Em uma postagem anterior, discutimos como você pode controlar o processo de failover no ClusterControl usando listas brancas e listas negras. Neste post, vamos discutir um conceito semelhante. Mas desta vez vamos focar nas integrações com scripts e aplicativos externos por meio de inúmeros ganchos disponibilizados pelo ClusterControl.
Os ambientes de infraestrutura podem ser construídos de diferentes maneiras, pois muitas vezes há muitas opções para escolher para uma determinada peça do quebra-cabeça. Como definimos em qual nó de banco de dados gravar? Você usa IP virtual? Você usa algum tipo de descoberta de serviço? Talvez você vá com entradas DNS e altere os registros A quando necessário? E a camada proxy? Você confia no valor 'read_only' para seus proxies decidirem sobre o gravador ou talvez faça as alterações necessárias diretamente na configuração do proxy? Como seu ambiente lida com as alternâncias? Você pode simplesmente ir em frente e executá-lo, ou talvez você tenha que tomar algumas ações preliminares de antemão? Por exemplo, interromper alguns outros processos antes que você possa realmente fazer a troca?
Não é possível que um software de failover seja pré-configurado para cobrir todas as diferentes configurações que as pessoas podem criar. Esta é a principal razão para fornecer diferentes maneiras de se conectar ao processo de failover. Dessa forma, você pode personalizá-lo e tornar possível lidar com todas as sutilezas de sua configuração. Nesta postagem do blog, veremos como o processo de failover do ClusterControl pode ser personalizado usando diferentes scripts pré e pós-failover. Também discutiremos alguns exemplos do que pode ser realizado com essa personalização.
Integrando o ClusterControl
O ClusterControl fornece vários ganchos que podem ser usados para conectar scripts externos. Abaixo você encontrará uma lista daqueles com alguma explicação.
- Replication_onfail_failover_script - este script é executado assim que for descoberto que um failover é necessário. Se o script retornar diferente de zero, ele forçará a interrupção do failover. Se o script for definido, mas não for encontrado, o failover será abortado. Quatro argumentos são fornecidos ao script:arg1='all servers' arg2='oldmaster' arg3='candidate', arg4='slaves of oldmaster' e passados assim:'scripname arg1 arg2 arg3 arg4'. O script deve ser acessível no controlador e executável.
- Replication_pre_failover_script - este script é executado antes do failover, mas depois que um candidato é eleito e é possível continuar o processo de failover. Se o script retornar diferente de zero, ele forçará a interrupção do failover. Se o script for definido, mas não for encontrado, o failover será abortado. O script deve ser acessível no controlador e executável.
- Replication_post_failover_script - este script é executado após o failover. Se o script retornar diferente de zero, um aviso será gravado no log de tarefas. O script deve ser acessível no controlador e executável.
- Replication_post_unsuccessful_failover_script - Este script é executado após a falha na tentativa de failover. Se o script retornar diferente de zero, um aviso será gravado no log de tarefas. O script deve ser acessível no controlador e executável.
- Replication_failed_reslave_failover_script - este script é executado após a promoção de um novo mestre e se a reescravização dos escravos para o novo mestre falhar. Se o script retornar diferente de zero, um aviso será gravado no log de tarefas. O script deve ser acessível no controlador e executável.
- Replication_pre_switchover_script - este script é executado antes da alternância. Se o script retornar diferente de zero, ele forçará o switchover a falhar. Se o script estiver definido, mas não for encontrado, a alternância será abortada. O script deve ser acessível no controlador e executável.
- Replication_post_switchover_script - este script é executado após a transição. Se o script retornar diferente de zero, um aviso será gravado no log de tarefas. O script deve ser acessível no controlador e executável.
Como você pode ver, os ganchos cobrem a maioria dos casos em que você pode querer realizar algumas ações - antes e depois de um switchover, antes e depois de um failover, quando o reslave falhou ou quando o failover falhou. Todos os scripts são invocados com quatro argumentos (que podem ou não ser manipulados no script, não é necessário que o script utilize todos eles):todos os servidores, hostname (ou IP - conforme definido no ClusterControl) do mestre antigo, hostname (ou IP - conforme definido no ClusterControl) do candidato mestre e o quarto, todas as réplicas do mestre antigo. Essas opções devem permitir o tratamento da maioria dos casos.
