O Service Pack 2 para SQL Server 2014 foi lançado no mês passado (leia as notas de lançamento aqui) e inclui uma nova instrução DBCC:
DBCC CLONEDATABASE . Eu estava muito animado para ver este comando introduzido, pois fornece um muito fácil maneira de copiar um esquema de banco de dados, incluindo estatísticas , que pode ser usado para testar o desempenho da consulta sem exigir todo o espaço necessário para os dados no banco de dados. Finalmente consegui algum tempo para testar DBCC CLONEDATABASE e compreendo as limitações, e devo dizer que foi bastante divertido. Noções básicas
Comecei criando um clone do banco de dados AdventureWorks2014 e executando uma consulta no banco de dados de origem e, em seguida, no banco de dados clone:
DBCC CLONEDATABASE (N'AdventureWorks2014', N'AdventureWorks2014_CLONE'); GO SET STATISTICS IO ON; GO SET STATISTICS TIME ON; GO SET STATISTICS XML ON; GO USE [AdventureWorks2014]; GO SELECT * FROM [Sales].[SalesOrderHeader] [h] JOIN [Sales].[SalesOrderDetail] [d] ON [h].[SalesOrderID] = [d].[SalesOrderID] ORDER BY [SalesOrderDetailID]; GO USE [AdventureWorks2014_CLONE]; GO SELECT * FROM [Sales].[SalesOrderHeader] [h] JOIN [Sales].[SalesOrderDetail] [d] ON [h].[SalesOrderID] = [d].[SalesOrderID] ORDER BY [SalesOrderDetailID]; GO SET STATISTICS IO OFF; GO SET STATISTICS TIME OFF; GO SET STATISTICS XML OFF; GO
Se eu observar a saída de E/S e TIME, posso ver que a consulta no banco de dados de origem demorou mais e gerou muito mais E/S, ambas esperadas, pois o banco de dados clone não possui dados:
/* banco de dados FONTE */
Tempos de execução do SQL Server:
tempo de CPU =0 ms, tempo decorrido =0 ms.
Tempo de análise e compilação do SQL Server:
tempo de CPU =0 ms, tempo decorrido =4 ms.
(121317 linhas afetadas)
Tabela 'SalesOrderHeader'. Contagem de varredura 0, leituras lógicas 371567, leituras físicas 0, leituras antecipadas 0, leituras lógicas lob 0, leituras físicas lob 0, leituras antecipadas lob 0.
Tabela 'Mesa de trabalho'. Contagem de varredura 0, leituras lógicas 0, leituras físicas 0, leituras antecipadas 0, leituras lógicas lob 0, leituras físicas lob 0, leituras antecipadas lob 0.
Tabela 'Detalhe do PedidoDeVendas'. Contagem de varredura 5, leituras lógicas 1361, leituras físicas 0, leituras antecipadas 0, leituras lógicas lob 0, leituras físicas lob 0, leituras antecipadas lob 0.
Tabela 'Mesa de trabalho'. Contagem de varredura 0, leituras lógicas 0, leituras físicas 0, leituras antecipadas 0, leituras lógicas lob 0, leituras físicas lob 0, leituras antecipadas lob 0.
(1 linha(s) afetada)
Tempos de execução do SQL Server:
tempo de CPU =686 ms, tempo decorrido =2548 ms.
/* CLONE banco de dados */
Tempos de execução do SQL Server:
tempo de CPU =0 ms, tempo decorrido =0 ms.
Tempo de análise e compilação do SQL Server:
tempo de CPU =12 ms, tempo decorrido =12 ms.
(0 linha(s) afetadas)
Tabela 'Mesa de trabalho'. Contagem de varredura 0, leituras lógicas 0, leituras físicas 0, leituras antecipadas 0, leituras lógicas lob 0, leituras físicas lob 0, leituras antecipadas lob 0.
Tabela 'SalesOrderHeader'. Contagem de varredura 0, leituras lógicas 0, leituras físicas 0, leituras antecipadas 0, leituras lógicas lob 0, leituras físicas lob 0, leituras antecipadas lob 0.
Tabela 'Detalhe do PedidoDeVendas'. Contagem de varredura 5, leituras lógicas 0, leituras físicas 0, leituras antecipadas 0, leituras lógicas lob 0, leituras físicas lob 0, leituras antecipadas lob 0.
(1 linha(s) afetada)
Tempos de execução do SQL Server:
tempo de CPU =0 ms, tempo decorrido =83 ms.
