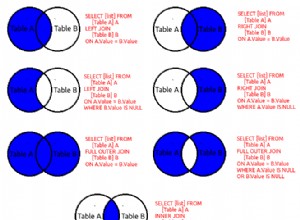
Introdução
Neste artigo, discutiremos como os diferentes tipos de índices nas tabelas com otimização de memória do SQL Server afetam o desempenho. Examinaremos exemplos de como diferentes tipos de índice podem afetar o desempenho de tabelas com otimização de memória.
Para facilitar a discussão do tópico, faremos uso de um exemplo bastante amplo. Para fins de simplicidade, este exemplo apresentará diferentes réplicas de uma única tabela, na qual executaremos consultas diferentes. Essas réplicas usarão índices diferentes ou nenhum índice (exceto, é claro, as chaves primárias – PKs).
Observe que o objetivo real deste artigo não é comparar o desempenho entre tabelas baseadas em disco e com otimização de memória no SQL Server em si. Seu objetivo é examinar como os índices afetam o desempenho em tabelas com otimização de memória. No entanto, para ter uma visão completa dos experimentos, os tempos também são fornecidos para as consultas de tabela baseadas em disco correspondentes e os aumentos de velocidade são calculados usando a configuração mais ideal de tabelas baseadas em disco como linhas de base.
Cenário
Os dados de amostra para nosso cenário são baseados em uma única tabela definida da seguinte forma:
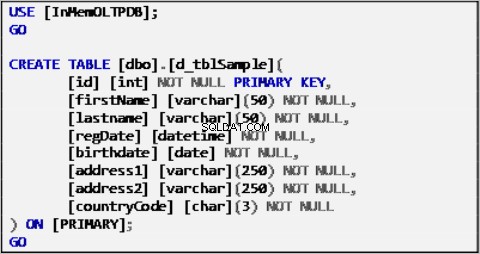
Lista 1:Exemplo de tabela de fontes de dados.
A tabela acima foi preenchida com dados de amostra e atuará como fonte de dados para o restante das tabelas.
Assim, com base na tabela acima, criamos as 9 variações de tabela a seguir e as preenchemos com os mesmos dados de amostra:
- 3 tabelas baseadas em disco:
- d_tblSample1
- Índice clusterizado na coluna “id” – chave primária (PK)
- d_tblSample2
- Índice agrupado na coluna "id" (PK)
- Índice não agrupado na coluna "countryCode"
- d_tblSample3
- Índice agrupado na coluna "id" (PK)
- Índices não agrupados na coluna "regDate"
- Índices não agrupados na coluna "countryCode"
- d_tblSample1
- 3 tabelas com otimização de memória (conjunto 1:índices de hash):
- m1_tblAmostra1
- Índice de hash não clusterizado na coluna “id” – chave primária (PK)
- m1_tblAmostra2
- Índice de hash não clusterizado na coluna "id" (PK)
- Índice de hash na coluna "countryCode"
- m1_tblSample3
- Índice de hash não clusterizado na coluna "id" (PK)
- Índice de hash na coluna "regDate"
- Índice de hash na coluna "countryCode"
- 3 tabelas com otimização de memória (conjunto 2:índices não agrupados):
- m2_tblAmostra1
- Índice não clusterizado na coluna “id” – chave primária (PK)
- m2_tblSample2
- Índice não agrupado na coluna "id" (PK)
- Índice não agrupado na coluna "countryCode"
- m2_tblSample3
- Índice não agrupado na coluna "id" (PK)
- Índice não agrupado na coluna "regDate"
- Índice não agrupado na coluna "countryCode"
- m2_tblAmostra1
- m1_tblAmostra1
Nas listagens abaixo, você pode encontrar as definições para as tabelas acima.
A lógica do cenário é que realizamos diferentes operações de banco de dados contra variações da mesma tabela (mas com índices diferentes) e observamos como o desempenho é afetado em cada caso.
Definições
Tabelas baseadas em disco
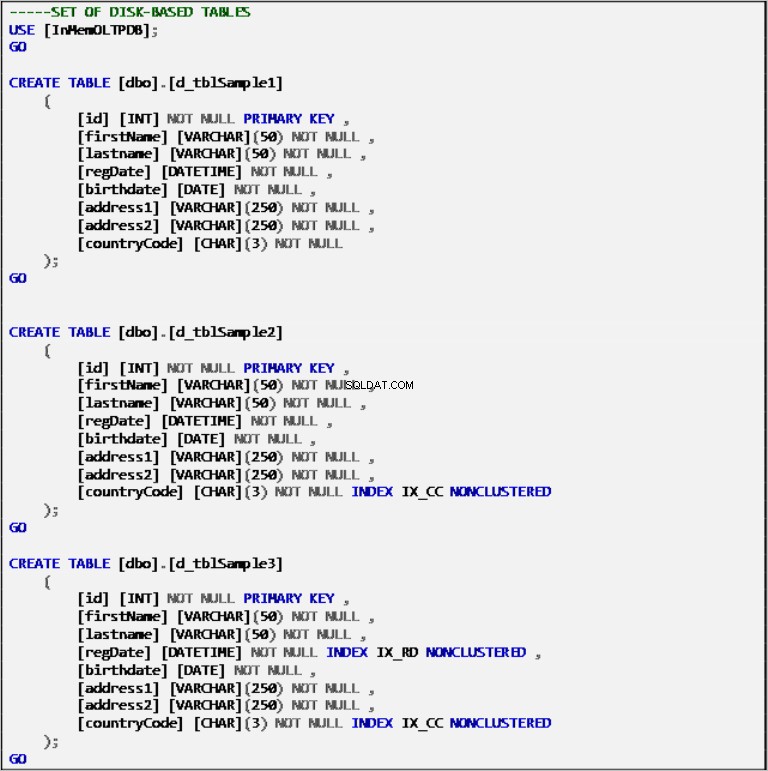
Lista 2:definição de tabelas baseadas em disco.
