O ProxySQL geralmente fica entre as camadas do aplicativo e do banco de dados, na chamada camada de proxy reverso. Quando seus contêineres de aplicativos são orquestrados e gerenciados pelo Kubernetes, convém usar o ProxySQL na frente de seus servidores de banco de dados.
Neste post, mostraremos como executar o ProxySQL no Kubernetes como um contêiner auxiliar em um pod. Vamos usar o Wordpress como um aplicativo de exemplo. O serviço de dados é fornecido por nossa Replicação MySQL de dois nós, implantada usando ClusterControl e localizada fora da rede Kubernetes em uma infraestrutura bare-metal, conforme ilustrado no diagrama a seguir:
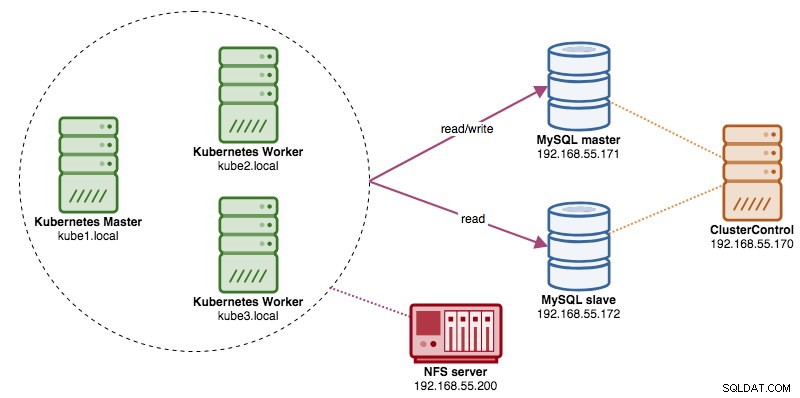
Imagem do Docker ProxySQL
Neste exemplo, usaremos a imagem do ProxySQL Docker mantida por Variousnines, uma imagem pública geral criada para uso multiuso. A imagem não vem com nenhum script de ponto de entrada e suporta Galera Cluster (além do suporte integrado para MySQL Replication), onde um script extra é necessário para fins de verificação de integridade.
Basicamente, para executar um container ProxySQL, basta executar o seguinte comando:
$ docker run -d -v /path/to/proxysql.cnf:/etc/proxysql.cnf severalnines/proxysqlEsta imagem recomenda que você vincule um arquivo de configuração do ProxySQL ao ponto de montagem, /etc/proxysql.cnf, embora você possa ignorar isso e configurá-lo posteriormente usando o console de administração do ProxySQL. As configurações de exemplo são fornecidas na página do Docker Hub ou na página do Github.
ProxySQL no Kubernetes
Projetar a arquitetura do ProxySQL é um tópico subjetivo e altamente dependente do posicionamento do aplicativo e dos contêineres do banco de dados, bem como da função do próprio ProxySQL. O ProxySQL não apenas roteia consultas, mas também pode ser usado para reescrever e armazenar em cache as consultas. Acertos de cache eficientes podem exigir uma configuração personalizada adaptada especificamente para a carga de trabalho do banco de dados do aplicativo.
Idealmente, podemos configurar o ProxySQL para ser gerenciado pelo Kubernetes com duas configurações:
- ProxySQL como um serviço Kubernetes (implantação centralizada).
- ProxySQL como um contêiner auxiliar em um pod (implantação distribuída).
A primeira opção é bem direta, onde criamos um pod ProxySQL e anexamos um serviço Kubernetes a ele. Os aplicativos se conectarão ao serviço ProxySQL por meio de rede nas portas configuradas. O padrão é 6033 para a porta com balanceamento de carga do MySQL e 6032 para a porta de administração do ProxySQL. Essa implantação será abordada na próxima postagem do blog.
A segunda opção é um pouco diferente. O Kubernetes tem um conceito chamado "pod". Você pode ter um ou mais contêineres por pod, eles são relativamente bem acoplados. O conteúdo de um pod é sempre co-localizado e co-agendado e executado em um contexto compartilhado. Um pod é a menor unidade de contêiner gerenciável no Kubernetes.
