Nesta postagem do blog, analisaremos 6 cenários de falha diferentes em sistemas de banco de dados de produção, variando de problemas de servidor único a planos de failover de vários datacenters. Orientaremos você pelos procedimentos de recuperação e failover para o respectivo cenário. Espero que isso lhe dê uma boa compreensão dos riscos que você pode enfrentar e coisas a serem consideradas ao projetar sua infraestrutura.
Esquema de banco de dados corrompido
Vamos começar com a instalação de um único nó - uma configuração de banco de dados na forma mais simples. Fácil de implementar, com o menor custo. Nesse cenário, você executa vários aplicativos no único servidor em que cada um dos esquemas de banco de dados pertence ao aplicativo diferente. A abordagem para recuperação de um único esquema dependeria de vários fatores.
- Tenho algum backup?
- Tenho um backup e com que rapidez posso restaurá-lo?
- Que tipo de mecanismo de armazenamento está em uso?
- Tenho um backup compatível com PITR (recuperação pontual)?
A corrupção de dados pode ser identificada pelo mysqlcheck.
mysqlcheck -uroot -p <DATABASE>Substitua DATABASE pelo nome do banco de dados e substitua TABLE pelo nome da tabela que você deseja verificar:
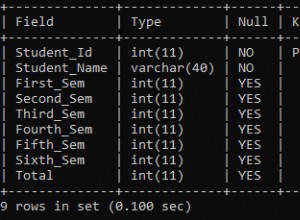
mysqlcheck -uroot -p <DATABASE> <TABLE>Mysqlcheck verifica o banco de dados e tabelas especificados. Se uma tabela passar na verificação, mysqlcheck exibirá OK para a tabela. No exemplo abaixo, podemos ver que a tabela salários requer recuperação.
employees.departments OK
employees.dept_emp OK
employees.dept_manager OK
employees.employees OK
Employees.salaries
Warning : Tablespace is missing for table 'employees/salaries'
Error : Table 'employees.salaries' doesn't exist in engine
status : Operation failed
employees.titles OKPara uma instalação de nó único sem servidores de DR adicionais, a abordagem principal seria restaurar os dados do backup. Mas esta não é a única coisa que você precisa considerar. Ter vários esquemas de banco de dados na mesma instância causa um problema quando você precisa desativar seu servidor para restaurar dados. Outra questão é se você pode reverter todos os seus bancos de dados para o último backup. Na maioria dos casos, isso não seria possível.
Existem algumas exceções aqui. É possível restaurar uma única tabela ou banco de dados do último backup quando a recuperação pontual não for necessária. Tal processo é mais complicado. Se você tiver mysqldump, poderá extrair seu banco de dados dele. Se você executar backups binários com xtradbackup ou mariabackup e tiver habilitado a tabela por arquivo, é possível.
Aqui está como verificar se você tem uma opção de tabela por arquivo habilitada.
mysql> SET GLOBAL innodb_file_per_table=1; Com innodb_file_per_table ativado, você pode armazenar tabelas InnoDB em um arquivo tbl_name .ibd. Ao contrário do mecanismo de armazenamento MyISAM, com seus arquivos tbl_name .MYD e tbl_name .MYI separados para índices e dados, o InnoDB armazena os dados e os índices juntos em um único arquivo .ibd. Para verificar seu mecanismo de armazenamento, você precisa executar:
mysql> select table_name,engine from information_schema.tables where table_name='table_name' and table_schema='database_name';ou diretamente do console:
[example@sqldat.com ~]# mysql -u<username> -p -D<database_name> -e "show table status\G"
Enter password:
*************************** 1. row ***************************
Name: test1
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 12
Avg_row_length: 1365
Data_length: 16384
Max_data_length: 0
Index_length: 0
Data_free: 0
Auto_increment: NULL
Create_time: 2018-05-24 17:54:33
Update_time: NULL
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment: Para restaurar tabelas do xtradbackup, você precisa passar por um processo de exportação. O backup precisa ser preparado antes de poder ser restaurado. A exportação é feita na fase de preparação. Depois que um backup completo for criado, execute o procedimento de preparação padrão com o sinalizador adicional --export :
innobackupex --apply-log --export /u01/backupIsso criará arquivos de exportação adicionais que você usará posteriormente na fase de importação. Para importar uma tabela para outro servidor, primeiro crie uma nova tabela com a mesma estrutura daquela que será importada nesse servidor:
mysql> CREATE TABLE corrupted_table (...) ENGINE=InnoDB;descarte o tablespace:
mysql> ALTER TABLE mydatabase.mytable DISCARD TABLESPACE;Em seguida, copie os arquivos mytable.ibd e mytable.exp para a home do banco de dados e importe seu tablespace:
mysql> ALTER TABLE mydatabase.mytable IMPORT TABLESPACE;Porém para fazer isso de forma mais controlada, a recomendação seria restaurar um backup do banco de dados em outra instância/servidor e copiar o que for necessário de volta para o sistema principal. Para fazer isso, você precisa executar a instalação da instância mysql. Isso pode ser feito na mesma máquina - mas requer mais esforço para configurar de forma que ambas as instâncias possam ser executadas na mesma máquina - por exemplo, isso exigiria configurações de comunicação diferentes.
