O Galera Cluster impõe uma forte consistência de dados, onde todos os nós do cluster são fortemente acoplados. Embora a segmentação de rede seja suportada, o desempenho da replicação ainda está vinculado a dois fatores:
-
O tempo de ida e volta (RTT) para o nó mais distante no cluster do nó originador.
-
O tamanho de um conjunto de gravação a ser transferido e certificado para conflito no nó receptor.
Embora existam maneiras de aumentar o desempenho do Galera, não é possível contornar esses dois fatores limitantes.
Felizmente, Galera Cluster foi construído em cima do MySQL, que também vem com um recurso de replicação embutido (duh!). Tanto a replicação Galera quanto a replicação MySQL existem no mesmo software de servidor de forma independente. Podemos fazer uso dessas tecnologias para trabalharmos juntos, onde toda a replicação dentro de um datacenter será no Galera, enquanto a replicação entre datacenters será no MySQL Replication padrão. O site escravo pode atuar como um site de espera ativa, pronto para servir dados assim que os aplicativos forem redirecionados para o site de backup. Cobrimos isso em um blog anterior sobre arquiteturas MySQL para recuperação de desastres.
A replicação de cluster para cluster foi introduzida no ClusterControl na versão 1.7.4. Nesta postagem do blog, mostraremos como é simples configurar a replicação entre dois Galera Clusters (PXC 8.0). Em seguida, veremos a parte mais desafiadora:lidar com falhas nos níveis de nó e cluster com a ajuda do ClusterControl; As operações de failover e failback são cruciais para preservar a integridade dos dados em todo o sistema.
