Todo sistema de banco de dados moderno suporta um módulo Query Optimizer para identificar automaticamente a estratégia mais eficiente para executar as consultas SQL. A estratégia eficiente é chamada de “Plano” e é medida em termos de custo que é diretamente proporcional ao “Tempo de Execução/Resposta da Consulta”. O plano é representado na forma de uma saída em árvore do Query Optimizer. Os nós da árvore do plano podem ser divididos principalmente nas 3 categorias a seguir:
- Verificar nós :Conforme explicado no meu blog anterior “Uma visão geral dos vários métodos de varredura no PostgreSQL”, ele indica a maneira como os dados da tabela base precisam ser buscados.
- Juntar nós :Conforme explicado no meu blog anterior “Uma visão geral dos métodos JOIN no PostgreSQL”, ele indica como duas tabelas precisam ser unidas para obter o resultado de duas tabelas.
- Nós de materialização :também chamados de nós auxiliares. Os dois tipos de nós anteriores estavam relacionados a como buscar dados de uma tabela base e como unir dados recuperados de duas tabelas. Os nós nesta categoria são aplicados em cima dos dados recuperados para analisar ou preparar relatórios adicionais, etc. Classificando os dados, agregando dados etc.
Considere um exemplo de consulta simples como...
SELECT * FROM TBL1, TBL2 where TBL1.ID > TBL2.ID order by TBL.ID;Suponha um plano gerado correspondente à consulta conforme abaixo:
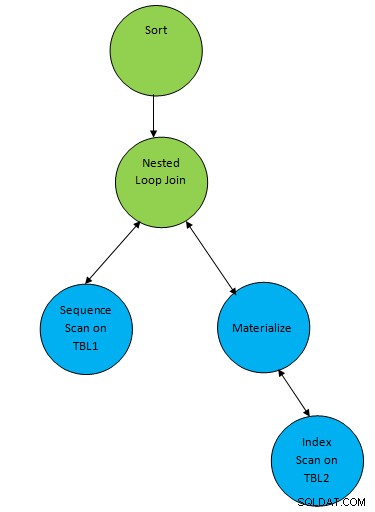
Aqui um nó auxiliar “Sort” é adicionado ao resultado de join para classificar os dados na ordem necessária.
Alguns dos nós auxiliares gerados pelo otimizador de consultas do PostgreSQL são os seguintes:
- Classificar
- Agregar
- Agrupar por agregado
- Limite
- Único
- LockRows
- SetOp
Vamos entender cada um desses nós.
Classificar
Como o nome sugere, este nó é adicionado como parte de uma árvore de plano sempre que houver necessidade de dados ordenados. Os dados classificados podem ser necessários de forma explícita ou implícita, como nos dois casos abaixo:
O cenário do usuário requer dados classificados como saída. Nesse caso, o nó de classificação pode estar no topo de toda a recuperação de dados, incluindo todos os outros processamentos.
postgres=# CREATE TABLE demotable (num numeric, id int);
CREATE TABLE
postgres=# INSERT INTO demotable SELECT random() * 1000, generate_series(1, 10000);
INSERT 0 10000
postgres=# analyze;
ANALYZE
postgres=# explain select * from demotable order by num;
QUERY PLAN
----------------------------------------------------------------------
Sort (cost=819.39..844.39 rows=10000 width=15)
Sort Key: num
-> Seq Scan on demotable (cost=0.00..155.00 rows=10000 width=15)
(3 rows)Observação: Mesmo que o usuário tenha exigido a saída final em ordem de classificação, o nó de classificação não pode ser adicionado no plano final se houver um índice na tabela e coluna de classificação correspondentes. Nesse caso, ele pode escolher a varredura de índice que resultará na ordem classificada implicitamente de dados. Por exemplo, vamos criar um índice no exemplo acima e ver o resultado:
postgres=# CREATE INDEX demoidx ON demotable(num);
CREATE INDEX
postgres=# explain select * from demotable order by num;
QUERY PLAN
--------------------------------------------------------------------------------
Index Scan using demoidx on demotable (cost=0.29..534.28 rows=10000 width=15)
(1 row)Como explicado em meu blog anterior Uma visão geral dos métodos JOIN no PostgreSQL, o Merge Join requer que ambos os dados da tabela sejam classificados antes da junção. Portanto, pode acontecer que o Merge Join seja mais barato do que qualquer outro método de junção, mesmo com um custo adicional de classificação. Portanto, neste caso, o nó Sort será adicionado entre o método join e scan da tabela para que os registros classificados possam ser passados para o método join.
