Autor convidado:Andy Mallon (@AMtwo)
Não, sério. O que é uma DTU?
Quando você está implantando qualquer aplicativo, uma das primeiras perguntas que surge é "Qual será o custo disso?" A maioria de nós já passou por esse tipo de exercício para dimensionar uma instalação do SQL Server em algum momento, mas e se você estiver implantando na nuvem? Com as implantações de IaaS do Azure, não mudou muito – você ainda está criando um servidor com base na contagem de CPU, alguma quantidade de memória e configurando o armazenamento para fornecer IOPS suficiente para sua carga de trabalho. No entanto, quando você passa para PaaS, o Banco de Dados SQL do Azure é dimensionado com diferentes camadas de serviço, onde o desempenho é medido em DTUs. O que diabos é uma DTU?
Eu sei o que é um BTU. Talvez DTU significa Database Thermal Unit? É a quantidade de poder de processamento necessária para aumentar a temperatura do data center em um grau? Em vez de adivinhar, vamos verificar a documentação e ver o que a Microsoft tem a dizer:
Uma [Database Transaction Unit] é uma medida combinada de CPU, memória e E/S de dados e E/S de log de transações em uma proporção determinada por uma carga de trabalho de referência de OLTP projetada para ser típica de cargas de trabalho OLTP do mundo real. Dobrar as DTUs aumentando o nível de desempenho de um banco de dados equivale a dobrar o conjunto de recursos disponíveis para esse banco de dados.
OK, esse foi o meu segundo palpite - mas qual é a "medida combinada"? Como posso traduzir o que sei sobre dimensionamento de um servidor em dimensionamento de um Banco de Dados SQL do Azure? Infelizmente, não há uma maneira direta de converter "2 núcleos de CPU e 4 GB de memória" em uma medida de DTU.
Não existe uma calculadora de DTU?
Sim! A Microsoft nos fornece uma calculadora de DTU para estimar a camada de serviço adequada do Banco de Dados SQL do Azure. Para usá-lo, baixe e execute um script do PowerShell (sql-perfmon.ps1) no servidor enquanto executa uma carga de trabalho no SQL Server. O script gera um CSV que contém quatro contadores perfmon:(1) % total de tempo do processador, (2) total de leituras de disco/segundo, (3) total de gravações de disco por segundo e (4) total de bytes de log liberados/segundo. Essa saída CSV é então carregada para a Calculadora DTU, que estima qual nível de serviço atenderá melhor às suas necessidades. Os únicos dados que a Calculadora DTU leva além do CSV é o número de núcleos de CPU no servidor que gerou o arquivo. A Calculadora de DTU ainda é uma caixa preta – não é fácil mapear o que sabemos de nossos bancos de dados locais para o Azure.
Gostaria de salientar que a definição de uma DTU é que é "uma medida combinada de CPU, memória , e E/S de dados e E/S de log de transações…" Nenhum dos contadores perfmon usados pela Calculadora DTU leva a memória em consideração, mas ela está claramente listada na definição como parte do cálculo. Isso não é necessariamente um problema, mas é uma evidência de que a Calculadora DTU não será perfeita.
Vou carregar alguma carga sintética na calculadora DTU e ver se consigo descobrir como essa caixa preta funciona. Na verdade, vou fabricar os CSVs completamente para que eu possa controlar totalmente os números de desempenho que carregamos na Calculadora DTU. Vamos analisar uma métrica de cada vez. Para cada métrica, carregaremos 25 minutos (1.500 segundos – gosto de números redondos) de dados fabricados e veremos como esses dados de desempenho são convertidos em DTUs.
CPU
Vou criar um CSV que simule um servidor de 16 núcleos, aumentando lentamente a utilização da CPU até atingir 100%. Como vou simular o aumento em um servidor de 16 núcleos, criarei meu CSV para aumentar 1/16 de cada vez - essencialmente simulando um núcleo no máximo, depois um segundo no máximo, depois o terceiro, etc. Durante todo o tempo, o CSV mostrará zero leituras, gravações e liberações de log. Um servidor nunca geraria uma carga de trabalho como essa, mas esse é o ponto. Estou isolando completamente a utilização da CPU para que eu possa ver como a CPU afeta as DTUs.