Implantação de cluster
Para o nosso exemplo, precisaremos de pelo menos dois clusters e dois sites – um para o primário e outro para o secundário. Funciona de forma semelhante à replicação mestre-escravo tradicional do MySQL, mas em uma escala maior com três nós de banco de dados em cada site. Com o ClusterControl, você conseguiria isso implantando um cluster primário, seguido pela implantação do cluster secundário no site de recuperação de desastres como um cluster de réplica, replicado por uma replicação assíncrona bidirecional.
O diagrama a seguir ilustra nossa arquitetura final:

Temos seis nós de banco de dados no total, três no site principal e outro três no site de recuperação de desastres. Para simplificar a representação do nó, usaremos as seguintes notações:
-
Site principal:
-
galera1-P - 192.168.11.171 (mestre)
-
galera2-P - 192.168.11.172
-
galera3-P - 192.168.11.173
-
-
Site de recuperação de desastres:
-
galera1-DR - 192.168.11.181 (escravo)
-
galera2-DR - 192.168.11.182
-
galera3-DR - 192.168.11.183
-
Primeiro, basta implantar o primeiro cluster e o chamamos de PXC-Primário. Abra ClusterControl UI → Deploy → MySQL Galera e insira todos os detalhes necessários:
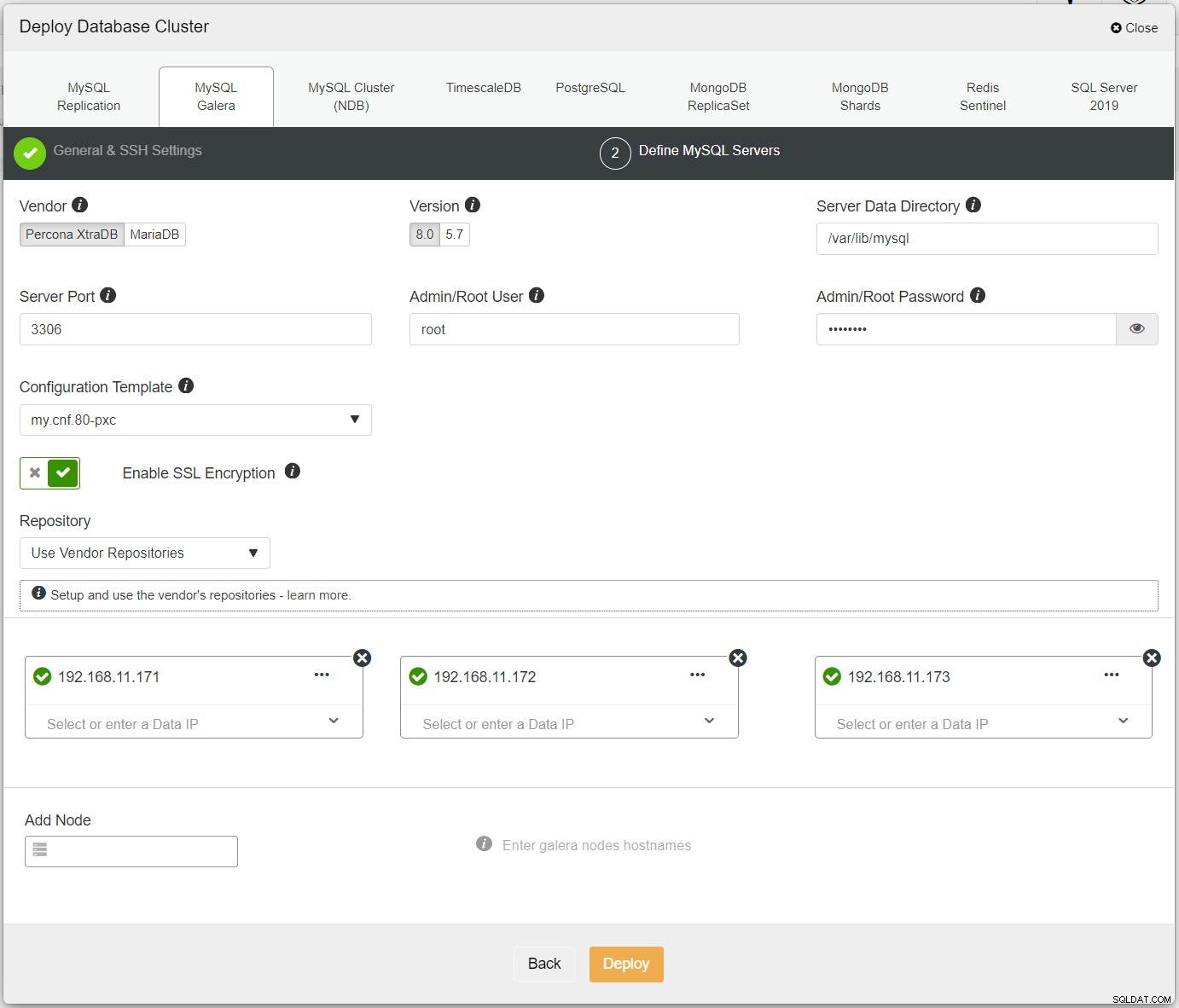