postgres=# create table demo1(id int, id2 int);
CREATE TABLE
postgres=# insert into demo1 values(generate_series(1,1000), generate_series(1,1000));
INSERT 0 1000
postgres=# create table demo2(id int, id2 int);
CREATE TABLE
postgres=# create index demoidx2 on demo2(id);
CREATE INDEX
postgres=# insert into demo2 values(generate_series(1,100000), generate_series(1,100000));
INSERT 0 100000
postgres=# analyze;
ANALYZE
postgres=# explain select * from demo1, demo2 where demo1.id=demo2.id;
QUERY PLAN
------------------------------------------------------------------------------------
Merge Join (cost=65.18..109.82 rows=1000 width=16)
Merge Cond: (demo2.id = demo1.id)
-> Index Scan using demoidx2 on demo2 (cost=0.29..3050.29 rows=100000 width=8)
-> Sort (cost=64.83..67.33 rows=1000 width=8)
Sort Key: demo1.id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(6 rows)Agregado
O nó agregado é adicionado como parte de uma árvore de plano se houver uma função agregada usada para calcular resultados únicos de várias linhas de entrada. Algumas das funções agregadas usadas são COUNT, SUM, AVG (AVERAGE), MAX (MAXIMUM) e MIN (MINIMUM).
Um nó agregado pode vir no topo de uma varredura de relação de base ou (e) na junção de relações. Exemplo:
postgres=# explain select count(*) from demo1;
QUERY PLAN
---------------------------------------------------------------
Aggregate (cost=17.50..17.51 rows=1 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=0)
(2 rows)
postgres=# explain select sum(demo1.id) from demo1, demo2 where demo1.id=demo2.id;
QUERY PLAN
-----------------------------------------------------------------------------------------------
Aggregate (cost=112.32..112.33 rows=1 width=8)
-> Merge Join (cost=65.18..109.82 rows=1000 width=4)
Merge Cond: (demo2.id = demo1.id)
-> Index Only Scan using demoidx2 on demo2 (cost=0.29..3050.29 rows=100000 width=4)
-> Sort (cost=64.83..67.33 rows=1000 width=4)
Sort Key: demo1.id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)HashAggregate / GroupAggregate
Esses tipos de nós são extensões do nó “Agregado”. Se as funções agregadas forem usadas para combinar várias linhas de entrada de acordo com seu grupo, esses tipos de nós serão adicionados a uma árvore de plano. Portanto, se a consulta tiver alguma função de agregação usada e junto com ela houver uma cláusula GROUP BY na consulta, o nó HashAggregate ou GroupAggregate será adicionado à árvore do plano.
Como o PostgreSQL usa o Cost Based Optimizer para gerar uma árvore de plano ideal, é quase impossível adivinhar quais desses nós serão usados. Mas vamos entender quando e como ele é usado.
HashAggregate
HashAggregate funciona construindo a tabela de hash dos dados para agrupá-los. Portanto, HashAggregate pode ser usado pela agregação de nível de grupo se a agregação estiver ocorrendo em um conjunto de dados não classificado.
postgres=# explain select count(*) from demo1 group by id2;
QUERY PLAN
---------------------------------------------------------------
HashAggregate (cost=20.00..30.00 rows=1000 width=12)
Group Key: id2
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)
(3 rows)Aqui os dados do esquema da tabela demo1 são conforme o exemplo mostrado na seção anterior. Como há apenas 1.000 linhas para agrupar, o recurso necessário para criar uma tabela de hash é menor que o custo de classificação. O planejador de consultas decide escolher HashAggregate.
