Esta é a segunda parte de uma série de cinco partes que se aprofunda na maneira como os planos paralelos do modo de linha do SQL Server são iniciados. Ao final da primeira parte, criamos o contexto de execução zero para a tarefa pai. Esse contexto contém toda a árvore de operadores executáveis, mas eles ainda não estão prontos para o modelo de execução iterativo do mecanismo de processamento de consultas.
Execução iterativa
O SQL Server executa uma consulta por meio de um processo conhecido como verificação de consulta . A inicialização do plano começa na raiz pelo processador de consulta chamando
Open no nó raiz. Open chamadas percorrem a árvore de iteradores chamando recursivamente Open em cada criança até que toda a árvore seja aberta. O processo de retorno de linhas de resultados também é recursivo, acionado pelo processador de consulta que chama
GetRow Na raiz. Cada chamada de root retorna uma linha por vez. O processador de consultas continua chamando GetRow no nó raiz até que não haja mais linhas disponíveis. A execução é encerrada com um Close recursivo final ligar. Esse arranjo permite que o processador de consultas inicialize, execute e feche qualquer plano arbitrário chamando os mesmos métodos de interface apenas na raiz. Para transformar a árvore de operadores executáveis em uma adequada para processamento linha por linha, o SQL Server adiciona uma verificação de consulta wrapper para cada operador. A verificação de consulta objeto fornece o
Open , GetRow e Close métodos necessários para execução iterativa. O objeto de verificação de consulta também mantém informações de estado e expõe outros métodos específicos do operador necessários durante a execução. Por exemplo, o objeto de verificação de consulta para um operador de Filtro de Inicialização (
CQScanStartupFilterNew ) expõe os seguintes métodos:OpenGetRowClosePrepRecomputeGetScrollLockSetMarkerGotoMarkerGotoLocationReverseDirectionDormant
Os métodos adicionais para este iterador são empregados principalmente em planos de cursor.
Iniciando a verificação de consulta
O processo de encapsulamento é chamado de inicialização da verificação de consulta . Ele é executado por uma chamada do processador de consulta para
CQueryScan::InitQScanRoot . A tarefa pai executa esse processo para todo o plano (contido no contexto de execução zero). O próprio processo de tradução é recursivo por natureza, começando na raiz e descendo pela árvore. Durante esse processo, cada operador é responsável por inicializar seus próprios dados e criar quaisquer recursos de tempo de execução precisa. Isso pode incluir a criação de objetos adicionais fora do processador de consulta, por exemplo, as estruturas necessárias para se comunicar com o mecanismo de armazenamento para buscar dados do armazenamento persistente.
Um lembrete do plano de execução, com números de nós adicionados (clique para ampliar):
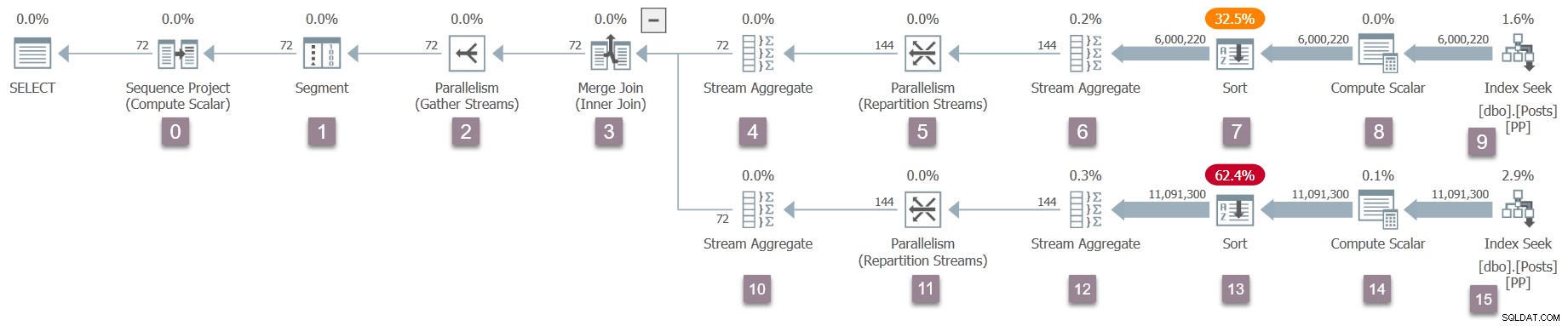
O operador na raiz (nó 0) da árvore de plano executável é um projeto de sequência . Ele é representado por uma classe chamada
CXteSeqProject . Como de costume, é aqui que a transformação recursiva começa. Invólucros de verificação de consulta
Como mencionado, o
CXteSeqProject o objeto não está equipado para participar da verificação de consulta iterativa processo — ele não tem o Open necessário , GetRow e Close métodos. O processador de consulta precisa de um wrapper em torno do operador executável para fornecer essa interface. Para obter esse wrapper de verificação de consulta, a tarefa pai chama
CXteSeqProject::QScanGet para retornar um objeto do tipo CQScanSeqProjectNew . O mapa vinculado de operadores criados anteriormente é atualizado para fazer referência ao novo objeto de verificação de consulta e seus métodos iteradores são conectados à raiz do plano. O filho do projeto de sequência é um segmento operador (nó 1). Chamando