Você pode combinar a restauração e a instalação de tarefas usando o ClusterControl.
O ClusterControl guiará você pelos backups disponíveis no local ou na nuvem, permitirá que você escolha a hora exata para uma restauração ou a posição exata do log e instale uma nova instância de banco de dados, se necessário.
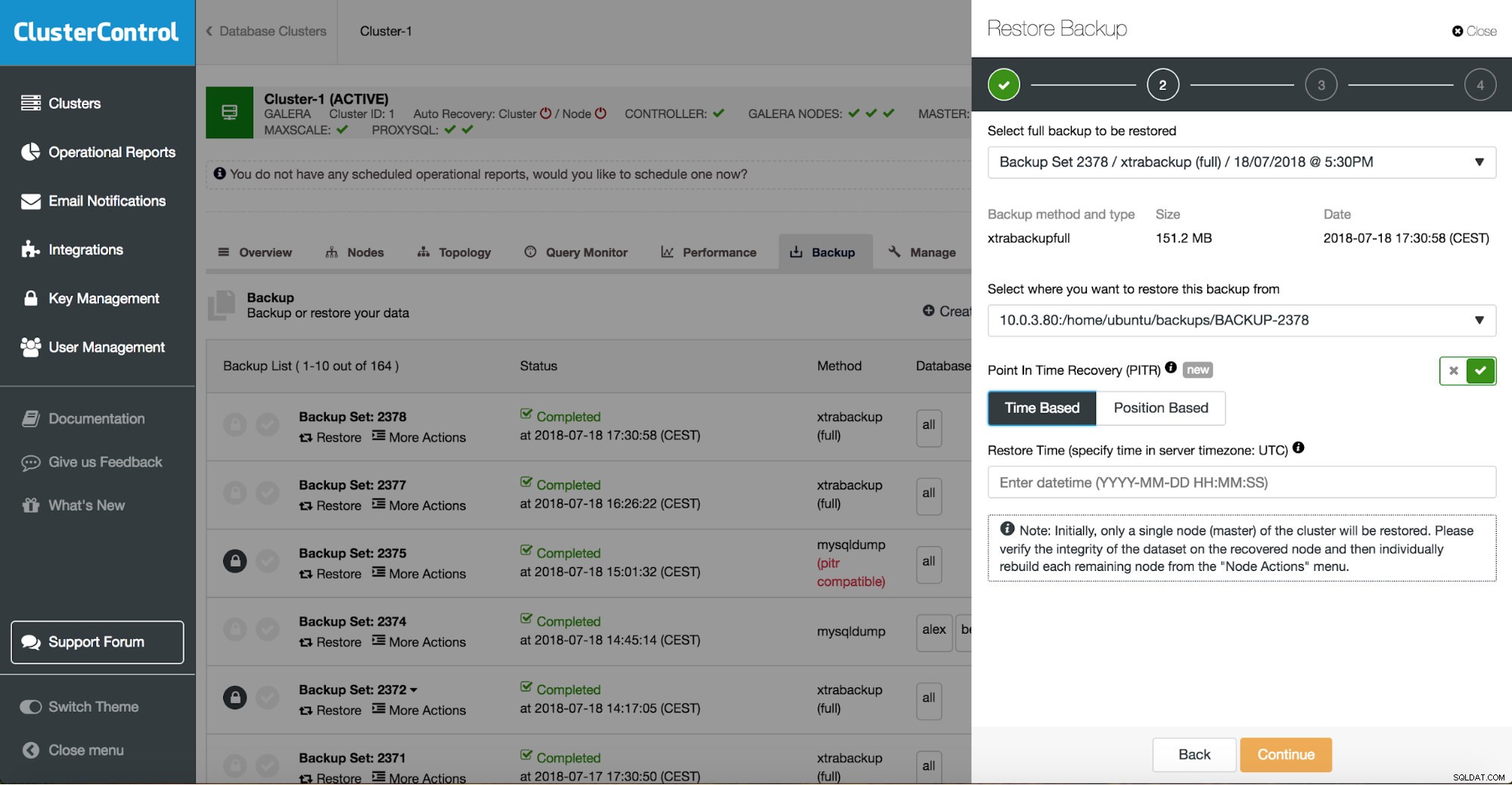 ClusterControl point in time recovery
ClusterControl point in time recovery 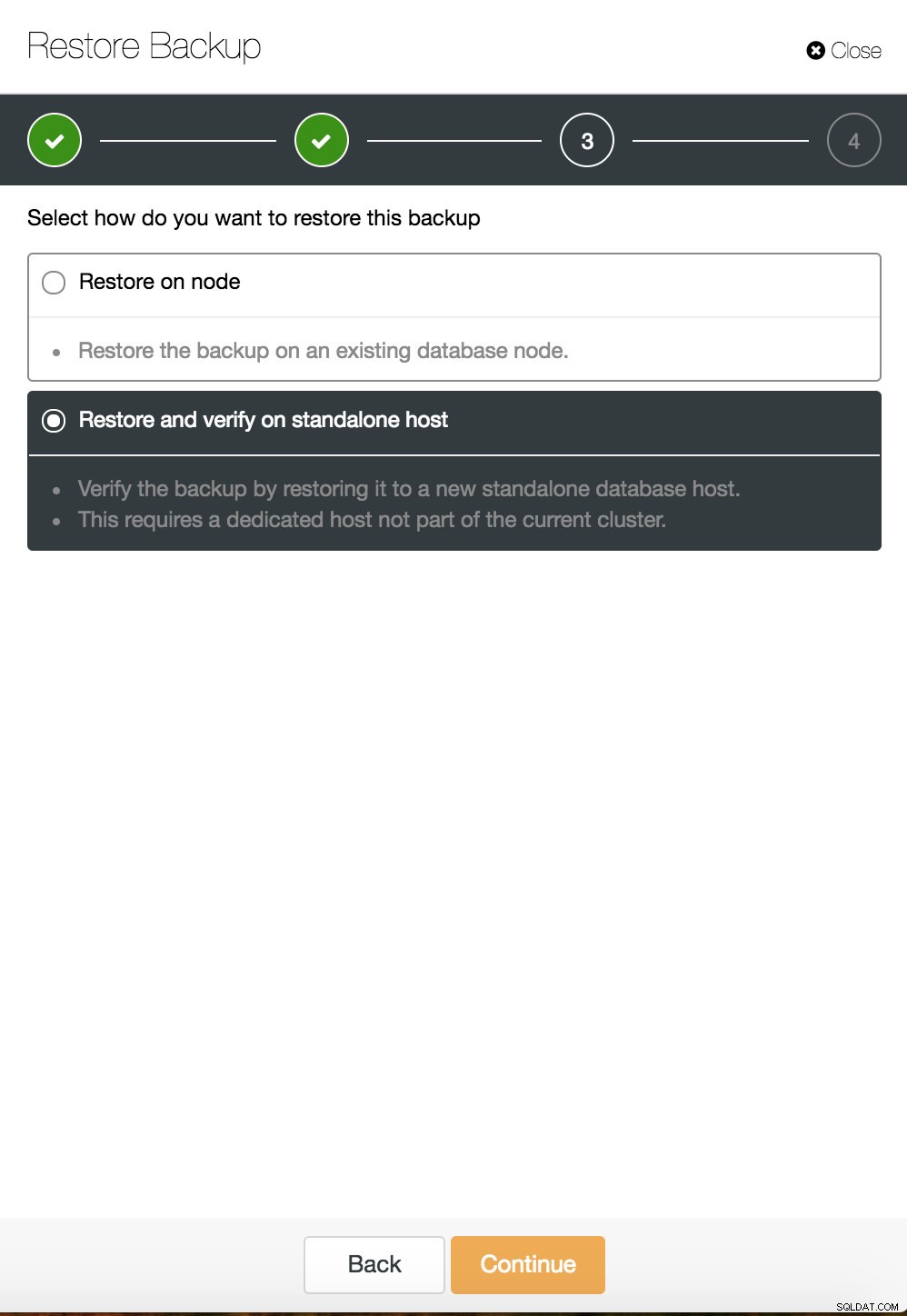 ClusterControl restaurar e verificar em um host autônomo
ClusterControl restaurar e verificar em um host autônomo 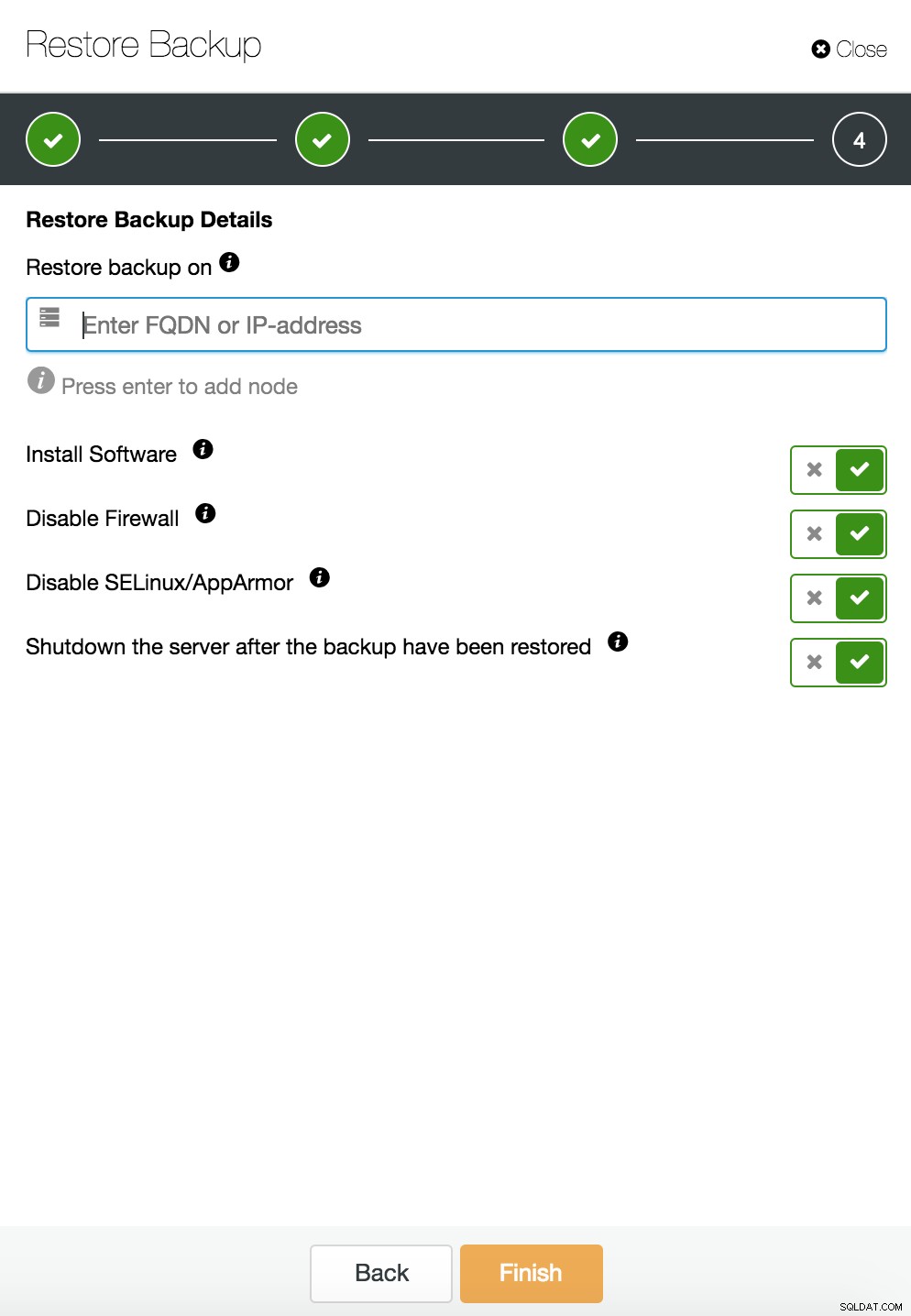 CusterControl restaurar e verificar em um host autônomo. Opções de instalação.
CusterControl restaurar e verificar em um host autônomo. Opções de instalação. Você pode encontrar mais informações sobre recuperação de dados no blog My MySQL Database is Corrupted... What Do I Do Now?
Instância de banco de dados corrompida no servidor dedicado