Todos esses ganchos devem ser definidos em um arquivo de configuração para um determinado cluster (/etc/cmon.d/cmon_X.cnf onde X é o id do cluster). Um exemplo pode ficar assim:
replication_pre_failover_script=/usr/bin/stonith.py
replication_post_failover_script=/usr/bin/vipmove.shÉ claro que os scripts invocados precisam ser executáveis, caso contrário, o cmon não poderá executá-los. Vamos agora tomar um momento e passar pelo processo de failover no ClusterControl e ver quando os scripts externos são executados.
Processo de failover no ClusterControl
Definimos todos os ganchos que estão disponíveis:
replication_onfail_failover_script=/tmp/1.sh
replication_pre_failover_script=/tmp/2.sh
replication_post_failover_script=/tmp/3.sh
replication_post_unsuccessful_failover_script=/tmp/4.sh
replication_failed_reslave_failover_script=/tmp/5.sh
replication_pre_switchover_script=/tmp/6.sh
replication_post_switchover_script=/tmp/7.shDepois disso, você deve reiniciar o processo cmon. Feito isso, estamos prontos para testar o failover. A topologia original fica assim:
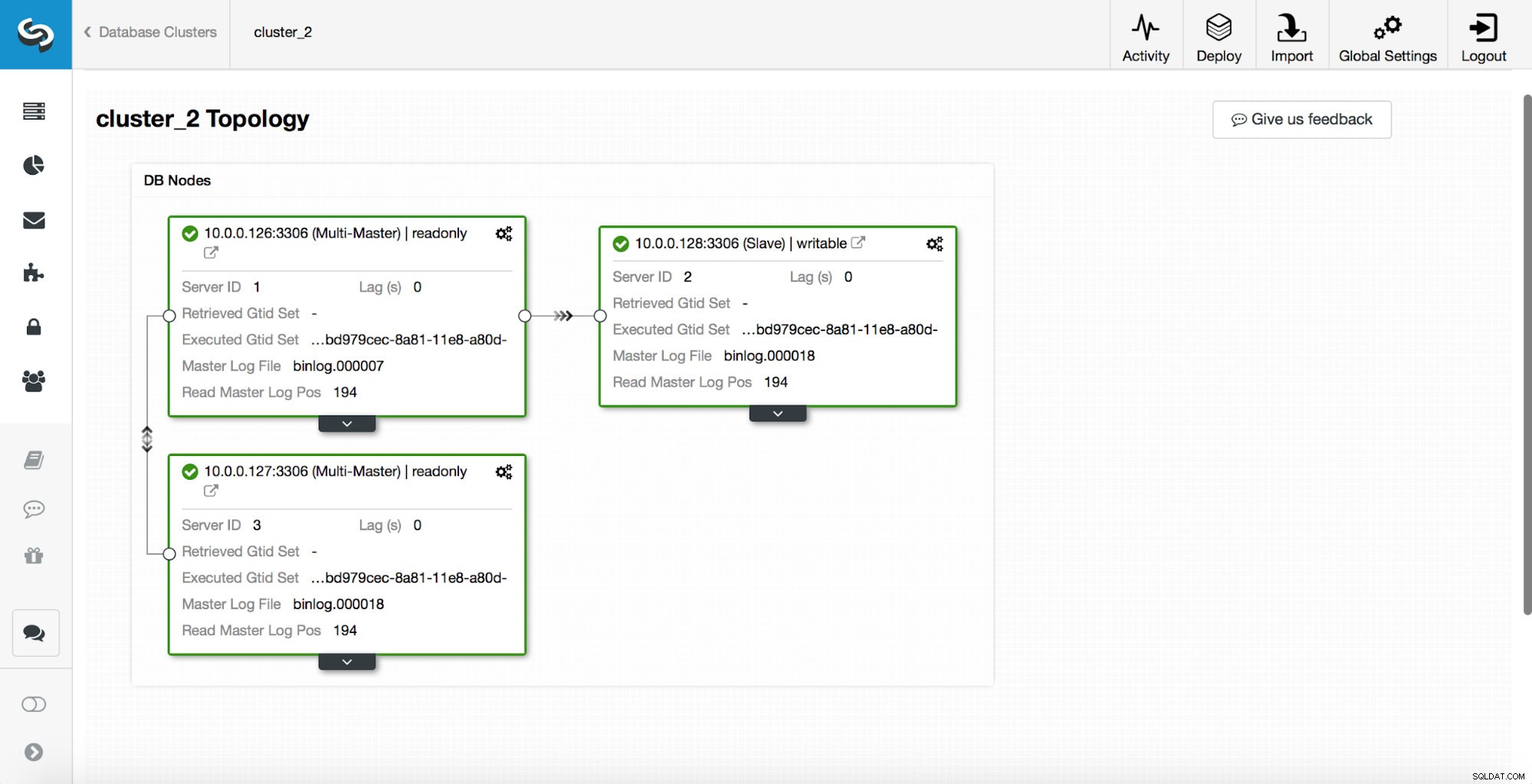
Um mestre foi eliminado e o processo de failover foi iniciado. Observe que as entradas de log mais recentes estão na parte superior, portanto, você deseja seguir o failover de baixo para cima.