CXteSegment::QScanGet retorna um objeto wrapper de verificação de consulta do tipo CQScanSegmentNew . O mapa vinculado é atualizado novamente e os ponteiros de função do iterador são conectados à varredura de consulta do projeto de sequência pai. Meia troca
O próximo operador é um troca de fluxos de coleta (nó 2). Chamando
CXteExchange::QScanGet retorna um CQScanExchangeNew como você já deve estar esperando. Este é o primeiro operador na árvore que precisa realizar uma inicialização extra significativa. Ele cria o lado do consumidor da troca via
CXTransport::CreateConsumerPart . Isso cria a porta (CXPort ) — uma estrutura de dados em memória compartilhada usada para sincronização e troca de dados — e um pipe (CXPipe ) para transporte de pacotes. Observe que o produtor lado da troca não foi criado nesse momento. Só temos meia troca! Mais envolvimento
O processo de configuração da verificação do processador de consultas continua com a junção de mesclagem (nó 3). Nem sempre vou repetir o
QScanGet e CQScan* chamadas a partir deste ponto, mas seguem o padrão estabelecido. A junção de mesclagem tem dois filhos. A configuração da verificação de consulta continua como antes com a entrada externa (superior) — um agregado de fluxo (nó 4), então uma repartição transmite troca (nó 5). Os fluxos de repartição novamente criam apenas o lado do consumidor da troca, mas desta vez há dois pipes criados porque DOP é dois. O lado do consumidor deste tipo de troca tem conexões DOP com seu operador pai (uma por thread).
Em seguida, temos outro agregado de fluxo (nó 6) e uma classificação (nó 7). A classificação tem um filho não visível nos planos de execução — um conjunto de linhas do mecanismo de armazenamento usado para implementar o derramamento para tempdb . O esperado
CQScanSortNew é, portanto, acompanhado por um CQScanRowsetNew filho na árvore interna. Não é visível na saída do showplan. Perfil de E/S e operações adiadas
A classificação operador também é o primeiro que inicializamos até agora que pode ser responsável por E/S . Supondo que a execução tenha solicitado dados de perfil de E/S (por exemplo, solicitando um plano 'real'), a classificação cria um objeto para registrar esses dados de perfil de tempo de execução via
CProfileInfo::AllocProfileIO . O próximo operador é um computador escalar (nó 8), chamado de projeto internamente. A chamada de configuração de verificação de consulta para
CXteProject::QScanGet não retornar um objeto de verificação de consulta, porque os cálculos executados por esse escalar de computação são diferidos para o primeiro operador pai que precisa do resultado. Neste plano, esse operador é o tipo. A classificação fará todo o trabalho atribuído ao escalar de computação, portanto, o projeto no nó 8 não faz parte da árvore de verificação de consulta. A computação escalar realmente não é executada em tempo de execução. Para obter mais detalhes sobre escalares de computação adiados, consulte Escalares de computação, expressões e desempenho do plano de execução. Verificação paralela
O operador final após a computação escalar nesta ramificação do plano é uma busca de índice (
CXteRange ) no nó 9. Isso produz o operador de verificação de consulta esperado (CQScanRangeNew ), mas também requer uma sequência complexa de inicializações para se conectar ao mecanismo de armazenamento e facilitar uma verificação paralela do índice. Apenas cobrindo os destaques, inicializando a busca do índice:
- Cria um objeto de criação de perfil para E/S (
CProfileInfo::AllocProfileIO). - Cria um conjunto de linhas paralelo verificação de consulta (
CQScanRowsetNew::ParallelGetRowset). - Configura uma sincronização objeto para coordenar a varredura de intervalo paralelo de tempo de execução (
CQScanRangeNew::GetSyncInfo). - Cria o mecanismo de armazenamento cursor de tabela e um descritor de transação somente leitura .