Certifique-se de que cada nó especificado tenha um visto verde próximo a ele, indicando que ClusterControl pode se conectar ao host via SSH sem senha. Clique em Implantar e aguarde a conclusão da implantação. Uma vez feito, você deverá ver o seguinte cluster listado na página do painel do cluster:
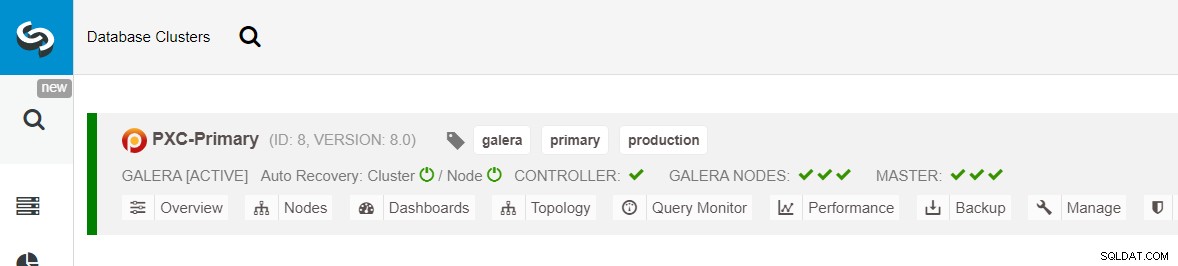
A seguir, usaremos o recurso ClusterControl chamado Create Replica Cluster, acessível em a lista suspensa Ação do cluster:
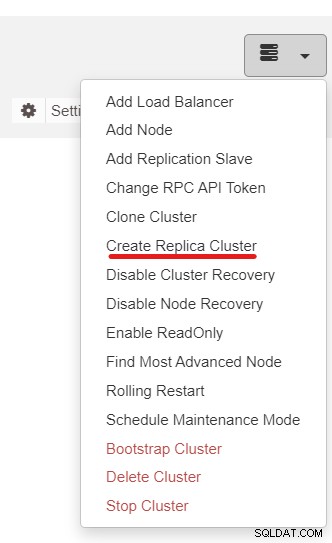
Você verá o seguinte pop-up da barra lateral:
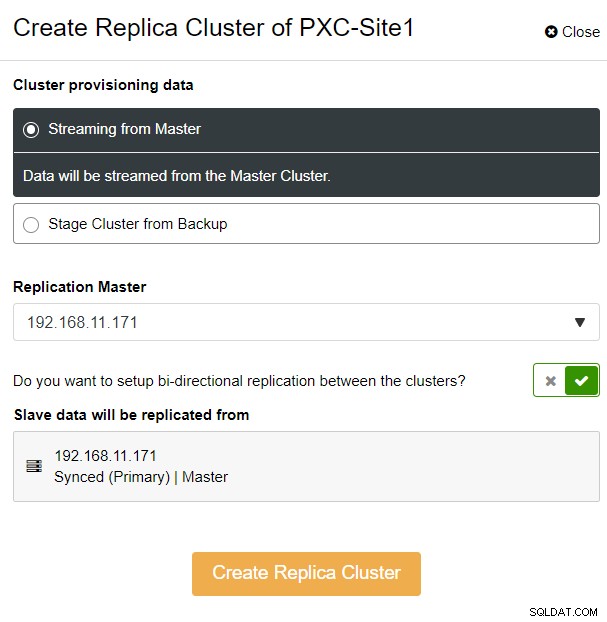
Escolhemos a opção "Streaming from Master", onde ClusterControl usará o mestre escolhido para sincronizar o cluster de réplica e configurar a replicação. Preste atenção à opção de replicação bidirecional. Se habilitado, o ClusterControl configurará uma replicação bidirecional entre os dois sites (replicação circular). O mestre escolhido será replicado do primeiro mestre definido para o cluster de réplicas e vice-versa. Essa configuração minimizará o tempo de preparação necessário ao recuperar após failover ou failback. Clique em "Criar cluster de réplica", onde o ClusterControl abre um novo assistente de implantação para o cluster de réplica, conforme mostrado abaixo:
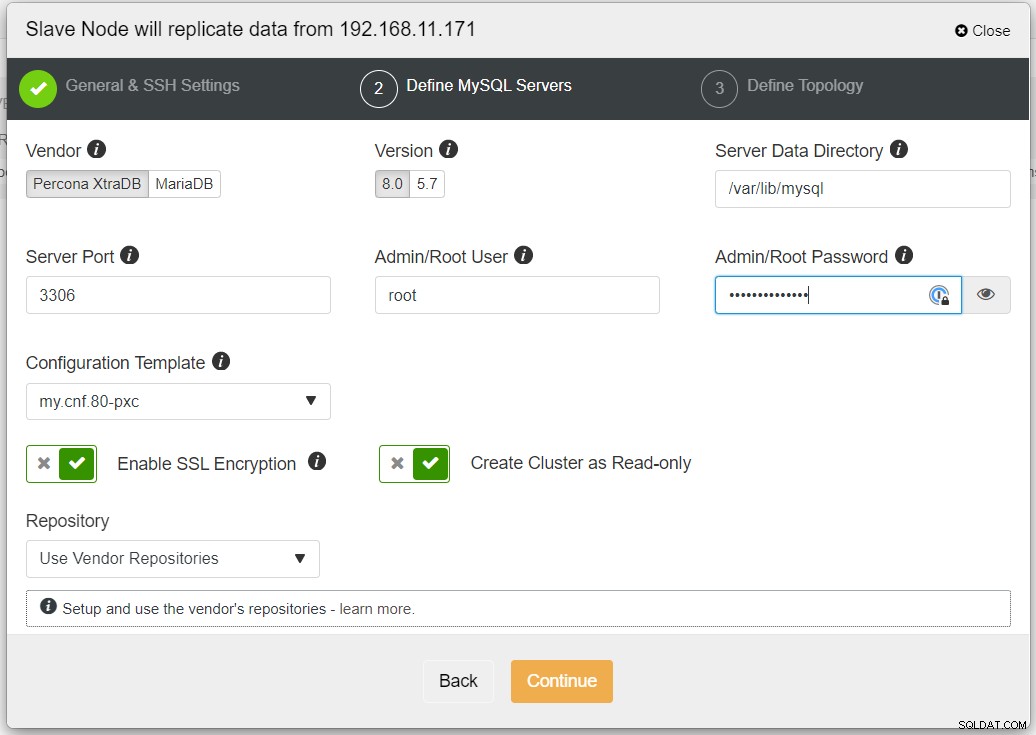
Recomenda-se habilitar a criptografia SSL se a replicação envolver redes não confiáveis como WAN, redes não encapsuladas ou a Internet. Além disso, certifique-se de que "Criar cluster como somente leitura" esteja alternado; esta é a proteção contra gravações acidentais e um bom indicador para distinguir facilmente entre o cluster ativo (leitura-gravação) e o cluster passivo (somente leitura).