Criarei um arquivo CSV com uma linha por segundo e, a cada 94 segundos, aumentarei o contador de tempo total do processador em ~6%. Os outros três contadores serão zero em todos os casos. Agora, eu carrego este arquivo para a Calculadora DTU (e digo à Calculadora DTU para considerar 16 núcleos), e aqui está a saída:
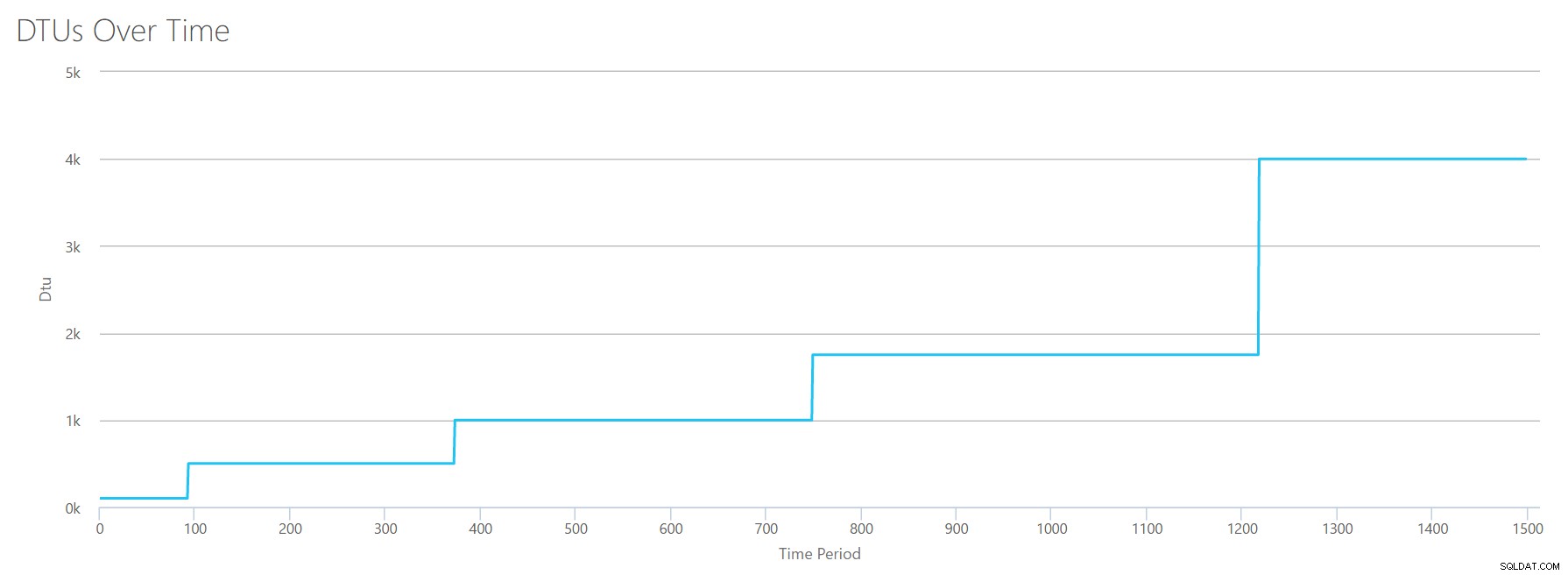
Esperar? Não aumentei a utilização da CPU em 16 etapas iguais? Este gráfico DTU mostra apenas cinco etapas. Eu devo ter me atrapalhado. Não – meu CSV tinha 16 passos pares, mas isso (aparentemente) não se traduz uniformemente em DTUs. Pelo menos não de acordo com a Calculadora DTU. Com base em nosso teste de CPU maximizado, nosso mapeamento de camada de CPU para DTU para serviço ficaria assim:
| Número de núcleos | DTUs | Nível de serviço |
|---|---|---|
| 1 | 100 | Padrão – S3 |
| 2-4 | 500 | Premium – P4 |
| 5-8 | 1000 | Premium – P6 |
| 9-13 | 1750 | Premium – P11 |
| 14-16 | 4000 | Premium – P15 |
A observação desses dados nos diz algumas coisas:
- Um núcleo de CPU, 100% utilizado equivale a 100 DTUs.
- DTUs aumentam meio que linearmente à medida que a CPU aumenta, mas aparentemente aos trancos e barrancos.
- As camadas de serviço Basic e Standard são iguais a menos de um único núcleo de CPU.
- Qualquer servidor multinúcleo seria convertido em algum tamanho dentro do nível de serviço Premium.