- Abre o conjunto de linhas pai para leitura (acessando o HoBt e fazendo as travas necessárias).
- Define o tempo limite de bloqueio.
- Configura a pré-busca (incluindo buffers de memória associados).
Adicionando operadores de perfil de modo de linha
Atingimos agora o nível folha desta ramificação do plano (o índice busca não tem filho). Tendo acabado de criar o objeto de verificação de consulta para a busca de índice, a próxima etapa é agrupar a verificação de consulta com uma classe de criação de perfil (supondo que solicitamos um plano real). Isso é feito por uma chamada para
sqlmin!PqsWrapQScan . Observe que os criadores de perfil são adicionados após a criação da verificação de consulta, à medida que começamos a subir na árvore do iterador. PqsWrapQScan cria um novo operador de criação de perfil como pai da busca de índice, por meio de uma chamada para CProfileInfo::GetOrCreateProfileInfo . O operador de criação de perfil (CQScanProfileNew ) tem os métodos usuais de interface de verificação de consulta. Além de coletar os dados necessários para os planos reais, os dados de criação de perfil também são expostos por meio do DMV sys.dm_exec_query_profiles . Consultar esse DMV neste exato momento para a sessão atual mostra que existe apenas um único operador de plano (nó 9) (o que significa que é o único envolvido por um criador de perfil):

Esta captura de tela mostra o conjunto de resultados completo do DMV no momento atual (não foi editado).
A seguir,
CQScanProfileNew chama a API do contador de desempenho de consulta (KERNEL32!QueryPerformanceCounterStub ) fornecido pelo sistema operacional para registrar o primeiro e último horário ativo do operador perfilado: 
O último horário ativo será atualizado usando a API do contador de desempenho de consulta sempre que o código desse iterador for executado.
O criador de perfil define o número estimado de linhas neste ponto do plano (
CProfileInfo::SetCardExpectedRows ), contabilizando qualquer meta de linha (CXte::CardGetRowGoal ). Como este é um plano paralelo, ele divide o resultado pelo número de threads (CXte::FGetRowGoalDefinedForOneThread ) e salva o resultado no contexto de execução. O número estimado de linhas não está visível via DMV neste momento, porque a tarefa pai não executará este operador. Em vez disso, a estimativa por thread será exposta posteriormente em contextos de execução paralela (que ainda não foram criados). No entanto, o número por thread é salvo no criador de perfil da tarefa pai - ele simplesmente não é visível no DMV.
O nome amigável do operador do plano (“Index Seek”) é então definido por meio de uma chamada para
CXteRange::GetPhysicalOp :
Antes disso, você deve ter notado que ao consultar o Detran mostrava o nome como “???”. Este é o nome permanente mostrado para operadores invisíveis (por exemplo, pré-busca de loops aninhados, classificação em lote) que não possuem um nome amigável definido.
Por fim, metadados de índice e estatísticas de E/S atuais para a busca de índice encapsulado são adicionados por meio de uma chamada para
CQScanRowsetNew::GetIoCounters :
Os contadores são zero no momento, mas serão atualizados à medida que a busca de índice executa E/S durante a execução do plano finalizado.
Mais processamento de verificação de consulta
Com o operador de criação de perfil criado para a busca de índice, o processamento de varredura de consulta volta a subir na árvore para o classificação pai (nó 7).
A classificação executa as seguintes tarefas de inicialização:
- Registra seu uso de memória com a consulta gerenciador de memória (
CQryMemManager::RegisterMemUsage) - Calcula a memória necessária para a entrada de classificação (
CQScanIndexSortNew::CbufInputMemory) e saída (CQScanSortNew::CbufOutputMemory). - A tabela de classificação é criado, juntamente com seu conjunto de linhas do mecanismo de armazenamento associado (
sqlmin!RowsetSorted). - Uma transação do sistema independente (não limitado pela transação do usuário) é criado para alocações de disco spill de classificação, juntamente com uma tabela de trabalho falsa (
sqlmin!CreateFakeWorkTable). - O serviço de expressão é inicializado (
sqlTsEs!CEsRuntime::Startup) para que o operador de classificação execute os cálculos adiados do escalar de computação. - Pré-busca para qualquer tipo de execução é derramado para tempdb é então criado via (
CPrefetchMgr::SetupPrefetch).