Tabelas otimizadas para memória (conjunto 1:índices de hash)

Listagem 3:tabelas com otimização de memória – conjunto 1 (índices de hash).
Tabelas otimizadas para memória (conjunto 2:índices não agrupados)

Listagem 4:tabelas com otimização de memória – conjunto 2 (índices não agrupados).
Em seguida, preenchemos todas as tabelas acima com os mesmos dados de amostra, que totalizam 5 milhões de registros em cada tabela.
Aqui está a saída do comando count para cada conjunto de tabelas:
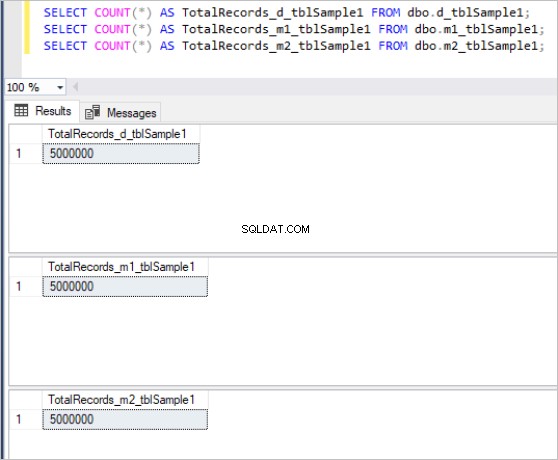
Figura 1:número total de registros para o primeiro conjunto de tabelas.
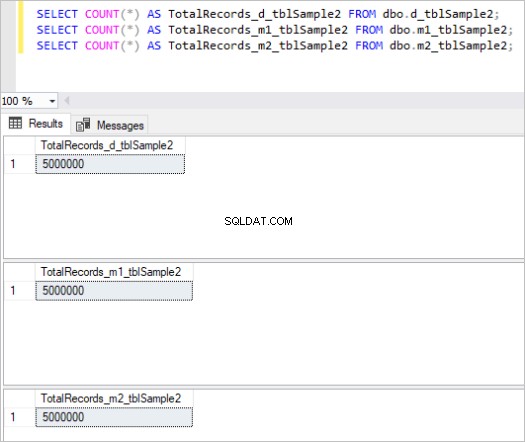
Figura 2:número total de registros para o segundo conjunto de tabelas.
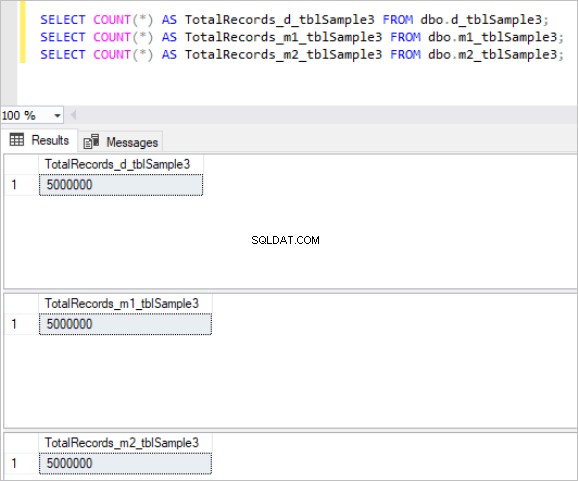
Figura 3:número total de registros para o terceiro conjunto de tabelas.
Consultas e execuções de cenários
Agora, vamos executar um conjunto de consultas nas tabelas acima e ver o desempenho de cada tabela.