Lê
Desta vez, vou usar a mesma metodologia. Vou gerar um CSV com números crescentes para o contador de leituras/segundo, com os outros contadores perfmon em zero. Vou aumentar o número lentamente ao longo do tempo. Desta vez, vamos avançar em pedaços de 2.000, a cada 100 segundos, até chegarmos a 30.000. Isso nos dá o mesmo tempo total de 25 minutos – no entanto, desta vez tenho 15 passos em vez de 16. (Eu gosto de números redondos.)
Quando carregamos este CSV para a calculadora DTU, ele nos dá este gráfico DTU:
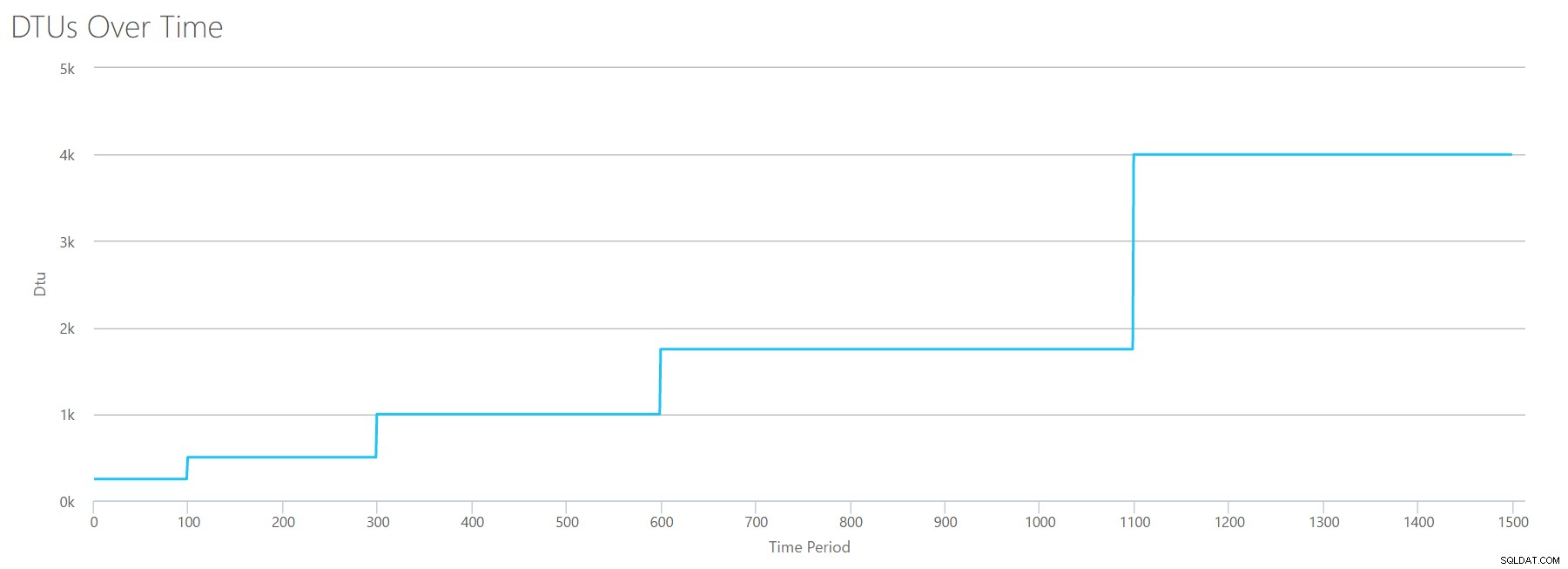
Espere um segundo... isso é bem parecido com o primeiro gráfico. Novamente, está aumentando em 5 incrementos desiguais, mesmo que eu tivesse 15 etapas pares no meu arquivo. Vejamos em um formato tabular:
| Leituras/s | DTUs | Nível de serviço |
|---|---|---|
| 2000 | 250 | Premium – P2 |
| 4000-6000 | 500 | Premium – P4 |
| 8000-12000 | 1000 | Premium – P6 |
| 14.000-22.000 | 1750 | Premium – P11 |
| 24.000-30.000 | 4000 | Premium – P15 |
Novamente, vemos que os níveis Básico e Padrão são saltados rapidamente (menos de 2.000 leituras/s), mas o nível Premium é bastante amplo, abrangendo de 2.000 a 30.000 leituras por segundo. Na tabela acima, as "Leituras/s" provavelmente poderiam ser consideradas como "IOPS"... Ou, tecnicamente, apenas "OPS", já que não há gravações para constituir a parte "entrada" do IOPS.
