Para operar qualquer banco de dados com eficiência, você precisa ter uma visão do desempenho do banco de dados. Isso pode não ser óbvio quando tudo está indo bem, mas assim que algo der errado, o acesso às informações pode ser fundamental para diagnosticar o problema de forma rápida e correta.
Todos os bancos de dados disponibilizam alguns de seus dados de status internos aos usuários. No MySQL, você pode obter esses dados principalmente executando 'SHOW STATUS' e 'SHOW GLOBAL STATUS', executando 'SHOW ENGINE INNODB STATUS', verificando tabelas information_schema e, em versões mais recentes, consultando tabelas performance_schema.

Esses métodos estão longe de ser convenientes nas operações do dia-a-dia, daí a popularidade de diferentes soluções de monitoramento e tendências. Ferramentas como Nagios/Icinga são projetadas para monitorar hosts/serviços e alertar quando um serviço estiver fora de um intervalo aceitável. Outras ferramentas, como Cacti e Munin, fornecem uma visão gráfica das informações de host/serviço e fornecem contexto histórico para desempenho e uso. O ClusterControl combina esses dois tipos de monitoramento, então veremos as informações que ele apresenta e como devemos interpretá-lo.
Se você estiver usando Galera Cluster (MySQL Galera Cluster by Codership ou MariaDB Cluster ou Percona XtraDB Cluster), você deve ter notado a seguinte seção na guia "Visão geral" do ClusterControl:
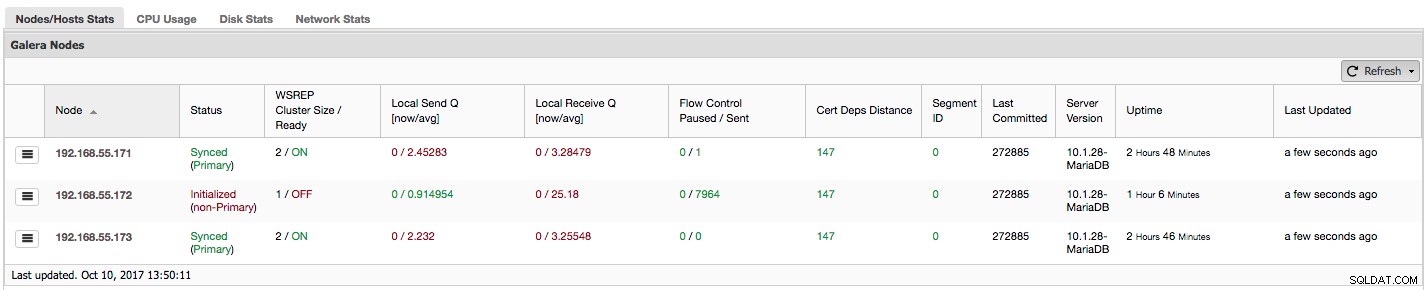
Vamos ver, passo a passo, que tipo de dados temos aqui.
A primeira coluna contém a lista de nós com seus endereços IP - não há muito mais a dizer sobre isso.
A segunda coluna é mais interessante - ela descreve o status do nó (wsrep_local_state_comment status). Um nó pode estar em diferentes estados:
- Inicializado - o nó está funcionando, mas não faz parte de um cluster. Pode ser causado, por exemplo, por problemas de rede;
- Ingressando - O nó está no processo de ingressar no cluster e está recebendo ou solicitando uma transferência de estado de um dos outros nós;
- Doador/Dessincronizado - O nó serve como doador para algum outro nó que está se juntando ao cluster;
- Ingressado - O nó ingressou no cluster, mas está ocupado recuperando os conjuntos de gravação confirmados;
- Sincronizado - O nó está funcionando normalmente.
Na mesma coluna dentro do colchete está o status do cluster (wsrep_cluster_status status). Pode ter três estados distintos:
- Primário - A comunicação entre os nós está funcionando e o quorum está presente (a maioria dos nós está disponível)
- Não primário - o nó fazia parte do cluster, mas, por algum motivo, perdeu contato com o restante do cluster. Como resultado, este nó é considerado inativo e não aceitará consultas
- Desconectado - O nó não pôde estabelecer comunicação em grupo.
"WSREP Cluster Size / Ready" nos informa sobre um tamanho de cluster como o nó o vê e se o nó está pronto para aceitar consultas. Os componentes não primários criam um cluster com tamanho 1 e a prontidão do wsrep está DESATIVADA.