Se eu observar os planos de execução, eles são os mesmos para os dois bancos de dados, exceto pelos valores reais (a quantidade de dados que realmente se moveu pelo plano):
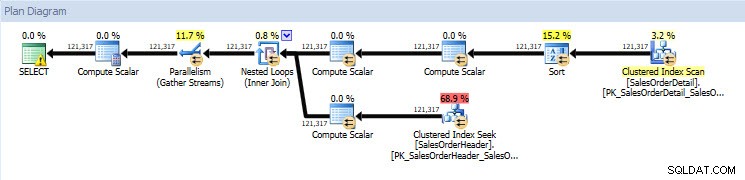 Plano de consulta para banco de dados AdventureWorks2014
Plano de consulta para banco de dados AdventureWorks2014 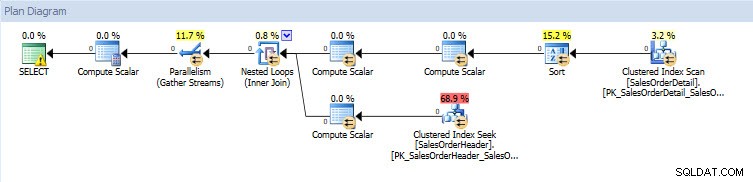 Plano de consulta para o banco de dados AdventureWorks2014_CLONE
Plano de consulta para o banco de dados AdventureWorks2014_CLONE É aqui que o valor de
DBCC CLONEDATABASE é aparente – posso obter uma cópia vazia de um banco de dados para qualquer pessoa (Suporte ao produto da Microsoft, meu colega DBA, etc.) e fazer com que recriem e investiguem um problema, e eles não precisam potencialmente de centenas de GB de espaço em disco para fazer isto. A postagem de terça-feira do T-SQL de julho da Melissa tem informações detalhadas sobre o que acontece durante o processo de clonagem, então recomendo a leitura para obter mais informações. É isso?
Mas… posso fazer mais com
DBCC CLONEDATABASE ? Quer dizer, isso é ótimo, mas acho que há muitas outras coisas que posso fazer com uma cópia vazia do banco de dados. Se você ler a documentação para DBCC CLONEDATABASE , você verá esta linha:Os Serviços de Atendimento ao Cliente da Microsoft podem solicitar que você gere um clone de um banco de dados usando DBCC CLONEDATABASE para investigar um problema de desempenho relacionado ao otimizador de consulta.
Meu primeiro pensamento foi:“otimizador de consulta – hmm… posso usar isso como uma opção para testar atualizações ?”
Bem, o banco de dados clonado é somente leitura, mas pensei em tentar alterar algumas opções de qualquer maneira. Por exemplo, se eu pudesse alterar o modo de compatibilidade, seria muito legal, pois assim eu poderia testar as alterações do CE no SQL Server 2014 e no SQL Server 2016.
USE [master]; GO ALTER DATABASE [AdventureWorks2014_CLONE] SET COMPATIBILITY_LEVEL = 110;
Eu recebo um erro:
Msg 3906, Level 16, State 1
Falha ao atualizar o banco de dados "AdventureWorks2014_CLONE" porque o banco de dados é somente leitura.
Msg 5069, Level 16, State 1
A instrução ALTER DATABASE falhou.
Hum. Posso alterar o modelo de recuperação?
ALTER DATABASE [AdventureWorks2014_CLONE] SET RECOVERY SIMPLE WITH NO_WAIT;
Eu posso. Isso não parece justo. Bem, é somente leitura, posso mudar isso?
ALTER DATABASE [AdventureWorks2014_CLONE] SET READ_WRITE WITH NO_WAIT;
SIM! Antes que você fique muito animado, deixe-me deixar esta nota da documentação aqui:
Observação O banco de dados recém-gerado gerado a partir de DBCC CLONEDATABASE não tem suporte para ser usado como um banco de dados de produção e destina-se principalmente para fins de diagnóstico e solução de problemas. Recomendamos desanexar o banco de dados clonado após a criação do banco de dados.
Vou repetir esta linha da documentação, colocar em negrito e vermelho como amigável, mas extremamente importante lembrete:
O banco de dados recém-gerado gerado a partir de DBCC CLONEDATABASE não tem suporte para ser usado como um banco de dados de produção e destina-se principalmente à solução de problemas e fins de diagnóstico.
Bem, tudo bem para mim, eu definitivamente não usaria isso para produção, mas agora posso usá-lo para testes! AGORA posso alterar o modo de compatibilidade e AGORA posso fazer backup e restaurá-lo em outra instância para teste!
USE [master]; GO BACKUP DATABASE [AdventureWorks2014_CLONE] TO DISK = N'C:\Backups\AdventureWorks2014_CLONE.bak' WITH INIT, NOFORMAT, STATS = 10, NAME = N'AW2014_CLONE_full'; GO /* restore on SQL Server 2016 */ RESTORE DATABASE [AdventureWorks2014_CLONE] FROM DISK = N'C:\Backups\AdventureWorks2014_CLONE.bak' WITH MOVE N'AdventureWorks2014_Data' TO N'C:\Databases\AdventureWorks2014_Data_2684624044.mdf', MOVE N'AdventureWorks2014_Log' TO N'C:\Databases\AdventureWorks2014_Log_3195542593.ldf', NOUNLOAD, REPLACE, STATS = 5; GO ALTER DATABASE [AdventureWorks2014_CLONE] SET COMPATIBILITY_LEVEL = 130; GO
ISSO É GRANDE.