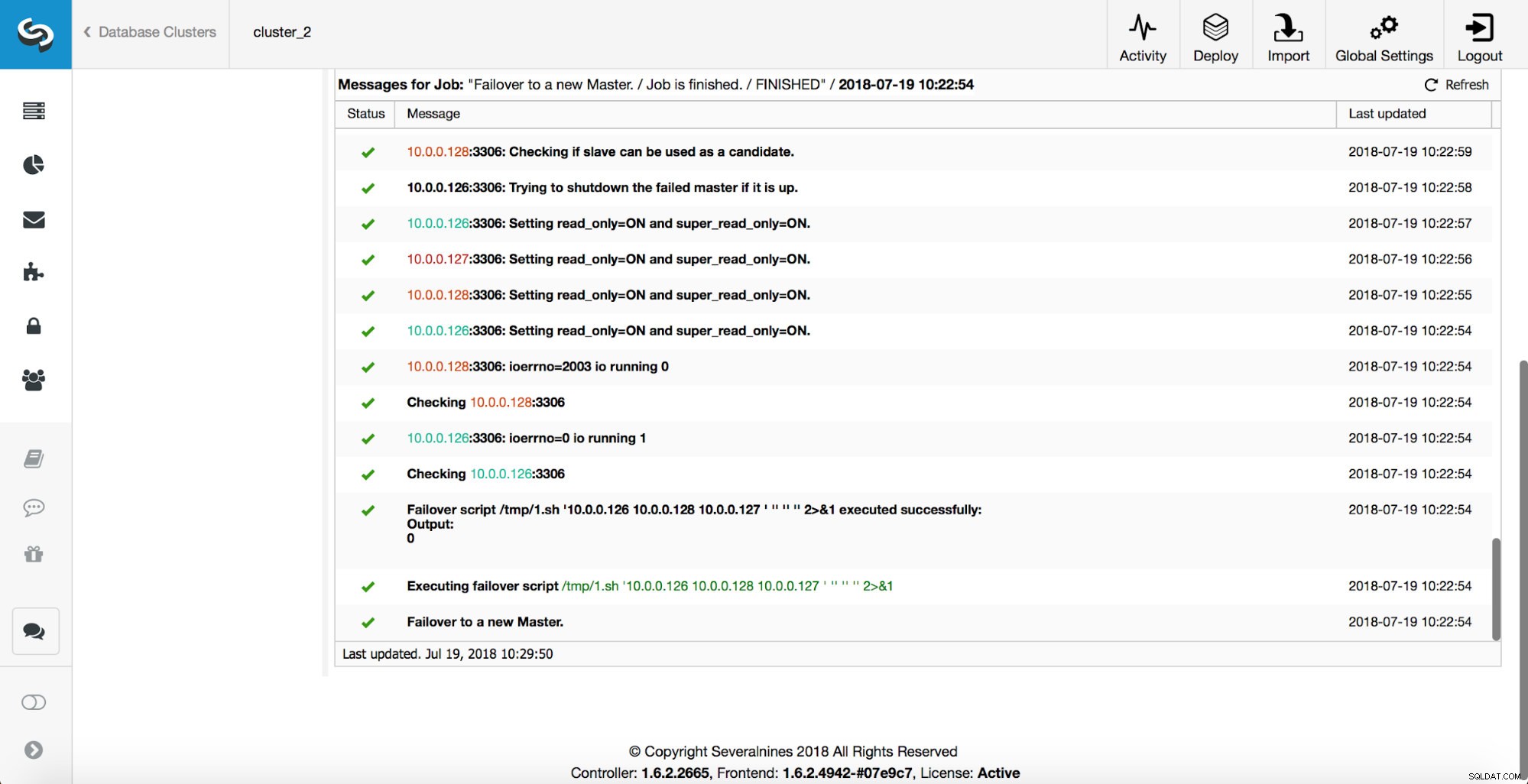
Como você pode ver, imediatamente após o início do trabalho de failover, ele aciona o gancho ‘replication_onfail_failover_script’. Em seguida, todos os hosts alcançáveis são marcados como read_only e o ClusterControl tenta impedir a execução do mestre antigo.
