Existem vários métodos para examinar consultas com desempenho insatisfatório no SQL Server, principalmente Repositório de Consultas, Eventos Estendidos e exibições de gerenciamento dinâmico (DMVs). Cada opção tem prós e contras. O Extended Events fornece dados sobre a execução individual de consultas, enquanto o Query Store e os DMVs agregam dados de desempenho. Para usar o Repositório de Consultas e Eventos Estendidos, você precisa configurá-los com antecedência – seja habilitando o Repositório de Consultas para seu(s) banco(s) de dados ou configurando uma sessão XE e iniciando-a. Os dados de DMV estão sempre disponíveis, por isso, muitas vezes, é o método mais fácil de obter uma primeira olhada rápida no desempenho da consulta. É aqui que as consultas DMV de Glenn são úteis – dentro de seu script, ele tem várias consultas que você pode usar para encontrar as principais consultas para a instância com base na CPU, E/S lógica e duração. A segmentação das consultas que consomem mais recursos geralmente é um bom começo na solução de problemas, mas não podemos esquecer o cenário “morte por mil cortes” – a consulta ou conjunto de consultas que são executadas com muita frequência – talvez centenas ou milhares de vezes por minuto. Glenn tem uma consulta em seu conjunto que lista as principais consultas para um banco de dados com base na contagem de execução, mas na minha experiência isso não fornece uma visão completa da sua carga de trabalho.
A principal DMV usada para examinar as métricas de desempenho de consulta é sys.dm_exec_query_stats. Dados adicionais específicos para procedimentos armazenados (sys.dm_exec_procedure_stats), funções (sys.dm_exec_function_stats) e gatilhos (sys.dm_exec_trigger_stats) também estão disponíveis, mas considere uma carga de trabalho que não seja puramente procedimentos armazenados, funções e gatilhos. Considere uma carga de trabalho mista que tenha algumas consultas ad hoc ou talvez seja totalmente ad hoc.
Cenário de exemplo
Tomando emprestado e adaptando o código de uma postagem anterior, Examinando o impacto no desempenho de uma carga de trabalho ad hoc, primeiro criaremos dois procedimentos armazenados. O primeiro, dbo.RandomSelects, gera e executa uma instrução ad hoc, e o segundo, dbo.SPRandomSelects, gera e executa uma consulta parametrizada.
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[RandomSelects];
GO
CREATE PROCEDURE dbo.[RandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50));
SELECT @QueryString = N'SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = ''' + @ConcatString + ''';';
EXEC (@QueryString);
SELECT @RowLoop = @RowLoop + 1;
END
GO