No meu último post eu falei sobre trace flag 2389 e teste com o novo Cardinality Estimator porque, amigos, você precisa estar testando com o novo CE antes de atualizar. Se você não testar e alterar o modo de compatibilidade para 120 (SQL Server 2014) ou 130 (SQL Server 2016) como parte de sua atualização, corre o risco de trabalhar em um modo de combate a incêndios se encontrar regressões com o novo CE. Agora, você pode ficar bem e o desempenho pode ser ainda melhor após a atualização. Mas... você não gostaria de ter certeza?
Muitas vezes, quando menciono o teste antes de uma atualização, me dizem que não há ambiente para fazer o teste. Eu sei que alguns de vocês têm um ambiente de teste. Alguns de vocês têm Test, Dev, QA, UAT e quem sabe o que mais. Você é sortudo.
Para aqueles de vocês que afirmam que não têm ambiente de teste para testar, dou
DBCC CLONEDATABASE . Com este comando, você não tem desculpa para não executar as consultas executadas com mais frequência e os pesos pesados em um clone do seu banco de dados. Mesmo que você não tenha um ambiente de teste, você tem sua própria máquina. Faça backup do banco de dados clone da produção, elimine o clone, restaure o backup para sua instância local e teste. O banco de dados clone ocupa muito pouco espaço em disco e você não incorrerá em contenção de memória ou E/S, pois não há dados. Você vai ser capaz de validar os planos de consulta do clone em relação aos do seu banco de dados de produção. Além disso, se você restaurar no SQL Server 2016, poderá incorporar o Query Store em seus testes! Habilite o Repositório de Consultas, execute seus testes no modo de compatibilidade original, atualize o modo de compatibilidade e teste novamente. Você pode usar o Query Store para comparar consultas lado a lado! (Você pode dizer que estou dançando na minha cadeira agora?) Considerações
Novamente, isso não deve ser algo que você usaria em produção, e eu sei que você não faria isso, mas vale a pena repetir porque em seu estado atual,
DBCC CLONEDATABASE não está totalmente concluído . Isso é observado no artigo da base de conhecimento em objetos com suporte; objetos como tabelas com otimização de memória e tabelas de arquivos não são copiados, texto completo não é suportado, etc. Agora, o banco de dados clone tem suas desvantagens. Se você inadvertidamente executar uma reconstrução de índice ou uma atualização de estatísticas nesse banco de dados, você acabou de eliminar seus dados de teste. Você perderá as estatísticas originais, que é o que provavelmente você realmente queria em primeiro lugar. Por exemplo, se eu verificar as estatísticas do índice clusterizado em SalesOrderHeader agora, recebo isto:
USE [AdventureWorks2014_CLONE]; GO DBCC SHOW_STATISTICS (N'Sales.SalesOrderHeader',PK_SalesOrderHeader_SalesOrderID);
 Estatísticas originais para SalesOrderHeader
Estatísticas originais para SalesOrderHeader Agora, se eu atualizar as estatísticas dessa tabela, recebo isso:
UPDATE STATISTICS [Sales].[SalesOrderHeader] WITH FULLSCAN; GO DBCC SHOW_STATISTICS (N'Sales.SalesOrderHeader',PK_SalesOrderHeader_SalesOrderID);
 Estatísticas atualizadas (vazias) para SalesOrderHeader
Estatísticas atualizadas (vazias) para SalesOrderHeader Como segurança adicional, provavelmente é uma boa ideia desabilitar as atualizações automáticas das estatísticas:
USE [master]; GO ALTER DATABASE [AdventureWorks2014_CLONE] SET AUTO_UPDATE_STATISTICS OFF WITH NO_WAIT;
Se você atualizar as estatísticas acidentalmente, executando
DBCC CLONEDATABASE e passar pelo processo de backup e restauração não é tão difícil, e você o automatizará rapidamente. Você pode adicionar dados ao banco de dados. Isso pode ser útil se você quiser experimentar estatísticas (por exemplo, diferentes taxas de amostragem, estatísticas filtradas) e tiver armazenamento suficiente para manter uma cópia dos dados da tabela.
Sem dados no banco de dados, você obviamente não obterá dados de duração e E/S representativos confiáveis. Isso está ok. Se você precisar de dados sobre o uso real de recursos, precisará de uma cópia do banco de dados com todos os dados nele.
DBCC CLONEDATABASE trata-se realmente de testar o desempenho da consulta; é isso. Não substitui de forma alguma os testes de atualização tradicionais, mas é uma nova opção para validar como o SQL Server otimiza uma consulta com diferentes versões e modos de compatibilidade. Feliz teste!