Escreve
Se criarmos um CSV usando a mesma fórmula que usamos para leituras e enviarmos esse CSV para a calculadora DTU, obteremos um gráfico idêntico ao gráfico para leituras:
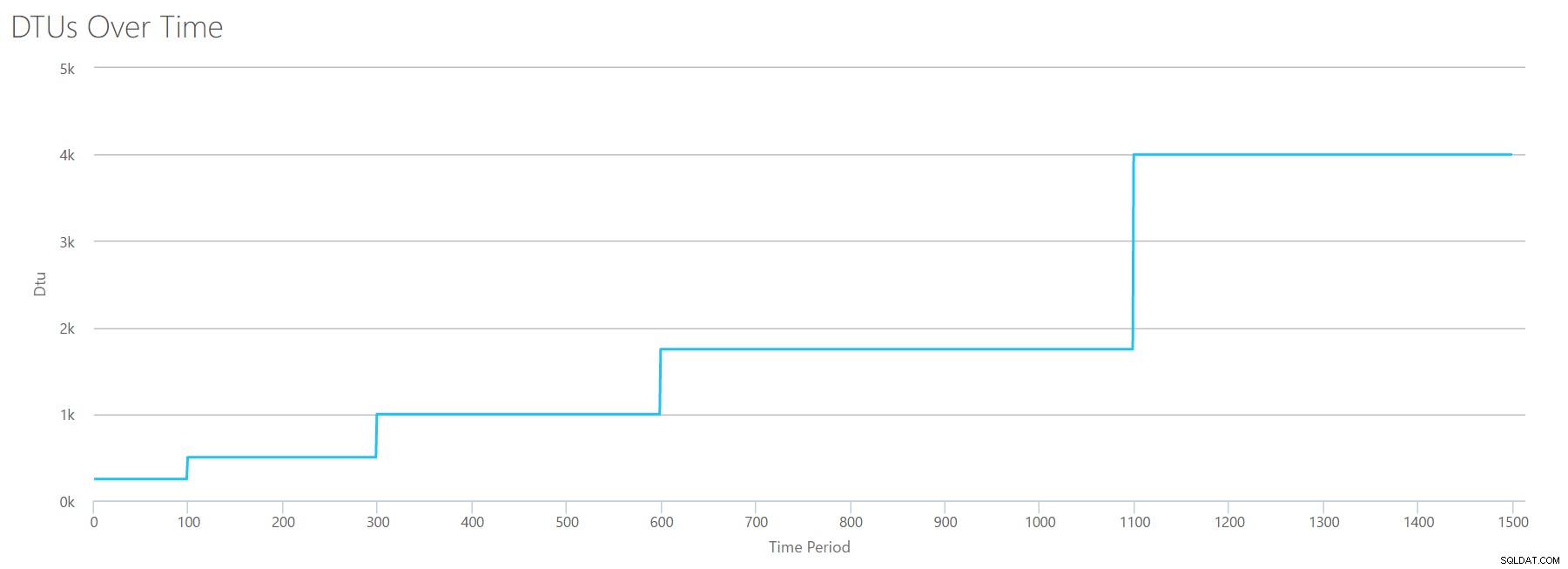
IOPS são IOPS, portanto, seja uma leitura ou uma gravação, parece que o cálculo da DTU a considera igualmente. Tudo o que sabemos (ou pensamos que sabemos) sobre leituras parece se aplicar igualmente a escritas.
Bytes de log liberados
Estamos até o último contador de perfmon:log bytes liberados por segundo. Essa é outra medida de E/S, mas específica para o log de transações do SQL Server. Caso você ainda não tenha percebido, estou criando esses CSVs para que os valores altos sejam calculados como um BD do Azure P15 e, em seguida, basta dividir o valor para dividi-lo em etapas pares. Desta vez, vamos passar de 5 milhões para 75 milhões, em passos de 5 milhões. Como fizemos em todos os testes anteriores, os outros contadores de desempenho serão zero. Como esse contador perfmon está em bytes por segundo e estamos medindo em milhões, podemos pensar nisso na unidade com a qual estamos mais confortáveis:Megabytes por segundo.