Ambas as implantações podem ser distinguidas facilmente observando o diagrama a seguir:
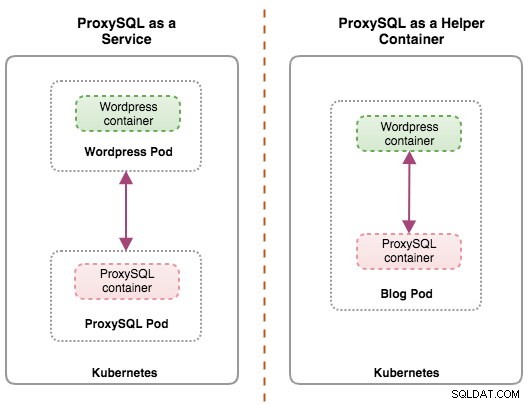
A principal razão pela qual os pods podem ter vários contêineres é oferecer suporte a aplicativos auxiliares que auxiliam um aplicativo principal. Exemplos típicos de aplicativos auxiliares são extratores de dados, pushers de dados e proxies. Os aplicativos auxiliares e primários geralmente precisam se comunicar entre si. Normalmente, isso é feito por meio de um sistema de arquivos compartilhado, conforme mostrado neste exercício, ou por meio da interface de rede de loopback, localhost. Um exemplo desse padrão é um servidor web junto com um programa auxiliar que pesquisa um repositório Git para novas atualizações.
Esta postagem de blog abordará a segunda configuração - executar o ProxySQL como um contêiner auxiliar em um pod.
ProxySQL como auxiliar em um pod
Nesta configuração, executamos o ProxySQL como um contêiner auxiliar para nosso contêiner do Wordpress. O diagrama a seguir ilustra nossa arquitetura de alto nível:
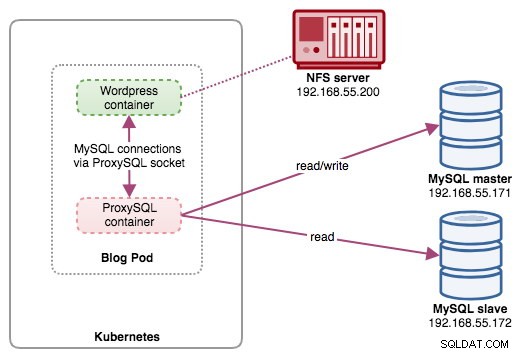
Nesta configuração, o contêiner ProxySQL está fortemente acoplado ao contêiner do Wordpress e o nomeamos como pod "blog". Se o reagendamento acontecer, por exemplo, o nó do trabalhador do Kubernetes ficar inativo, esses dois contêineres sempre serão reprogramados juntos como uma unidade lógica no próximo host disponível. Para manter o conteúdo dos contêineres do aplicativo persistente em vários nós, temos que usar um sistema de arquivos em cluster ou remoto, que neste caso é o NFS.
A função do ProxySQL é fornecer uma camada de abstração de banco de dados para o contêiner do aplicativo. Como estamos executando uma Replicação MySQL de dois nós como serviço de banco de dados de back-end, a divisão de leitura-gravação é vital para maximizar o consumo de recursos em ambos os servidores MySQL. O ProxySQL é excelente nisso e requer poucas ou nenhuma alteração no aplicativo.
Há vários outros benefícios executando o ProxySQL nesta configuração:
- Traga o recurso de cache de consulta mais próximo da camada de aplicativo em execução no Kubernetes.
- Implementação segura conectando-se por meio do arquivo de soquete ProxySQL UNIX. É como um pipe que o servidor e os clientes podem usar para conectar e trocar solicitações e dados.
- Nível de proxy reverso distribuído com arquitetura sem compartilhamento.
- Menos sobrecarga de rede devido à implementação de "pular rede".
- Abordagem de implantação sem estado usando ConfigMaps do Kubernetes.
