O agrupamento de dados de data e hora envolve a organização de dados em grupos que representam intervalos fixos de tempo para fins analíticos. Muitas vezes, a entrada são dados de séries temporais armazenados em uma tabela em que as linhas representam medições feitas em intervalos de tempo regulares. Por exemplo, as medições podem ser leituras de temperatura e umidade feitas a cada 5 minutos, e você deseja agrupar os dados usando intervalos horários e computar agregados como média por hora. Embora os dados de série temporal sejam uma fonte comum para análise baseada em bucket, o conceito é igualmente relevante para qualquer dado que envolva atributos de data e hora e medidas associadas. Por exemplo, talvez você queira organizar dados de vendas em buckets de ano fiscal e calcular agregações como o valor total de vendas por ano fiscal. Neste artigo, abordo dois métodos para agrupar dados de data e hora. Uma está usando uma função chamada DATE_BUCKET, que no momento da escrita está disponível apenas no Azure SQL Edge. Outra é usar um cálculo personalizado que emula a função DATE_BUCKET, que você pode usar em qualquer versão, edição e sabor do SQL Server e do Banco de Dados SQL do Azure.
Em meus exemplos, usarei o banco de dados de exemplo TSQLV5. Você pode encontrar o script que cria e preenche o TSQLV5 aqui e seu diagrama ER aqui.
DATE_BUCKET
Conforme mencionado, a função DATE_BUCKET está atualmente disponível apenas no Azure SQL Edge. O SQL Server Management Studio já tem suporte ao IntelliSense, conforme mostrado na Figura 1:
 Figura 1:suporte de inteligência para DATE_BUCKET no SSMS
Figura 1:suporte de inteligência para DATE_BUCKET no SSMS A sintaxe da função é a seguinte:
DATE_BUCKET (
A entrada origem representa um ponto de ancoragem na seta do tempo. Ele pode ser de qualquer um dos tipos de dados de data e hora com suporte. Se não especificado, o padrão é 1900, 1º de janeiro, meia-noite. Você pode então imaginar a linha do tempo dividida em intervalos discretos começando com o ponto de origem, onde o comprimento de cada intervalo é baseado nas entradas largura do bucket e parte da data . O primeiro é a quantidade e o segundo é a unidade. Por exemplo, para organizar a linha do tempo em unidades de 2 meses, especifique 2 como a largura do bucket entrada e mês como a parte da data entrada.
A entrada timestamp é um ponto no tempo arbitrário que precisa ser associado ao bucket que o contém. Seu tipo de dados precisa corresponder ao tipo de dados da entrada origem . A entrada timestamp é o valor de data e hora associado às medidas que você está capturando.
A saída da função é então o ponto de partida do bucket que o contém. O tipo de dados da saída é o da entrada timestamp .
Se já não fosse óbvio, normalmente você usaria a função DATE_BUCKET como um elemento de conjunto de agrupamento na cláusula GROUP BY da consulta e naturalmente a retornaria na lista SELECT também, junto com medidas agregadas.
Ainda um pouco confuso sobre a função, suas entradas e sua saída? Talvez um exemplo específico com uma representação visual da lógica da função ajude. Começarei com um exemplo que usa variáveis de entrada e, posteriormente, no artigo demonstrarei a maneira mais comum de usá-la como parte de uma consulta em uma tabela de entrada.
Considere o seguinte exemplo:
DECLARE @timestamp AS DATETIME2 = '20210510 06:30:00', @bucketwidth AS INT = 2, @origin AS DATETIME2 = '20210115 00:00:00'; SELECT DATE_BUCKET(month, @bucketwidth, @timestamp, @origin);
Você pode encontrar uma representação visual da lógica da função na Figura 2.