Carregamos este CSV para a calculadora DTU e obtemos o seguinte gráfico:
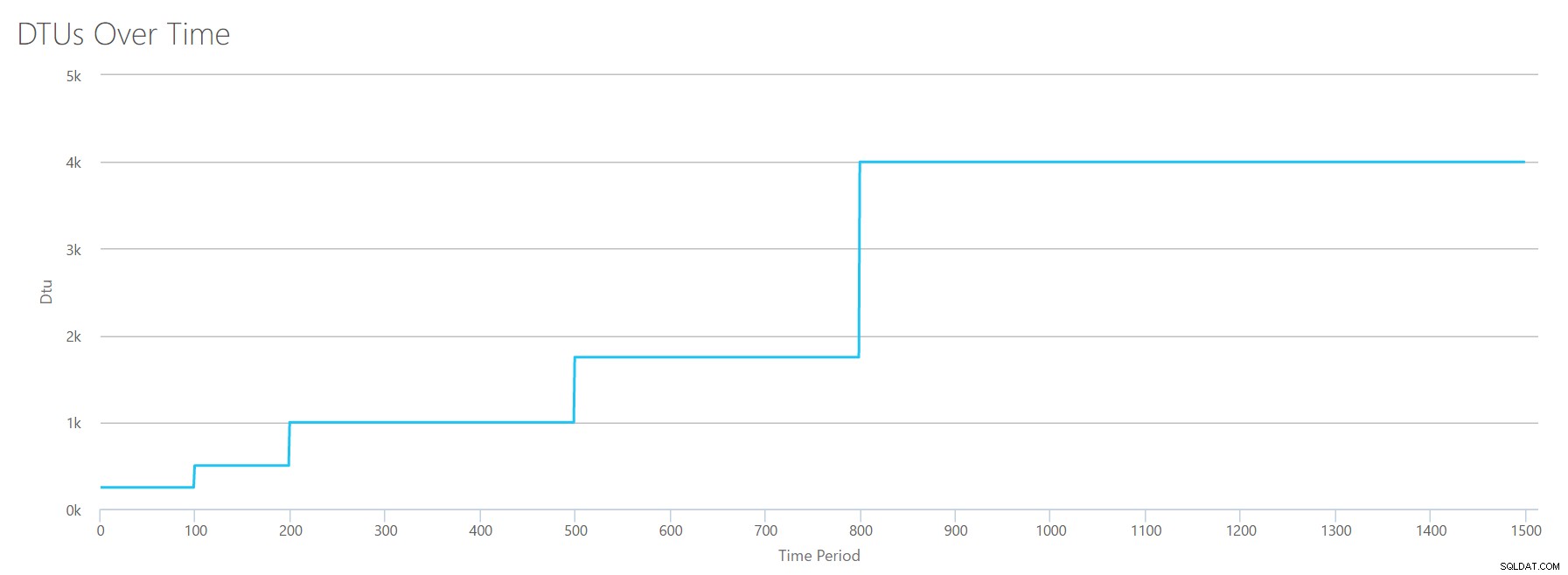
| Megabytes de log liberados/s | DTUs | Nível de serviço |
|---|---|---|
| 5 | 250 | Premium – P2 |
| 10 | 500 | Premium – P4 |
| 15-25 | 1000 | Premium – P6 |
| 30-40 | 1750 | Premium – P11 |
| 45-75 | 4000 | Premium – P15 |
A forma deste gráfico está ficando bastante previsível. Só que desta vez, avançamos pelas camadas um pouco mais rápido, atingindo P15 após apenas 8 etapas (em comparação com 11 para E/S e 12 para CPU). Isso pode levar você a pensar:"Este será meu gargalo mais estreito!" mas eu não teria tanta certeza disso. Com que frequência você está gerando 75 MB de log em um segundo ? São 4,5 GB por minuto . Isso é muita atividade de banco de dados. Minha carga de trabalho sintética não é necessariamente uma carga de trabalho realista.
Combinando tudo
OK, agora que vimos onde alguns dos limites superiores estão isolados, vou combinar os dados e ver como eles se comparam quando CPU, E/S e E/S de log de transações estão acontecendo ao mesmo tempo – afinal , não é assim que as coisas realmente acontecem?