Preparando o banco de dados
Crie o banco de dados wordpress e o usuário no mestre e atribua com o privilégio correto:
mysql-master> CREATE DATABASE wordpress;
mysql-master> CREATE USER example@sqldat.com'%' IDENTIFIED BY 'passw0rd';
mysql-master> GRANT ALL PRIVILEGES ON wordpress.* TO example@sqldat.com'%';Além disso, crie o usuário de monitoramento ProxySQL:
mysql-master> CREATE USER example@sqldat.com'%' IDENTIFIED BY 'proxysqlpassw0rd';Em seguida, recarregue a tabela de concessões:
mysql-master> FLUSH PRIVILEGES;Preparando o Pod
Agora, copie e cole as seguintes linhas em um arquivo chamado blog-deployment.yml no host onde o kubectl está configurado:
apiVersion: apps/v1
kind: Deployment
metadata:
name: blog
labels:
app: blog
spec:
replicas: 1
selector:
matchLabels:
app: blog
tier: frontend
strategy:
type: RollingUpdate
template:
metadata:
labels:
app: blog
tier: frontend
spec:
restartPolicy: Always
containers:
- image: wordpress:4.9-apache
name: wordpress
env:
- name: WORDPRESS_DB_HOST
value: localhost:/tmp/proxysql.sock
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-pass
key: password
ports:
- containerPort: 80
name: wordpress
volumeMounts:
- name: wordpress-persistent-storage
mountPath: /var/www/html
- name: shared-data
mountPath: /tmp
- image: severalnines/proxysql
name: proxysql
volumeMounts:
- name: proxysql-config
mountPath: /etc/proxysql.cnf
subPath: proxysql.cnf
- name: shared-data
mountPath: /tmp
volumes:
- name: wordpress-persistent-storage
persistentVolumeClaim:
claimName: wp-pv-claim
- name: proxysql-config
configMap:
name: proxysql-configmap
- name: shared-data
emptyDir: {}O arquivo YAML tem muitas linhas e vamos ver apenas a parte interessante. A primeira seção:
apiVersion: apps/v1
kind: DeploymentA primeira linha é a apiVersion. Nosso cluster Kubernetes está sendo executado na v1.12, portanto, devemos consultar a documentação da API Kubernetes v1.12 e seguir a declaração do recurso de acordo com essa API. O próximo é o tipo, que informa que tipo de recurso queremos implantar. Deployment, Service, ReplicaSet, DaemonSet, PersistentVolume são alguns dos exemplos.
A próxima seção importante é a seção "contêineres". Aqui definimos todos os contêineres que gostaríamos de executar juntos neste pod. A primeira parte é o contêiner do Wordpress:
- image: wordpress:4.9-apache
name: wordpress
env:
- name: WORDPRESS_DB_HOST
value: localhost:/tmp/proxysql.sock
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-pass
key: password
ports:
- containerPort: 80
name: wordpress
volumeMounts:
- name: wordpress-persistent-storage
mountPath: /var/www/html
- name: shared-data
mountPath: /tmpNesta seção, estamos dizendo ao Kubernetes para implantar o Wordpress 4.9 usando o servidor web Apache e demos ao contêiner o nome "wordpress". Também queremos que o Kubernetes passe várias variáveis de ambiente:
- WORDPRESS_DB_HOST - O host do banco de dados. Como nosso contêiner ProxySQL reside no mesmo Pod com o contêiner Wordpress, é mais seguro usar um arquivo de soquete ProxySQL. O formato para usar o arquivo de soquete no Wordpress é "localhost:{caminho para o arquivo de soquete}". Por padrão, ele está localizado no diretório /tmp do contêiner ProxySQL. Esse caminho /tmp é compartilhado entre os contêineres Wordpress e ProxySQL usando volumeMounts de "dados compartilhados", conforme mostrado mais abaixo. Ambos os contêineres precisam montar esse volume para compartilhar o mesmo conteúdo no diretório /tmp.
- WORDPRESS_DB_USER - Especifique o usuário do banco de dados wordpress.
- WORDPRESS_DB_PASSWORD - A senha para WORDPRESS_DB_USER . Como não queremos expor a senha neste arquivo, podemos ocultá-la usando o Kubernetes Secrets. Aqui instruímos o Kubernetes a ler o recurso secreto "mysql-pass". Os segredos precisam ser criados com antecedência antes da implantação do pod, conforme explicado mais abaixo.
Também queremos publicar a porta 80 do contêiner para o usuário final. O conteúdo do Wordpress armazenado em /var/www/html no container será montado em nosso armazenamento persistente rodando em NFS.
Em seguida, definimos o contêiner ProxySQL:
- image: severalnines/proxysql:1.4.12
name: proxysql
volumeMounts:
- name: proxysql-config
mountPath: /etc/proxysql.cnf
subPath: proxysql.cnf
- name: shared-data
mountPath: /tmp
ports:
- containerPort: 6033
name: proxysqlNa seção acima, estamos dizendo ao Kubernetes para implantar um ProxySQL usando severalnines/proxysql versão da imagem 1.4.12. Também queremos que o Kubernetes monte nosso arquivo de configuração personalizado e pré-configurado e o mapeie para /etc/proxysql.cnf dentro do contêiner. Haverá um volume chamado "shared-data" que mapeia para o diretório /tmp para compartilhar com a imagem do Wordpress - um diretório temporário que compartilha a vida útil de um pod. Isso permite que o arquivo de soquete ProxySQL (/tmp/proxysql.sock) seja usado pelo contêiner do Wordpress ao se conectar ao banco de dados, ignorando a rede TCP/IP.