Por fim, a varredura de consulta de classificação é envolvida por um operador de criação de perfil (incluindo E/S), exatamente como vimos para a busca de índice:

Observe que a computação escalar (nó 8) está ausente do Detran. Isso ocorre porque seu trabalho é adiado para a classificação, não faz parte da árvore de verificação de consulta e, portanto, não possui objeto de perfilador de encapsulamento.
Movendo-se para o pai da classificação, a agregação de fluxo operador de verificação de consulta (nó 6) inicializa suas expressões e contadores de tempo de execução (por exemplo, contagem de linhas do grupo atual). A agregação de fluxo é encapsulada com um operador de criação de perfil, registrando seus tempos iniciais:

A repartição pai transmite troca (nó 5) é encapsulado por um criador de perfil (lembre-se que apenas o lado do consumidor desta troca existe neste momento):

O mesmo é feito para o agregado de stream pai (nó 4), que também é inicializado conforme descrito anteriormente:

O processamento de verificação de consulta retorna à junção de mesclagem pai (nó 3), mas ainda não o inicializa. Em vez disso, movemos para baixo o lado interno (inferior) da junção de mesclagem, executando as mesmas tarefas detalhadas para esses operadores (nós 10 a 15) conforme feito para a ramificação superior (externa):
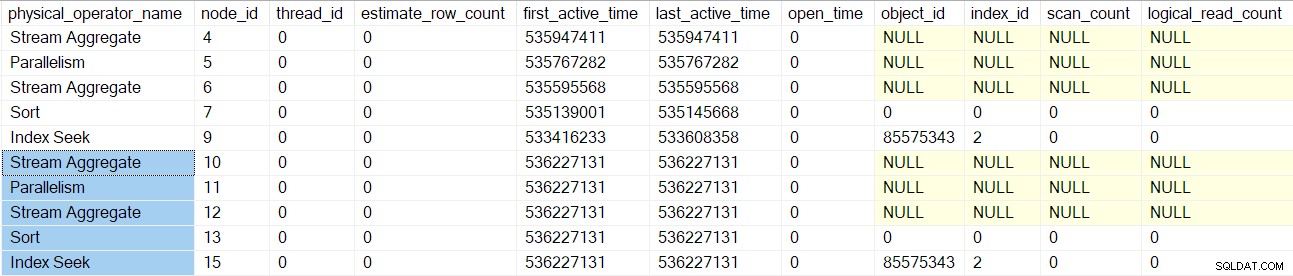
Depois que esses operadores forem processados, a junção de mesclagem a verificação de consulta é criada, inicializada e encapsulada com um objeto de criação de perfil. Isso inclui contadores de E/S porque uma junção de mesclagem muitos-muitos usa uma tabela de trabalho (mesmo que a junção de mesclagem atual seja um-muitos):
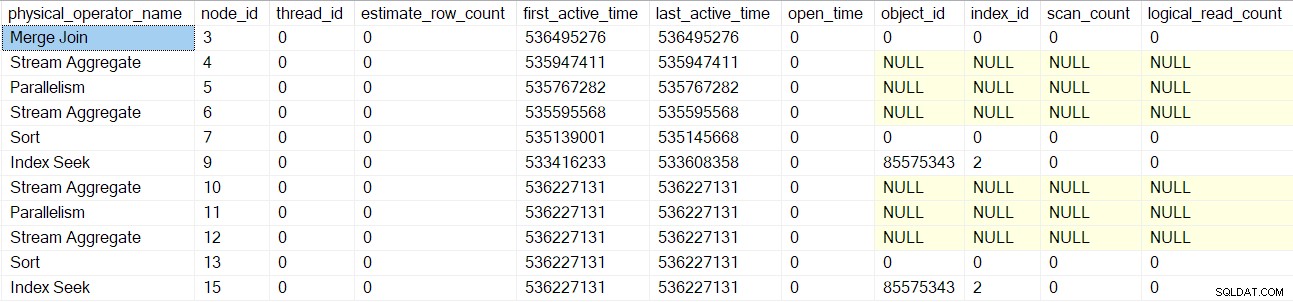
O mesmo processo é seguido para os fluxos de coleta pai exchange (nó 2) somente lado do consumidor, segmento (nó 1) e projeto de sequência (nó 0) operadores. Não vou descrevê-los em detalhes.