Para construir este CSV, simplesmente peguei os valores existentes que usamos para cada teste individual acima e combinei esses valores em um único CSV, o que produz este adorável gráfico:
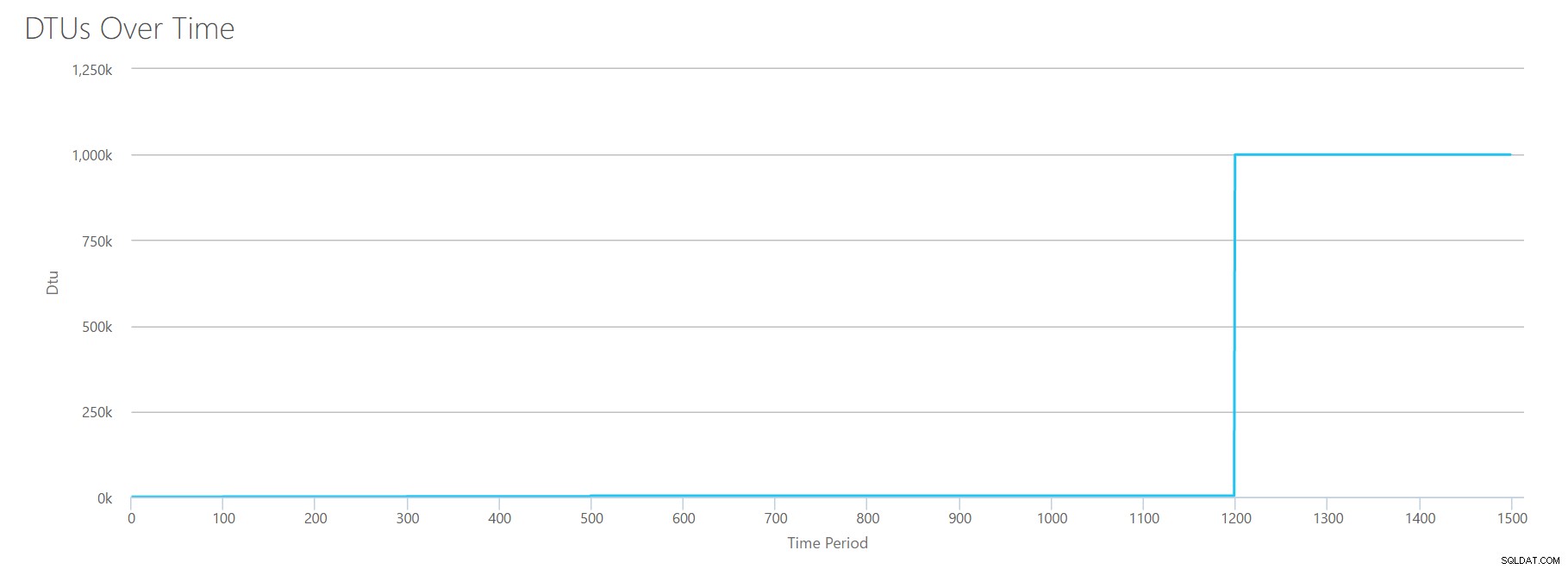
Ele também gera a mensagem:
Com base na utilização do banco de dados, sua carga de trabalho do SQL Server está fora do intervalo . No momento, não há um nível de serviço/nível de desempenho que cubra sua utilização.
Se você olhar para o eixo Y, verá que atingimos "1.000k" (ou seja, 1 milhão) de DTUs na marca de 1.200 segundos. Isso parece... uhh... errado? Se observarmos os testes acima, a marca de 1.200 segundos foi quando todas as 4 métricas individuais atingiram a marca de 4.000 DTU, nível P15. Faz sentido que estaríamos fora do alcance, mas a forma do gráfico não faz muito sentido para mim - acho que a calculadora DTU apenas levantou as mãos e disse:"Que seja, Andy. É muito. É muito É um bajillion DTUs. Essa carga de trabalho não se encaixa no Banco de Dados SQL do Azure."
OK, então o que acontece antes a marca de 1200 segundos? Vamos cortar o CSV e reenviá-lo para a calculadora com apenas os primeiros 1200 segundos. Os valores máximos para cada coluna são:81% de CPU (ou apx 13 núcleos a 100%), 24.000 leituras/s, 24.000 gravações/s e 60 MB de log liberado/s.
