Como qualquer linguagem de programação, o T-SQL tem sua parcela de bugs e armadilhas comuns, alguns dos quais causam resultados incorretos e outros causam problemas de desempenho. Em muitos desses casos, existem práticas recomendadas que podem ajudá-lo a evitar problemas. Eu pesquisei colegas MVPs da Microsoft Data Platform perguntando sobre os bugs e armadilhas que eles veem com frequência ou que eles acham particularmente interessantes, e as práticas recomendadas que eles empregam para evitá-los. Tenho muitos casos interessantes.
Muito obrigado a Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser e Chan Ming Man por compartilhar seu conhecimento e experiência!
Este artigo é o primeiro de uma série sobre o tema. Cada artigo se concentra em um determinado tema. Este mês, concentro-me em bugs, armadilhas e melhores práticas relacionadas ao determinismo. Um cálculo determinístico é aquele que garante a produção de resultados repetíveis dadas as mesmas entradas. Existem muitos bugs e armadilhas que resultam do uso de cálculos não determinísticos. Neste artigo, abordo as implicações do uso de ordem não determinística, funções não determinísticas, várias referências a expressões de tabela com cálculos não determinísticos e o uso de expressões CASE e da função NULLIF com cálculos não determinísticos.
Eu uso o banco de dados de amostra TSQLV5 em muitos dos exemplos desta série.
Ordem não determinística
Uma fonte comum de bugs no T-SQL é o uso de ordem não determinística. Ou seja, quando seu pedido por lista não identifica exclusivamente uma linha. Pode ser pedido de apresentação, pedido de TOP/OFFSET-FETCH ou pedido de janela.
Tomemos, por exemplo, um cenário de paginação clássico usando o filtro OFFSET-FETCH. Você precisa consultar a tabela Sales.Orders retornando uma página de 10 linhas por vez, ordenadas por orderdate, decrescente (mais recente primeiro). Usarei constantes para os elementos de deslocamento e busca por simplicidade, mas normalmente são expressões baseadas em parâmetros de entrada.
A consulta a seguir (chamada de Consulta 1) retorna a primeira página dos 10 pedidos mais recentes:
USE TSQLV5; SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC OFFSET 0 ROWS FETCH NEXT 10 ROWS ONLY;
O plano para a Consulta 1 é mostrado na Figura 1.
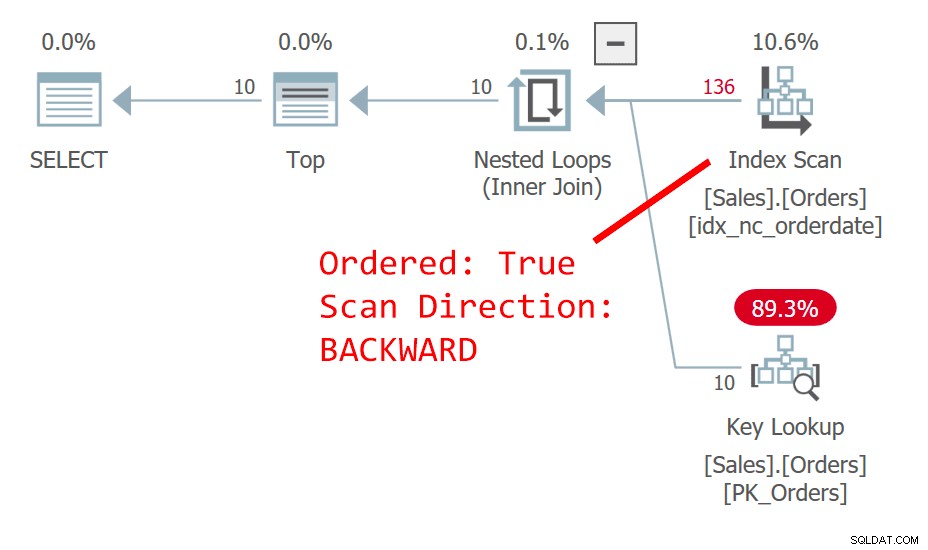 Figura 1:plano para consulta 1
Figura 1:plano para consulta 1 A consulta ordena as linhas por orderdate, decrescente. A coluna orderdate não identifica exclusivamente uma linha. Essa ordem não determinística significa que, conceitualmente, não há preferência entre as linhas com a mesma data. Em caso de empate, o que determina qual linha o SQL Server preferirá são coisas como escolhas de plano e layout de dados físicos — não algo em que você possa confiar como repetível. O plano na Figura 1 verifica o índice em orderdate ordenado para trás. Acontece que esta tabela tem um índice clusterizado em orderid, e em uma tabela clusterizada a chave de índice clusterizado é usada como um localizador de linha em índices não clusterizados. Na verdade, ele é posicionado implicitamente como o último elemento-chave em todos os índices não clusterizados, embora teoricamente o SQL Server pudesse tê-lo colocado no índice como uma coluna incluída. Portanto, implicitamente, o índice não clusterizado em orderdate é realmente definido em (orderdate, orderid). Consequentemente, em nossa varredura regressiva ordenada do índice, entre as linhas vinculadas com base em orderdate, uma linha com um valor de orderid mais alto é acessada antes de uma linha com um valor de orderid mais baixo. Essa consulta gera a seguinte saída:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 80 *** 11068 2019-05-04 62
Em seguida, use a seguinte consulta (chame-a de Consulta 2) para obter a segunda página de 10 linhas:
SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC OFFSET 10 ROWS FETCH PRÓXIMAS 10 ROWS ONLY;
O plano para Consulta é mostrado na Figura 2.