DROP PROCEDURE IF EXISTS dbo.[SPRandomSelects];
GO
CREATE PROCEDURE dbo.[SPRandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50))
SELECT c.CustomerID, c.AccountOpenedDate, COUNT(ct.CustomerTransactionID)
FROM Sales.Customers c
JOIN Sales.CustomerTransactions ct
ON c.CustomerID = ct.CustomerID
WHERE c.CustomerName = @ConcatString
GROUP BY c.CustomerID, c.AccountOpenedDate;
SELECT @RowLoop = @RowLoop + 1;
END
GO Agora vamos executar os dois procedimentos armazenados 1000 vezes, usando o mesmo método descrito no meu post anterior com arquivos .cmd chamando arquivos .sql com as seguintes instruções:
Conteúdo do arquivo Adhoc.sql:
EXEC [WideWorldImporters].dbo.[RandomSelects] @NumRows = 1000;
Conteúdo do arquivo .sql parametrizado:
EXEC [WideWorldImporters].dbo.[SPRandomSelects] @NumRows = 1000;
Sintaxe de exemplo no arquivo .cmd que chama o arquivo .sql:
sqlcmd -S WIN2016\SQL2017 -i"Adhoc.sql" exit
Se usarmos uma variação da consulta Top Worker Time de Glenn para examinar as principais consultas com base no tempo do trabalhador (CPU):
-- Get top total worker time queries for entire instance (Query 44) (Top Worker Time Queries) SELECT TOP(50) DB_NAME(t.[dbid]) AS [Database Name], REPLACE(REPLACE(LEFT(t.[text], 255), CHAR(10),''), CHAR(13),'') AS [Short Query Text], qs.total_worker_time AS [Total Worker Time], qs.execution_count AS [Execution Count], qs.total_worker_time/qs.execution_count AS [Avg Worker Time], qs.creation_time AS [Creation Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp ORDER BY qs.total_worker_time DESC OPTION (RECOMPILE);
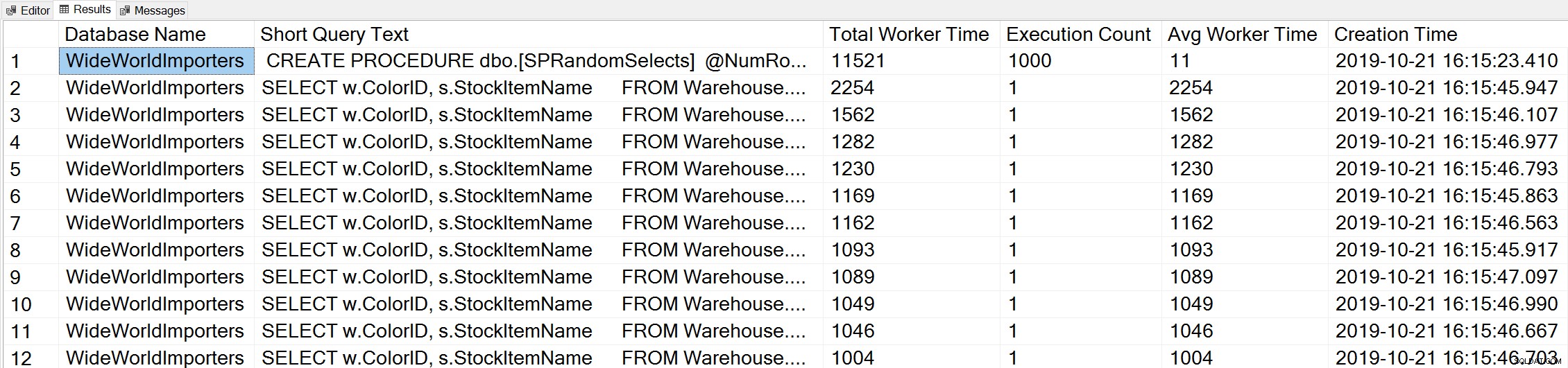
Vemos a instrução de nosso procedimento armazenado como a consulta que é executada com a maior quantidade de CPU cumulativa.
Se executarmos uma variação da consulta Query Execution Counts de Glenn no banco de dados WideWorldImporters:
USE [WideWorldImporters]; GO -- Get most frequently executed queries for this database (Query 57) (Query Execution Counts) SELECT TOP(50) LEFT(t.[text], 50) AS [Short Query Text], qs.execution_count AS [Execution Count], qs.total_logical_reads AS [Total Logical Reads], qs.total_logical_reads/qs.execution_count AS [Avg Logical Reads], qs.total_worker_time AS [Total Worker Time], qs.total_worker_time/qs.execution_count AS [Avg Worker Time], qs.total_elapsed_time AS [Total Elapsed Time], qs.total_elapsed_time/qs.execution_count AS [Avg Elapsed Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp WHERE t.dbid = DB_ID() ORDER BY qs.execution_count DESC OPTION (RECOMPILE);
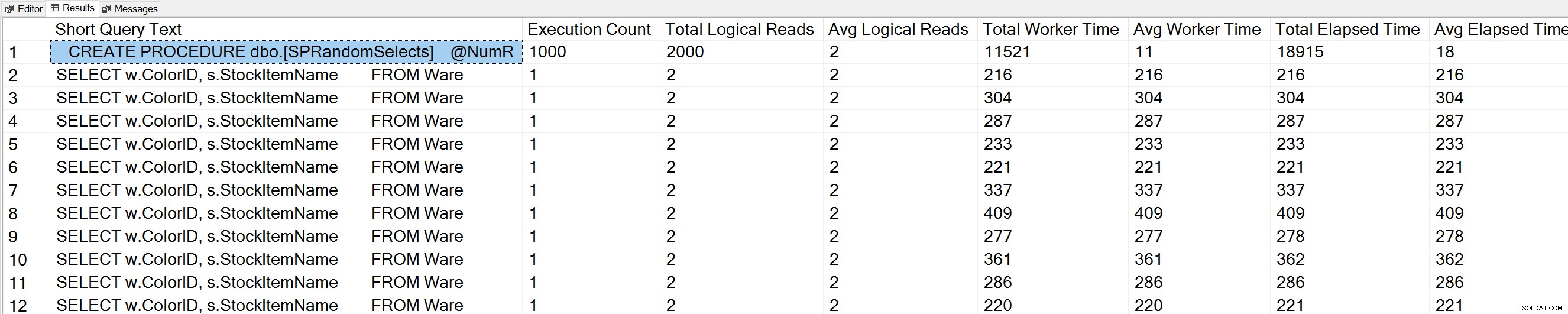
Também vemos nossa instrução de procedimento armazenado no topo da lista.