Essas consultas realizam as seguintes operações:
- Consulta 1:agregação (GROUP BY)
- Consulta 2:busca de índice em predicados de igualdade
- Consulta 3:busca de índice sobre predicados de igualdade e desigualdade
O plano é executar as consultas conforme abaixo:
Consulta 1 – Execução nas seguintes tabelas:
- d_tblAmostra3
- m1_tblAmostra3
- m2_tblAmostra3
- m1_tblSample1 (sem índice nas colunas de destino)
- m2_tblSample1 (sem índice nas colunas de destino)
Consulta 2 – Execução nas seguintes tabelas:
- d_tblAmostra2
- m1_tblAmostra2
- m2_tblAmostra2
- m1_tblSample1 (sem índice nas colunas de destino)
- m2_tblSample1 (sem índice nas colunas de destino)
Consulta 3 – Execução nas seguintes tabelas:
- d_tblAmostra3
- m1_tblAmostra3
- m2_tblAmostra3
- m1_tblSample1 (sem índice nas colunas de destino)
- m2_tblSample1 (sem índice nas colunas de destino)
Observação :mesmo que a definição de d_tblSample1 tabela baseada em disco está incluída nas definições de tabela acima, ela não é usada nas consultas fornecidas neste artigo. A razão é que, em cada cenário, a configuração mais otimizada possível para a tabela baseada em disco é usada, pois queremos que nossa linha de base seja a mais rápida possível quando comparada com o desempenho das tabelas com otimização de memória. Para isso, o d_tblSample1 tabela é apresentada apenas para fins informativos.
Abaixo você encontra os scripts T-SQL para as três consultas junto com os mecanismos de medição do tempo de execução.

Listagem 5:Consulta 1 – Agregação (com índices).
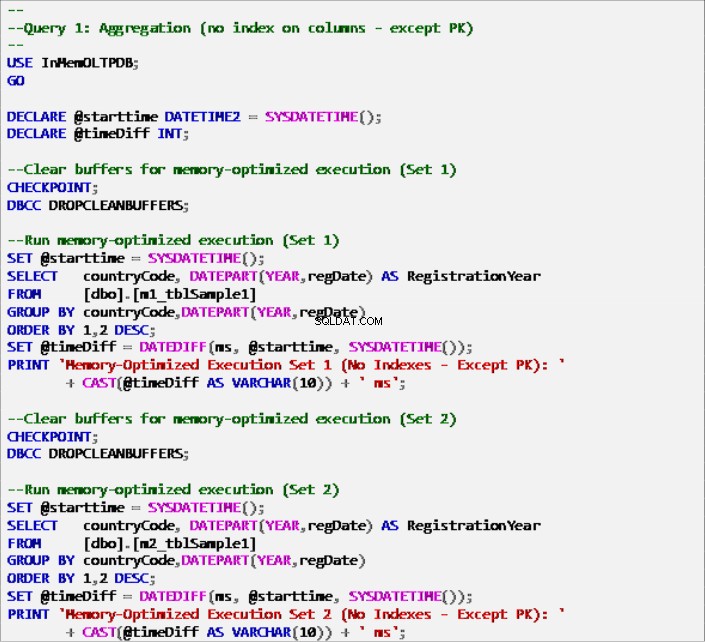
Listagem 6:consulta 1 – agregação (sem índices – exceto chave primária).
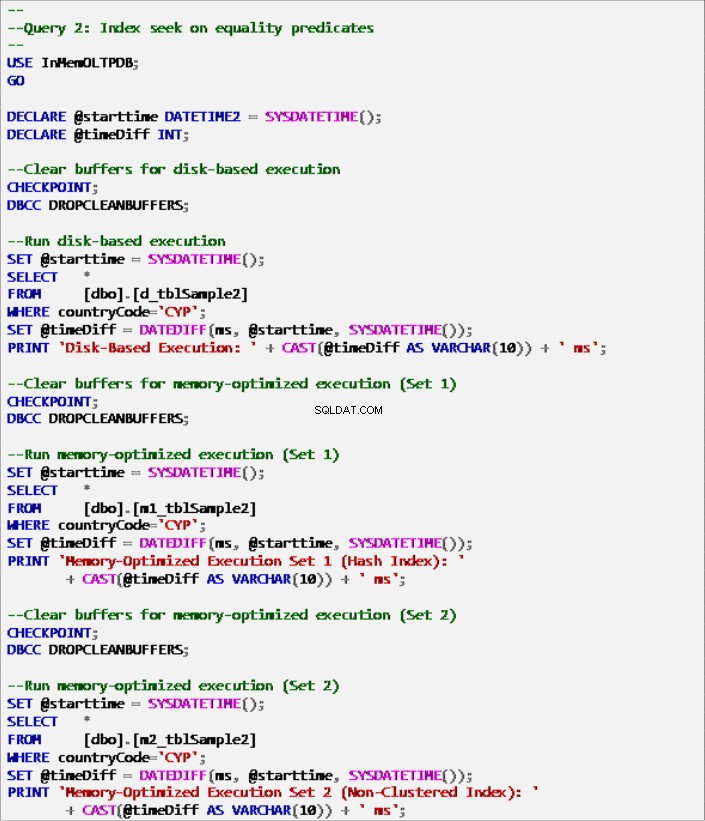
Listagem 7:Consulta 2 – Busca de índice em predicados de igualdade (com índices).

Listagem 8:Consulta 2 – Busca de índice em predicados de igualdade (sem índices – exceto chave primária).