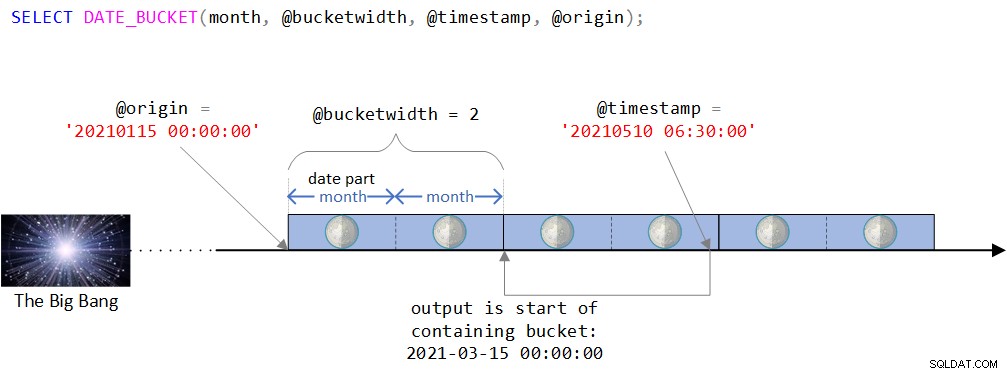 Figura 2:representação visual da lógica da função DATE_BUCKET
Figura 2:representação visual da lógica da função DATE_BUCKET Como você pode ver na Figura 2, o ponto de origem é o valor DATETIME2 15 de janeiro de 2021, meia-noite. Se este ponto de origem parece um pouco estranho, você estaria certo em perceber intuitivamente que normalmente você usaria um ponto mais natural como o início de algum ano ou o início de algum dia. Na verdade, muitas vezes você ficaria satisfeito com o padrão, que, como você se lembra, é 1º de janeiro de 1900 à meia-noite. Eu intencionalmente queria usar um ponto de origem menos trivial para poder discutir certas complexidades que podem não ser relevantes ao usar um ponto de origem mais natural. Mais sobre isso em breve.
A linha do tempo é então dividida em intervalos discretos de 2 meses, começando com o ponto de origem. O carimbo de data/hora de entrada é o valor DATETIME2 10 de maio de 2021, 6h30.
Observe que o carimbo de data/hora de entrada faz parte do bucket que começa em 15 de março de 2021, meia-noite. De fato, a função retorna esse valor como um valor do tipo DATETIME2:
--------------------------- 2021-03-15 00:00:00.0000000
Emulando DATE_BUCKET
A menos que você esteja usando o Azure SQL Edge, se quiser agrupar dados de data e hora, por enquanto, você precisaria criar sua própria solução personalizada para emular o que a função DATE_BUCKET faz. Fazer isso não é muito complexo, mas também não é muito simples. Lidar com dados de data e hora geralmente envolve lógica complicada e armadilhas com as quais você precisa ter cuidado.
Construirei o cálculo em etapas e usarei as mesmas entradas que usei com o exemplo DATE_BUCKET que mostrei anteriormente:
DECLARE @timestamp AS DATETIME2 = '20210510 06:30:00', @bucketwidth AS INT = 2, @origin AS DATETIME2 = '20210115 00:00:00';
Certifique-se de incluir esta parte antes de cada um dos exemplos de código que mostrarei se você realmente quiser executar o código.
Na Etapa 1, você usa a função DATEDIFF para calcular a diferença na parte da data unidades entre origem e carimbo de data e hora . Vou me referir a essa diferença como diff1 . Isso é feito com o seguinte código:
SELECT DATEDIFF(month, @origin, @timestamp) AS diff1;
Com nossas entradas de exemplo, essa expressão retorna 4.
A parte complicada aqui é que você precisa calcular quantas unidades inteiras de parte de data existe entre origem e carimbo de data e hora . Com nossas entradas de exemplo, há 3 meses inteiros entre os dois e não 4. A razão pela qual a função DATEDIFF reporta 4 é que, quando calcula a diferença, ela analisa apenas a parte solicitada das entradas e as partes mais altas, mas não as partes mais baixas . Assim, quando você pede a diferença em meses, a função só se preocupa com as partes do ano e do mês das entradas e não com as partes abaixo do mês (dia, hora, minuto, segundo, etc.). De fato, há 4 meses entre janeiro de 2021 e maio de 2021, mas apenas 3 meses inteiros entre as entradas completas.