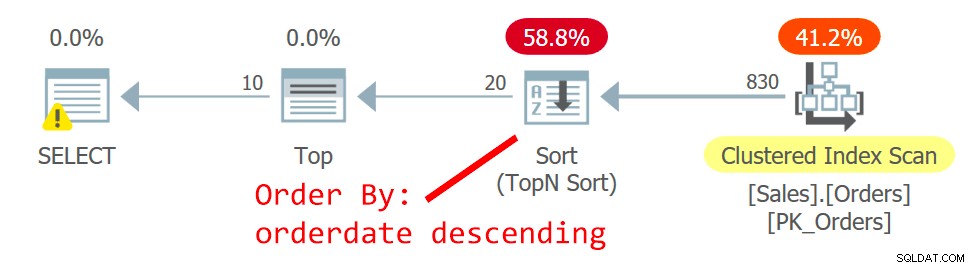
Figura 2:plano para consulta 2
O otimizador escolhe um plano diferente — um que verifica o índice clusterizado de forma não ordenada e usa um TopN Sort para dar suporte à solicitação do operador Top para lidar com o filtro de busca de deslocamento. O motivo da mudança é que o plano na Figura 1 usa um índice não abrangente não clusterizado e, quanto mais longe a página que você procura, mais pesquisas são necessárias. Com a solicitação da segunda página, você cruzou o ponto de inflexão que justifica o uso do índice não coberto.
Embora a varredura do índice clusterizado, que é definido com orderid como a chave, seja não ordenada, o mecanismo de armazenamento emprega uma varredura de ordem de índice internamente. Isso tem a ver com o tamanho do índice. Até 64 páginas, o mecanismo de armazenamento geralmente prefere varreduras de ordem de índice a varreduras de ordem de alocação. Mesmo que o índice fosse maior, sob o nível de isolamento de leitura confirmada e dados que não estão marcados como somente leitura, o mecanismo de armazenamento usa uma varredura de ordem de índice para evitar leitura dupla e pular linhas como resultado de divisões de página que ocorrem durante o Varredura. Nas condições dadas, na prática, entre linhas com a mesma data, este plano acessa uma linha com um orderid inferior antes de uma com um orderid superior.
Essa consulta gera a seguinte saída:
orderid orderdate custid ----------- ---------- ----------- 11069 2019-05-04 80 *** 11064 2019 -05-01 71 11065 2019-05-01 46 11066 2019-05-01 89 11060 2019-04-30 27 11061 2019-04-30 32 11062 2019-04-30 66 11063 2019-04-30 30 11063 2019-04-30 04-29 53 11058 2019-04-29 6
Observe que, embora os dados subjacentes não tenham sido alterados, você acabou com o mesmo pedido (com o ID do pedido 11069) retornado na primeira e na segunda página!
Felizmente, a melhor prática aqui é clara. Adicione um desempate ao seu pedido por lista para obter um pedido determinístico. Por exemplo, ordem por ordem decrescente decrescente, orderid decrescente.
Tente novamente pedindo a primeira página, desta vez com uma ordem determinística:
SELECT orderid, orderdate, custid DE Sales.Orders ORDER BY orderdate DESC, orderid DESC OFFSET 0 ROWS FETCH NEXT 10 ROWS ONLY;
Você obtém a seguinte saída, garantida:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 80 11068 2019-05-04 62
Peça a segunda página:
SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC, orderid DESC OFFSET 10 ROWS FETCH PRÓXIMAS 10 ROWS ONLY;
Você obtém a seguinte saída, garantida:
orderid orderdate custid ----------- ---------- ----------- 11067 2019-05-04 17 11066 2019-05- 01 89 11065 2019-05-01 46 11064 2019-05-01 71 11063 2019-04-30 37 11062 2019-04-30 66 11061 2019-04-30 32 11060 2019-04-30 32 2019-04-30 67 11058 29-04-2019 6
Desde que não haja alterações nos dados subjacentes, você terá a garantia de obter páginas consecutivas sem repetições ou pular linhas entre as páginas.