Ao preencher todas as informações necessárias, você deve chegar ao seguinte estágio para definir a topologia do cluster de réplicas:
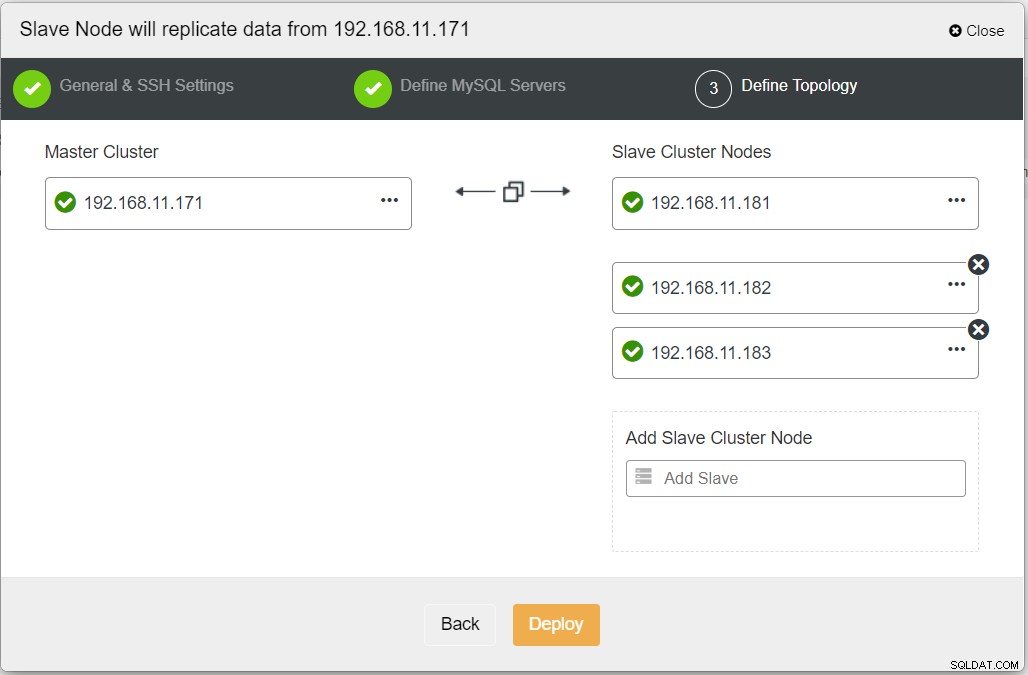
No painel do ClusterControl, quando a implantação for concluída, você deverá ver o O site DR tem uma seta bidirecional conectada ao site Primário:
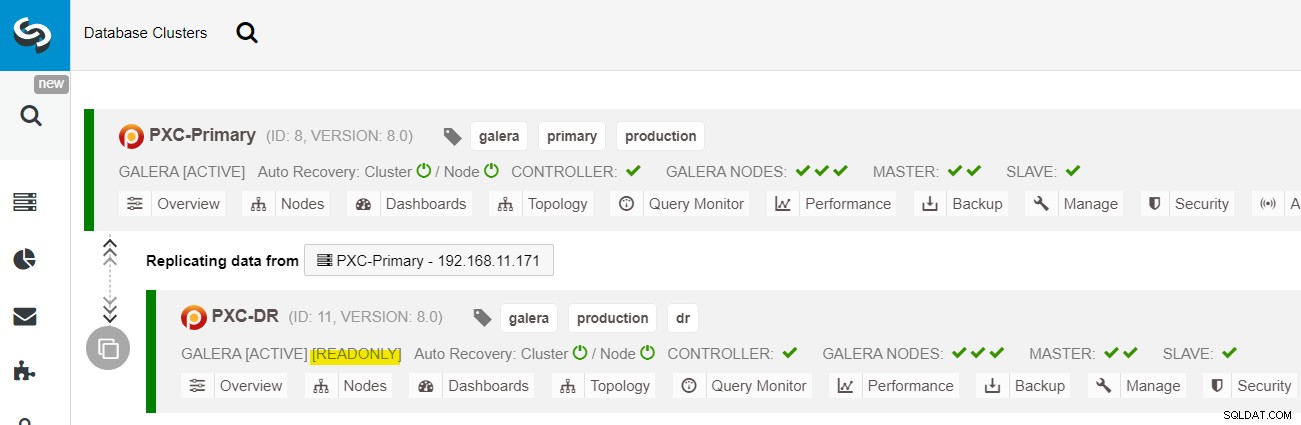
A implantação está concluída. Os aplicativos devem enviar gravações apenas para o Site Primário, pois este é o site ativo e o site de DR está configurado para somente leitura (destacado em amarelo). As leituras podem ser enviadas para ambos os sites, embora o site de DR corra o risco de ficar para trás devido à natureza da replicação assíncrona. Essa configuração tornará os sites primário e de recuperação de desastres independentes um do outro, conectados livremente com a replicação assíncrona. Um dos nós Galera no site DR será um escravo que replica de um dos nós Galera (master) no site primário.
Agora temos um sistema em que uma falha de cluster no site primário não afetará o site de backup. Em termos de desempenho, a latência da WAN não afetará as atualizações no cluster ativo. Eles são enviados de forma assíncrona para o site de backup.
Como observação lateral, também é possível ter uma instância escrava dedicada como retransmissão de replicação em vez de usar um dos nós Galera como escravo.