A última parte é a seção "volumes":
volumes:
- name: wordpress-persistent-storage
persistentVolumeClaim:
claimName: wp-pv-claim
- name: proxysql-config
configMap:
name: proxysql-configmap
- name: shared-data
emptyDir: {}O Kubernetes terá que criar três volumes para este pod:
- wordpress-persistent-storage - Use o PersistentVolumeClaim recurso para mapear a exportação NFS para o contêiner para armazenamento de dados persistentes para conteúdo do Wordpress.
- proxysql-config - Use o ConfigMap recurso para mapear o arquivo de configuração do ProxySQL.
- shared-data - Use o emptyDir resource para montar um diretório compartilhado para nossos contêineres dentro do Pod. emptyDir resource é um diretório temporário que compartilha o tempo de vida de um pod.
Portanto, com base em nossa definição de YAML acima, precisamos preparar vários recursos do Kubernetes antes de começar a implantar o pod "blog":
- Volume Persistente e PersistentVolumeClaim - Para armazenar o conteúdo da web do nosso aplicativo Wordpress, para que quando o pod estiver sendo reprogramado para outro nó de trabalho, não percamos as últimas alterações.
- Segredos - Para ocultar a senha do usuário do banco de dados Wordpress dentro do arquivo YAML.
- ConfigMap - Para mapear o arquivo de configuração para o contêiner ProxySQL, para que quando ele estiver sendo reprogramado para outro nó, o Kubernetes possa remontá-lo automaticamente.
PersistentVolume e PersistentVolumeClaim
Um bom armazenamento persistente para Kubernetes deve ser acessível por todos os nós Kubernetes no cluster. Para esta postagem do blog, usamos o NFS como o provedor PersistentVolume (PV) porque é fácil e com suporte pronto para uso. O servidor NFS está localizado em algum lugar fora da nossa rede Kubernetes e nós o configuramos para permitir todos os nós Kubernetes com a seguinte linha dentro de /etc/exports:
/nfs 192.168.55.*(rw,sync,no_root_squash,no_all_squash)Observe que o pacote do cliente NFS deve ser instalado em todos os nós do Kubernetes. Caso contrário, o Kubernetes não poderá montar o NFS corretamente. Em todos os nós:
$ sudo apt-install nfs-common #Ubuntu/Debian
$ yum install nfs-utils #RHEL/CentOSAlém disso, verifique se no servidor NFS existe o diretório de destino:
(nfs-server)$ mkdir /nfs/kubernetes/wordpressEm seguida, crie um arquivo chamado wordpress-pv-pvc.yml e adicione as seguintes linhas:
apiVersion: v1
kind: PersistentVolume
metadata:
name: wp-pv
labels:
app: blog
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 3Gi
mountOptions:
- hard
- nfsvers=4.1
nfs:
path: /nfs/kubernetes/wordpress
server: 192.168.55.200
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: wp-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi
selector:
matchLabels:
app: blog
tier: frontendNa definição acima, gostaríamos que o Kubernetes alocasse 3 GB de espaço de volume no servidor NFS para nosso contêiner Wordpress. Anote o uso de produção, o NFS deve ser configurado com provisionador automático e classe de armazenamento.
Crie os recursos PV e PVC:
$ kubectl create -f wordpress-pv-pvc.ymlVerifique se esses recursos foram criados e o status deve ser "Ligado":
$ kubectl get pv,pvc
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/wp-pv 3Gi RWO Recycle Bound default/wp-pvc 22h
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/wp-pvc Bound wp-pv 3Gi RWO 22hSegredos
A primeira é criar um segredo para ser usado pelo container Wordpress para WORDPRESS_DB_PASSWORD variável de ambiente. A razão é simplesmente porque não queremos expor a senha em texto não criptografado dentro do arquivo YAML.
Crie um recurso secreto chamado mysql-pass e passe a senha de acordo:
$ kubectl create secret generic mysql-pass --from-literal=password=passw0rdVerifique se nosso segredo foi criado:
$ kubectl get secrets mysql-pass
NAME TYPE DATA AGE
mysql-pass Opaque 1 7h12mConfigMap
Também precisamos criar um recurso ConfigMap para nosso contêiner ProxySQL. Um arquivo ConfigMap do Kubernetes contém pares de chave-valor de dados de configuração que podem ser consumidos em pods ou usados para armazenar dados de configuração. Os ConfigMaps permitem dissociar os artefatos de configuração do conteúdo da imagem para manter os aplicativos em contêiner portáteis.