Defeitos na plataforma subjacente geralmente são a causa da corrupção do banco de dados. Sua instância MySQL depende de várias coisas para armazenar e recuperar dados - subsistema de disco, controladores, canais de comunicação, drivers e firmware. Uma falha pode afetar partes de seus dados, binários mysql ou até mesmo arquivos de backup que você armazena no sistema. Para separar aplicativos diferentes, você pode colocá-los em servidores dedicados.
Esquemas de aplicativos diferentes em sistemas separados é uma boa ideia se você puder comprá-los. Pode-se dizer que isso é um desperdício de recursos, mas há uma chance de que o impacto nos negócios seja menor se apenas um deles cair. Mas mesmo assim, você precisa proteger seu banco de dados contra perda de dados. Armazenar backup no mesmo servidor não é uma má ideia, desde que você tenha uma cópia em outro lugar. Atualmente, o armazenamento em nuvem é uma excelente alternativa ao backup em fita.
O ClusterControl permite que você mantenha uma cópia do seu backup na nuvem. Ele suporta upload para os 3 principais provedores de nuvem - Amazon AWS, Google Cloud e Microsoft Azure.
Quando você tiver seu backup completo restaurado, convém restaurá-lo para um determinado momento. A recuperação pontual atualizará o servidor para um momento mais recente do que quando o backup completo foi feito. Para fazer isso, você precisa ter seus logs binários ativados. Você pode verificar os logs binários disponíveis com:
mysql> SHOW BINARY LOGS;E arquivo de log atual com:
SHOW MASTER STATUS;Em seguida, você pode capturar dados incrementais passando logs binários para o arquivo sql. As operações ausentes podem ser executadas novamente.
mysqlbinlog --start-position='14231131' --verbose /var/lib/mysql/binlog.000010 /var/lib/mysql/binlog.000011 /var/lib/mysql/binlog.000012 /var/lib/mysql/binlog.000013 /var/lib/mysql/binlog.000015 > binlog.outO mesmo pode ser feito no ClusterControl.