O DMV dos perfis de consulta agora relata um conjunto completo de nós de verificação de consulta encapsulados pelo criador de perfil:
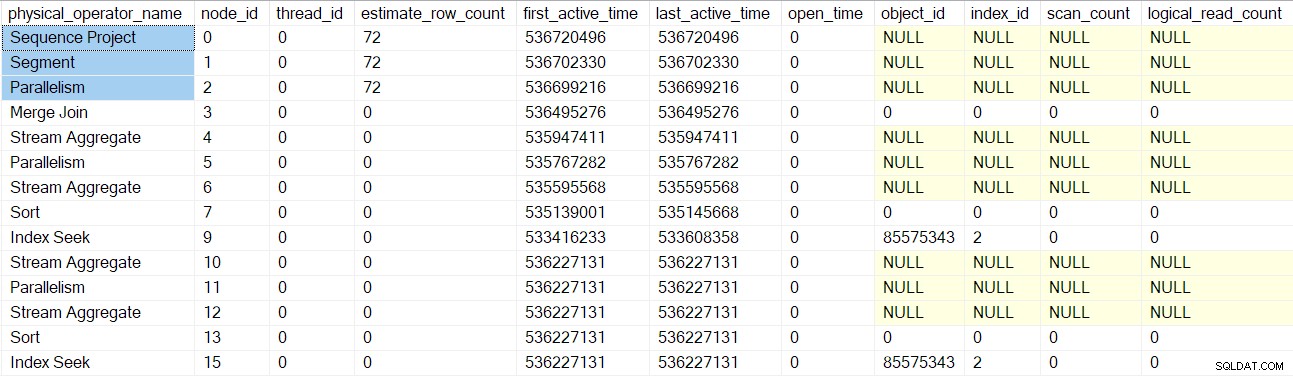
Observe que o consumidor de fluxos de projeto, segmento e coleta de sequência tem uma contagem de linhas estimada porque esses operadores serão executados pela tarefa pai , não por tarefas paralelas adicionais (consulte
CXte::FGetRowGoalDefinedForOneThread mais cedo). A tarefa pai não tem trabalho a fazer em ramificações paralelas, portanto, o conceito de contagem de linhas estimada só faz sentido para tarefas adicionais. Os valores de tempo ativo mostrados acima estão um pouco distorcidos porque eu precisava parar a execução e tirar screenshots do DMV em cada etapa. Uma execução separada (sem os atrasos artificiais introduzidos usando um depurador) produziu os seguintes tempos:
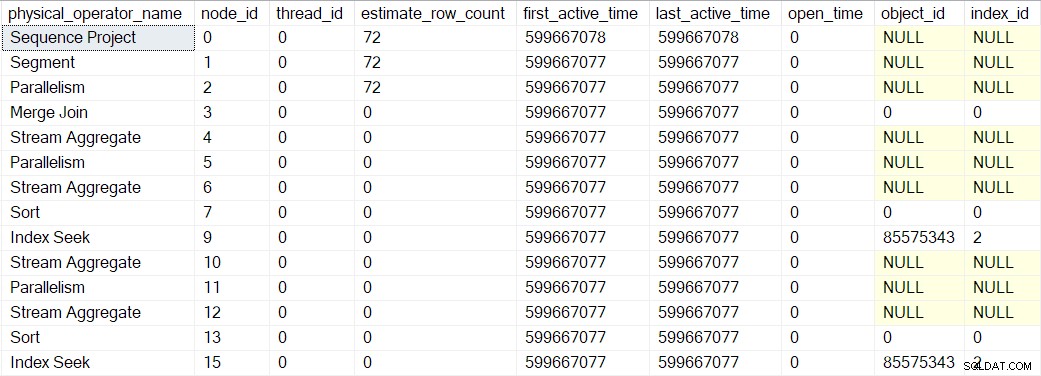
A árvore é construída na mesma sequência descrita anteriormente, mas o processo é tão rápido que leva apenas 1 microssegundo diferença entre o tempo ativo do primeiro operador encapsulado (a busca de índice no nó 9) e o último (projeto de sequência no nó 0).
Fim da Parte 2
Pode parecer que fizemos muito trabalho, mas lembre-se de que criamos apenas uma árvore de verificação de consulta para a tarefa pai , e as trocas têm apenas um lado do consumidor (ainda sem produtor). Nosso plano paralelo também tem apenas um thread (como mostrado na última captura de tela). A Parte 3 verá a criação de nossas primeiras tarefas paralelas adicionais.