Como nosso servidor de banco de dados já está sendo executado em servidores bare-metal com um nome de host e endereço IP estáticos, além de nome de usuário e senha de monitoramento estático, neste caso de uso, o arquivo ConfigMap armazenará informações de configuração pré-configuradas sobre o serviço ProxySQL que queremos usar.
Primeiro crie um arquivo de texto chamado proxysql.cnf e adicione as seguintes linhas:
datadir="/var/lib/proxysql"
admin_variables=
{
admin_credentials="admin:adminpassw0rd"
mysql_ifaces="0.0.0.0:6032"
refresh_interval=2000
}
mysql_variables=
{
threads=4
max_connections=2048
default_query_delay=0
default_query_timeout=36000000
have_compress=true
poll_timeout=2000
interfaces="0.0.0.0:6033;/tmp/proxysql.sock"
default_schema="information_schema"
stacksize=1048576
server_version="5.1.30"
connect_timeout_server=10000
monitor_history=60000
monitor_connect_interval=200000
monitor_ping_interval=200000
ping_interval_server_msec=10000
ping_timeout_server=200
commands_stats=true
sessions_sort=true
monitor_username="proxysql"
monitor_password="proxysqlpassw0rd"
}
mysql_servers =
(
{ address="192.168.55.171" , port=3306 , hostgroup=10, max_connections=100 },
{ address="192.168.55.172" , port=3306 , hostgroup=10, max_connections=100 },
{ address="192.168.55.171" , port=3306 , hostgroup=20, max_connections=100 },
{ address="192.168.55.172" , port=3306 , hostgroup=20, max_connections=100 }
)
mysql_users =
(
{ username = "wordpress" , password = "passw0rd" , default_hostgroup = 10 , active = 1 }
)
mysql_query_rules =
(
{
rule_id=100
active=1
match_pattern="^SELECT .* FOR UPDATE"
destination_hostgroup=10
apply=1
},
{
rule_id=200
active=1
match_pattern="^SELECT .*"
destination_hostgroup=20
apply=1
},
{
rule_id=300
active=1
match_pattern=".*"
destination_hostgroup=10
apply=1
}
)
mysql_replication_hostgroups =
(
{ writer_hostgroup=10, reader_hostgroup=20, comment="MySQL Replication 5.7" }
)Preste atenção extra às seções "mysql_servers" e "mysql_users", onde você pode precisar modificar os valores para se adequar à configuração do cluster do banco de dados. Nesse caso, temos dois servidores de banco de dados em execução no MySQL Replication, conforme resumido na captura de tela da Topologia a seguir, tirada do ClusterControl:
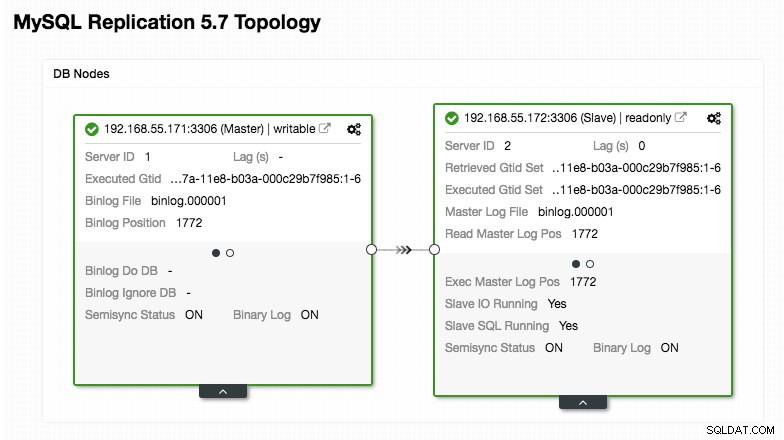
Todas as gravações devem ir para o nó mestre enquanto as leituras são encaminhadas para o hostgroup 20, conforme definido na seção "mysql_query_rules". Esse é o básico da divisão de leitura/gravação e queremos utilizá-los completamente.