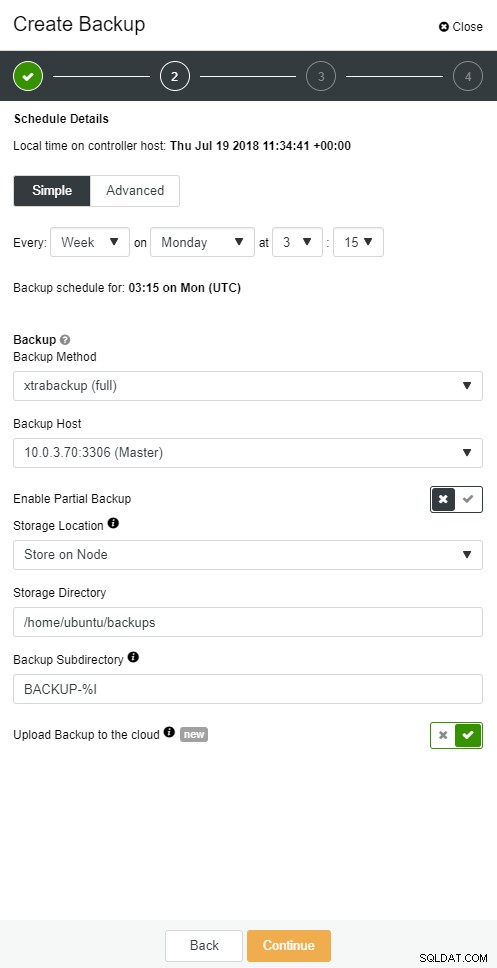 Backup na nuvem do ClusterControl
Backup na nuvem do ClusterControl 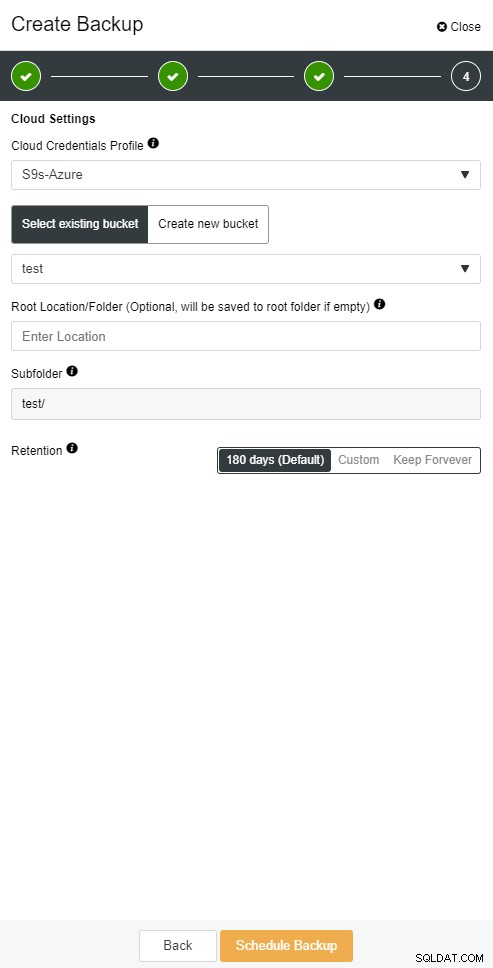 Backup na nuvem do ClusterControl
Backup na nuvem do ClusterControl O escravo do banco de dados fica inativo
Ok, então você tem seu banco de dados rodando em um servidor dedicado. Você criou um agendamento de backup sofisticado com uma combinação de backups completos e incrementais, carregá-los na nuvem e armazenar o backup mais recente em discos locais para uma recuperação rápida. Você tem diferentes políticas de retenção de backup - mais curtas para backups armazenados em drivers de disco locais e estendidas para seus backups na nuvem.
Parece que você está bem preparado para um cenário de desastre. Mas quando se trata do tempo de restauração, pode não atender às suas necessidades de negócios.
Você precisa de uma função de failover rápida. Um servidor que estará funcionando aplicando logs binários do mestre onde as gravações acontecem. A replicação mestre/escravo inicia um novo capítulo no cenário de failover. É um método rápido para trazer seu aplicativo de volta à vida se o master ficar inativo.
Mas há poucas coisas a serem consideradas no cenário de failover. Uma é configurar um escravo de replicação atrasada, para que você possa reagir aos comandos fat finger que foram acionados no servidor mestre. Um servidor escravo pode ficar atrás do mestre por pelo menos um determinado período de tempo. O atraso padrão é 0 segundos. Use a opção MASTER_DELAY para CHANGE MASTER TO para definir o atraso para N segundos:
CHANGE MASTER TO MASTER_DELAY = N;A segunda é habilitar o failover automatizado. Existem muitas soluções de failover automatizadas no mercado. Você pode configurar o failover automático com ferramentas de linha de comando como MHA, MRM, mysqlfailover ou GUI Orchestrator e ClusterControl. Quando configurado corretamente, pode reduzir significativamente sua interrupção.
O ClusterControl suporta failover automatizado para replicações MySQL, PostgreSQL e MongoDB, bem como soluções de cluster multi-mestre Galera e NDB.