Mas a consulta ad hoc que executamos, embora tenha valores literais diferentes, foi essencialmente a mesma comando executado repetidamente, como podemos ver olhando para o query_hash:
SELECT TOP(50) DB_NAME(t.[dbid]) AS [Database Name], REPLACE(REPLACE(LEFT(t.[text], 255), CHAR(10),''), CHAR(13),'') AS [Short Query Text], qs.query_hash AS [query_hash], qs.creation_time AS [Creation Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp ORDER BY [Short Query Text];
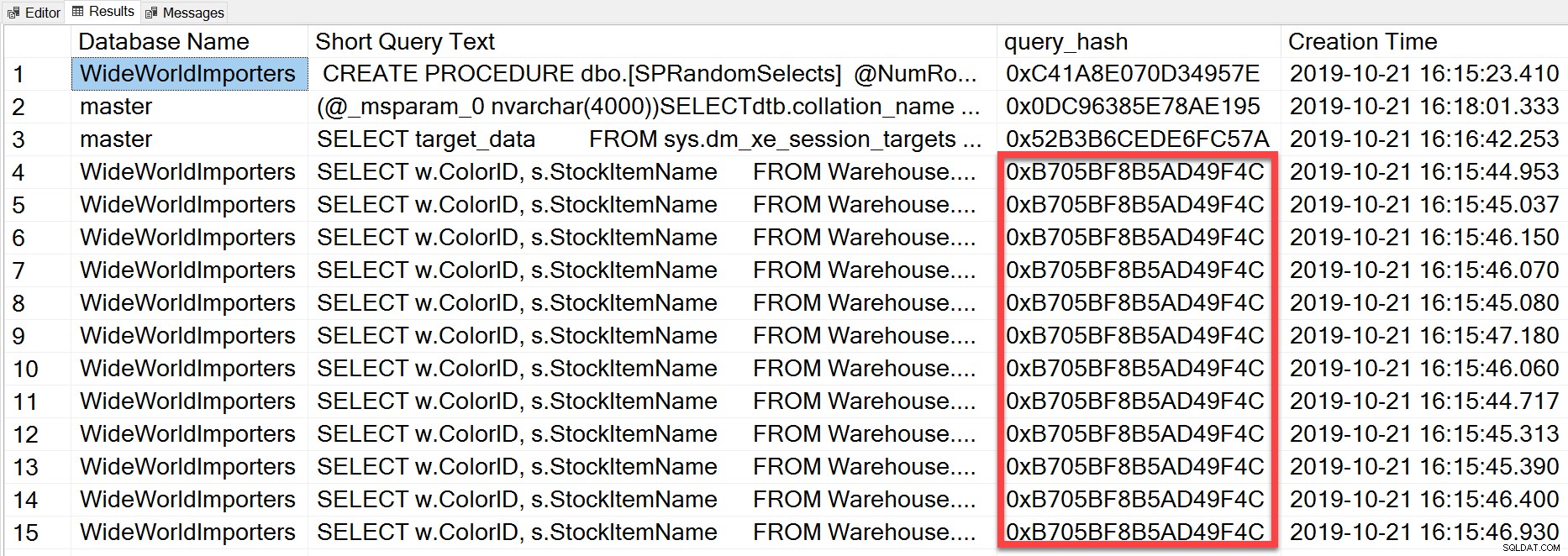
O query_hash foi adicionado no SQL Server 2008 e é baseado na árvore dos operadores lógicos gerados pelo Query Optimizer para o texto da instrução. As consultas que têm um texto de instrução semelhante que gera a mesma árvore de operadores lógicos terão o mesmo query_hash, mesmo que os valores literais no predicado da consulta sejam diferentes. Embora os valores literais possam ser diferentes, os objetos e seus aliases devem ser os mesmos, assim como as dicas de consulta e potencialmente as opções SET. O procedimento armazenado RandomSelects gera consultas com diferentes valores literais:
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = '1005451175198';
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = '1006416358897'; Mas cada execução tem exatamente o mesmo valor para query_hash, 0xB705BF8B5AD49F4C. Para entender com que frequência uma consulta ad hoc – e aquelas que são iguais em termos de query_hash – são executadas, temos que agrupar pela ordem query_hash nessa contagem, em vez de olhar para execution_count em sys.dm_exec_query_stats (que geralmente mostra um valor de 1).