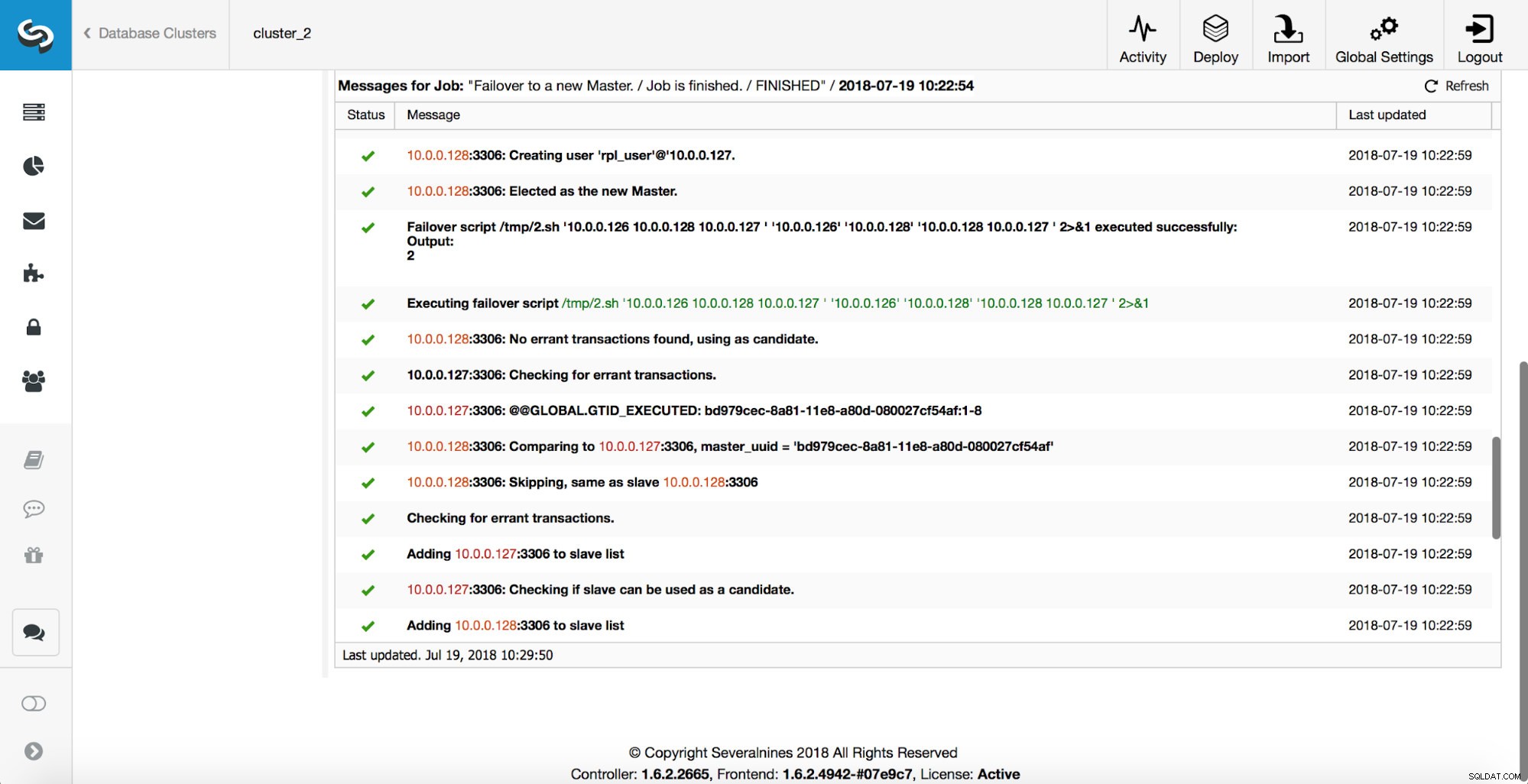
Em seguida, o candidato mestre é escolhido, as verificações de sanidade são executadas. Uma vez confirmado que o candidato a mestre pode ser usado como um novo mestre, o ‘replication_pre_failover_script’ é executado.