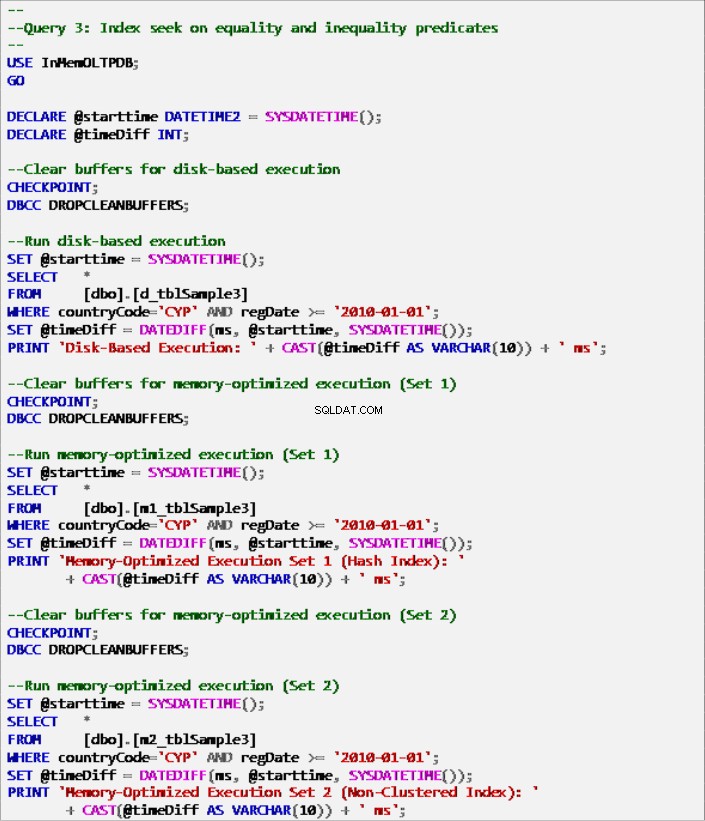
Listagem 9:Consulta 3 – Busca de índice em predicados de igualdade e desigualdade (com índices).

Listagem 10:Consulta 3 – Busca de índice em predicados de igualdade e desigualdade (sem índices – exceto chave primária).
As capturas de tela abaixo mostram a saída de cada execução de consulta:
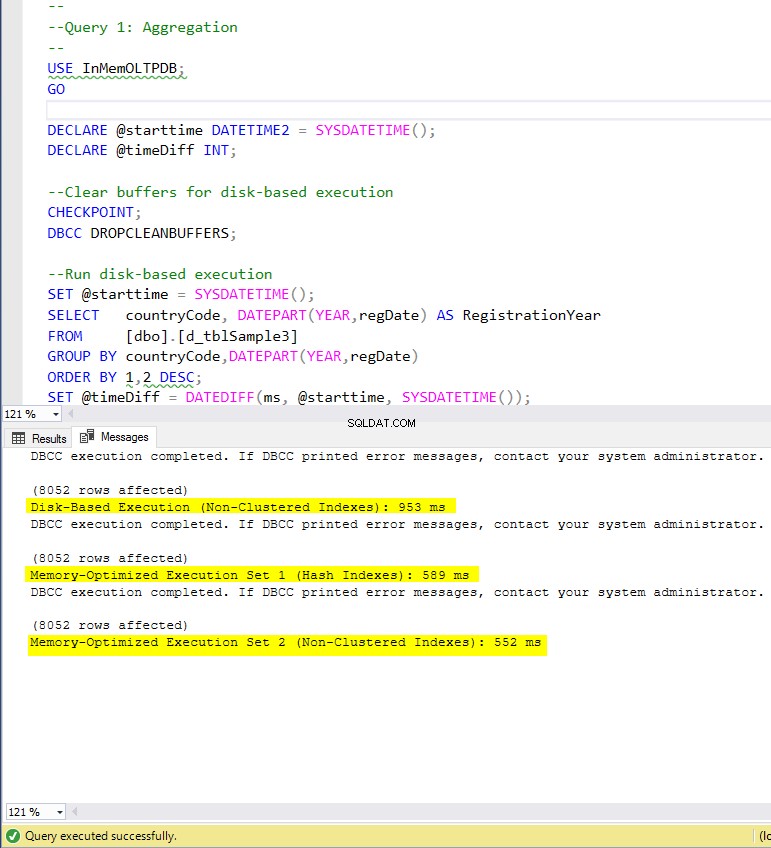
Figura 4:tempo de execução da consulta 1 (com índices).