Se alterarmos o contexto para o banco de dados WideWorldImporters e procurarmos as principais consultas com base na contagem de execução, onde agrupamos em query_hash, agora podemos ver o procedimento armazenado e nossa consulta ad hoc:
;WITH qh AS
(
SELECT TOP (25) query_hash, COUNT(*) AS COUNT
FROM sys.dm_exec_query_stats
GROUP BY query_hash
ORDER BY COUNT(*) DESC
),
qs AS
(
SELECT obj = COALESCE(ps.object_id, fs.object_id, ts.object_id),
db = COALESCE(ps.database_id, fs.database_id, ts.database_id),
qs.query_hash, qs.query_plan_hash, qs.execution_count,
qs.sql_handle, qs.plan_handle
FROM sys.dm_exec_query_stats AS qs
INNER JOIN qh ON qs.query_hash = qh.query_hash
LEFT OUTER JOIN sys.dm_exec_procedure_stats AS [ps]
ON [qs].[sql_handle] = [ps].[sql_handle]
LEFT OUTER JOIN sys.dm_exec_function_stats AS [fs]
ON [qs].[sql_handle] = [fs].[sql_handle]
LEFT OUTER JOIN sys.dm_exec_trigger_stats AS [ts]
ON [qs].[sql_handle] = [ts].[sql_handle]
)
SELECT TOP (50)
OBJECT_NAME(qs.obj, qs.db),
query_hash,
query_plan_hash,
SUM([qs].[execution_count]) AS [ExecutionCount],
MAX([st].[text]) AS [QueryText]
FROM qs
CROSS APPLY sys.dm_exec_sql_text ([qs].[sql_handle]) AS [st]
CROSS APPLY sys.dm_exec_query_plan ([qs].[plan_handle]) AS [qp]
GROUP BY qs.obj, qs.db, qs.query_hash, qs.query_plan_hash
ORDER BY ExecutionCount DESC; 
Observação:a DMV sys.dm_exec_function_stats foi adicionada ao SQL Server 2016. A execução dessa consulta no SQL Server 2014 e versões anteriores requer a remoção da referência a essa DMV.
Essa saída fornece uma compreensão muito mais abrangente de quais consultas realmente são executadas com mais frequência, pois agrega com base no query_hash, não apenas observando o execution_count em sys.dm_exec_query_stats, que pode ter várias entradas para o mesmo query_hash quando diferentes valores literais são usado. A saída da consulta também inclui query_plan_hash, que pode ser diferente para consultas com o mesmo query_hash. Essas informações adicionais são úteis ao avaliar o desempenho do plano para uma consulta. No exemplo acima, toda consulta tem o mesmo query_plan_hash, 0x299275DD475C4B17, demonstrando que mesmo com valores de entrada diferentes, o Query Optimizer gera o mesmo plano – é estável. Quando existem vários valores query_plan_hash para o mesmo query_hash, existe variabilidade de plano. Em um cenário onde a mesma consulta, baseada em query_hash, é executada milhares de vezes, uma recomendação geral é parametrizar a consulta. Se você puder verificar se não existe variabilidade de plano, a parametrização da consulta removerá a otimização e o tempo de compilação de cada execução e poderá reduzir a CPU geral. Em alguns cenários, a parametrização de cinco a 10 consultas ad hoc pode melhorar o desempenho do sistema como um todo.
Resumo
Para qualquer ambiente, é importante entender quais consultas são mais caras em termos de uso de recursos e quais consultas são executadas com mais frequência. O mesmo conjunto de consultas pode aparecer para ambos os tipos de análise ao usar o script DMV de Glenn, o que pode ser enganoso. Como tal, é importante estabelecer se a carga de trabalho é principalmente processual, principalmente ad hoc ou uma mistura. Embora haja muito documentado sobre os benefícios dos procedimentos armazenados, acho que cargas de trabalho mistas ou altamente ad hoc são muito comuns, principalmente com soluções que usam mapeadores relacionais de objeto (ORMs), como Entity Framework, NHibernate e LINQ to SQL. Se você não tiver certeza sobre o tipo de carga de trabalho de um servidor, executar a consulta acima para ver as consultas mais executadas com base em um query_hash é um bom começo. À medida que você começa a entender a carga de trabalho e o que existe para as consultas de peso pesado e morte por mil cortes, você pode passar a entender verdadeiramente o uso de recursos e o impacto que essas consultas têm no desempenho do sistema e direcionar seus esforços para ajuste.