Vamos dar uma olhada na captura de tela acima e ver o que ela está nos dizendo sobre o Galera. Podemos ver três nós. Dois deles (192.168.55.171 e 192.168.55.173) estão perfeitamente bem, ambos estão "Sincronizados" e o cluster está no estado "Primário". O cluster atualmente consiste em dois nós. O nó 192.168.55.172 é "Inicializado" e forma um componente "não primário". Isso significa que esse nó perdeu a conexão com o cluster - provavelmente algum tipo de problema de rede (na verdade, usamos iptables para bloquear um tráfego para esse nó de 192.168.55.171 e 192.168.55.173).
Neste momento temos que parar um pouco e descrever como o Galera Cluster funciona internamente. Não entraremos em muitos detalhes, pois não está no escopo desta postagem do blog, mas é necessário algum conhecimento para entender a importância dos dados apresentados nas próximas colunas.
Galera é um cluster multi-mestre "virtualmente" síncrono. Isso significa que você deve esperar que os dados sejam transferidos entre os nós "virtualmente" ao mesmo tempo (não há mais problemas irritantes com escravos atrasados) e que você pode gravar em qualquer nó em um cluster (não há mais problemas irritantes com a promoção de um escravo para mestre ). Para isso, o Galera usa writesets - conjunto atômico de alterações que são replicadas no cluster. Um conjunto de gravação pode conter várias alterações de linha e informações adicionais necessárias, como dados sobre bloqueio.
Uma vez que um cliente emite COMMIT, mas antes que o MySQL realmente confirme qualquer coisa, um writeset é criado e enviado para todos os nós no cluster para certificação. Todos os nós verificam se é possível confirmar as alterações ou não (pois as alterações podem interferir em outras escritas executadas, entretanto, diretamente em outro nó). Se sim, os dados são realmente confirmados pelo MySQL, se não, o rollback é executado.
O que é importante lembrar é o fato de que os nós, semelhantes aos escravos na replicação regular, podem ter um desempenho diferente - alguns podem ter hardware melhor que outros, alguns podem ser mais carregados que outros. No entanto, o Galera exige que eles processem os conjuntos de gravação de maneira curta e rápida, para manter a sincronização "virtual". Deve haver um mecanismo que possa limitar a replicação e permitir que nós mais lentos acompanhem o resto do cluster.
