UDFs escalares sempre foram uma faca de dois gumes – eles são ótimos para desenvolvedores, que conseguem abstrair a lógica tediosa em vez de repeti-la em todas as suas consultas, mas são horríveis para o desempenho de tempo de execução na produção, porque o otimizador não t tratá-los bem. Essencialmente, o que acontece é que as execuções de UDF são mantidas separadas do restante do plano de execução e, portanto, são chamadas uma vez para cada linha e não podem ser otimizadas com base no número estimado ou real de linhas ou dobradas no restante do plano.
Uma vez que, apesar de nossos melhores esforços desde o SQL Server 2000, não podemos efetivamente impedir que UDFs escalares sejam usadas, não seria ótimo fazer o SQL Server simplesmente lidar melhor com elas?
O SQL Server 2019 apresenta um novo recurso chamado Scalar UDF Inlining. Em vez de manter a função separada, ela é incorporada ao plano geral. Isso leva a um plano de execução muito melhor e, por sua vez, a um melhor desempenho de tempo de execução.
Mas primeiro, para ilustrar melhor a origem do problema, vamos começar com um par de tabelas simples com apenas algumas linhas, em um banco de dados rodando no SQL Server 2017 (ou no 2019, mas com um nível de compatibilidade menor):
CREATE DATABASE Whatever; GO ALTER DATABASE Whatever SET COMPATIBILITY_LEVEL = 140; GO USE Whatever; GO CREATE TABLE dbo.Languages ( LanguageID int PRIMARY KEY, Name sysname ); CREATE TABLE dbo.Employees ( EmployeeID int PRIMARY KEY, LanguageID int NOT NULL FOREIGN KEY REFERENCES dbo.Languages(LanguageID) ); INSERT dbo.Languages(LanguageID, Name) VALUES(1033, N'English'), (45555, N'Klingon'); INSERT dbo.Employees(EmployeeID, LanguageID) SELECT [object_id], CASE ABS([object_id]%2) WHEN 1 THEN 1033 ELSE 45555 END FROM sys.all_objects;
Agora, temos uma consulta simples onde queremos mostrar cada funcionário e o nome de seu idioma principal. Digamos que essa consulta seja usada em muitos lugares e/ou de maneiras diferentes, então, em vez de construir uma junção na consulta, escrevemos uma UDF escalar para abstrair essa junção:
CREATE FUNCTION dbo.GetLanguage(@id int) RETURNS sysname AS BEGIN RETURN (SELECT Name FROM dbo.Languages WHERE LanguageID = @id); END
Então nossa consulta real se parece com isso:
SELECT TOP (6) EmployeeID, Language = dbo.GetLanguage(LanguageID) FROM dbo.Employees;
Se observarmos o plano de execução da consulta, algo está estranhamente ausente:
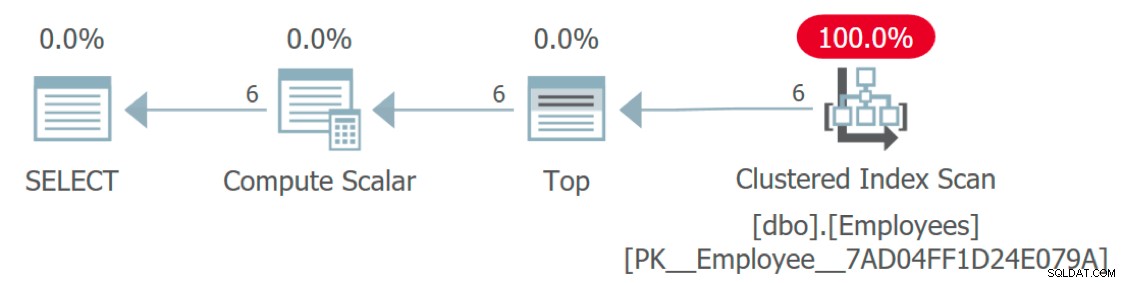 Plano de execução mostrando acesso a funcionários, mas não a idiomas
Plano de execução mostrando acesso a funcionários, mas não a idiomas Como a tabela Idiomas é acessada? Este plano parece muito eficiente porque – como a própria função – está abstraindo um pouco da complexidade envolvida. Na verdade, este plano gráfico é idêntico a uma consulta que apenas atribui uma constante ou variável ao
Language coluna:SELECT TOP (6) EmployeeID, Language = N'Sanskrit' FROM dbo.Employees;
Mas se você executar um rastreamento na consulta original, verá que existem, na verdade, seis chamadas para a função (uma para cada linha) além da consulta principal, mas esses planos não são retornados pelo SQL Server.