GrupoAgregado
GroupAggregate funciona em dados classificados, portanto, não requer nenhuma estrutura de dados adicional. GroupAggregate pode ser usado por agregação de nível de grupo se a agregação estiver em um conjunto de dados classificado. Para agrupar em dados classificados, ele pode classificar explicitamente (adicionando o nó Sort) ou pode funcionar em dados buscados por índice, caso em que é classificado implicitamente.
postgres=# explain select count(*) from demo2 group by id2;
QUERY PLAN
-------------------------------------------------------------------------
GroupAggregate (cost=9747.82..11497.82 rows=100000 width=12)
Group Key: id2
-> Sort (cost=9747.82..9997.82 rows=100000 width=4)
Sort Key: id2
-> Seq Scan on demo2 (cost=0.00..1443.00 rows=100000 width=4)
(5 rows) Aqui os dados do esquema da tabela demo2 são conforme o exemplo mostrado na seção anterior. Como aqui há 100.000 linhas para agrupar, o recurso necessário para construir a tabela de hash pode ser mais caro do que o custo de classificação. Assim, o planejador de consultas decide escolher GroupAggregate. Observe aqui que os registros selecionados da tabela “demo2” são classificados explicitamente e para os quais há um nó adicionado na árvore do plano.
Veja abaixo outro exemplo, onde os dados já são recuperados e classificados por causa da varredura de índice:
postgres=# create index idx1 on demo1(id);
CREATE INDEX
postgres=# explain select sum(id2), id from demo1 where id=1 group by id;
QUERY PLAN
------------------------------------------------------------------------
GroupAggregate (cost=0.28..8.31 rows=1 width=12)
Group Key: id
-> Index Scan using idx1 on demo1 (cost=0.28..8.29 rows=1 width=8)
Index Cond: (id = 1)
(4 rows) Veja abaixo mais um exemplo, que apesar de ter Index Scan, ainda precisa classificar explicitamente como a coluna em que o índice ali e a coluna de agrupamento não são os mesmos. Portanto, ainda precisa classificar de acordo com a coluna de agrupamento.
postgres=# explain select sum(id), id2 from demo1 where id=1 group by id2;
QUERY PLAN
------------------------------------------------------------------------------
GroupAggregate (cost=8.30..8.32 rows=1 width=12)
Group Key: id2
-> Sort (cost=8.30..8.31 rows=1 width=8)
Sort Key: id2
-> Index Scan using idx1 on demo1 (cost=0.28..8.29 rows=1 width=8)
Index Cond: (id = 1)
(6 rows)Observação: GroupAggregate/HashAggregate pode ser usado para muitas outras consultas indiretas, mesmo que a agregação com o grupo não esteja na consulta. Depende de como o planejador interpreta a consulta. Por exemplo. Digamos que precisamos obter um valor distinto da tabela, então ele pode ser visto como um grupo pela coluna correspondente e, em seguida, obter um valor de cada grupo.
postgres=# explain select distinct(id) from demo1;
QUERY PLAN
---------------------------------------------------------------
HashAggregate (cost=17.50..27.50 rows=1000 width=4)
Group Key: id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)
(3 rows)Então aqui HashAggregate é usado mesmo que não haja agregação e grupo por envolvidos.
Limite
Os nós de limite são adicionados à árvore do plano se a cláusula “limit/offset” for usada na consulta SELECT. Esta cláusula é usada para limitar o número de linhas e, opcionalmente, fornecer um deslocamento para iniciar a leitura dos dados. Exemplo abaixo:
postgres=# explain select * from demo1 offset 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.15..15.00 rows=990 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)
postgres=# explain select * from demo1 limit 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.00..0.15 rows=10 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)
postgres=# explain select * from demo1 offset 5 limit 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.07..0.22 rows=10 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)Único
Este nó é selecionado para obter um valor distinto do resultado subjacente. Observe que, dependendo da consulta, seletividade e outras informações de recursos, o valor distinto pode ser recuperado usando HashAggregate/GroupAggregate também sem usar o nó Unique. Exemplo:
postgres=# explain select distinct(id) from demo2 where id<100;
QUERY PLAN
-----------------------------------------------------------------------------------
Unique (cost=0.29..10.27 rows=99 width=4)
-> Index Only Scan using demoidx2 on demo2 (cost=0.29..10.03 rows=99 width=4)
Index Cond: (id < 100)
(3 rows)LockRows
PostgreSQL fornece funcionalidade para bloquear todas as linhas selecionadas. As linhas podem ser selecionadas no modo “Compartilhado” ou no modo “Exclusivo”, dependendo da cláusula “FOR SHARE” e “FOR UPDATE”, respectivamente. Um novo nó “LockRows” é adicionado à árvore de planos para realizar esta operação.