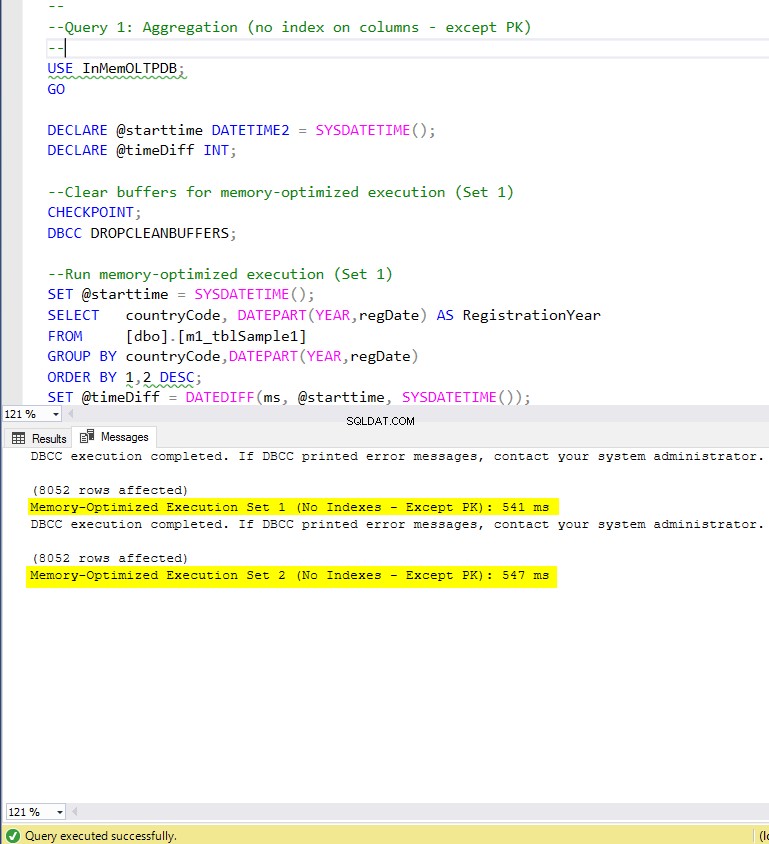
Figura 5:tempo de execução da consulta 1 (sem índices – exceto PK).
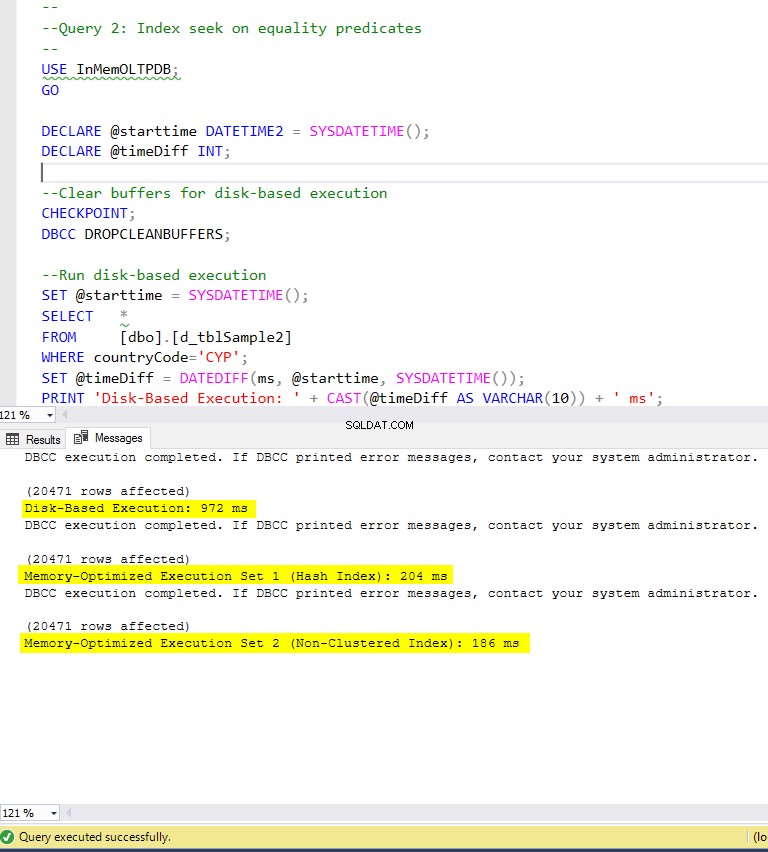
Figura 6:tempo de execução da consulta 2 (com índices).