Procedimento de failover do nó Galera
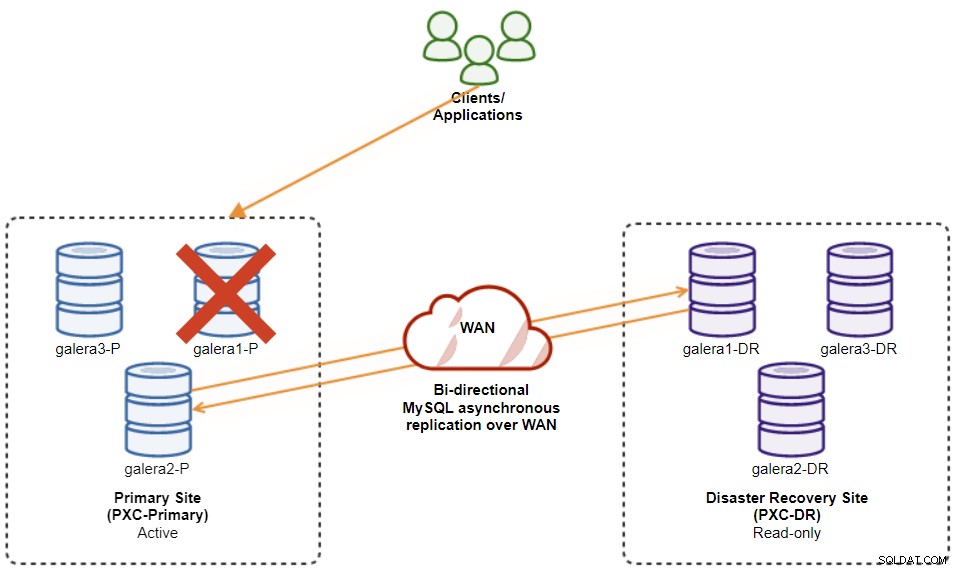
Caso o mestre atual (galera1-P) falhe e os nós restantes no Site Primário ainda estejam ativos, o escravo no site de Recuperação de Desastres (galera1-DR) deve ser direcionado para quaisquer mestres disponíveis no Site Primário, conforme mostrado no diagrama a seguir:
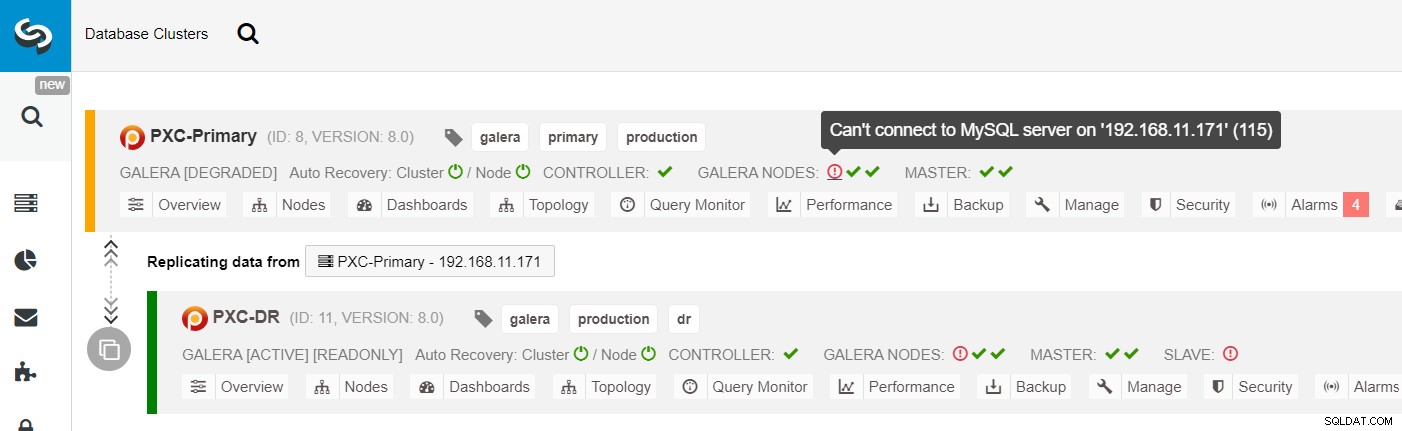
Na lista de clusters ClusterControl, você pode ver que o status do cluster está degradado , e se você rolar sobre o ícone do ponto de exclamação, poderá ver o erro para esse nó específico (galera1-P):
Com o ClusterControl, você pode simplesmente ir para PXC-DR cluster → Nodes → pick galera1-DR → Node Actions → Rebuild Replication Slave, e você verá a seguinte caixa de diálogo de configuração:
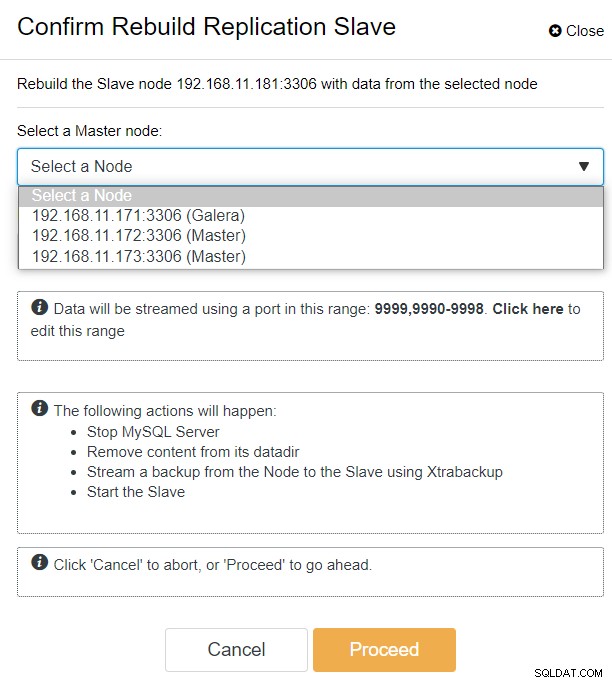
Podemos ver todos os nós Galera no Site Primário (192.168.11.17x ) na lista suspensa. Escolha o nó secundário, 192.168.11.172 (galera2-P), e clique em Continuar. O ClusterControl irá então configurar a topologia de replicação como deve ser, configurando a replicação bidirecional da galera2-P para a galera1-DR. Você pode confirmar isso na página do painel do cluster (destacada em amarelo):
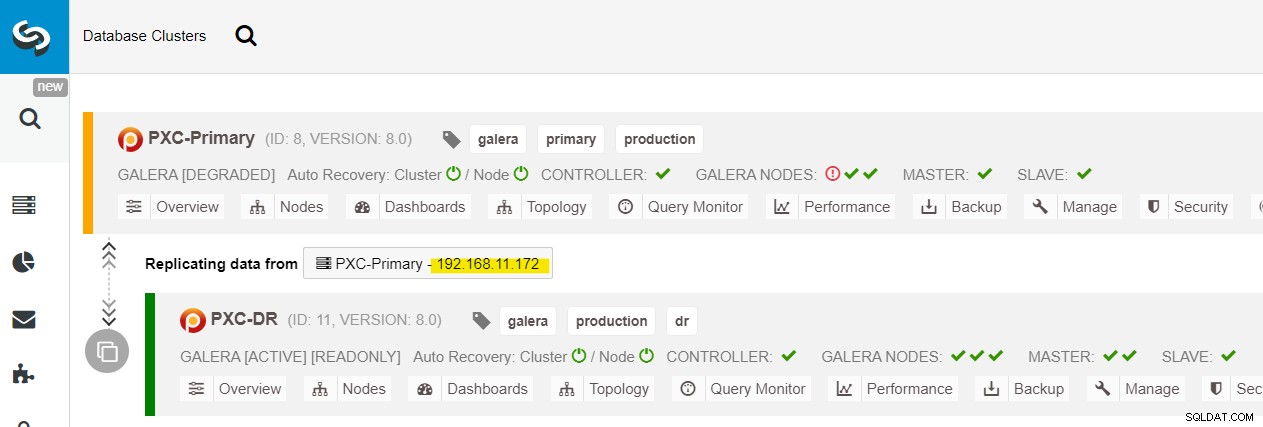
Neste ponto, o cluster primário (PXC-Primary) ainda está servindo como o cluster ativo para esta topologia. Não deve afetar o tempo de atividade do serviço de banco de dados do cluster primário.