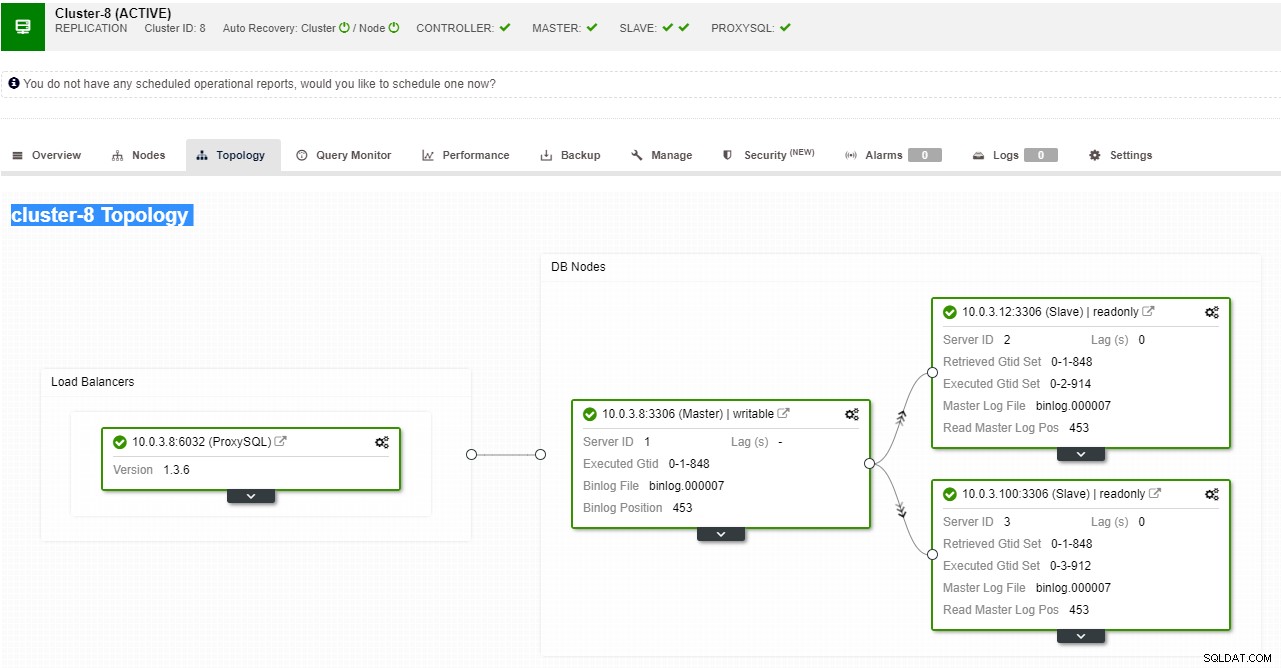 Visualização da topologia de replicação do ClusterControl
Visualização da topologia de replicação do ClusterControl Quando um nó escravo trava e o servidor está muito atrasado, você pode querer reconstruir seu servidor escravo. O processo de reconstrução do escravo é semelhante à restauração do backup.
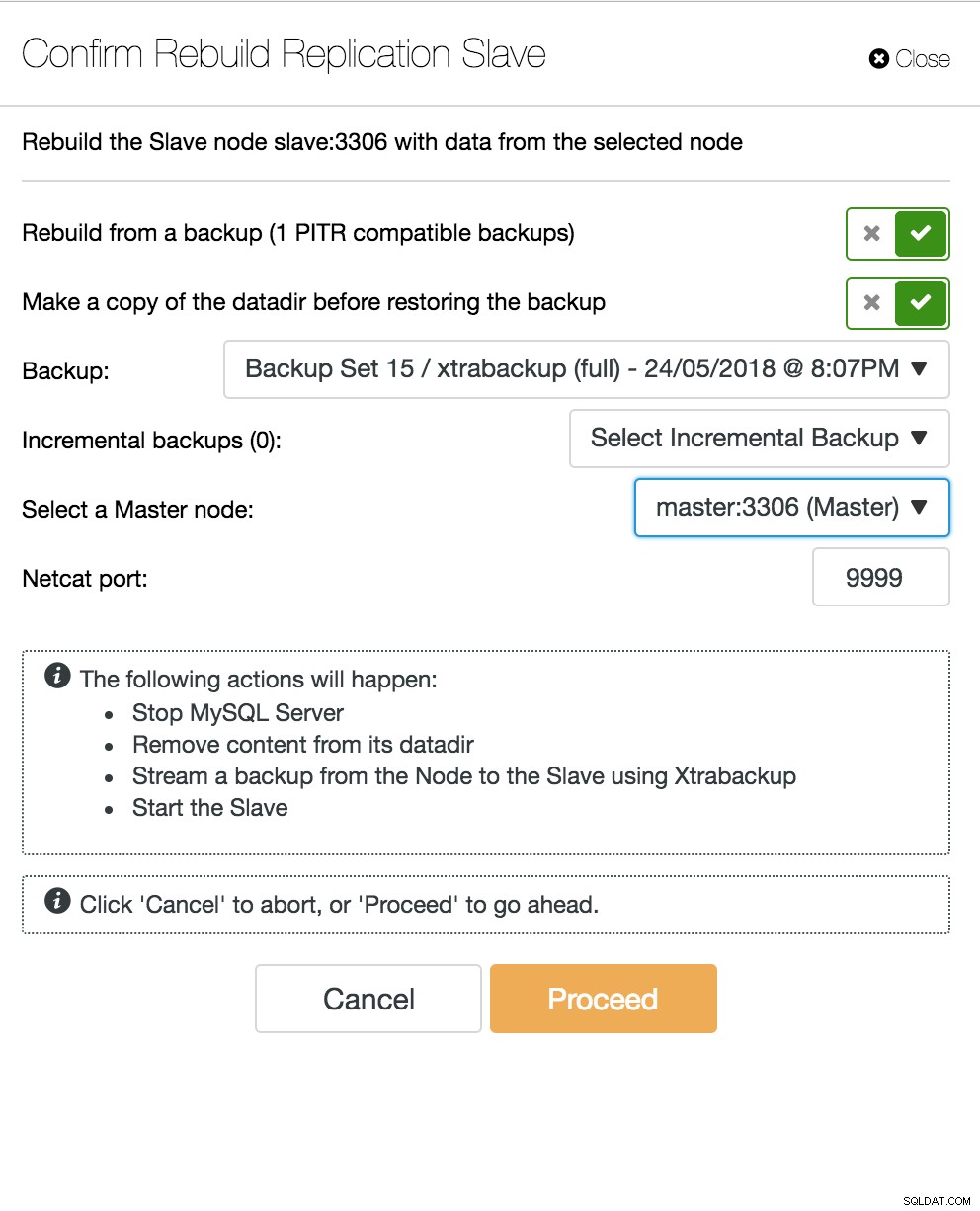 Escravo de reconstrução do ClusterControl
Escravo de reconstrução do ClusterControl Servidor multimestre de banco de dados fica inativo
Agora, quando você tem um servidor escravo atuando como um nó DR e seu processo de failover é bem automatizado e testado, sua vida de DBA se torna mais confortável. Isso é verdade, mas há mais alguns quebra-cabeças para resolver. O poder de computação não é gratuito, e sua equipe de negócios pode solicitar que você utilize melhor seu hardware, você pode querer usar seu servidor escravo não apenas como servidor passivo, mas também para atender a operações de gravação.
Você pode então querer investigar uma solução de replicação multimestre. Galera Cluster tornou-se uma opção mainstream para MySQL e MariaDB de alta disponibilidade. E embora agora seja conhecido como um substituto confiável para as arquiteturas mestre-escravo tradicionais do MySQL, não é um substituto imediato.
O cluster Galera possui uma arquitetura nada compartilhada. Em vez de discos compartilhados, Galera usa replicação baseada em certificação com comunicação de grupo e ordenação de transações para obter replicação síncrona. Um cluster de banco de dados deve ser capaz de sobreviver à perda de um nó, embora isso seja feito de maneiras diferentes. No caso do Galera, o aspecto crítico é o número de nós. Galera requer um quórum para permanecer operacional. Um cluster de três nós pode sobreviver à falha de um nó. Com mais nós em seu cluster, você pode sobreviver a mais falhas.