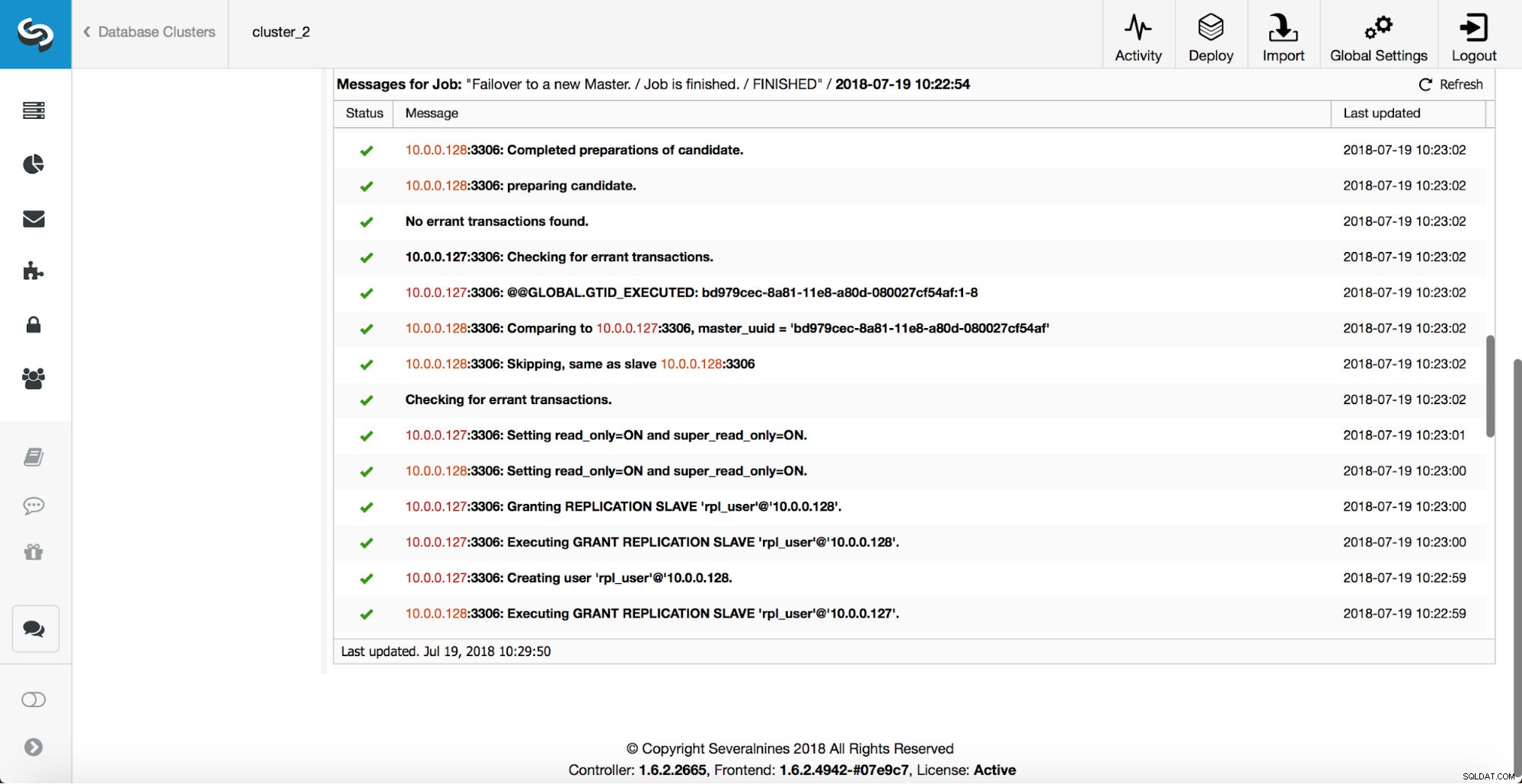
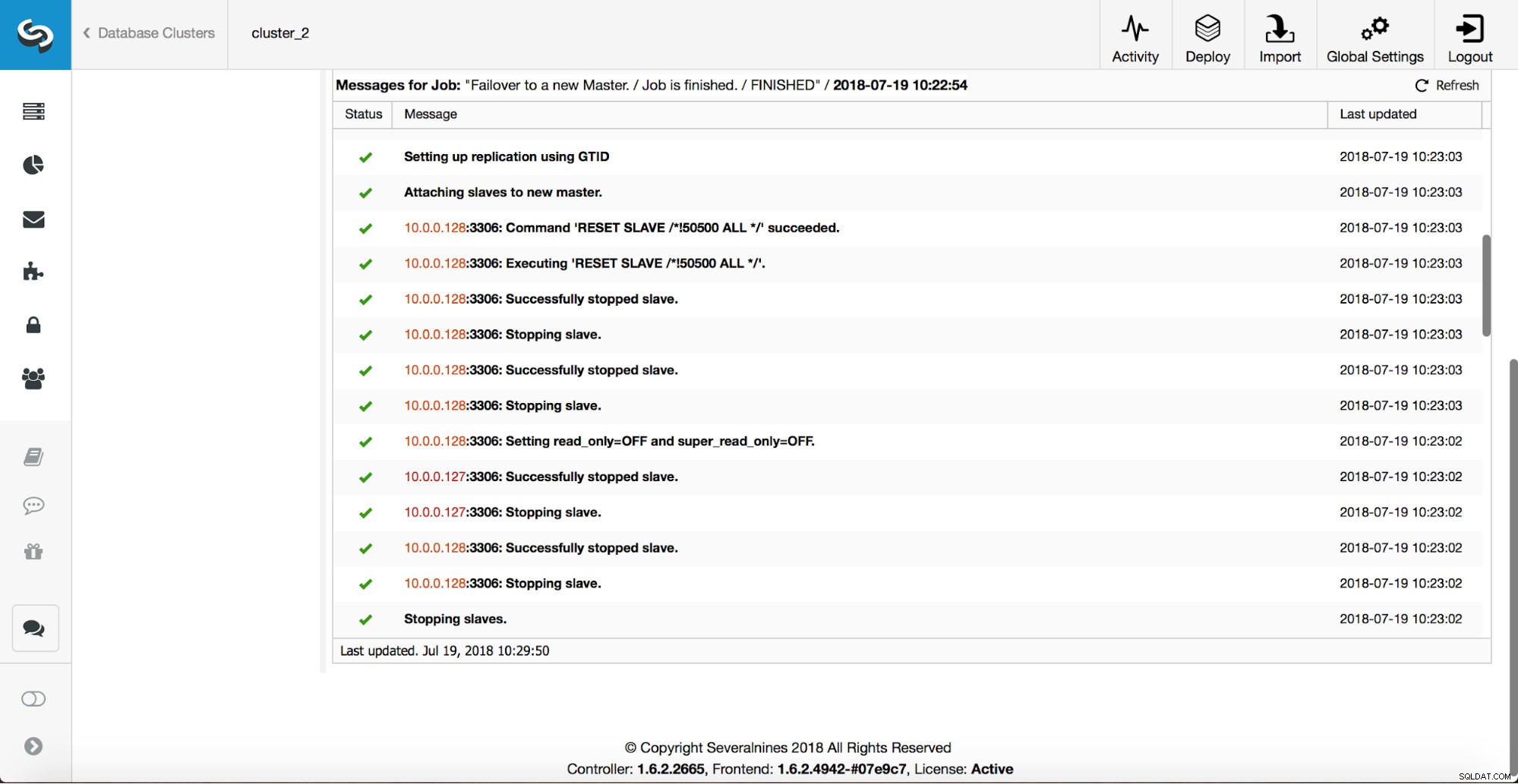
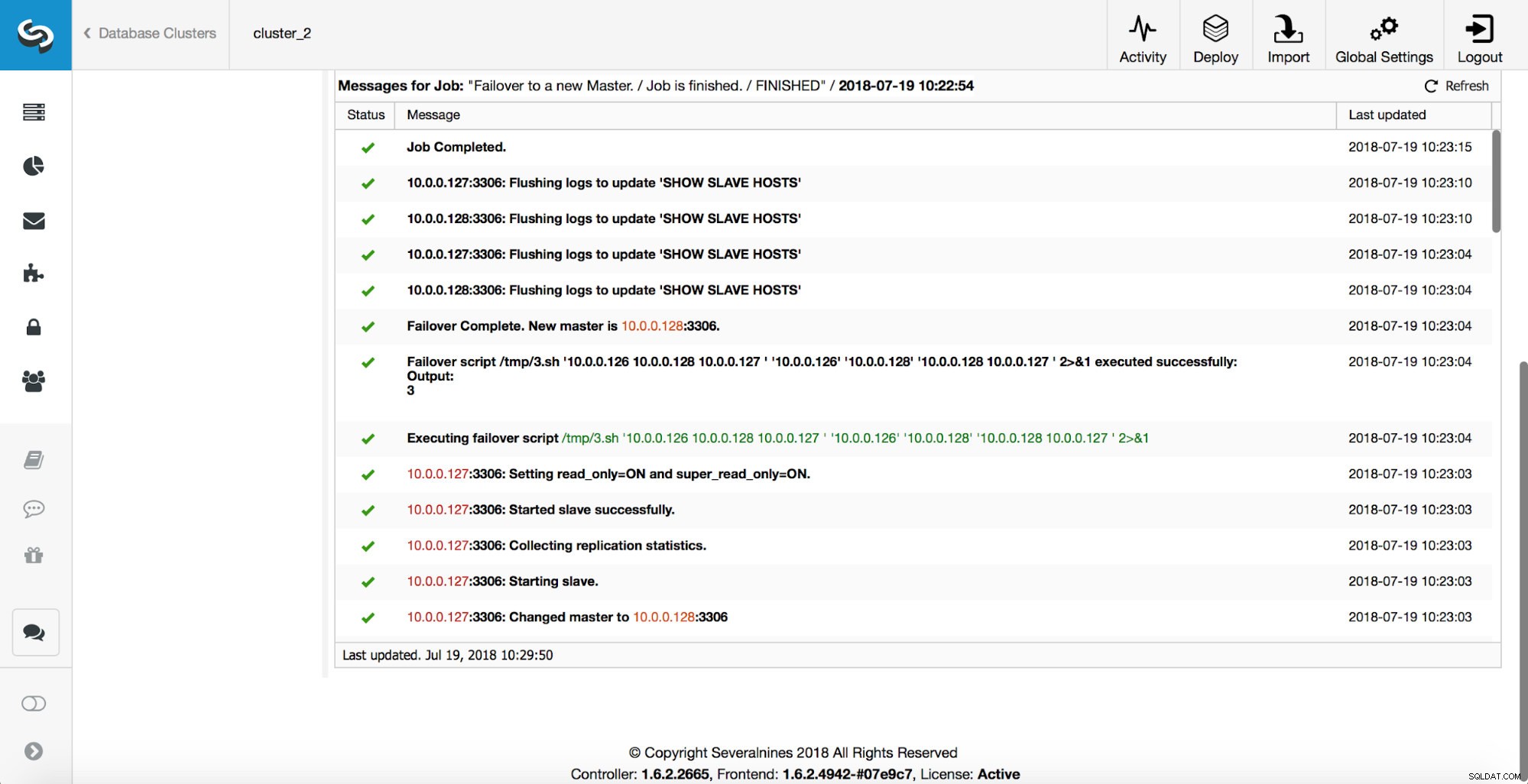
Mais verificações são executadas, as réplicas são interrompidas e escravizadas no novo mestre. Finalmente, após a conclusão do failover, um gancho final, ‘replication_post_failover_script’, é acionado.