Procedimento de failover do cluster do Galera
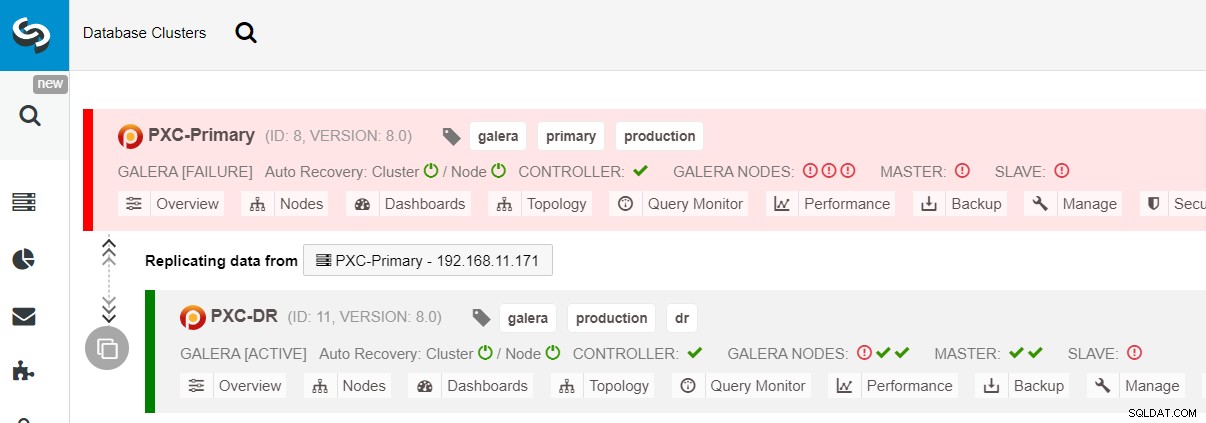
Se o cluster primário ficar inativo, travar ou simplesmente perder a conectividade do ponto de vista do aplicativo, o aplicativo poderá ser direcionado para o site de DR quase instantaneamente. O SysAdmin simplesmente precisa desabilitar somente leitura em todos os nós do Galera no site de recuperação de desastres usando a seguinte instrução:
mysql> SET GLOBAL read_only = 0; -- repeat on galera1-DR, galera2-DR, galera3-DRPara usuários do ClusterControl, você pode usar ClusterControl UI → Nós → escolher o nó do banco de dados → Ações do nó → Desabilitar somente leitura. ClusterControl CLI também está disponível, executando os seguintes comandos no nó ClusterControl:
$ s9s node --nodes="192.168.11.181" --cluster-id=11 --set-read-write
$ s9s node --nodes="192.168.11.182" --cluster-id=11 --set-read-write
$ s9s node --nodes="192.168.11.183" --cluster-id=11 --set-read-writeO failover para o site de DR está concluído e os aplicativos podem começar a enviar gravações para o cluster PXC-DR. Na IU do ClusterControl, você deve ver algo assim:
O diagrama a seguir mostra nossa arquitetura após o failover do aplicativo para o site de DR :
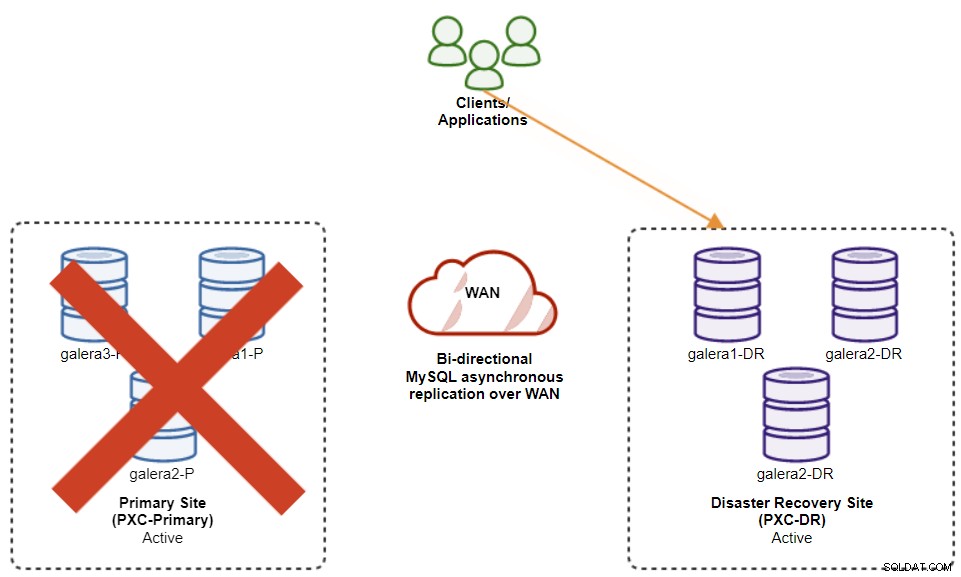
Supondo que o Site Primário ainda esteja inativo, neste momento, não há replicação entre sites até que o Site Primário volte a funcionar.