Em seguida, importe o arquivo de configuração para o ConfigMap:
$ kubectl create configmap proxysql-configmap --from-file=proxysql.cnf
configmap/proxysql-configmap createdVerifique se o ConfigMap está carregado no Kubernetes:
$ kubectl get configmap
NAME DATA AGE
proxysql-configmap 1 45sImplantando o pod
Agora devemos estar prontos para implantar o pod de blog. Envie o job de implantação para o Kubernetes:
$ kubectl create -f blog-deployment.ymlVerifique o status do pod:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
blog-54755cbcb5-t4cb7 2/2 Running 0 100sEle deve mostrar 2/2 na coluna READY, indicando que há dois contêineres sendo executados dentro do pod. Use o sinalizador de opção -c para verificar os contêineres Wordpress e ProxySQL dentro do pod de blog:
$ kubectl logs blog-54755cbcb5-t4cb7 -c wordpress
$ kubectl logs blog-54755cbcb5-t4cb7 -c proxysqlNo log do contêiner ProxySQL, você deve ver as seguintes linhas:
2018-10-20 08:57:14 [INFO] Dumping current MySQL Servers structures for hostgroup ALL
HID: 10 , address: 192.168.55.171 , port: 3306 , weight: 1 , status: ONLINE , max_connections: 100 , max_replication_lag: 0 , use_ssl: 0 , max_latency_ms: 0 , comment:
HID: 10 , address: 192.168.55.172 , port: 3306 , weight: 1 , status: OFFLINE_HARD , max_connections: 100 , max_replication_lag: 0 , use_ssl: 0 , max_latency_ms: 0 , comment:
HID: 20 , address: 192.168.55.171 , port: 3306 , weight: 1 , status: ONLINE , max_connections: 100 , max_replication_lag: 0 , use_ssl: 0 , max_latency_ms: 0 , comment:
HID: 20 , address: 192.168.55.172 , port: 3306 , weight: 1 , status: ONLINE , max_connections: 100 , max_replication_lag: 0 , use_ssl: 0 , max_latency_ms: 0 , comment:O HID 10 (writer hostgroup) deve ter apenas um nó ONLINE (indicando um único mestre) e o outro host deve estar pelo menos no status OFFLINE_HARD. Para HID 20, espera-se que esteja ONLINE para todos os nós (indicando várias réplicas de leitura).
Para obter um resumo da implantação, use o sinalizador de descrição:
$ kubectl describe deployments blogNosso blog já está rodando, porém não podemos acessá-lo de fora da rede Kubernetes sem configurar o serviço, conforme explicado na próxima seção.
Criando o serviço de blog
A última etapa é criar um serviço anexado ao nosso pod. Isso para garantir que nosso pod de blog Wordpress seja acessível do mundo exterior. Crie um arquivo chamado blog-svc.yml e cole a seguinte linha:
apiVersion: v1
kind: Service
metadata:
name: blog
labels:
app: blog
tier: frontend
spec:
type: NodePort
ports:
- name: blog
nodePort: 30080
port: 80
selector:
app: blog
tier: frontendCrie o serviço:
$ kubectl create -f blog-svc.ymlVerifique se o serviço foi criado corretamente:
example@sqldat.com:~/proxysql-blog# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
blog NodePort 10.96.140.37 <none> 80:30080/TCP 26s
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 43hA porta 80 publicada pelo pod de blog agora está mapeada para o mundo exterior através da porta 30080. Podemos acessar nossa postagem de blog em https://{any_kubernetes_host}:30080/ e devemos ser redirecionados para a página de instalação do Wordpress. Se continuarmos com a instalação, ele pularia a parte de conexão do banco de dados e mostraria diretamente esta página:
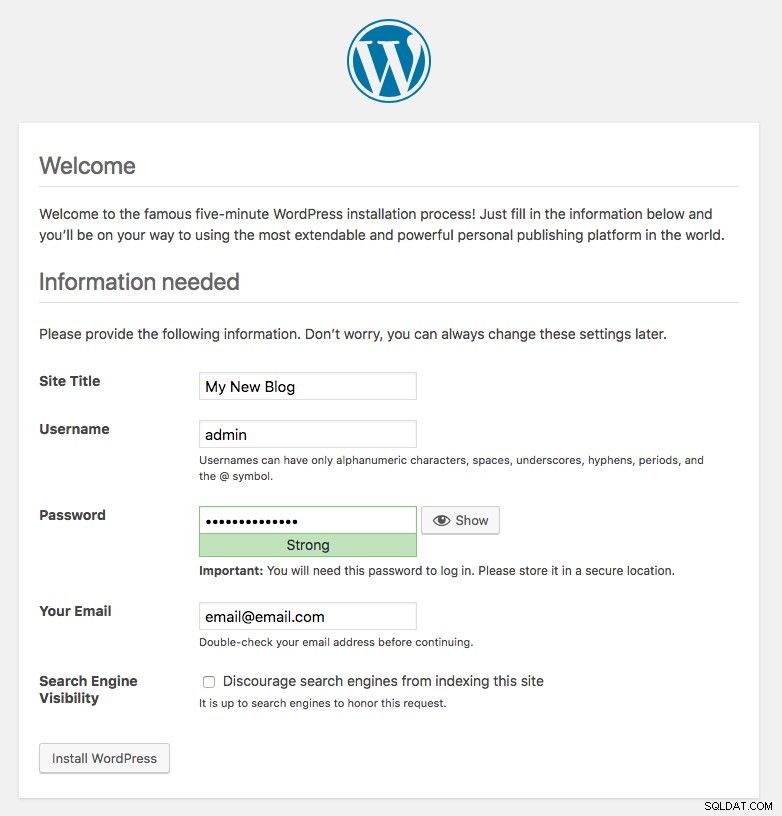
Indica que nossa configuração MySQL e ProxySQL está configurada corretamente dentro do arquivo wp-config.php. Caso contrário, você será redirecionado para a página de configuração do banco de dados.