Vamos dar uma olhada nas colunas "Local Send Q [now/avg]" e "Local Receive Q [now/avg]". Cada nó tem uma fila local para enviar e receber conjuntos de gravação. Ele permite paralelizar algumas das gravações e dados de fila que não podem ser processados de uma só vez se o nó não puder acompanhar o tráfego. Em SHOW GLOBAL STATUS podemos encontrar oito contadores descrevendo ambas as filas, quatro contadores por fila:
- wsrep_local_send_queue - estado atual da fila de envio
- wsrep_local_send_queue_min - mínimo desde FLUSH STATUS
- wsrep_local_send_queue_max - máximo desde FLUSH STATUS
- wsrep_local_send_queue_avg - média desde FLUSH STATUS
- wsrep_local_recv_queue - estado atual da fila de recebimento
- wsrep_local_recv_queue_min - mínimo desde FLUSH STATUS
- wsrep_local_recv_queue_max - máximo desde FLUSH STATUS
- wsrep_local_recv_queue_avg - média desde FLUSH STATUS
As métricas acima são unificadas nos nós em ClusterControl -> Performance -> DB Status:
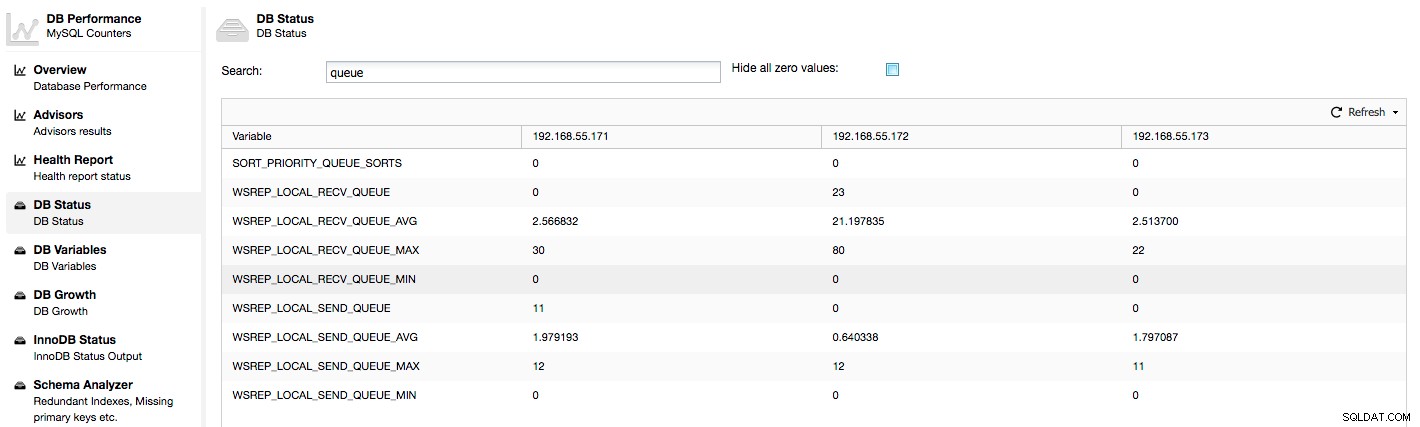
O ClusterControl exibe os contadores "agora" e "média", pois são os mais significativos como um único número (você também pode criar gráficos personalizados com base em variáveis que descrevem o estado atual das filas) . Quando vemos que uma das filas está subindo, isso significa que o nó não pode acompanhar a replicação e outros nós terão que desacelerar para permitir que ele se recupere. Recomendamos investigar uma carga de trabalho desse determinado nó - verifique a lista de processos para algumas consultas de longa duração, verifique as estatísticas do sistema operacional, como utilização da CPU e carga de trabalho de E/S. Talvez também seja possível redistribuir parte do tráfego desse nó para o resto do cluster.
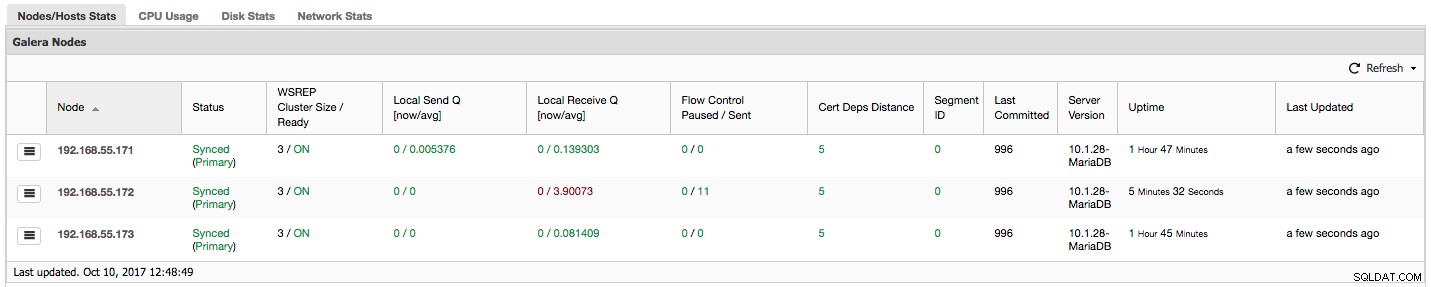
"Controle de fluxo pausado" mostra informações sobre a porcentagem de tempo que um determinado nó teve que pausar sua replicação devido a uma carga muito pesada. Quando um nó não consegue acompanhar a carga de trabalho, ele envia pacotes de controle de fluxo para outros nós, informando que eles devem diminuir o envio de conjuntos de gravação. Em nossa captura de tela, temos o valor de '0,30' para o nó 192.168.55.172. Isso significa que em quase 30% do tempo esse nó teve que pausar a replicação porque não conseguiu acompanhar a taxa de certificação de conjunto de gravações exigida por outros nós (ou, mais simples, muitas gravações o atingiram!). Como podemos ver, "Local Receive Q [avg]" também nos aponta para esse fato.
A próxima coluna, "Flow Control Sent" nos dá informações sobre quantos pacotes de controle de fluxo um determinado nó enviou para o cluster. Novamente, vemos que é o nó 192.168.55.172 que está desacelerando o cluster.