Procedimento de failback do cluster do Galera
Depois que o site primário for ativado, é importante observar que o cluster primário deve ser definido como somente leitura, para que saibamos que o cluster ativo é aquele no site de recuperação de desastres. No ClusterControl, vá para o menu suspenso do cluster e escolha "Enable Read-only", que habilitará somente leitura em todos os nós do cluster primário e resume a topologia atual conforme abaixo:
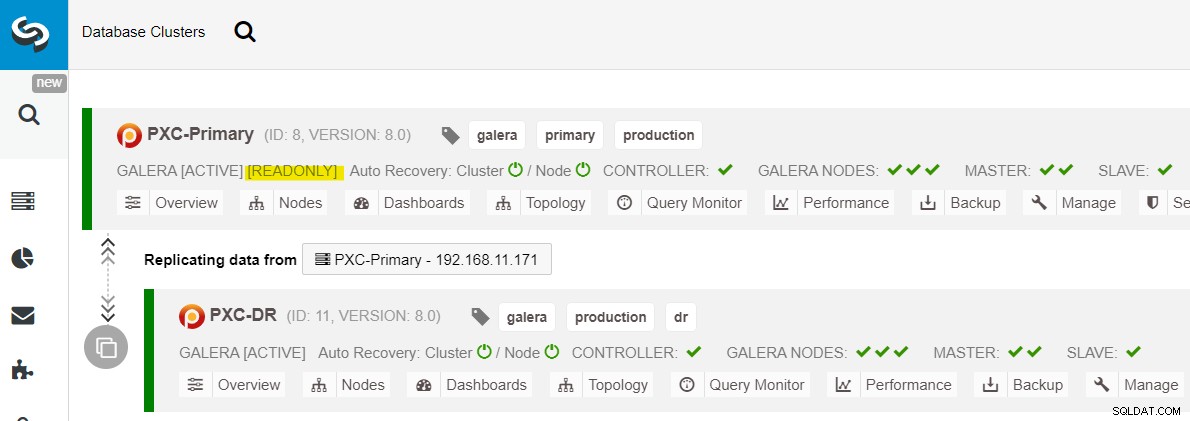
Certifique-se de que tudo esteja verde antes de planejar iniciar o procedimento de failback do cluster (verde significa que todos os nós estão ativos e sincronizados entre si). Se houver um nó em status degradante, por exemplo, o nó de replicação ainda está atrasado ou apenas alguns dos nós do cluster primário foram alcançáveis, espere até que o cluster seja totalmente recuperado, ou aguardando os procedimentos de recuperação automática do ClusterControl para completar, ou intervenção manual.
Neste ponto, o cluster ativo ainda é o cluster do DR, e o cluster primário está agindo como um cluster secundário. O diagrama a seguir ilustra a arquitetura atual:
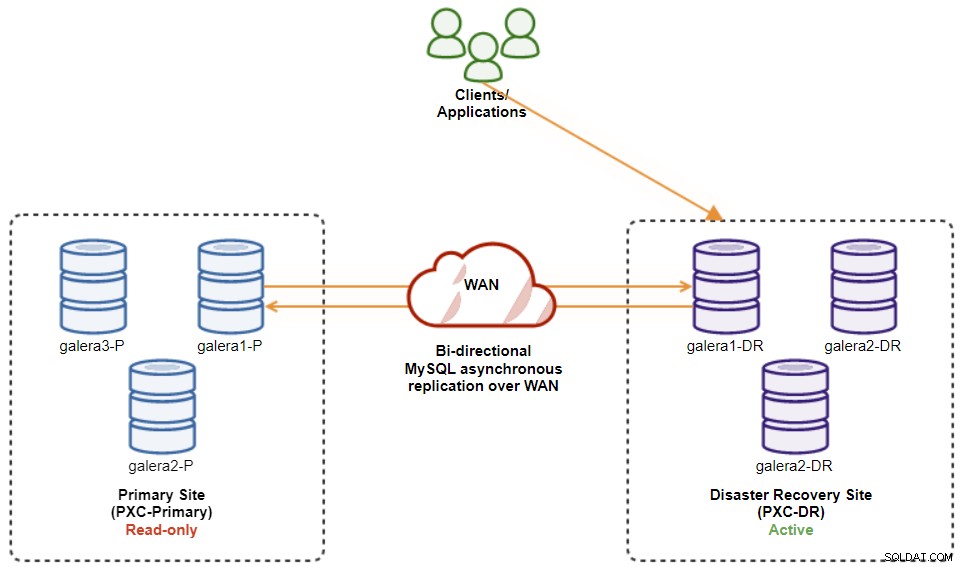
A maneira mais segura de fazer failback para o Site Primário é definir somente leitura no cluster do DR, seguido pela desabilitação de somente leitura no Site Primário. Vá para ClusterControl UI → PXC-DR (menu suspenso) → Habilitar somente leitura. Isso acionará um trabalho para definir somente leitura em todos os nós no cluster do DR. Em seguida, vá para ClusterControl UI → PXC-Primary → Nodes e desative somente leitura em todos os nós de banco de dados no cluster primário.