O processo de recuperação é automatizado para que você não precise realizar nenhuma operação de failover. No entanto, a boa prática seria matar os nós e ver o quão rápido você pode trazê-los de volta. Para tornar essa operação mais eficiente, você pode modificar o tamanho do cache galera. Se o tamanho do cache galera não for planejado corretamente, seu próximo nó de inicialização terá que fazer um backup completo em vez de apenas perder conjuntos de gravação no cache.
O cenário de failover é simples como iniciar a instância. Com base nos dados no cache do galera, o nó de inicialização executará SST (restauração do backup completo) ou IST (aplicar conjuntos de gravação ausentes). No entanto, isso está muitas vezes ligado à intervenção humana. Se você deseja automatizar todo o processo de failover, pode usar a funcionalidade de recuperação automática do ClusterControl (nível de nó e cluster).
 Recuperação automática do cluster do ClusterControl
Recuperação automática do cluster do ClusterControl Estime o tamanho do cache galera:
MariaDB [(none)]> SET @start := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); do sleep(60); SET @end := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); SET @gcache := (SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(@@GLOBAL.wsrep_provider_options,'gcache.size = ',-1), 'M', 1)); SELECT ROUND((@end - @start),2) AS `MB/min`, ROUND((@end - @start),2) * 60 as `MB/hour`, @gcache as `gcache Size(MB)`, ROUND(@gcache/round((@end - @start),2),2) as `Time to full(minutes)`;Para tornar o failover mais consistente, você deve habilitar gcache.recover=yes em mycnf. Esta opção irá reviver o galera-cache na reinicialização. Isso significa que o nó pode atuar como um DONOR e serviços de conjuntos de gravação ausentes (facilitando o IST, em vez de usar o SST).