O objetivo da Etapa 2 é calcular quantas unidades inteiras de parte de data existe entre origem e carimbo de data e hora . Vou me referir a essa diferença como diff2 . Para conseguir isso, você pode adicionar diff1 unidades de parte de data para origem . Se o resultado for maior que timestamp , você subtrai 1 de diff1 para calcular diff2 , caso contrário, subtraia 0 e, portanto, use diff1 como diff2 . Isso pode ser feito usando uma expressão CASE, assim:
SELECT
DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END AS diff2; Essa expressão retorna 3, que é o número de meses inteiros entre as duas entradas.
Lembre-se de que mencionei anteriormente que no meu exemplo usei intencionalmente um ponto de origem que não é natural, como um início redondo de um período, para poder discutir certas complexidades que podem ser relevantes. Por exemplo, se você usar mês como a parte da data e o início exato de algum mês (1 de algum mês à meia-noite) como origem, você pode pular a Etapa 2 com segurança e usar diff1 como diff2 . Isso porque origem + dif1 nunca pode ser> timestamp nesse caso. No entanto, meu objetivo é fornecer uma alternativa logicamente equivalente à função DATE_BUCKET que funcionaria corretamente para qualquer ponto de origem, comum ou não. Portanto, incluirei a lógica da Etapa 2 em meus exemplos, mas lembre-se de que, ao identificar casos em que essa etapa não é relevante, você pode remover com segurança a parte em que subtrai a saída da expressão CASE.
Na Etapa 3, você identifica quantas unidades de parte de data existem em buckets inteiros que existem entre origin e carimbo de data e hora . Vou me referir a esse valor como diff3 . Isso pode ser feito com a seguinte fórmula:
diff3 = diff2 / <bucket width> * <bucket width>
O truque aqui é que ao usar o operador de divisão / em T-SQL com operandos inteiros, você obtém uma divisão inteira. Por exemplo, 3/2 em T-SQL é 1 e não 1,5. A expressão diff2 /
SELECT
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth AS diff3; Essa expressão retorna 2, que é o número de meses em todos os buckets de 2 meses que existem entre as duas entradas.
Na Etapa 4, que é a etapa final, você adiciona diff3 unidades de parte de data para origem para calcular o início do bucket que o contém. Aqui está o código para conseguir isso:
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Este código gera a seguinte saída:
--------------------------- 2021-03-15 00:00:00.0000000
Como você deve se lembrar, esta é a mesma saída produzida pela função DATE_BUCKET para as mesmas entradas.
Sugiro que você tente esta expressão com várias entradas e partes. Vou mostrar alguns exemplos aqui, mas sinta-se à vontade para tentar o seu próprio.
Aqui está um exemplo em que origem está um pouco à frente do timestamp no mês:
DECLARE
@timestamp AS DATETIME2 = '20210510 06:30:00',
@bucketwidth AS INT = 2,
@origin AS DATETIME2 = '20210110 06:30:01';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Este código gera a seguinte saída:
--------------------------- 2021-03-10 06:30:01.0000000
Observe que o início do bucket que o contém é em março.
Aqui está um exemplo em que origem está no mesmo ponto dentro do mês que timestamp :
DECLARE
@timestamp AS DATETIME2 = '20210510 06:30:00',
@bucketwidth AS INT = 2,
@origin AS DATETIME2 = '20210110 06:30:00';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Este código gera a seguinte saída:
--------------------------- 2021-05-10 06:30:00.0000000
Observe que desta vez o início do bucket que o contém é em maio.
Veja um exemplo com buckets de 4 semanas:
DECLARE
@timestamp AS DATETIME2 = '20210303 21:22:11',
@bucketwidth AS INT = 4,
@origin AS DATETIME2 = '20210115';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
week,
( DATEDIFF(week, @origin, @timestamp)
- CASE
WHEN DATEADD(
week,
DATEDIFF(week, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Observe que o código usa a semana parte desta vez.