Você também pode simplificar os procedimentos acima com o ClusterControl CLI. Como alternativa, execute os seguintes comandos no host ClusterControl:
$ s9s cluster --cluster-id=11 --set-read-only # enable cluster-wide read-only
$ s9s node --nodes="192.168.11.171" --cluster-id=8 --set-read-write
$ s9s node --nodes="192.168.11.172" --cluster-id=8 --set-read-write
$ s9s node --nodes="192.168.11.173" --cluster-id=8 --set-read-writeUma vez feito, a direção de replicação voltou para sua configuração original, onde PXC-Primary é o cluster ativo e PXC-DR é o cluster em espera. O diagrama a seguir ilustra a arquitetura final após a operação de failback do cluster:
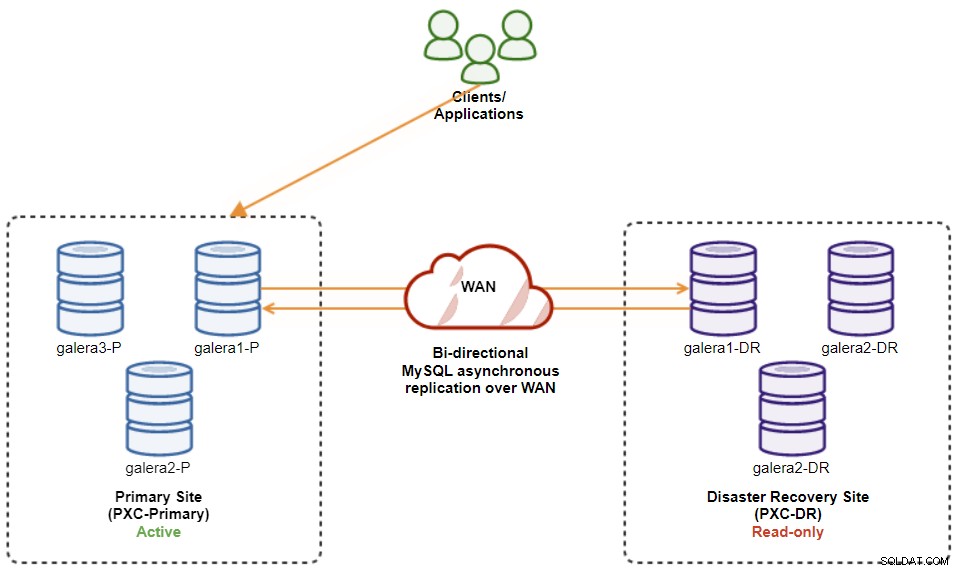
Neste ponto, agora é seguro redirecionar os aplicativos para gravação o Sítio Primário.
Vantagens da replicação assíncrona cluster a cluster
Cluster-to-cluster com replicação assíncrona vem com várias vantagens:
-
Mínimo tempo de inatividade durante uma operação de failover de banco de dados. Basicamente, você pode redirecionar a gravação quase instantaneamente para o site escravo, apenas se puder proteger as gravações para não atingir o site mestre (já que essas gravações não seriam replicadas e provavelmente serão substituídas ao sincronizar novamente do site de DR).
-
Sem impacto de desempenho no site primário, pois ele é independente do site de backup (DR). A replicação do mestre para o escravo é realizada de forma assíncrona. O site mestre gera logs binários, o site escravo replica os eventos e aplica os eventos posteriormente.
-
Os sites de recuperação de desastres podem ser usados para outros fins, por exemplo, backup de banco de dados, backup de log binário e relatórios, ou consultas analíticas pesadas (OLAP). Ambos os sites podem ser usados simultaneamente, exceto pelo atraso de replicação e operações somente leitura no lado escravo.
-
O cluster de DR pode ser executado em instâncias menores em um ambiente de nuvem pública, desde que possam acompanhar com o cluster primário. Você pode atualizar as instâncias, se necessário. Em certos cenários, você pode economizar alguns custos.
-
Você só precisa de um site extra para recuperação de desastres em comparação com a configuração de replicação multissite ativo-ativo do Galera, que requer pelo menos três sites ativos para funcionar corretamente.
Desvantagens da replicação assíncrona cluster a cluster
Também há desvantagens nessa configuração, dependendo se você estiver usando replicação bidirecional ou unidirecional:
-
Há uma chance de perder alguns dados durante o failover se o escravo estiver atrasado, pois a replicação é assíncrona. Isso pode ser melhorado com replicação de escravos semi-síncrona e multi-thread, embora haja outro conjunto de desafios em espera (sobrecarga de rede, lacuna de replicação etc.).
-
Na replicação unidirecional, apesar dos procedimentos de failover serem bastante simples, os procedimentos de failback podem ser complicados e propensos a erros humanos erro. Requer alguma experiência em mudar a função de mestre/escravo de volta para o site primário. É recomendável manter os procedimentos documentados, ensaiar a operação de failover/failback regularmente e usar ferramentas de monitoramento e relatórios precisos.
-
Pode ser bastante caro, pois você precisa configurar um número semelhante de nós no site de recuperação de desastres . Isso não é preto no branco, pois a justificativa de custo geralmente vem dos requisitos do seu negócio. Com algum planejamento, é possível maximizar o uso dos recursos do banco de dados em ambos os sites, independentemente das funções do banco de dados.
Encerrando
Configurar a replicação assíncrona para seus clusters do MySQL Galera pode ser um processo relativamente simples — contanto que você entenda como lidar adequadamente com falhas no nível do nó e do cluster. Em última análise, as operações de failover e failback são críticas para garantir a integridade dos dados.
Para obter mais dicas sobre como projetar seus Clusters Galera com estratégias de failover e failback em mente, confira este post sobre arquiteturas MySQL para recuperação de desastres. Se você está procurando ajuda para automatizar essas operações, avalie o ClusterControl gratuitamente por 30 dias e siga as etapas deste post.
Não se esqueça de nos seguir no Twitter ou LinkedIn e assinar nosso boletim informativo para ficar atualizado sobre as últimas notícias e práticas recomendadas para gerenciar suas infraestruturas de banco de dados de código aberto.