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 2,
members = 2/3 (joined/total),
act_id = 12810,
last_appl. = 0,
protocols = 0/7/3 (gcs/repl/appl),
group UUID = 49eca8f8-0e3a-11e8-be4a-e7e3fe48cb69
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Flow-control interval: [28, 28]
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Trying to continue unpaused monitor
2018-07-20 8:59:44 139657311033088 [Note] WSREP: New cluster view: global state: 49eca8f8-0e3a-11e8-be4a-e7e3fe48cb69:12810, view# 3: Primary, number of nodes: 3, my index: 1, protocol version 3O nó proxy SQL fica inativo
Se você tiver uma configuração de IP virtual, tudo o que você precisa fazer é apontar seu aplicativo para o endereço IP virtual e tudo deve estar correto na conexão. Não basta ter suas instâncias de banco de dados abrangendo vários datacenters, você ainda precisa de seus aplicativos para acessá-los. Suponha que você tenha dimensionado o número de réplicas de leitura, talvez você queira implementar IPs virtuais para cada uma dessas réplicas de leitura também por motivos de manutenção ou disponibilidade. Pode se tornar um pool complicado de IPs virtuais que você precisa gerenciar. Se uma dessas réplicas de leitura sofrer uma falha, você precisará reatribuir o IP virtual ao host diferente, ou então seu aplicativo se conectará a um host que está inativo ou, na pior das hipóteses, a um servidor atrasado com dados obsoletos.
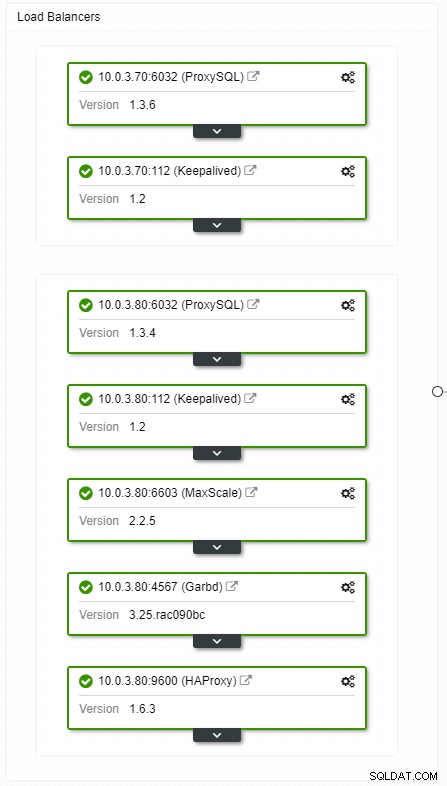 Visualização de topologia de balanceadores de carga de HA ClusterControl
Visualização de topologia de balanceadores de carga de HA ClusterControl Falhas não são frequentes, mas são mais prováveis do que servidores caindo. Se, por qualquer motivo, um escravo ficar inativo, algo como ProxySQL redirecionará todo o tráfego para o mestre, com o risco de sobrecarregá-lo. Quando o escravo se recuperar, o tráfego será redirecionado de volta para ele. Normalmente, esse tempo de inatividade não deve demorar mais do que alguns minutos, portanto, a gravidade geral é média, embora a probabilidade também seja média.
Para ter seus componentes do balanceador de carga redundantes, você pode usar keepalived.
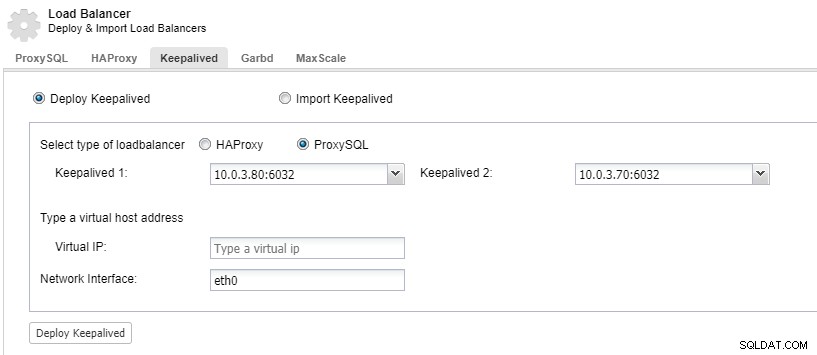 ClusterControl:implantar keepalived para balanceador de carga ProxySQL
ClusterControl:implantar keepalived para balanceador de carga ProxySQL O datacenter fica inativo
O principal problema com a replicação é que não há um mecanismo majoritário para detectar uma falha no datacenter e atender um novo mestre. Uma das resoluções é usar o Orchestrator/Raft. O Orchestrator é um supervisor de topologia que pode controlar failovers. Quando usado junto com o Raft, o Orchestrator se tornará ciente do quorum. Uma das instâncias do orquestrador é eleita como líder e executa as tarefas de recuperação. A conexão entre o nó do orquestrador não se correlaciona com as confirmações do banco de dados transacional e é esparsa.
O Orchestrator/Raft pode usar instâncias extras que realizam o monitoramento da topologia. No caso de particionamento de rede, as instâncias particionadas do orquestrador não realizarão nenhuma ação. A parte do cluster do orquestrador que tiver o quorum elegerá um novo mestre e fará as alterações de topologia necessárias.
O ClusterControl é usado para gerenciamento, dimensionamento e, o que é mais importante, recuperação de nós - o Orchestrator lidaria com failovers, mas se um escravo travasse, o ClusterControl garantiria que ele fosse recuperado. O Orchestrator e o ClusterControl estariam localizados na mesma zona de disponibilidade, separados dos nós MySQL, para garantir que suas atividades não sejam afetadas por divisões de rede entre as zonas de disponibilidade no data center.