Você também pode verificar isso verificando
sys.dm_exec_function_stats , mas isso não é uma garantia :SELECT [function] = OBJECT_NAME([object_id]), execution_count FROM sys.dm_exec_function_stats WHERE object_name(object_id) IS NOT NULL;
function execution_count ----------- --------------- GetLanguage 6
O SentryOne Plan Explorer mostrará as declarações se você gerar um plano real de dentro do produto, mas só podemos obtê-las do rastreamento, e ainda não há planos coletados ou mostrados para as chamadas de função individuais:
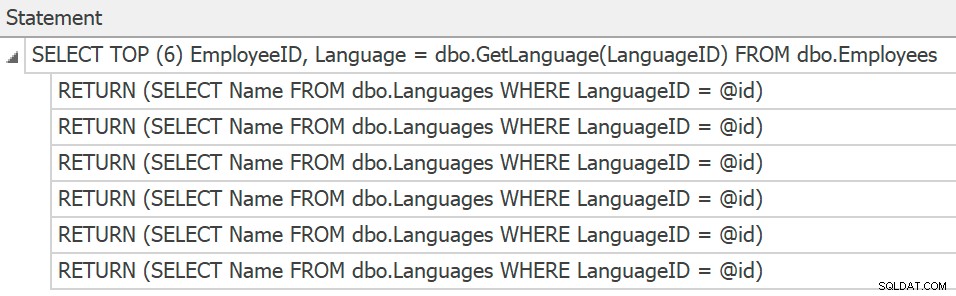 Declarações de rastreamento para invocações de UDF escalares individuais
Declarações de rastreamento para invocações de UDF escalares individuais Tudo isso os torna muito difíceis de solucionar, porque você precisa caçá-los, mesmo quando já sabe que eles estão lá. Também pode atrapalhar a análise de desempenho se você estiver comparando dois planos com base em custos estimados, porque não apenas os operadores relevantes estão se escondendo do diagrama físico, mas os custos também não são incorporados em nenhum lugar do plano.
Avanço rápido para o SQL Server 2019
Depois de todos esses anos de comportamento problemático e causas-raiz obscuras, eles conseguiram que algumas funções pudessem ser otimizadas no plano geral de execução. O Scalar UDF Inlining torna os objetos que eles acessam visíveis para solução de problemas *e* permite que eles sejam incluídos na estratégia do plano de execução. Agora, as estimativas de cardinalidade (com base em estatísticas) permitem estratégias de junção que simplesmente não eram possíveis quando a função era chamada uma vez para cada linha.
Podemos usar o mesmo exemplo acima, criar o mesmo conjunto de objetos em um banco de dados SQL Server 2019 ou limpar o cache do plano e aumentar o nível de compatibilidade para 150:
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE; GO ALTER DATABASE Whatever SET COMPATIBILITY_LEVEL = 150; GO
Agora, quando executamos nossa consulta de seis linhas novamente:
SELECT TOP (6) EmployeeID, Language = dbo.GetLanguage(LanguageID) FROM dbo.Employees;
Obtemos um plano que inclui a tabela Idiomas e os custos associados ao acesso:
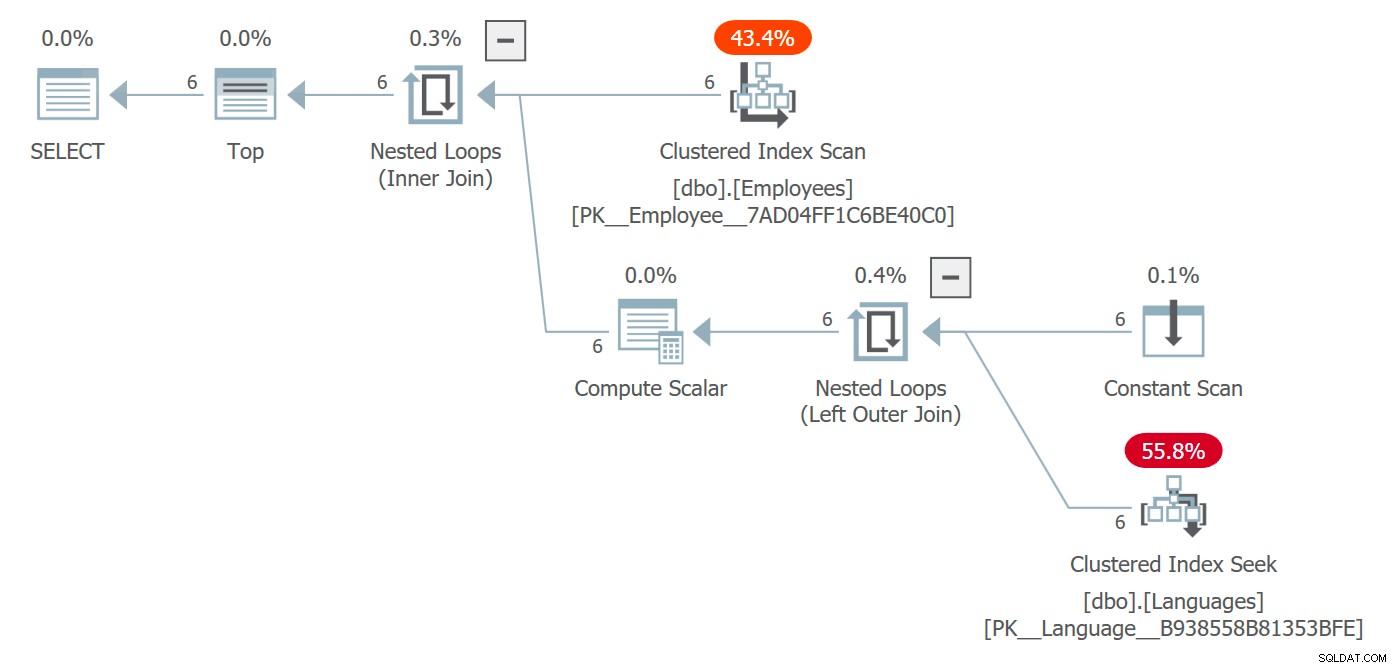 Plano que inclui acesso a objetos referenciados dentro de UDF escalar
Plano que inclui acesso a objetos referenciados dentro de UDF escalar Aqui, o otimizador escolheu uma junção de loops aninhados, mas, em circunstâncias diferentes, ele poderia ter escolhido uma estratégia de junção diferente, contemplado o paralelismo e sido essencialmente livre para alterar completamente a forma do plano. Você provavelmente não verá isso em uma consulta que retorne 6 linhas e não seja um problema de desempenho de forma alguma, mas em escalas maiores pode acontecer.