postgres=# explain select * from demo1 for update;
QUERY PLAN
----------------------------------------------------------------
LockRows (cost=0.00..25.00 rows=1000 width=14)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=14)
(2 rows)
postgres=# explain select * from demo1 for share;
QUERY PLAN
----------------------------------------------------------------
LockRows (cost=0.00..25.00 rows=1000 width=14)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=14)
(2 rows)SetOp
PostgreSQL fornece funcionalidade para combinar os resultados de duas ou mais consultas. Assim, à medida que o tipo de nó Join é selecionado para unir duas tabelas, um tipo semelhante de nó SetOp é selecionado para combinar os resultados de duas ou mais consultas. Por exemplo, considere uma tabela com funcionários com seu id, nome, idade e salário conforme abaixo:
postgres=# create table emp(id int, name char(20), age int, salary int);
CREATE TABLE
postgres=# insert into emp values(1,'a', 30,100);
INSERT 0 1
postgres=# insert into emp values(2,'b', 31,90);
INSERT 0 1
postgres=# insert into emp values(3,'c', 40,105);
INSERT 0 1
postgres=# insert into emp values(4,'d', 20,80);
INSERT 0 1 Agora vamos pegar os funcionários com idade superior a 25 anos:
postgres=# select * from emp where age > 25;
id | name | age | salary
----+----------------------+-----+--------
1 | a | 30 | 100
2 | b | 31 | 90
3 | c | 40 | 105
(3 rows) Agora vamos obter funcionários com salário superior a 95 milhões:
postgres=# select * from emp where salary > 95;
id | name | age | salary
----+----------------------+-----+--------
1 | a | 30 | 100
3 | c | 40 | 105
(2 rows)Agora, para obter funcionários com idade superior a 25 anos e salário superior a 95 milhões, podemos escrever abaixo a consulta de interseção:
postgres=# explain select * from emp where age>25 intersect select * from emp where salary > 95;
QUERY PLAN
---------------------------------------------------------------------------------
HashSetOp Intersect (cost=0.00..72.90 rows=185 width=40)
-> Append (cost=0.00..64.44 rows=846 width=40)
-> Subquery Scan on "*SELECT* 1" (cost=0.00..30.11 rows=423 width=40)
-> Seq Scan on emp (cost=0.00..25.88 rows=423 width=36)
Filter: (age > 25)
-> Subquery Scan on "*SELECT* 2" (cost=0.00..30.11 rows=423 width=40)
-> Seq Scan on emp emp_1 (cost=0.00..25.88 rows=423 width=36)
Filter: (salary > 95)
(8 rows) Aqui, um novo tipo de nó HashSetOp é adicionado para avaliar a interseção dessas duas consultas individuais.
Observe que há outros dois tipos de novos nós adicionados aqui:
Anexar
Este nó é adicionado para combinar vários conjuntos de resultados em um.
Verificação de Subconsulta
Este nó é adicionado para avaliar qualquer subconsulta. No plano acima, a subconsulta é adicionada para avaliar um valor de coluna constante adicional que indica qual conjunto de entrada contribuiu com uma linha específica.
HashedSetop funciona usando o hash do resultado subjacente, mas é possível gerar uma operação SetOp baseada em Sort pelo otimizador de consulta. O nó Setop baseado em classificação é indicado como “Setop”.
Nota:É possível obter o mesmo resultado mostrado no resultado acima com uma única consulta, mas aqui é mostrado usando intersect apenas para uma demonstração fácil.
Conclusão
Todos os nós do PostgreSQL são úteis e são selecionados com base na natureza da consulta, dados, etc. Muitas das cláusulas são mapeadas individualmente com nós. Para algumas cláusulas, existem várias opções para nós, que são decididas com base nos cálculos de custo de dados subjacentes.