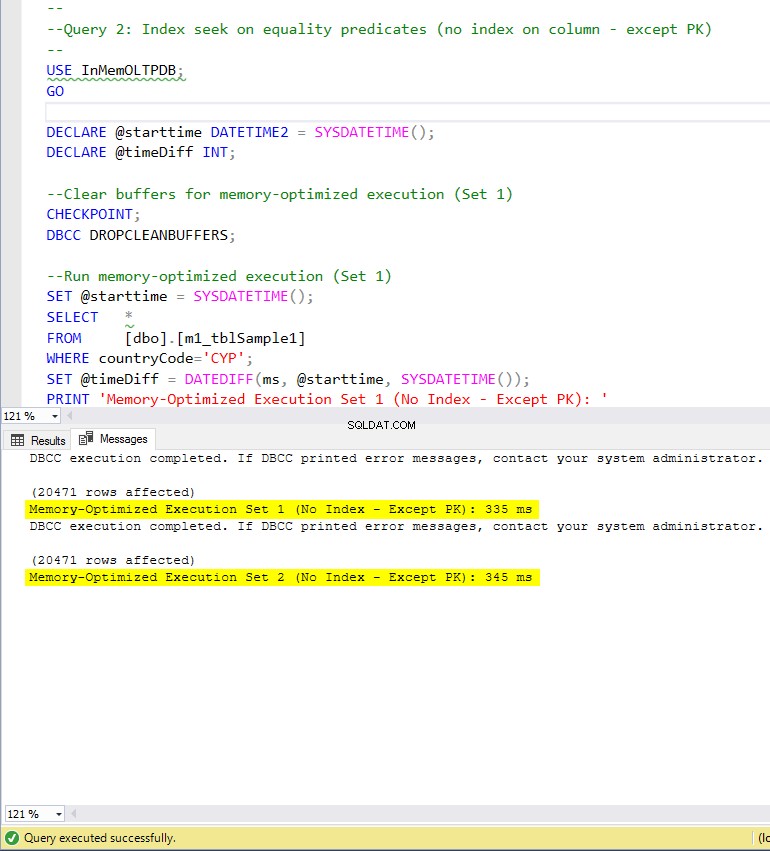
Figura 7:tempo de execução da consulta 2 (sem índices – exceto PK).
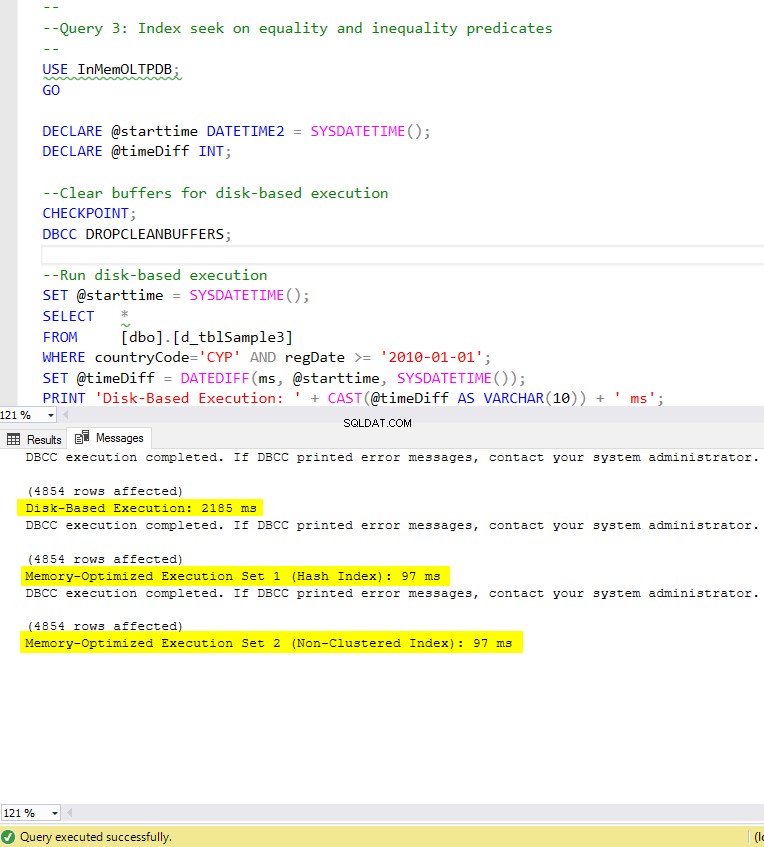
Figura 8:tempo de execução da consulta 3 (com índices).
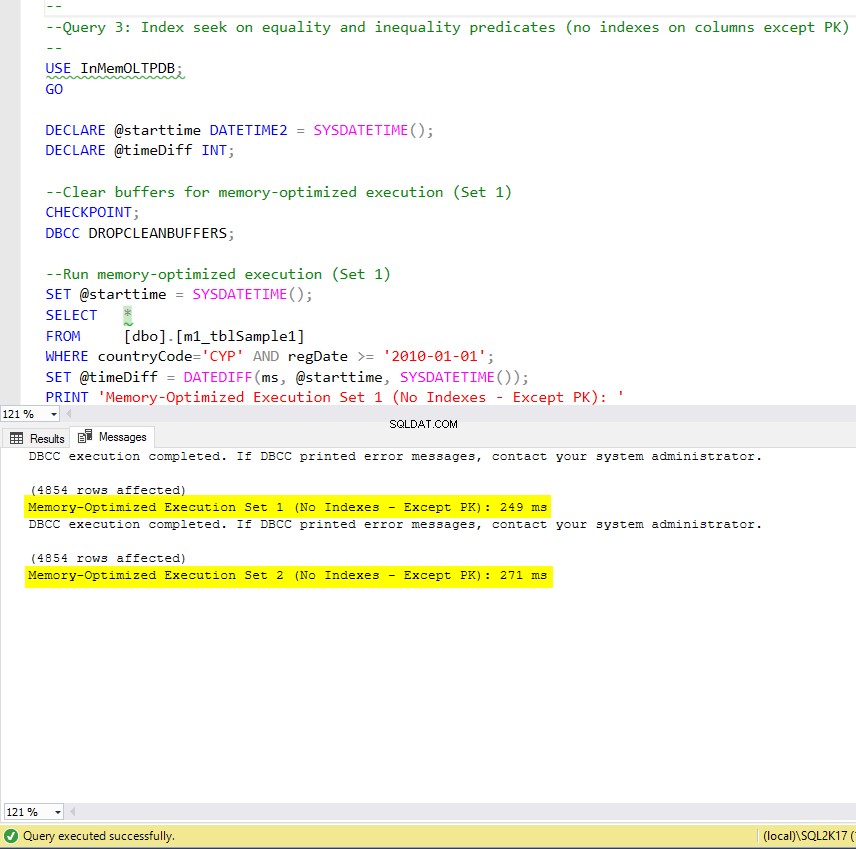
Figura 9:tempo de execução da consulta 3 (sem índices – exceto PK).