De maneira semelhante, usando funções de janela como ROW_NUMBER com ordem não determinística, você pode obter resultados diferentes para a mesma consulta, dependendo da forma do plano e da ordem de acesso real entre os laços. Considere a seguinte consulta (chame-a de Consulta 3), implementando a solicitação de primeira página usando números de linha (forçando o uso do índice na data do pedido para fins de ilustração):
WITH C AS ( SELECT orderid, orderdate, custid, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n FROM Sales.Orders WITH (INDEX(idx_nc_orderdate)) ) SELECT orderid, orderdate, custid FROM C WHERE n BETWEEN 1 E 10;
O plano para esta consulta é mostrado na Figura 3:
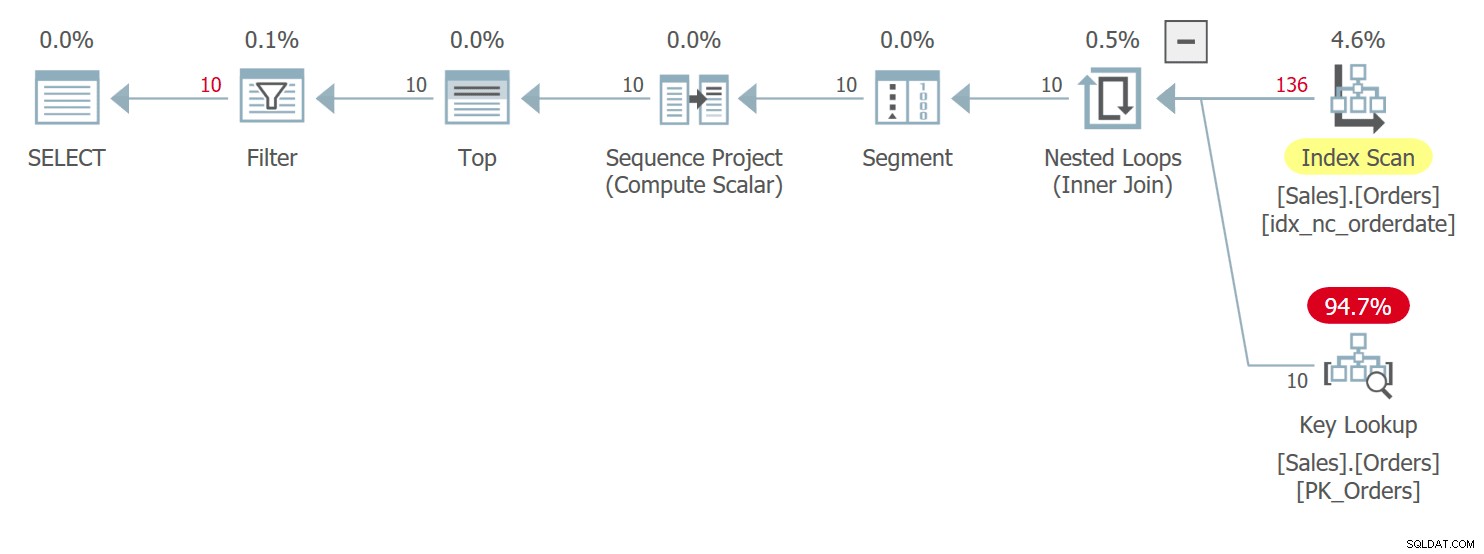
Figura 3:planejar a consulta 3
Você tem condições muito semelhantes aqui às que descrevi anteriormente para a Consulta 1 com seu plano mostrado anteriormente na Figura 1. Entre linhas com empates nos valores de orderdate, este plano acessa uma linha com um valor de orderid mais alto antes de uma com um menor valor do pedido. Essa consulta gera a seguinte saída:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 80 *** 11068 2019-05-04 62
Em seguida, execute a consulta novamente (chame-a de Consulta 4), solicitando a primeira página, só que desta vez force o uso do índice clusterizado PK_Orders:
WITH C AS ( SELECT orderid, orderdate, custid, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n FROM Sales.Orders WITH (INDEX(PK_Orders)) ) SELECT orderid, orderdate, custid FROM C WHERE n BETWEEN 1 E 10;
O plano para esta consulta é mostrado na Figura 4.

Figura 4:planejar a consulta 4
Desta vez, você tem condições muito semelhantes às que descrevi anteriormente para a Consulta 2 com seu plano mostrado anteriormente na Figura 2. Entre as linhas com empates nos valores de orderdate, esse plano acessa uma linha com um valor de orderid inferior antes de uma com um valor de pedido mais alto. Essa consulta gera a seguinte saída:
orderid orderdate custid ----------- ---------- ----------- 11074 2019-05-06 73 11075 2019-05- 06 68 11076 06-05-2019 9 11077 06-05-2019 65 11070 05-05-2019 44 11071 05-05-2019 46 11072 05-05-2019 20 11073 05-05-2019 58 05-05-2019 58 17 *** 11068 2019-05-04 62
Observe que as duas execuções produziram resultados diferentes, embora nada tenha mudado nos dados subjacentes.
Novamente, a melhor prática aqui é simples - use a ordem determinística adicionando um desempate, assim:
WITH C AS ( SELECT orderid, orderdate, custid, ROW_NUMBER() OVER(ORDER BY orderdate DESC, orderid DESC) AS n FROM Sales.Orders ) SELECT orderid, orderdate, custid FROM C WHERE n BETWEEN 1 AND 10;
Essa consulta gera a seguinte saída:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 80 11068 2019-05-04 62
O conjunto retornado é garantido para ser repetível, independentemente da forma do plano.
Provavelmente vale a pena mencionar que, como essa consulta não tem uma ordem de apresentação por cláusula na consulta externa, não há ordem de apresentação garantida aqui. Se você precisar de tal garantia, você deve adicionar uma ordem de apresentação por cláusula, assim:
WITH C AS ( SELECT orderid, orderdate, custid, ROW_NUMBER() OVER(ORDER BY orderdate DESC, orderid DESC) AS n FROM Sales.Orders ) SELECT orderid, orderdate, custid FROM C WHERE n BETWEEN 1 AND 10 ORDER BY n;Funções não determinísticas
Uma função não determinística é uma função que, dadas as mesmas entradas, pode retornar resultados diferentes em diferentes execuções da função. Exemplos clássicos são SYSDATETIME, NEWID e RAND (quando invocados sem uma semente de entrada). O comportamento de funções não determinísticas no T-SQL pode ser surpreendente para alguns e pode resultar em bugs e armadilhas em alguns casos.
