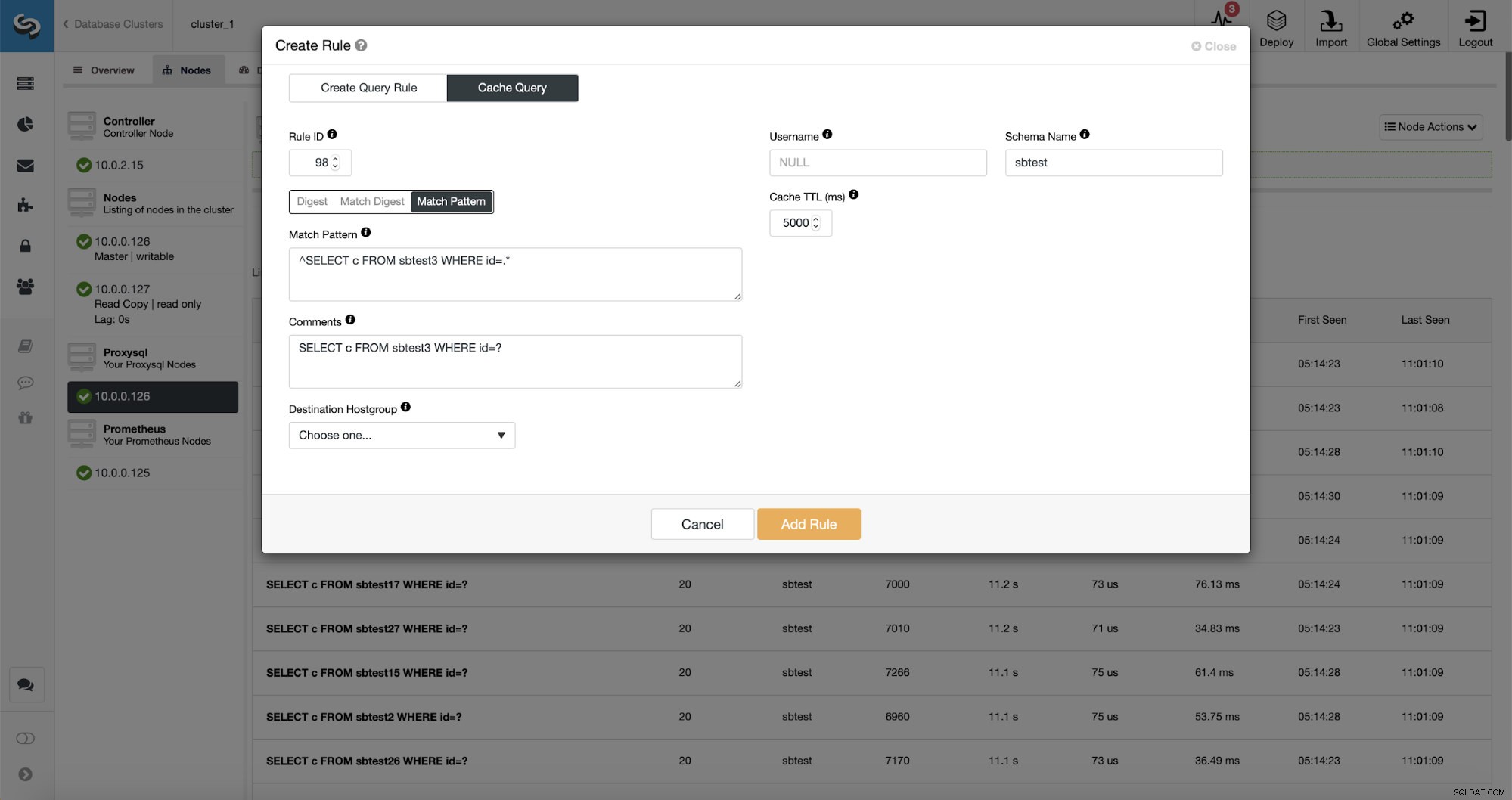
Como você pode ver, alguns dos dados como IP da regra, TTL do cache ou Nome do esquema já estão preenchidos. O ClusterControl também preencherá os dados com base no mecanismo de correspondência que você decidiu usar. Podemos facilmente usar hash para um determinado tipo de consulta ou podemos usar Match Digest ou Match Pattern se quisermos ajustar a expressão regular (por exemplo, fazendo o mesmo que fizemos anteriormente e estendendo a expressão regular para corresponder a todos os tabelas no esquema sbtest).
Isso é tudo que você precisa para criar facilmente regras de cache de consulta no ProxySQL. Baixe ClusterControl para experimentá-lo hoje.