Agora, vamos resumir os resultados obtidos acima. A tabela a seguir exibe os tempos de execução medidos para todas as consultas acima e combinações de tabela/índice.
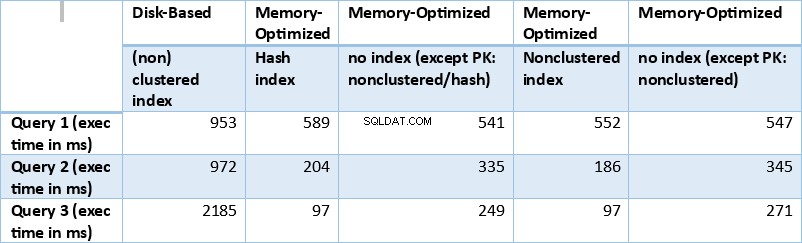
Tabela 1:Resumo dos tempos de execução (ms) para todas as consultas.
Discussão
Se examinarmos os resultados da execução resumidos na tabela acima, podemos chegar a algumas conclusões. Vamos plotar cada resultado da consulta em um gráfico. Os gráficos abaixo ilustram os tempos de execução, bem como a aceleração das tabelas com otimização de memória em relação às tabelas baseadas em disco.
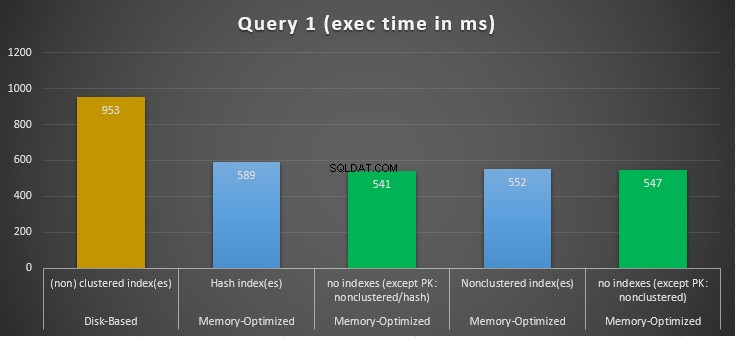
Figura 10:Comparação dos tempos de execução da consulta 1.
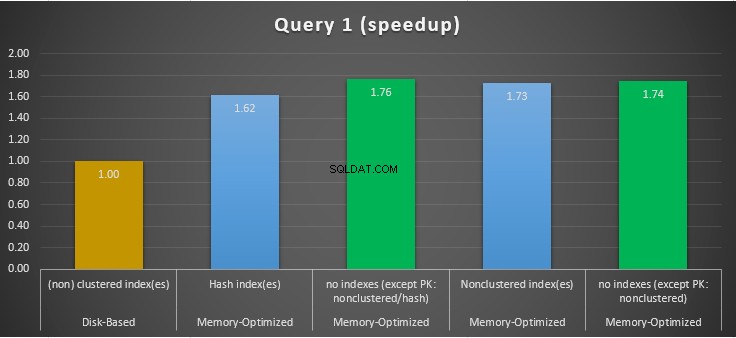
Figura 11:comparação de aceleração da consulta 1.
Em relação à consulta 1, que era uma agregação GROUP BY, podemos ver que ambas as versões (índices vs sem índices) de tabelas com otimização de memória, executam quase o mesmo tendo um speedup sobre a tabela baseada em disco (habilitada com índices) entre 1,62 e 1,76 vezes mais rápido.
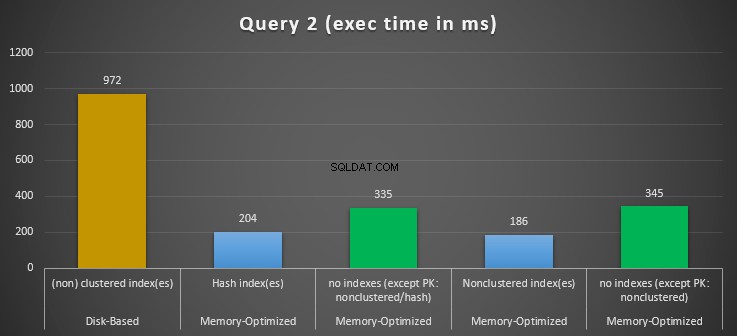
Figura 12:Comparação dos tempos de execução da consulta 2.