Quando ganchos podem ser úteis?
Nesta seção, veremos alguns exemplos de casos em que pode ser uma boa ideia implementar scripts externos. Não entraremos em detalhes, pois eles estão muito relacionados a um ambiente específico. Será mais uma lista de sugestões que podem ser úteis para implementar.
roteiro STONITH
Shoot The Other Node In The Head (STONITH) é um processo para garantir que o antigo mestre, que está morto, permaneça morto (e sim, não gostamos de zumbis vagando em nossa infraestrutura). A última coisa que você provavelmente quer é ter um mestre antigo que não responde, que volta a ficar online e, como resultado, você acaba com dois mestres graváveis. Existem precauções que você pode tomar para garantir que o antigo mestre não seja usado mesmo que apareça novamente, e é mais seguro mantê-lo offline. Maneiras de como garantir que isso será diferente de ambiente para ambiente. Portanto, muito provavelmente, não haverá suporte interno para STONITH na ferramenta de failover. Dependendo do ambiente, você pode querer executar o comando CLI que irá parar (e até remover) uma VM na qual o antigo mestre está sendo executado. Se você tiver uma configuração local, poderá ter mais controle sobre o hardware. Pode ser possível utilizar algum tipo de gerenciamento remoto (Lights-out integrado ou algum outro acesso remoto ao servidor). Você também pode ter acesso a soquetes de energia gerenciáveis e desligar a energia em um deles para garantir que o servidor nunca seja reiniciado sem intervenção humana.
Descoberta de serviço
Já mencionamos um pouco sobre descoberta de serviços. Existem várias maneiras de armazenar informações sobre uma topologia de replicação e detectar qual host é um mestre. Definitivamente, uma das opções mais populares é usar etc.d ou Consul para armazenar dados sobre a topologia atual. Com ele, um aplicativo ou proxy pode contar com esses dados para enviar o tráfego para o nó correto. O ClusterControl (assim como a maioria das ferramentas que suportam o tratamento de failover) não tem uma integração direta com o etc.d ou Consul. A tarefa de atualizar os dados da topologia está no usuário. Ela pode usar ganchos como replication_post_failover_script ou replication_post_switchover_script para invocar alguns dos scripts e fazer as alterações necessárias. Outra solução bastante comum é usar o DNS para direcionar o tráfego para as instâncias corretas. Se você mantiver o tempo de vida de um registro DNS baixo, poderá definir um domínio, que apontará para seu mestre (ou seja, writes.cluster1.example.com). Isso requer uma alteração nos registros DNS e, novamente, ganchos como replication_post_failover_script ou replication_post_switchover_script podem ser realmente úteis para fazer as modificações necessárias após um failover.
Reconfiguração de proxy
Cada servidor proxy usado deve enviar tráfego para instâncias corretas. Dependendo do proxy em si, como uma detecção de mestre é realizada pode ser (parcialmente) codificada ou pode caber ao usuário definir o que quiser. O mecanismo de failover do ClusterControl foi projetado de forma a se integrar bem aos proxies que ele implantou e configurou. Ainda pode acontecer que existam proxies instalados, que não foram instalados pelo ClusterControl e que requerem que algumas ações manuais ocorram enquanto o failover está sendo executado. Esses proxies também podem ser integrados ao processo de failover do ClusterControl por meio de scripts externos e ganchos como replication_post_failover_script ou replication_post_switchover_script.
Registro Adicional
Pode acontecer que você queira coletar dados do processo de failover para fins de depuração. O ClusterControl possui impressões extensas para garantir que seja possível acompanhar o processo e descobrir o que aconteceu e por quê. Ainda pode acontecer que você queira coletar algumas informações adicionais personalizadas. Basicamente, todos os ganchos podem ser utilizados aqui - você pode coletar o estado inicial, antes do failover, você pode rastrear o estado do ambiente em todos os estágios do failover.