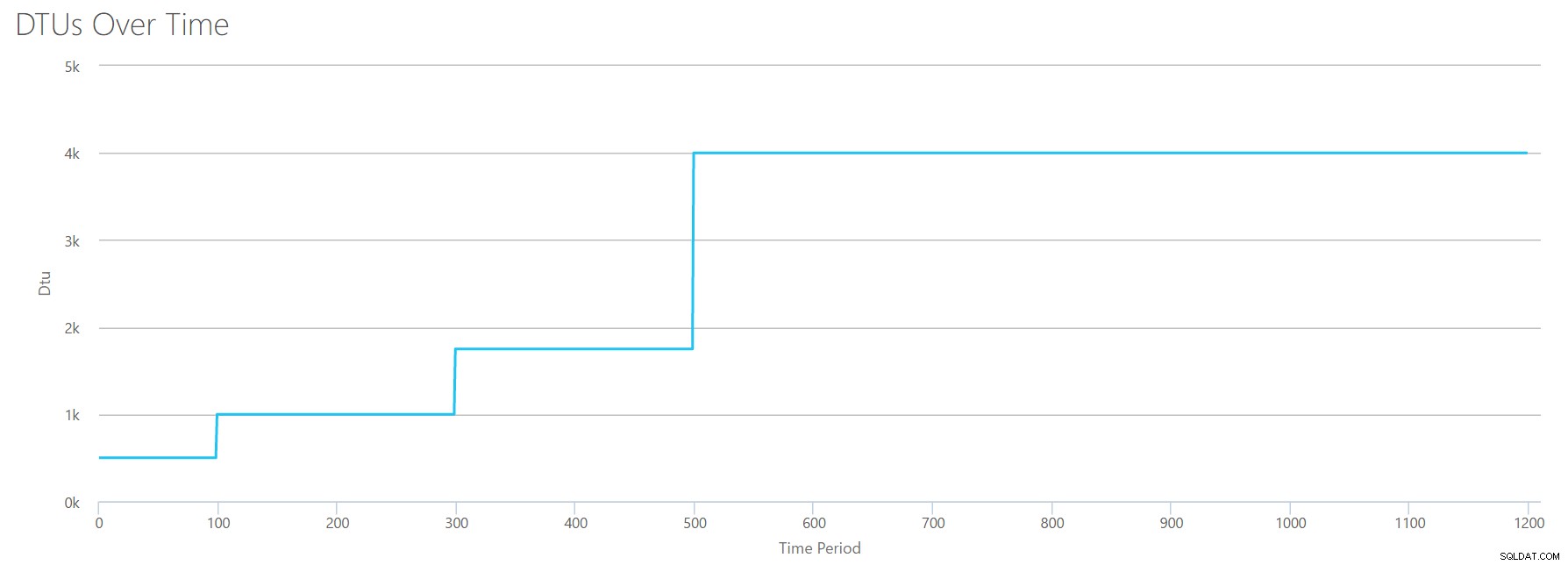
Olá, velho amigo… Aquela forma familiar está de volta. Aqui está um resumo dos dados do CSV e o que a Calculadora de DTU estima para o uso total de DTU e o nível de serviço.
| Número de núcleos | Leituras/s | Gravações/segundo | Megabytes de log liberados/s | DTUs | Nível de serviço |
|---|---|---|---|---|---|
| 1 | 2000 | 2000 | 5 | 500 | Premium – P4 |
| 2-3 | 4000-6000 | 4000-6000 | 10 | 1000 | Premium – P6 |
| 4-5 | 8000-10000 | 8000-10000 | 15-25 | 1750 | Premium – P11 |
| 6-13 | 12.000-24.000 | 12.000-24.000 | 30-40 | 4000 | Premium – P15 |
Agora, vamos ver como os cálculos de DTU individuais (quando os avaliamos isoladamente) se comparam aos cálculos de DTU desta verificação mais recente:
| DTUs de CPU | Ler DTUs | Escrever DTUs | DTUs de liberação de log | Soma do total de DTUs | Estimativa da Calculadora DTU | Nível de serviço |
|---|---|---|---|---|---|---|
| 100 | 250 | 250 | 250 | 850 | 500 | Premium – P4 |
| 500 | 500 | 500 | 500 | 2000 | 1000 | Premium – P6 |
| 500-1000 | 1000 | 1000 | 1000 | 3500-4000 | 1750 | Premium – P11 |
| 1000-1750 | 1000-1750 | 1000-1750 | 1750 | 4750-7000 | 4000 | Premium – P15 |
Você notará que o cálculo de DTU não é tão simples quanto somar suas DTUs separadas. Como a definição que citei no início afirma, é uma "medida combinada" dessas métricas separadas. A fórmula usada para "misturar" é complicada, e na verdade não temos essa fórmula. O que podemos ver é que as estimativas da Calculadora DTU são mais baixas do que a soma dos cálculos de DTU separados.
