Quando estiver profundamente envolvido na solução de um problema no SQL Server, às vezes você deseja saber a ordem exata em que as consultas foram executadas. Vejo isso com procedimentos armazenados mais complicados que contêm camadas de lógica ou em cenários em que há muito código redundante. Eventos estendidos é uma escolha natural aqui, pois normalmente é usado para capturar informações sobre a execução de consultas. Muitas vezes você pode usar session_id e o timestamp para entender a ordem dos eventos, mas há uma opção de sessão para XE que é ainda mais confiável:Track Causality.
Quando você habilita o Track Causality para uma sessão, ele adiciona um GUID e um número de sequência a cada evento, que você pode usar para percorrer a ordem em que os eventos ocorreram. A sobrecarga é mínima e pode ser uma economia de tempo significativa em muitos cenários de solução de problemas.
Configuração
Usando o banco de dados WideWorldImporters, criaremos um procedimento armazenado para usar:
DROP PROCEDURE IF EXISTS [Sales].[usp_CustomerTransactionInfo]; GO CREATE PROCEDURE [Sales].[usp_CustomerTransactionInfo] @CustomerID INT AS SELECT [CustomerID], SUM([AmountExcludingTax]) FROM [Sales].[CustomerTransactions] WHERE [CustomerID] = @CustomerID GROUP BY [CustomerID]; SELECT COUNT([OrderID]) FROM [Sales].[Orders] WHERE [CustomerID] = @CustomerID GO
Em seguida, criaremos uma sessão de evento:
CREATE EVENT SESSION [TrackQueries] ON SERVER
ADD EVENT sqlserver.sp_statement_completed(
WHERE ([sqlserver].[is_system]=(0))),
ADD EVENT sqlserver.sql_statement_completed(
WHERE ([sqlserver].[is_system]=(0)))
ADD TARGET package0.event_file
(
SET filename=N'C:\temp\TrackQueries',max_file_size=(256)
)
WITH
(
MAX_MEMORY = 4096 KB,
EVENT_RETENTION_MODE = ALLOW_SINGLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY = 30 SECONDS,
MAX_EVENT_SIZE = 0 KB,
MEMORY_PARTITION_MODE = NONE,
TRACK_CAUSALITY = ON,
STARTUP_STATE = OFF
); Também executaremos consultas ad-hoc, portanto, capturamos sp_statement_completed (instruções concluídas em um procedimento armazenado) e sql_statement_completed (instruções concluídas que não estão em um procedimento armazenado). Observe que a opção TRACK_CAUSALITY para a sessão está definida como ON. Novamente, essa configuração é específica para a sessão do evento e deve ser habilitada antes de iniciá-la. Você não pode ativar a configuração em tempo real, como pode adicionar ou remover eventos e destinos enquanto a sessão está em execução.
Para iniciar a sessão do evento por meio da interface do usuário, basta clicar com o botão direito do mouse e selecionar Iniciar Sessão.
Teste
No Management Studio, executaremos o seguinte código:
EXEC [Sales].[usp_CustomerTransactionInfo] 490;
SELECT [c].[CustomerID], [c].[CustomerName], [p].[FullName], [o].[OrderID]
FROM [Application].[People] [p]
JOIN [Sales].[Customers] [c] ON [p].[PersonID] = [c].[PrimaryContactPersonID]
JOIN [Sales].[Orders] [o] ON [c].[CustomerID] = [o].[CustomerID]
WHERE [p].[FullName] = 'Naseem Radan'; Aqui está nossa saída XE:

Observe que a primeira consulta executada, destacada, é SELECT @@SPID e possui um GUID de FDCCB1CF-CA55-48AA-8FBA-7F5EBF870674. Não executamos essa consulta, ela ocorreu em segundo plano e, embora a sessão XE esteja configurada para filtrar as consultas do sistema, esta – por qualquer motivo – ainda é capturada.
As próximas quatro linhas representam o código que realmente executamos. Existem as duas consultas do procedimento armazenado, o próprio procedimento armazenado e, em seguida, nossa consulta ad-hoc. Todos têm o mesmo GUID, ACBFFD99-2400-4AFF-A33F-351821667B24. Ao lado do GUID está o ID de sequência (seq) e as consultas são numeradas de um a quatro.