Muitas pessoas assumem que quando você invoca uma função não determinística como parte de uma consulta, a função é avaliada separadamente por linha. Na prática, a maioria das funções não determinísticas é avaliada uma vez por referência na consulta. Considere a seguinte consulta como um exemplo:
SELECT orderid, SYSDATETIME() AS dt, RAND() AS rnd FROM Sales.Orders;
Como há apenas uma referência para cada uma das funções não determinísticas SYSDATETIME e RAND na consulta, cada uma dessas funções é avaliada apenas uma vez e seu resultado é repetido em todas as linhas de resultados. Eu obtive a seguinte saída ao executar esta consulta:
orderid dt rnd ----------- --------------------------- ------ ---------------- 11008 2019-02-04 17:03:07.9229177 0,962042872007464 11019 2019-02-04 17:03:07.9229177 0,962042872007464 11039 2019-02-04 17:03:07.9229177 0.962042872007464 11040 2019-02-04 17:03:07.9229177 0.962042872007464 11045 2019-02-04 17:03:07.9229177 0.962042872007464 11051 2019-02-04 17:03:07.9229177 0.962042872007464 11054 2019-02-04 17:03:07.9229177 0.962042872007464 11058 2019-02-04 17:03:07.9229177 0,962042872007464 11059 2019-02-04 17:03:07.9229177 0,96204272007464 1106119-02-02-02-02-02-20770.962042727464
Como um exemplo em que não entender esse comportamento pode resultar em um bug, suponha que você precise escrever uma consulta que retorne três pedidos aleatórios da tabela Sales.Orders. Uma tentativa inicial comum é usar uma consulta TOP com ordenação baseada na função RAND, pensando que a função seria avaliada separadamente por linha, assim:
SELECT TOP (3) orderid FROM Sales.Orders ORDER BY RAND();
Na prática, a função é avaliada apenas uma vez para toda a consulta; portanto, todas as linhas obtêm o mesmo resultado e a ordenação não é afetada. Na verdade, se você verificar o plano para esta consulta, não verá nenhum operador Sort. Quando executei essa consulta várias vezes, continuei obtendo o mesmo resultado:
ID do pedido ----------- 11008 11019 11039
A consulta é, na verdade, equivalente a uma sem uma cláusula ORDER BY, onde a ordenação da apresentação não é garantida. Portanto, tecnicamente, a ordenação não é determinística e, teoricamente, execuções diferentes podem resultar em uma ordem diferente e, portanto, em uma seleção diferente das 3 primeiras linhas. No entanto, a probabilidade disso é baixa e você não pode pensar nessa solução como produzindo três linhas aleatórias em cada execução.
Uma exceção à regra de que uma função não determinística é invocada uma vez por referência na consulta é a função NEWID, que retorna um identificador global exclusivo (GUID). Quando usada em uma consulta, esta função é invocado separadamente por linha. A consulta a seguir demonstra isso:
SELECT orderid, NEWID() AS mynewid FROM Sales.Orders;
Essa consulta gerou a seguinte saída:
orderid mynewid ----------- ---------------------------------- -- 11008 D6417542-C78A-4A2D-9517-7BB0FCF3B932 11019 E2E46BF1-4FA6-4EF2-8328-18B86259AD5D 11039 2917D923-AC60-44F5-92D7-FF84E52250CC 11040 B6287B49-DAE7-4C6C-98A8-7DB8A879581C 11045 2E14D8F7-21E5-4039-BF7E -0A27D1A0E186 11051 FA0B7B3E-BA41-4D80-8581-782EB88836C0 11054 1E6146BB-FEE7-4FF4-A4A2-3243AA2CBF78 11058 49302EA9-0243-4502-B9D2-46D751E6EFA9 11059 F5BB7CB2-3B17-4D01-ABD2-04F3C5115FCF 11061 09E406CA-0251-423B-8DF5 -564E1257F93E ...