O que podemos fazer com essas informações? Principalmente, devemos investigar o que está acontecendo no nó lento. Verifique a utilização da CPU, verifique o desempenho de E/S e as estatísticas da rede. Este primeiro passo ajuda a avaliar que tipo de problema estamos enfrentando.
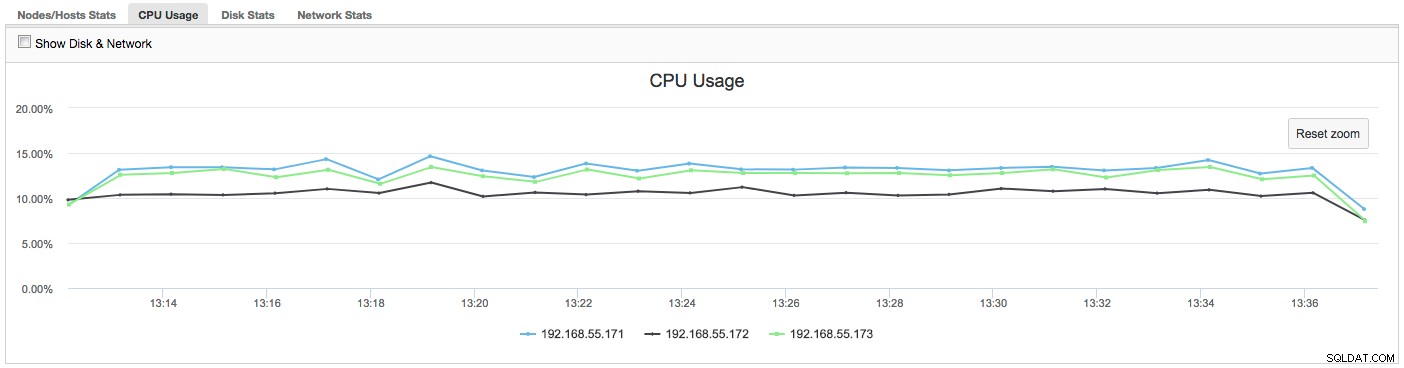
Nesse caso, quando mudamos para a guia Uso da CPU, fica claro que a utilização extensiva da CPU está causando nossos problemas. O próximo passo seria identificar o culpado examinando PROCESSLIST (Query Monitor -> Running Queries -> filter by 192.168.55.172) para verificar as consultas ofensivas:
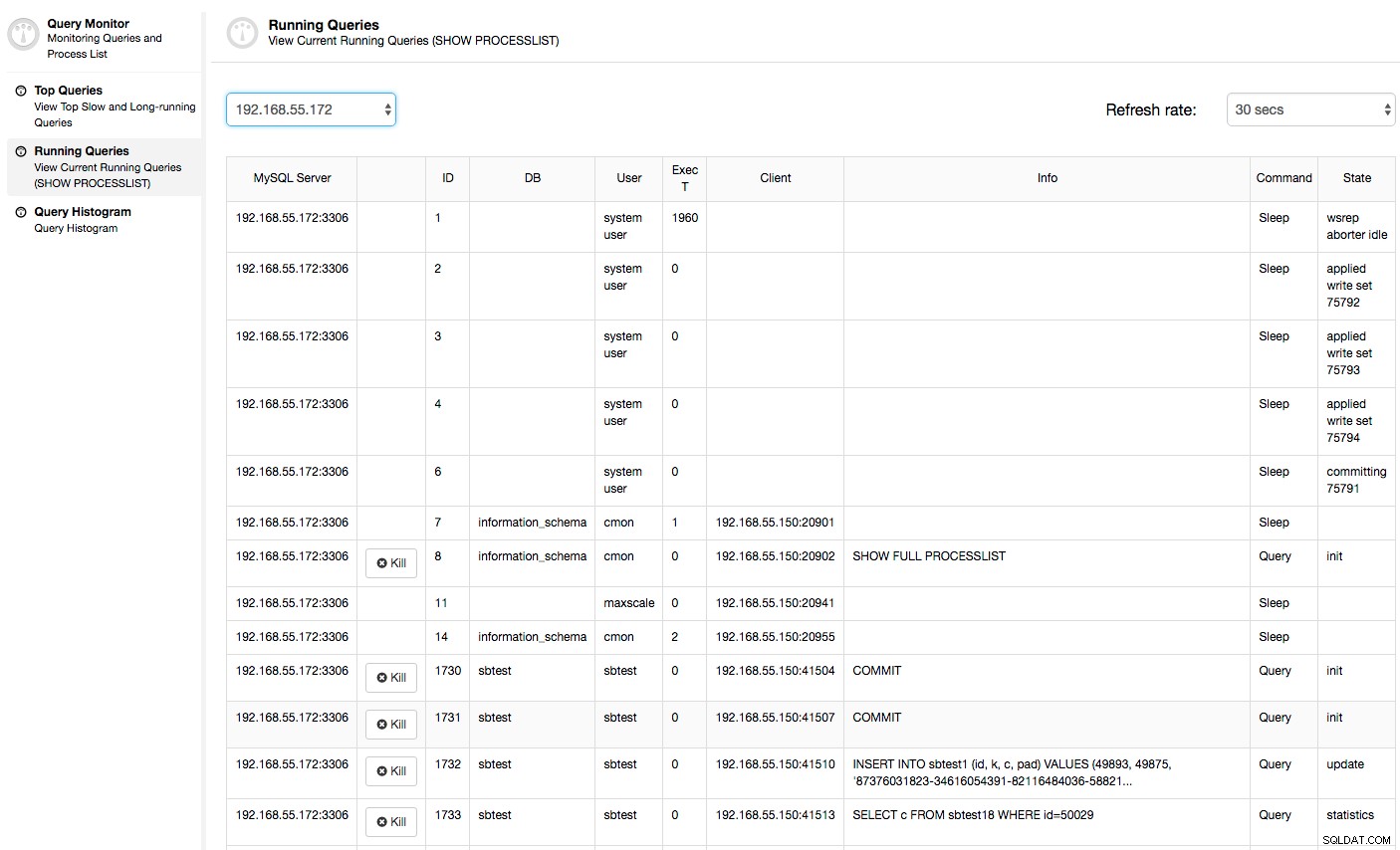
Ou verifique os processos no nó do lado do sistema operacional (Nodes -> 192.168.55.172 -> Top) para ver se a carga não é causada por algo fora do Galera/MySQL.
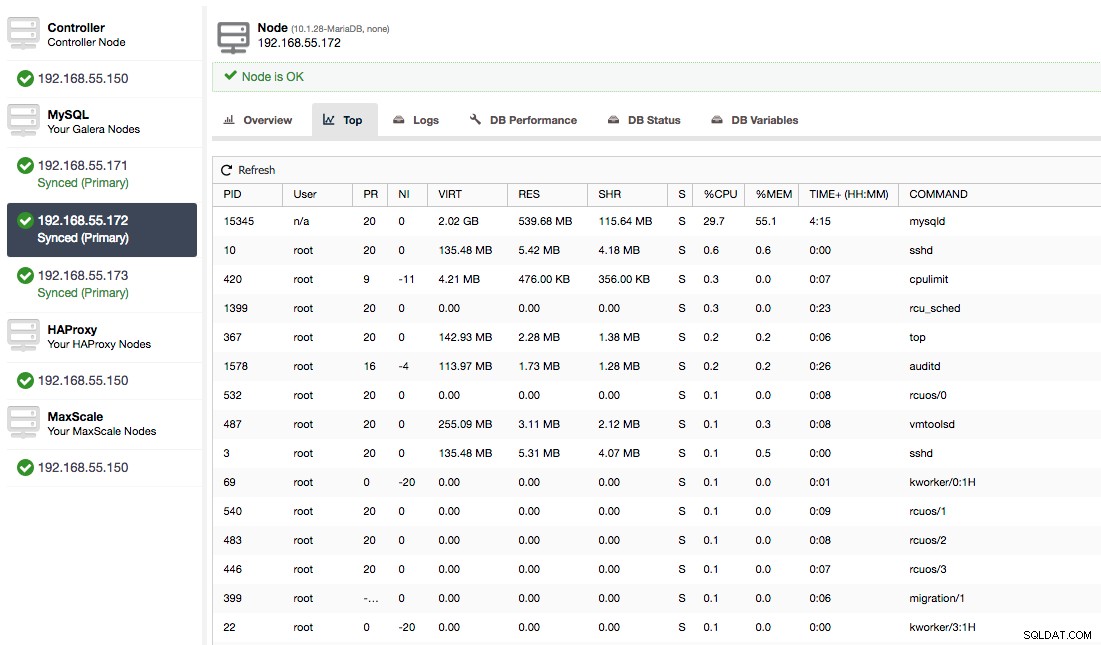
Neste caso, executamos o comando mysqld através do cpulimit, para simular o uso lento da CPU especificamente para o processo mysqld, limitando-o a 30% de 400% da CPU disponível (o servidor possui 4 núcleos).