Em nosso exemplo, não usamos GO para separar as instruções em lotes diferentes. Observe como a saída muda quando fazemos isso:
EXEC [Sales].[usp_CustomerTransactionInfo] 490;
GO
SELECT [c].[CustomerID], [c].[CustomerName], [p].[FullName], [o].[OrderID]
FROM [Application].[People] [p]
JOIN [Sales].[Customers] [c] ON [p].[PersonID] = [c].[PrimaryContactPersonID]
JOIN [Sales].[Orders] [o] ON [c].[CustomerID] = [o].[CustomerID]
WHERE [p].[FullName] = 'Naseem Radan';
GO 
Ainda temos o mesmo número de linhas totais, mas agora temos três GUIDs. Um para o SELECT @@SPID (E8D136B8-092F-439D-84D6-D4EF794AE753), um para as três consultas que representam o procedimento armazenado (F962B9A4-0665-4802-9E6C-B217634D8787) e um para a consulta ad-hoc (5DD6A5FE -9702-4DE5-8467-8D7CF55B5D80).
Isso é o que você provavelmente verá quando estiver analisando os dados do seu aplicativo, mas depende de como o aplicativo funciona. Se ele usar o pool de conexões e as conexões forem redefinidas regularmente (o que é esperado), cada conexão terá seu próprio GUID.
Você pode recriá-lo usando o exemplo de código do PowerShell abaixo:
while(1 -eq 1)
{
$SqlConn = New-Object System.Data.SqlClient.SqlConnection;
$SqlConn.ConnectionString = "Data Source=Hedwig\SQL2017;Initial Catalog=WideWorldImporters;Integrated Security=True;Application Name = MyCoolApp";
$SQLConn.Open()
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = "SELECT TOP 1 CustomerID FROM Sales.Customers ORDER BY NEWID();"
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlReader = $SqlCmd.ExecuteReader();
$Results = New-Object System.Collections.ArrayList;
while ($SqlReader.Read())
{
$Results.Add($SqlReader.GetSqlInt32(0)) | Out-Null;
}
$SqlReader.Close();
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = "Sales.usp_CustomerTransactionInfo"
$SqlCmd.CommandType = [System.Data.CommandType]::StoredProcedure;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CustomerID", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::Int;
$SqlCmd.ExecuteNonQuery();
$SqlConn.Close();
$Names = New-Object System.Collections.Generic.List``1[System.String]
$SqlConn = New-Object System.Data.SqlClient.SqlConnection
$SqlConn.ConnectionString = "Data Source=Hedwig\SQL2017;Initial Catalog=WideWorldImporters;User Id=aw_webuser;Password=12345;Application Name=AdventureWorks Online Ordering;Workstation ID=AWWEB01";
$SqlConn.Open();
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = "SELECT FullName FROM Application.People ORDER BY NEWID();";
$dr = $SqlCmd.ExecuteReader();
while($dr.Read())
{
$Names.Add($dr.GetString(0));
}
$SqlConn.Close();
$name = Get-Random -InputObject $Names;
$query = [String]::Format("SELECT [c].[CustomerID], [c].[CustomerName], [p].[FullName], [o].[OrderID]
FROM [Application].[People] [p]
JOIN [Sales].[Customers] [c] ON [p].[PersonID] = [c].[PrimaryContactPersonID]
JOIN [Sales].[Orders] [o] ON [c].[CustomerID] = [o].[CustomerID]
WHERE [p].[FullName] = '{0}';", $name);
$SqlConn = New-Object System.Data.SqlClient.SqlConnection
$SqlConn.ConnectionString = "Data Source=Hedwig\SQL2017;Initial Catalog=WideWorldImporters;User Id=aw_webuser;Password=12345;Application Name=AdventureWorks Online Ordering;Workstation ID=AWWEB01";
$SqlConn.Open();
$SqlCmd = $sqlconnection.CreateCommand();
$SqlCmd.CommandText = $query
$SqlCmd.ExecuteNonQuery();
$SqlConn.Close();
} Aqui está um exemplo da saída de eventos estendidos depois de deixar o código rodar um pouco:

Existem quatro GUIDs diferentes para nossas cinco instruções e, se você observar o código acima, verá que há quatro conexões diferentes feitas. Se você alterar a sessão do evento para incluir o evento rpc_completed, poderá ver entradas com exec sp_reset_connection.