Mapeando DTUs para hardware tradicional
Vamos pegar os dados da Calculadora de DTU e tentar juntar algumas suposições sobre como o hardware tradicional pode mapear para algumas camadas do Banco de Dados SQL do Azure.
Primeiro, vamos supor que "reads/sec" e "writes/sec" traduzam para IOPS diretamente, sem necessidade de tradução. Em segundo lugar, vamos supor que adicionar esses dois contadores nos dará nosso IOPS total. Terceiro, vamos admitir que não temos ideia do que é o uso de memória e não temos como tirar conclusões a esse respeito.
Enquanto estou estimando as especificações de hardware, também escolherei um possível tamanho de VM do Azure que se ajuste a cada configuração de hardware. Há muitos tamanhos semelhantes de VM do Azure, cada um otimizado para diferentes métricas de desempenho, mas fui em frente e limitei minhas escolhas à Série A e à Série DSv2.
| Número de núcleos | IOPS | Memória | DTUs | Nível de serviço | Tamanho de VM do Azure comparável |
|---|---|---|---|---|---|
| 1 núcleo, 5% de utilização | 10 | ??? | 5 | Básico | Padrão_A0, pouco usado |
| <1 núcleo | 150 | ??? | 100 | Padrão S0-S3 | Padrão_A0, não totalmente utilizado |
| 1 núcleo | até 4.000 | ??? | 500 | Premium – P4 | Padrão_DS1_v2 |
| 2-3 núcleos | até 12.000 | ??? | 1000 | Premium – P6 | Padrão_DS3_v2 |
| 4-5 núcleos | até 20.000 | ??? | 1750 | Premium – P11 | Padrão_DS4_v2 |
| 6-13 | até 48.000 | ??? | 4000 | Premium – P15 | Padrão_DS5_v2 |
O nível Básico é incrivelmente limitado. É bom para uso ocasional/casual e é uma maneira barata de "estacionar" seu banco de dados quando você não o estiver usando. Mas se você estiver executando qualquer aplicativo real, a camada Básica não funcionará para você.
O nível padrão também é bastante limitado, mas para aplicativos pequenos, é capaz de atender às suas necessidades. Se você tiver um servidor de 2 núcleos executando vários bancos de dados, esses bancos de dados individualmente podem se encaixar na camada Padrão. Da mesma forma, se você tiver um servidor com apenas um banco de dados, executando 1 núcleo de CPU a 100% (ou 2 núcleos executando a 50%), provavelmente é apenas potência suficiente para inclinar a escala para a camada de serviço Premium-P1.
Se você estiver usando um servidor multinúcleo em um local (ou IaaS), estará procurando na camada de serviço Premium no Banco de Dados SQL do Azure. É apenas uma questão de determinar quanta potência de CPU e E/S você precisa para sua carga de trabalho. Seu servidor de 2 núcleos e 4 GB provavelmente o coloca em algum lugar em torno de um banco de dados SQL do Azure P6. Em uma carga de trabalho de CPU pura (com zero E/S), um banco de dados P15 pode lidar com 16 núcleos de processamento, mas depois que você adiciona E/S à mistura, qualquer coisa maior que ~ 12 núcleos não se encaixa no Banco de Dados SQL do Azure.
Da próxima vez, pegarei algumas cargas de trabalho reais e compararei o desempenho entre as camadas de serviço. As estimativas da Calculadora DTU serão precisas? Nós vamos descobrir.
Sobre o autor
 Andy Mallon é um DBA SQL Server e Microsoft Data Platform MVP que gerenciou bancos de dados nas áreas de saúde, finanças, e -comércio e setores sem fins lucrativos. Desde 2003, Andy oferece suporte a ambientes OLTP de alto volume e alta disponibilidade com necessidades de desempenho exigentes. Andy é o fundador do BostonSQL, co-organizador do SQLSaturday Boston, e bloga em am2.co.
Andy Mallon é um DBA SQL Server e Microsoft Data Platform MVP que gerenciou bancos de dados nas áreas de saúde, finanças, e -comércio e setores sem fins lucrativos. Desde 2003, Andy oferece suporte a ambientes OLTP de alto volume e alta disponibilidade com necessidades de desempenho exigentes. Andy é o fundador do BostonSQL, co-organizador do SQLSaturday Boston, e bloga em am2.co.