O valor de NEWID em si é bastante aleatório. Se você aplicar a função CHECKSUM sobre ela, obterá um resultado inteiro com uma distribuição aleatória ainda melhor. Portanto, uma maneira de obter três pedidos aleatórios é usar uma consulta TOP com ordenação baseada em CHECKSUM(NEWID()), assim:
SELECT TOP (3) orderid FROM Sales.Orders ORDER BY CHECKSUM(NEWID());
Execute esta consulta repetidamente e observe que você obtém um conjunto diferente de três ordens aleatórias a cada vez. Eu obtive a seguinte saída em uma execução:
ID do pedido ----------- 11031 10330 10962
E a seguinte saída em outra execução:
código do pedido ----------- 10308 10885 10444
Além de NEWID, e se você precisar usar uma função não determinística como SYSDATETIME em uma consulta e precisar que ela seja avaliada separadamente por linha? Uma maneira de conseguir isso é usar uma função definida pelo usuário (UDF) que invoca a função não determinística, assim:
CRIAR OU ALTERAR FUNÇÃO dbo.MySysDateTime() RETURNS DATETIME2 AS BEGIN RETURN SYSDATETIME(); FIM; IR
Você então invoca a UDF na consulta assim (chame-a de Consulta 5):
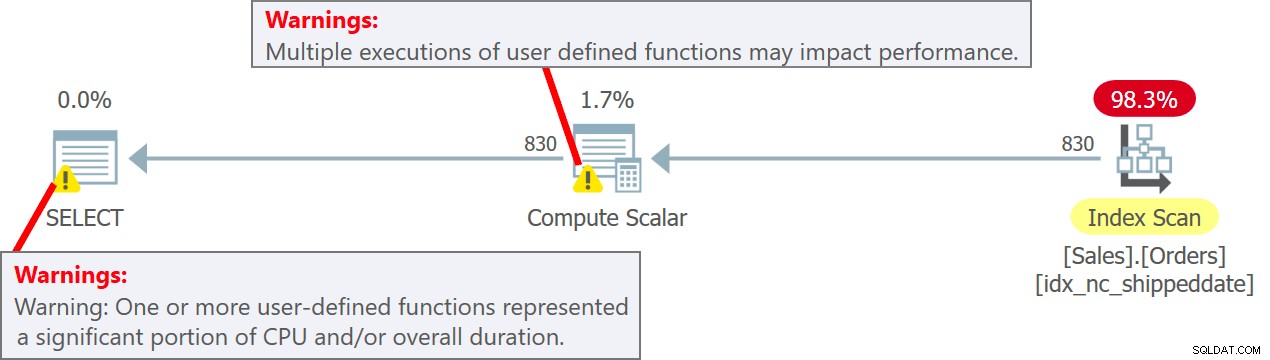
SELECT orderid, dbo.MySysDateTime() AS mydt FROM Sales.Orders;
A UDF é executada por linha desta vez. Você precisa estar ciente, porém, de que há uma penalidade de desempenho bastante acentuada associada à execução por linha da UDF. Além disso, invocar uma UDF T-SQL escalar é um inibidor de paralelismo.
O plano para esta consulta é mostrado na Figura 5.
Figura 5:planejar a consulta 5
Observe no plano que, de fato, a UDF é invocada por linha de origem no operador Compute Scalar. Observe também que o SentryOne Plan Explorer avisa sobre a possível penalidade de desempenho associada ao uso da UDF tanto no operador Compute Scalar quanto no nó raiz do plano.
Eu obtive a seguinte saída da execução desta consulta:
orderid mydt ----------- --------------------------- 11008 2019-02-04 17 :07:03.7221339 11019 2019-02-04 17:07:03.7221339 11039 2019-02-04 17:07:03.7221339 ... 10251 2019-02-04 17:07:093.7231315 10755 107:55 03.7231315 10248 2019-02-04 17:07:03.7231315 ... 10416 2019-02-04 17:07:03.7241304 10420 2019-02-04 17:07:03.7241304 1042102-02-02-04 17:07:03.7241304 10421214-02-02-04 .
Observe que as linhas de saída têm vários valores de data e hora diferentes na coluna mydt.
Você pode ter ouvido que o SQL Server 2019 aborda o problema de desempenho comum causado por UDFs T-SQL escalares ao inserir essas funções. No entanto, a UDF precisa atender a uma lista de requisitos para ser inlineável. Um dos requisitos é que a UDF não chame nenhuma função intrínseca não determinística, como SYSDATETIME. O raciocínio para esse requisito é que talvez você tenha criado a UDF exatamente para obter uma execução por linha. Se a UDF fosse embutida, a função não determinística subjacente seria executada apenas uma vez para toda a consulta. Na verdade, o plano na Figura 5 foi gerado no SQL Server 2019 e você pode ver claramente que a UDF não foi incorporada. Isso se deve ao uso da função não determinística SYSDATETIME. Você pode verificar se uma UDF é inlineável no SQL Server 2019 consultando o atributo is_inlineable na exibição sys.sql_modules, assim:
SELECT is_inlineable FROM sys.sql_modules WHERE object_id =OBJECT_ID(N'dbo.MySysDateTime');
Esse código gera a seguinte saída informando que o UDF MySysDateTime não é inlineável:
is_inlineable ------------- 0
Para demonstrar uma UDF que é inlineável, aqui está a definição de uma UDF chamada EndOfyear que aceita uma data de entrada e retorna a respectiva data de final de ano:
CRIAR OU ALTERAR FUNÇÃO dbo.EndOfYear(@dt AS DATE) RETURNS DATE AS BEGIN RETURN DATEADD(ano, DATEDIFF(ano, '18991231', @dt), '18991231'); FIM; IR
Não há uso de funções não determinísticas aqui, e o código também atende aos outros requisitos para inlining. Você pode verificar se a UDF é inlineável usando o seguinte código:
SELECT is_inlineable FROM sys.sql_modules WHERE object_id =OBJECT_ID(N'dbo.EndOfYear');
Este código gera a seguinte saída:
is_inlineable ------------- 1
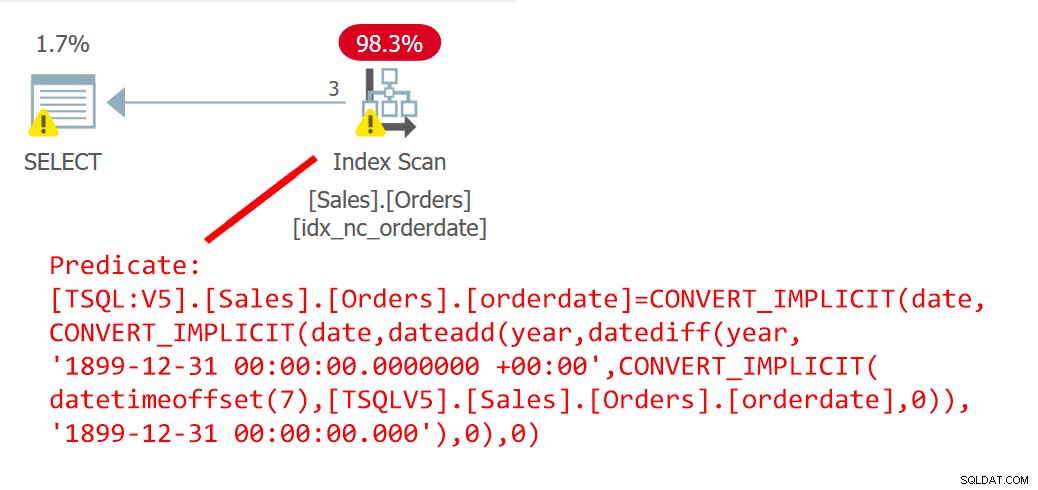
A consulta a seguir (chamada de Consulta 6) usa a UDF EndOfYear para filtrar pedidos que foram feitos em uma data de final de ano:
SELECT orderid FROM Sales.Orders WHERE orderdate =dbo.EndOfYear(orderdate);
O plano para esta consulta é mostrado na Figura 6.