Sua saída XE dependerá do seu código e do seu aplicativo; Mencionei inicialmente que isso era útil ao solucionar problemas de procedimentos armazenados mais complexos. Considere o seguinte exemplo:
DROP PROCEDURE IF EXISTS [Sales].[usp_CustomerTransactionInfo]; GO CREATE PROCEDURE [Sales].[usp_CustomerTransactionInfo] @CustomerID INT AS SELECT [CustomerID], SUM([AmountExcludingTax]) FROM [Sales].[CustomerTransactions] WHERE [CustomerID] = @CustomerID GROUP BY [CustomerID]; SELECT COUNT([OrderID]) FROM [Sales].[Orders] WHERE [CustomerID] = @CustomerID GO DROP PROCEDURE IF EXISTS [Sales].[usp_GetFullCustomerInfo]; GO CREATE PROCEDURE [Sales].[usp_GetFullCustomerInfo] @CustomerID INT AS SELECT [o].[CustomerID], [o].[OrderDate], [ol].[StockItemID], [ol].[Quantity], [ol].[UnitPrice] FROM [Sales].[Orders] [o] JOIN [Sales].[OrderLines] [ol] ON [o].[OrderID] = [ol].[OrderID] WHERE [o].[CustomerID] = @CustomerID ORDER BY [o].[OrderDate] DESC; SELECT [o].[CustomerID], SUM([ol].[Quantity]*[ol].[UnitPrice]) FROM [Sales].[Orders] [o] JOIN [Sales].[OrderLines] [ol] ON [o].[OrderID] = [ol].[OrderID] WHERE [o].[CustomerID] = @CustomerID GROUP BY [o].[CustomerID] ORDER BY [o].[CustomerID] ASC; GO DROP PROCEDURE IF EXISTS [Sales].[usp_GetCustomerData]; GO CREATE PROCEDURE [Sales].[usp_GetCustomerData] @CustomerID INT AS BEGIN SELECT * FROM [Sales].[Customers] EXEC [Sales].[usp_CustomerTransactionInfo] @CustomerID EXEC [Sales].[usp_GetFullCustomerInfo] @CustomerID END GO
Aqui temos dois procedimentos armazenados, usp_TransctionInfo e usp_GetFullCustomerInfo, que são chamados por outro procedimento armazenado, usp_GetCustomerData. Não é incomum ver isso ou até mesmo ver níveis adicionais de aninhamento com procedimentos armazenados. Se executarmos usp_GetCustomerData do Management Studio, veremos o seguinte:
EXEC [Sales].[usp_GetCustomerData] 981;

Aqui, todas as execuções ocorreram no mesmo GUID, BF54CD8F-08AF-4694-A718-D0C47DBB9593, e podemos ver a ordem de execução da consulta de um a oito usando a coluna seq. Nos casos em que há vários procedimentos armazenados chamados, não é incomum que o valor do ID da sequência chegue às centenas ou aos milhares.
Por fim, no caso em que você está analisando a execução da consulta e incluiu Track Causality e encontra uma consulta com desempenho insatisfatório – porque classificou a saída com base na duração ou em alguma outra métrica, observe que você pode encontrar a outra consultas agrupando no GUID:
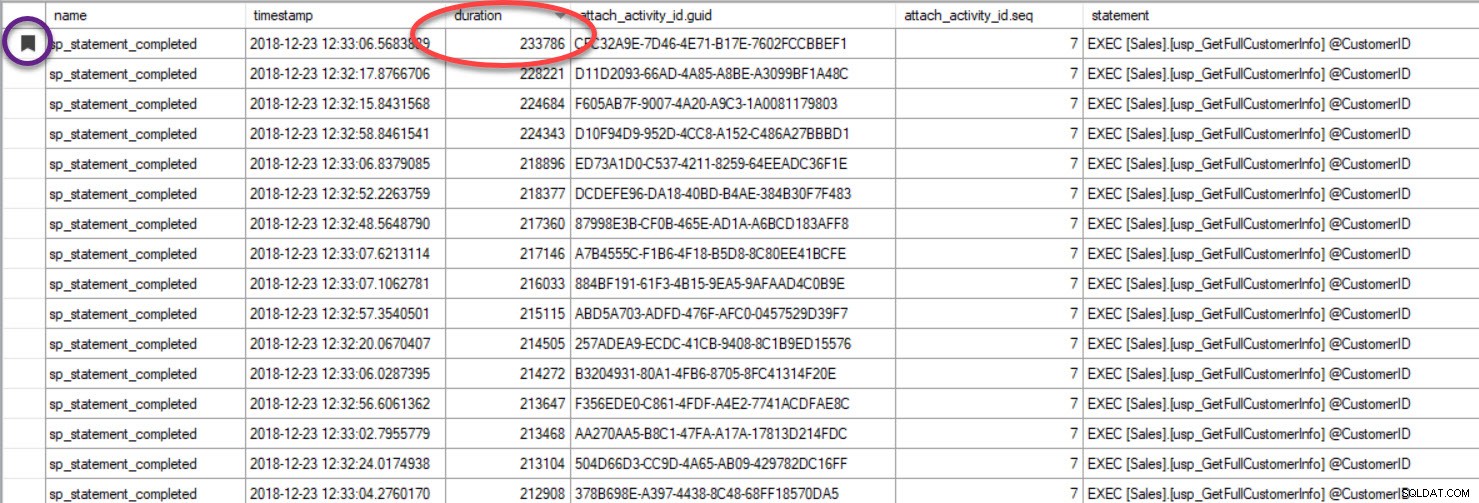
A saída foi classificada por duração (valor mais alto circulado em vermelho) e eu a marquei (em roxo) usando o botão Toggle Bookmark. Se quisermos ver as outras consultas para o GUID, agrupe por GUID (clique com o botão direito do mouse no nome da coluna na parte superior e selecione Agrupar por esta coluna) e use o botão Próximo marcador para voltar à nossa consulta:
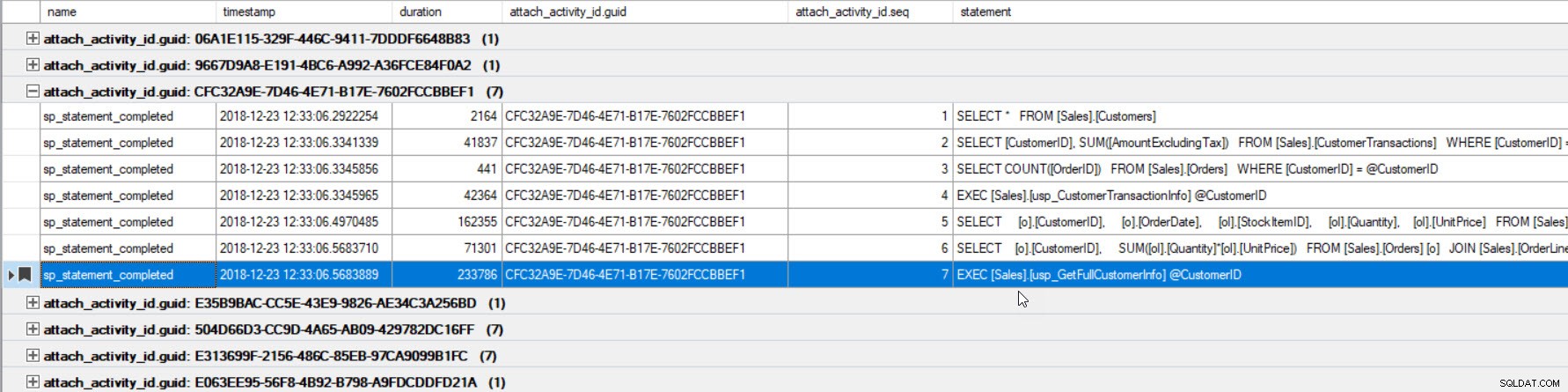
Agora podemos ver todas as consultas que foram executadas na mesma conexão e na ordem de execução.
Conclusão
A opção Rastrear Causalidade pode ser imensamente útil ao solucionar problemas de desempenho de consulta e tentar entender a ordem dos eventos no SQL Server. Também é útil ao configurar uma sessão de evento que usa o destino pair_matching, para ajudar a garantir que você esteja correspondendo no campo/ação correto e encontrando o evento não correspondente adequado. Novamente, esta é uma configuração de nível de sessão, portanto, deve ser aplicada antes de iniciar a sessão do evento. Para uma sessão em execução, interrompa a sessão do evento, ative a opção e inicie-a novamente.