Este código gera a seguinte saída:
--------------------------- 2021-02-12 00:00:00.0000000
Aqui está um exemplo com intervalos de 15 minutos:
DECLARE
@timestamp AS DATETIME2 = '20210203 21:22:11',
@bucketwidth AS INT = 15,
@origin AS DATETIME2 = '19000101';
-- SELECT DATE_BUCKET(minute, @bucketwidth, @timestamp);
SELECT DATEADD(
minute,
( DATEDIFF(minute, @origin, @timestamp)
- CASE
WHEN DATEADD(
minute,
DATEDIFF(minute, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Este código gera a seguinte saída:
--------------------------- 2021-02-03 21:15:00.0000000
Observe que a parte é minuto . Neste exemplo, você deseja usar buckets de 15 minutos começando na parte inferior da hora, portanto, um ponto de origem que seja a parte inferior de qualquer hora funcionaria. De fato, um ponto de origem que tenha uma unidade de minuto de 00, 15, 30 ou 45 com zeros nas partes inferiores, com qualquer data e hora funcionaria. Então o padrão que a função DATE_BUCKET usa para a entrada origem trabalharia. Obviamente, ao usar a expressão personalizada, você deve ser explícito sobre o ponto de origem. Então, para simpatizar com a função DATE_BUCKET, você pode usar a data base à meia-noite como eu faço no exemplo acima.
Aliás, você pode ver por que isso seria um bom exemplo em que é perfeitamente seguro pular a Etapa 2 na solução? Se você realmente optou por pular a Etapa 2, obterá o seguinte código:
DECLARE
@timestamp AS DATETIME2 = '20210203 21:22:11',
@bucketwidth AS INT = 15,
@origin AS DATETIME2 = '19000101';
-- SELECT DATE_BUCKET(minute, @bucketwidth, @timestamp);
SELECT DATEADD(
minute,
( DATEDIFF( minute, @origin, @timestamp ) ) / @bucketwidth * @bucketwidth,
@origin
); Claramente, o código se torna significativamente mais simples quando a Etapa 2 não é necessária.
Agrupar e agregar dados por intervalos de data e hora
Há casos em que você precisa agrupar dados de data e hora que não exigem funções sofisticadas ou expressões complicadas. Por exemplo, suponha que você queira consultar a exibição Sales.OrderValues no banco de dados TSQLV5, agrupar os dados anualmente e calcular o total de contagens e valores de pedidos por ano. Claramente, é suficiente usar a função YEAR(orderdate) como o elemento do conjunto de agrupamento, assim:
USE TSQLV5; SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues GROUP BY YEAR(orderdate) ORDER BY orderyear;
Este código gera a seguinte saída:
orderyear numorders totalvalue ----------- ----------- ----------- 2017 152 208083.99 2018 408 617085.30 2019 270 440623.93
Mas e se você quisesse agrupar os dados por ano fiscal da sua organização? Algumas organizações usam um ano fiscal para fins de contabilidade, orçamento e relatórios financeiros, não alinhados com o ano civil. Digamos, por exemplo, que o ano fiscal de sua organização opere em um calendário fiscal de outubro a setembro e seja indicado pelo ano civil em que o ano fiscal termina. Assim, um evento ocorrido em 3 de outubro de 2018 pertence ao ano fiscal iniciado em 1º de outubro de 2018, encerrado em 30 de setembro de 2019, e é denotado pelo ano de 2019.