Nossa implantação está concluída.
Gerenciando o contêiner ProxySQL dentro de um pod
Espera-se que o failover e a recuperação sejam tratados automaticamente pelo Kubernetes. Por exemplo, se o trabalhador do Kubernetes ficar inativo, o pod será recriado no próximo nó disponível após --pod-eviction-timeout (o padrão é 5 minutos). Se o contêiner travar ou for morto, o Kubernetes o substituirá quase instantaneamente.
Espera-se que algumas tarefas comuns de gerenciamento sejam diferentes ao serem executadas no Kubernetes, conforme mostrado nas próximas seções.
Escalando para cima e para baixo
Na configuração acima, estávamos implantando uma réplica em nossa implantação. Para ampliar, basta alterar o spec.replicas valor de acordo usando o comando kubectl edit:
$ kubectl edit deployment blogEle abrirá a definição de implantação em um arquivo de texto padrão e simplesmente alterará o spec.replicas valor para algo maior, por exemplo, "réplicas:3". Em seguida, salve o arquivo e verifique imediatamente o status de distribuição usando o seguinte comando:
$ kubectl rollout status deployment blog
Waiting for deployment "blog" rollout to finish: 1 of 3 updated replicas are available...
Waiting for deployment "blog" rollout to finish: 2 of 3 updated replicas are available...
deployment "blog" successfully rolled outNeste ponto, temos três pods de blog (Wordpress + ProxySQL) rodando simultaneamente no Kubernetes:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
blog-54755cbcb5-6fnqn 2/2 Running 0 11m
blog-54755cbcb5-cwpdj 2/2 Running 0 11m
blog-54755cbcb5-jxtvc 2/2 Running 0 22mNeste ponto, nossa arquitetura está mais ou menos assim:
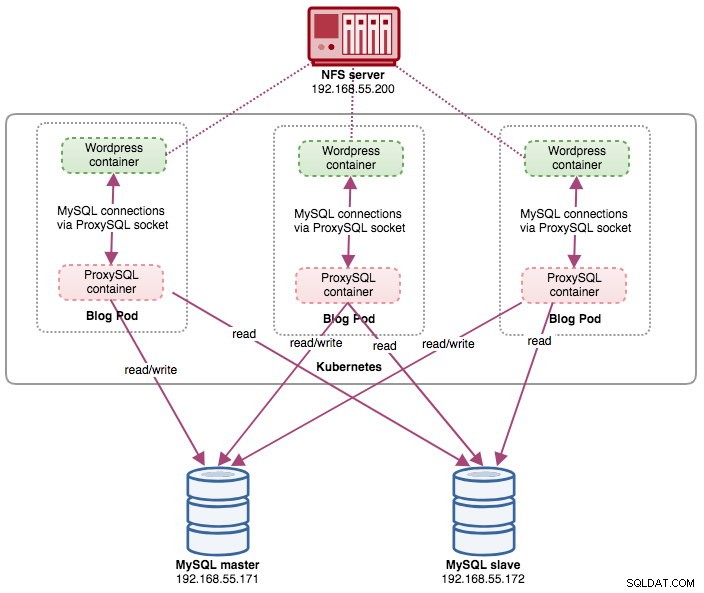
Observe que pode exigir mais personalização do que nossa configuração atual para executar o Wordpress sem problemas em um ambiente de produção em escala horizontal (pense em conteúdo estático, gerenciamento de sessão e outros). Esses estão realmente além do escopo desta postagem no blog.