Figura 6:planejar a consulta 6
O plano mostra claramente que a UDF foi alinhada.
Expressões de tabela, não determinismo e referências múltiplas
Conforme mencionado, funções não determinísticas como SYSDATETIME são invocadas uma vez por referência em uma consulta. Mas e se você fizer referência a essa função uma vez em uma consulta em uma expressão de tabela como um CTE e, em seguida, tiver uma consulta externa com várias referências ao CTE? Muitas pessoas não percebem que cada referência à expressão de tabela é expandida separadamente e o código embutido resulta em várias referências à função não determinística subjacente. Com uma função como SYSDATETIME, dependendo do tempo exato de cada uma das execuções, você pode acabar obtendo um resultado diferente para cada uma. Algumas pessoas acham esse comportamento surpreendente.
Isso pode ser ilustrado com o seguinte código:
DECLARE @i AS INT =1, @rc AS INT =NULL; ENQUANTO 1 =1 COMEÇA; WITH C1 AS ( SELECT SYSDATETIME() AS dt ), C2 AS ( SELECT dt FROM C1 UNION SELECT dt FROM C1 ) SELECT @rc =COUNT(*) FROM C2; SE @rc> 1 QUEBRA; SET @i +=1; FIM; SELECT @rc AS valores distintos, @i AS iterações;
Se ambas as referências a C1 na consulta em C2 representassem a mesma coisa, esse código resultaria em um loop infinito. No entanto, como as duas referências são expandidas separadamente, quando o tempo é tal que cada chamada ocorre em um intervalo diferente de 100 nanossegundos (a precisão do valor do resultado), a união resulta em duas linhas e o código deve quebrar do ciclo. Execute este código e veja por si mesmo. De fato, depois de algumas iterações, ele quebra. Eu obtive o seguinte resultado em uma das execuções:
iterações de valores distintos -------------- ----------- 2 448
A prática recomendada é evitar o uso de expressões de tabela como CTEs e exibições, quando a consulta interna usa cálculos não determinísticos e a consulta externa se refere à expressão de tabela várias vezes. Isso é claro, a menos que você entenda as implicações e esteja de acordo com elas. Opções alternativas podem ser persistir o resultado da consulta interna, digamos, em uma tabela temporária e, em seguida, consultar a tabela temporária quantas vezes você precisar.
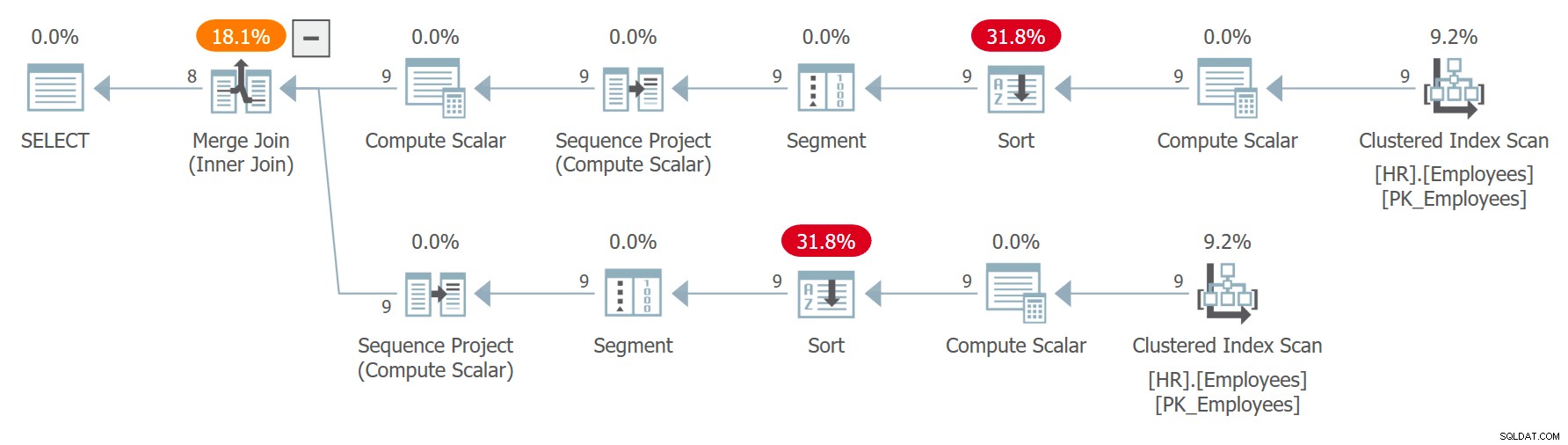
Para demonstrar exemplos em que não seguir a prática recomendada pode causar problemas, suponha que você precise escrever uma consulta que emparelhe funcionários da tabela HR.Employees aleatoriamente. Você cria a seguinte consulta (chame-a de consulta 7) para lidar com a tarefa:
WITH C AS ( SELECT empid, firstname, lastname, ROW_NUMBER() OVER(ORDER BY CHECKSUM(NEWID())) AS n FROM HR.Employees ) SELECT C1.empid AS empid1, C1.firstname AS firstname1, C1. lastname AS lastname1, C2.empid AS empid2, C2.firstname AS firstname2, C2.lastname AS lastname2 FROM C AS C1 INNER JOIN C AS C2 ON C1.n =C2.n + 1;
O plano para esta consulta é mostrado na Figura 7.