O plano reflete que a função não está sendo chamada por linha – enquanto a busca é realmente executada seis vezes, você pode ver que a função em si não aparece mais em
sys.dm_exec_function_stats . Uma desvantagem que você pode tirar é que, se você usar esse DMV para determinar se uma função está sendo usada ativamente (como costumamos fazer com procedimentos e índices), isso não será mais confiável. Advertências
Nem toda função escalar é inlineável e, mesmo quando uma função *é* inlineável, ela não será necessariamente inline em todos os cenários. Isso geralmente tem a ver com a complexidade da função, a complexidade da consulta envolvida ou a combinação de ambas. Você pode verificar se uma função é inlineável em
sys.sql_modules visualização do catálogo:SELECT OBJECT_NAME([object_id]), definition, is_inlineable FROM sys.sql_modules;
E se, por qualquer motivo, você não quiser que uma determinada função (ou qualquer função em um banco de dados) seja incorporada, você não precisa confiar no nível de compatibilidade do banco de dados para controlar esse comportamento. Nunca gostei desse acoplamento frouxo, que é como trocar de sala para assistir a um programa de televisão diferente, em vez de simplesmente mudar de canal. Você pode controlar isso no nível do módulo usando a opção INLINE:
ALTER FUNCTION dbo.GetLanguage(@id int) RETURNS sysname WITH INLINE = OFF AS BEGIN RETURN (SELECT Name FROM dbo.Languages WHERE LanguageID = @id); END GO
E você pode controlar isso no nível do banco de dados, mas separado do nível de compatibilidade:
ALTER DATABASE SCOPED CONFIGURATION SET TSQL_SCALAR_UDF_INLINING = OFF;
Embora você tenha que ter um bom caso de uso para balançar esse martelo, IMHO.
Conclusão
Agora, não estou sugerindo que você possa abstrair cada parte da lógica em uma UDF escalar e assumir que agora o SQL Server apenas cuidará de todos os casos. Se você tiver um banco de dados com muito uso de UDF escalar, baixe o CTP do SQL Server 2019 mais recente, restaure um backup do banco de dados e verifique o DMV para ver quantas dessas funções serão inlineáveis quando chegar a hora. Pode ser um grande ponto de bala na próxima vez que você estiver discutindo uma atualização, já que você terá todo esse desempenho e tempo perdido na solução de problemas de volta.
Enquanto isso, se você estiver sofrendo de desempenho escalar de UDF e não atualizar para o SQL Server 2019 tão cedo, pode haver outras maneiras de ajudar a mitigar o(s) problema(s).
Observação:escrevi e coloquei este artigo na fila antes de perceber que já havia postado um artigo diferente em outro lugar.