Os procedimentos de redução são semelhantes.
Gerenciamento de configuração
O gerenciamento de configuração é importante no ProxySQL. É aqui que a mágica acontece, onde você pode definir seu próprio conjunto de regras de consulta para fazer cache de consulta, firewall e reescrita. Ao contrário da prática comum, onde o ProxySQL seria configurado via Admin Console e empurrado para a persistência usando "SAVE .. TO DISK", ficaremos com os arquivos de configuração apenas para tornar as coisas mais portáteis no Kubernetes. Essa é a razão pela qual estamos usando ConfigMaps.
Como contamos com nossa configuração centralizada armazenada pelo Kubernetes ConfigMaps, há várias maneiras de realizar alterações de configuração. Em primeiro lugar, usando o comando de edição kubectl:
$ kubectl edit configmap proxysql-configmapEle abrirá a configuração em um editor de texto padrão e você poderá fazer alterações diretamente nele e salvar o arquivo de texto uma vez feito. Caso contrário, recrie os configmaps também deve fazer:
$ vi proxysql.cnf # edit the configuration first
$ kubectl delete configmap proxysql-configmap
$ kubectl create configmap proxysql-configmap --from-file=proxysql.cnfDepois que a configuração for enviada para o ConfigMap, reinicie o pod ou contêiner conforme mostrado na seção Controle de serviço. A configuração do contêiner por meio da interface de administração do ProxySQL (porta 6032) não o tornará persistente após o reagendamento do pod pelo Kubernetes.
Controle de Serviço
Como os dois contêineres dentro de um pod são fortemente acoplados, a melhor maneira de aplicar as alterações de configuração do ProxySQL é forçar o Kubernetes a fazer a substituição do pod. Considere que estamos tendo três pods de blog agora depois que aumentamos:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
blog-54755cbcb5-6fnqn 2/2 Running 0 31m
blog-54755cbcb5-cwpdj 2/2 Running 0 31m
blog-54755cbcb5-jxtvc 2/2 Running 1 22mUse o seguinte comando para substituir um pod por vez:
$ kubectl get pod blog-54755cbcb5-6fnqn -n default -o yaml | kubectl replace --force -f -
pod "blog-54755cbcb5-6fnqn" deleted
pod/blog-54755cbcb5-6fnqnEm seguida, verifique com o seguinte:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
blog-54755cbcb5-6fnqn 2/2 Running 0 31m
blog-54755cbcb5-cwpdj 2/2 Running 0 31m
blog-54755cbcb5-qs6jm 2/2 Running 1 2m26sVocê notará que o pod mais recente foi reiniciado observando a coluna AGE e RESTART, ele apareceu com um nome de pod diferente. Repita as mesmas etapas para as cápsulas restantes. Caso contrário, você também pode usar o comando "docker kill" para eliminar o contêiner ProxySQL manualmente dentro do nó do trabalhador do Kubernetes. Por exemplo:
(kube-worker)$ docker kill $(docker ps | grep -i proxysql_blog | awk {'print $1'})O Kubernetes substituirá o contêiner ProxySQL morto por um novo.
Monitoramento
Use o comando kubectl exec para executar a instrução SQL via cliente mysql. Por exemplo, para monitorar a digestão de consultas:
$ kubectl exec -it blog-54755cbcb5-29hqt -c proxysql -- mysql -uadmin -p -h127.0.0.1 -P6032
mysql> SELECT * FROM stats_mysql_query_digest;Ou com um one-liner:
$ kubectl exec -it blog-54755cbcb5-29hqt -c proxysql -- mysql -uadmin -p -h127.0.0.1 -P6032 -e 'SELECT * FROM stats_mysql_query_digest'Ao alterar a instrução SQL, você pode monitorar outros componentes do ProxySQL ou realizar qualquer tarefa de administração por meio deste Admin Console. Novamente, ele persistirá apenas durante a vida útil do contêiner ProxySQL e não será persistido se o pod for reprogramado.
Considerações finais
O ProxySQL tem um papel fundamental se você deseja dimensionar seus contêineres de aplicativos e ter uma maneira inteligente de acessar um back-end de banco de dados distribuído. Há várias maneiras de implantar o ProxySQL no Kubernetes para dar suporte ao crescimento de nossos aplicativos ao executar em escala. Este post do blog cobre apenas um deles.
Em uma próxima postagem do blog, veremos como executar o ProxySQL em uma abordagem centralizada usando-o como um serviço do Kubernetes.