Figura 7:plano para a consulta 7
Observe que as duas referências a C são expandidas separadamente e os números de linha são calculados independentemente para cada referência ordenada por invocações independentes da expressão CHECKSUM(NEWID()). Isso significa que não é garantido que o mesmo funcionário obtenha o mesmo número de linha nas duas referências expandidas. Se um funcionário obtiver o número da linha x em C1 e o número da linha x – 1 em C2, a consulta emparelhará o funcionário com ele mesmo. Por exemplo, obtive o seguinte resultado em uma das execuções:
empid1 firstname1 lastname1 empid2 firstname2 lastname2 ------------ ---------- -------------------- ----------- ---------- -------------------- 3 Judy Lew 6 Paul Suurs 9 Patricia Doyle *** 9 Patricia Doyle *** 5 Sven Mortensen 4 Yael Peled 6 Paul Suurs 8 Maria Cameron 8 Maria Cameron 5 Sven Mortensen 2 Don Funk *** 2 Don Funk *** 4 Yael Peled 3 Judy Lew 7 Russell King ** * 7 Russel King ***
Observe que há três casos aqui de autopares. Isso é mais fácil de ver adicionando um filtro à consulta externa que procura especificamente por autopares, assim:
WITH C AS ( SELECT empid, firstname, lastname, ROW_NUMBER() OVER(ORDER BY CHECKSUM(NEWID())) AS n FROM HR.Employees ) SELECT C1.empid AS empid1, C1.firstname AS firstname1, C1. lastname AS lastname1, C2.empid AS empid2, C2.firstname AS firstname2, C2.lastname AS lastname2 FROM C AS C1 INNER JOIN C AS C2 ON C1.n =C2.n + 1 WHERE C1.empid =C2.empid;
Talvez seja necessário executar essa consulta várias vezes para ver o problema. Segue um exemplo do resultado que obtive em uma das execuções:
empid1 firstname1 lastname1 empid2 firstname2 lastname2 ------------ ---------- -------------------- ----------- ---------- -------------------- 5 Sven Mortensen 5 Sven Mortensen 2 Don Funk 2 Don Funk
Seguindo a prática recomendada, uma maneira de resolver esse problema é persistir o resultado da consulta interna em uma tabela temporária e, em seguida, consultar várias instâncias da tabela temporária conforme necessário.
Outro exemplo ilustra erros que podem resultar do uso de ordem não determinística e várias referências a uma expressão de tabela. Suponha que você precise consultar a tabela Sales.Orders e, para fazer a análise de tendências, deseja emparelhar cada pedido com o próximo com base no pedido da data do pedido. Sua solução deve ser compatível com sistemas anteriores ao SQL Server 2012, o que significa que você não pode usar as funções óbvias de LAG/LEAD. Você decide usar um CTE que calcula números de linha para posicionar linhas com base na ordenação de orderdate e, em seguida, une duas instâncias do CTE, emparelhando pedidos com base em um deslocamento de 1 entre os números de linha, assim (chame isso de Consulta 8):
WITH C AS ( SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n FROM Sales.Orders ) SELECT C1.orderid AS orderid1, C1.orderdate AS orderdate1, C1.custid AS custid1, C2.orderid AS orderid2, C2.orderdate AS orderdate2 FROM C AS C1 LEFT OUTER JOIN C AS C2 ON C1.n =C2.n + 1;
O plano para esta consulta é mostrado na Figura 8.
Figura 8:planejar a consulta 8
A ordenação do número da linha não é determinística, pois orderdate não é exclusiva. Observe que as duas referências ao CTE são expandidas separadamente. Curiosamente, como a consulta está procurando um subconjunto diferente de colunas de cada uma das instâncias, o otimizador decide usar um índice diferente em cada caso. Em um caso, ele usa uma varredura regressiva ordenada do índice em orderdate, varrendo efetivamente as linhas com a mesma data com base na ordem descendente de orderid. No outro caso ele varre o índice clusterizado, ordenou false e então ordena, mas efetivamente entre as linhas com a mesma data, ele acessa as linhas em ordem crescente de orderid. Isso se deve ao raciocínio semelhante que forneci na seção sobre ordem não determinística anterior. Isso pode resultar na mesma linha obtendo o número da linha x em uma instância e o número da linha x – 1 na outra instância. Nesse caso, a junção acabará combinando um pedido consigo mesmo, em vez de com o próximo, como deveria.