A coluna "Cert Deps Distance" nos fornece informações sobre quantos conjuntos de gravação, em média, podem ser aplicados em paralelo. Writesets podem, às vezes, ser executados ao mesmo tempo - Galera tira vantagem disso usando vários wsrep_slave_threads para aplicar conjuntos de escrita. Esta coluna dá uma ideia de quantos encadeamentos escravos você pode usar em sua carga de trabalho. Vale a pena notar que não faz sentido configurar wsrep_slave_threads variável para valores mais altos do que você vê nesta coluna ou em wsrep_cert_deps_distance variável de status, na qual a coluna "Cert Deps Distance" é baseada. Outra observação importante - não faz sentido configurar wsrep_slave_threads variável para mais do que o número de núcleos que sua CPU possui.
"ID do segmento" - esta coluna exigirá mais algumas explicações. Os segmentos são um novo recurso adicionado no Galera 3.0. Antes desta versão, os writesets eram trocados entre todos os nós. Digamos que temos dois datacenters:
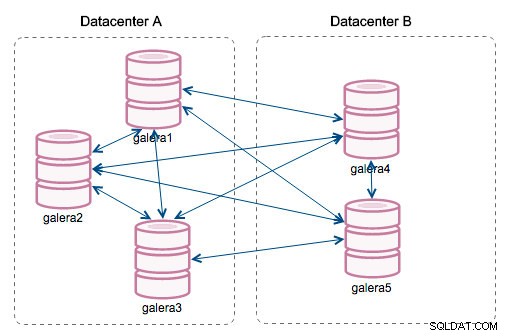
Esse tipo de conversa funciona bem em redes locais, mas WAN é uma história diferente - a certificação fica mais lenta devido ao aumento da latência, custos adicionais são gerados devido à largura de banda da rede usada para transferir conjuntos de gravação entre todos os membros do cluster.
Com a introdução de "Segmentos", as coisas mudaram. Você pode atribuir um nó a um segmento modificando wsrep_provider_options variável e adicionando "gmcast.segment=x" (0, 1, 2) a ela. Nós com o mesmo número de segmento são tratados como se estivessem no mesmo datacenter, conectados por rede local. Nosso gráfico então se torna diferente:
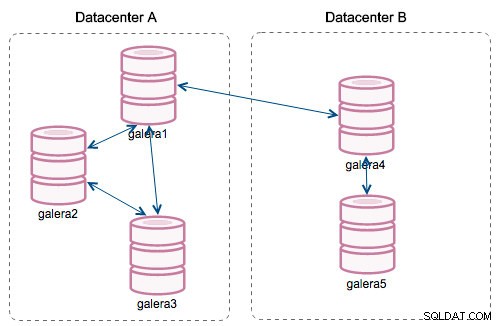
A principal diferença é que não é mais a comunicação de todos para todos. Dentro de cada segmento, sim - ainda é o mesmo mecanismo, mas ambos os segmentos se comunicam apenas por meio de uma única conexão entre dois nós escolhidos. Em caso de tempo de inatividade, esta conexão fará failover automaticamente. Como resultado, obtemos menos conversas na rede e menos uso de largura de banda entre datacenters remotos. Então, basicamente, a coluna "ID do segmento" nos diz a qual segmento um nó está atribuído.
A coluna "Último Confirmado" nos fornece informações sobre o número de sequência do conjunto de gravações que foi executado pela última vez em um determinado nó. Pode ser útil para determinar qual nó é o mais atual se houver a necessidade de inicializar o cluster.
O restante das colunas é autoexplicativo:versão do servidor, tempo de atividade de um nó e quando o status foi atualizado.
Como você pode ver, a seção "Galera Nodes" das "Nodes/Hosts Stats" na guia "Overview" fornece uma boa compreensão da integridade do cluster - se ele forma um componente "Primário", quantos nós estão íntegros , há algum problema de desempenho com alguns nós e, em caso afirmativo, qual nó está deixando o cluster mais lento.
Este conjunto de dados é muito útil quando você opera seu cluster Galera, então espero que não seja mais necessário voar às cegas :-)