Isso é muito fácil de conseguir com a função DATE_BUCKET, assim:
DECLARE @bucketwidth AS INT = 1, @origin AS DATETIME2 = '19001001'; -- this is Oct 1 of some year SELECT YEAR(startofbucket) + 1 AS fiscalyear, COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues CROSS APPLY ( VALUES( DATE_BUCKET( year, @bucketwidth, orderdate, @origin ) ) ) AS A(startofbucket) GROUP BY startofbucket ORDER BY startofbucket;
E aqui está o código usando o equivalente lógico personalizado da função DATE_BUCKET:
DECLARE
@bucketwidth AS INT = 1,
@origin AS DATETIME2 = '19001001'; -- this is Oct 1 of some year
SELECT
YEAR(startofbucket) + 1 AS fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
DATEADD(
year,
( DATEDIFF(year, @origin, orderdate)
- CASE
WHEN DATEADD(
year,
DATEDIFF(year, @origin, orderdate),
@origin) > orderdate
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin) ) ) AS A(startofbucket)
GROUP BY startofbucket
ORDER BY startofbucket; Este código gera a seguinte saída:
fiscalyear numorders totalvalue ----------- ----------- ----------- 2017 70 79728.58 2018 370 563759.24 2019 390 622305.40
Usei variáveis aqui para a largura do bucket e o ponto de origem para tornar o código mais generalizado, mas você pode substituí-las por constantes se estiver sempre usando as mesmas e simplificar o cálculo conforme apropriado.
Como uma pequena variação do acima, suponha que seu ano fiscal vai de 15 de julho de um ano civil a 14 de julho do próximo ano civil e é indicado pelo ano civil ao qual o início do ano fiscal pertence. Portanto, um evento ocorrido em 18 de julho de 2018 pertence ao ano fiscal de 2018. Um evento ocorrido em 14 de julho de 2018 pertence ao ano fiscal de 2017. Usando a função DATE_BUCKET, você obteria isso da seguinte forma:
DECLARE @bucketwidth AS INT = 1, @origin AS DATETIME2 = '19000715'; -- July 15 marks start of fiscal year SELECT YEAR(startofbucket) AS fiscalyear, -- no need to add 1 here COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues CROSS APPLY ( VALUES( DATE_BUCKET( year, @bucketwidth, orderdate, @origin ) ) ) AS A(startofbucket) GROUP BY startofbucket ORDER BY startofbucket;
Você pode ver as alterações em comparação com o exemplo anterior nos comentários.
E aqui está o código usando o equivalente lógico personalizado para a função DATE_BUCKET:
DECLARE
@bucketwidth AS INT = 1,
@origin AS DATETIME2 = '19000715';
SELECT
YEAR(startofbucket) AS fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
DATEADD(
year,
( DATEDIFF(year, @origin, orderdate)
- CASE
WHEN DATEADD(
year,
DATEDIFF(year, @origin, orderdate),
@origin) > orderdate
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin) ) ) AS A(startofbucket)
GROUP BY startofbucket
ORDER BY startofbucket; Este código gera a seguinte saída:
fiscalyear numorders totalvalue ----------- ----------- ----------- 2016 8 12599.88 2017 343 495118.14 2018 479 758075.20
Obviamente, existem métodos alternativos que você pode usar em casos específicos. Veja o exemplo antes do último, onde o ano fiscal vai de outubro a setembro e denotado pelo ano civil em que o ano fiscal termina. Nesse caso, você pode usar a seguinte expressão, muito mais simples:
YEAR(orderdate) + CASE WHEN MONTH(orderdate) BETWEEN 10 AND 12 THEN 1 ELSE 0 END
E então sua consulta ficaria assim:
SELECT
fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
YEAR(orderdate)
+ CASE
WHEN MONTH(orderdate) BETWEEN 10 AND 12 THEN 1
ELSE 0
END ) ) AS A(fiscalyear)
GROUP BY fiscalyear
ORDER BY fiscalyear; No entanto, se você deseja uma solução generalizada que funcione em muitos outros casos, e que você possa parametrizar, você naturalmente deseja usar a forma mais geral. Se você tiver acesso à função DATE_BUCKET, ótimo. Caso contrário, você pode usar o equivalente lógico personalizado.
Conclusão
A função DATE_BUCKET é uma função bastante útil que permite agrupar dados de data e hora. É útil para lidar com dados de séries temporais, mas também para agrupar quaisquer dados que envolvam atributos de data e hora. Neste artigo, expliquei como a função DATE_BUCKET funciona e forneci um equivalente lógico personalizado caso a plataforma que você está usando não a suporte.