Eu obtive o seguinte resultado ao executar esta consulta:
orderid1 orderdate1 custid1 orderid2 orderdate2 ----------- ---------- ----------- ---------- - ---------- 11074 2019-05-06 73 NULL NULL 11075 2019-05-06 68 11077 2019-05-06 11076 2019-05-06 9 11076 2019-05-06 *** 11077 2019-05-06 65 11075 2019-05-06 11070 2019-05-05 44 11074 2019-05-06 11071 2019-05-05 46 11073 2019-05-05 11072 2019-05-05 20 11072 05 *** ...
Observe as autocorrespondências no resultado. Novamente, o problema pode ser identificado mais facilmente adicionando um filtro procurando por autocorrespondências, assim:
WITH C AS ( SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n FROM Sales.Orders ) SELECT C1.orderid AS orderid1, C1.orderdate AS orderdate1, C1.custid AS custid1, C2.orderid AS orderid2, C2.orderdate AS orderdate2 FROM C AS C1 LEFT OUTER JOIN C AS C2 ON C1.n =C2.n + 1 WHERE C1.orderid =C2.orderid;
Eu obtive a seguinte saída desta consulta:
orderid1 orderdate1 custid1 orderid2 orderdate2 ----------- ---------- ----------- ---------- - ---------- 11076 2019-05-06 9 11076 2019-05-06 11072 2019-05-05 20 11072 2019-05-05 11062 2019-04-30 66 11062 2019-04-30 11052 27-04-2019 34 11052 27-04-2019 11042 22-04-2019 15 11042 22-04-2019 ...
A melhor prática aqui é certificar-se de usar uma ordem exclusiva para garantir o determinismo, adicionando um desempate como orderid à cláusula de ordem da janela. Portanto, mesmo que você tenha várias referências ao mesmo CTE, os números das linhas serão os mesmos em ambos. Se você deseja evitar a repetição dos cálculos, também pode considerar persistir o resultado da consulta interna, mas precisa considerar o custo adicional de tal trabalho.
CASE/NULLIF e funções não determinísticas
Quando você tem várias referências a uma função não determinística em uma consulta, cada referência é avaliada separadamente. O que pode ser surpreendente e até resultar em bugs é que às vezes você escreve uma referência, mas implicitamente ela é convertida em várias referências. Essa é a situação com alguns usos da expressão CASE e da função IIF.
Considere o seguinte exemplo:
SELECT CASE ABS(CHECKSUM(NEWID())) % 2 QUANDO 0 ENTÃO 'Par' QUANDO 1 ENTÃO 'Ímpar' END;
Aqui o resultado da expressão testada é um valor inteiro não negativo, então claramente tem que ser par ou ímpar. Não pode ser nem par nem ímpar. No entanto, se você executar esse código várias vezes, às vezes você obterá um NULL indicando que a cláusula ELSE NULL implícita da expressão CASE foi ativada. A razão para isso é que a expressão acima se traduz no seguinte:
SELECT CASE WHEN ABS(CHECKSUM(NEWID())) % 2 =0 THEN 'Even' WHEN ABS(CHECKSUM(NEWID())) % 2 =1 THEN 'Odd' ELSE NULL END;
In the converted expression there are two separate references to the tested expression that generates a random nonnegative value, and each gets evaluated separately. One possible path is that the first evaluation produces an odd number, the second produces an even number, and then the ELSE NULL clause is activated.
Here’s a very similar situation with the NULLIF function:
SELECT NULLIF(ABS(CHECKSUM(NEWID())) % 2, 0);
This expression generates a random nonnegative value, and is supposed to return 1 when it’s odd, and NULL otherwise. It’s never supposed to return 0 since in such a case the 0 is supposed to be replaced with a NULL. Run it a few times and you will see that in some cases you get a 0. The reason for this is that the above expression internally translates to the following one:
SELECT CASE WHEN ABS(CHECKSUM(NEWID())) % 2 =0 THEN NULL ELSE ABS(CHECKSUM(NEWID())) % 2 END;
A possible path is that the first WHEN clause generates a random odd value, so the ELSE clause is activated, and the ELSE clause generates a random even value so the % 2 calculation results in a 0.
In both cases this behavior is standard, so the bug is more in the eyes of the beholder based on your expectations and your choice of how to write the code. The best practice in both cases is to persist the result of the original calculation and then interact with the persisted result. If it’s a single value, store the result in a variable first. If you’re querying tables, first persist the result of the nondeterministic calculation in a column in a temporary table, and then apply the CASE/IIF logic in the query against the temporary table.
Conclusão
This article is the first in a series about T-SQL bugs, pitfalls and best practices, and is the result of discussions with fellow Microsoft Data Platform MVPs who shared their experiences. This time I focused on bugs and pitfalls that resulted from using nondeterministic order and nondeterministic calculations. In future articles I’ll continue with other themes. If you have bugs and pitfalls that you often stumble into, or that you find as particularly interesting, please do share!