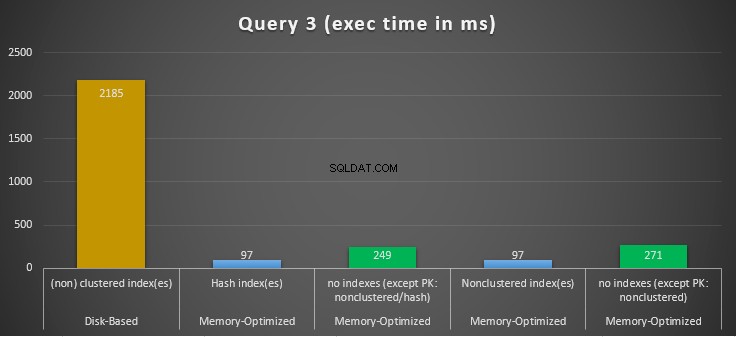
Figura 13:comparação de aceleração da consulta 2.
Em relação à Consulta 2, que envolveu uma busca de índice em predicados de igualdade, podemos ver que as tabelas com otimização de memória com índices tiveram um desempenho muito melhor do que as tabelas com otimização de memória sem índices. Além disso, observamos que a tabela com otimização de memória com índice não clusterizado na coluna usada como predicado teve um desempenho melhor do que aquela com o índice de hash.
Portanto, para a consulta 2, a vencedora é a tabela com otimização de memória com o índice não clusterizado, com uma aceleração geral de 5,23 vezes mais rápido do que a execução baseada em disco.
Figura 14:Comparação dos tempos de execução da consulta 3.
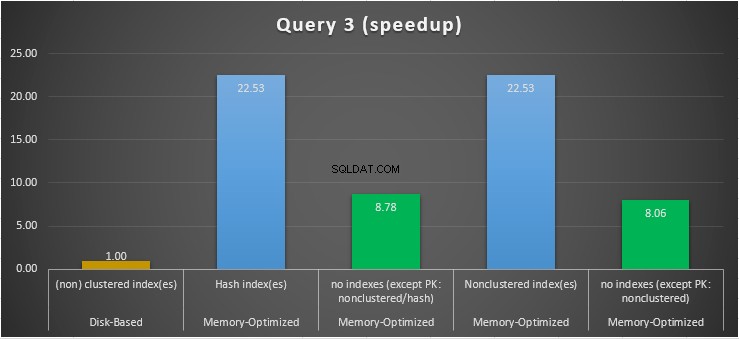
Figura 15:comparação de aceleração da consulta 3.
Em relação à Consulta 3, que envolveu uma busca de índice sobre predicados de igualdade e desigualdade combinados, podemos ver que as tabelas com otimização de memória com índices tiveram um desempenho muito melhor do que as tabelas com otimização de memória sem índices. Além disso, observamos que a tabela com otimização de memória com índice não clusterizado na coluna usada como predicado teve o mesmo desempenho daquela com o índice de hash.
Para isso, podemos ver que ambas as tabelas com otimização de memória que utilizam índices nas colunas usadas como predicados, tiveram um desempenho mais rápido do que aquelas sem índices e alcançaram uma aceleração de 22,53 vezes sobre a execução baseada em disco.
Conclusão
Neste artigo, examinamos o uso de índices em tabelas com otimização de memória no SQL Server. Usamos como linha de base para cada consulta a melhor configuração de tabela baseada em disco possível e, em seguida, comparamos o desempenho de três consultas com as tabelas baseadas em disco e 4 variações de tabelas com otimização de memória. Duas das quatro tabelas com otimização de memória usaram índices (hash/não clusterizados) e as outras duas não usaram índices, exceto os usados para as chaves primárias.
A conclusão geral é que você sempre precisa examinar como os índices afetam o desempenho, não apenas para tabelas com otimização de memória, mas também para tabelas baseadas em disco, e sempre que identificar que eles melhoram o desempenho, use-os. As descobertas dos exemplos deste artigo mostram que, se você usar os índices adequados em tabelas com otimização de memória, poderá obter um desempenho muito melhor para consultas semelhantes às usadas neste artigo em comparação com apenas usar tabelas com otimização de memória sem índices .
Referências e leitura adicional:
- Microsoft Docs:tabelas com otimização de memória
- Microsoft Docs:Diretrizes para usar índices em tabelas com otimização de memória
- Microsoft Docs:índices em tabelas com otimização de memória
Ferramenta útil:
dbForge Index Manager – suplemento SSMS útil para analisar o status de índices SQL e corrigir problemas com fragmentação de índice.