Uma definição simples de mediana é:
A mediana é o valor do meio em uma lista ordenada de números
Para detalhar um pouco, podemos encontrar a mediana de uma lista de números usando o seguinte procedimento:
- Ordenar os números (em ordem crescente ou decrescente, não importa qual).
- O número do meio (por posição) na lista ordenada é a mediana.
- Se houver dois números "igualmente centrais", a mediana será a média dos dois valores centrais.
Aaron Bertrand testou anteriormente várias maneiras de calcular a mediana no SQL Server:
- Qual é a maneira mais rápida de calcular a mediana?
- Melhores abordagens para mediana agrupada
Rob Farley recentemente adicionou outra abordagem voltada para instalações pré-2012:
- Médias pré-SQL 2012
Este artigo apresenta um novo método usando um cursor dinâmico.
O método 2012 OFFSET-FETCH
Começaremos analisando a implementação de melhor desempenho, criada por Peter Larsson. Ele usa o SQL Server 2012
OFFSET extensão para o ORDER BY cláusula para localizar eficientemente uma ou duas linhas do meio necessárias para calcular a mediana. Média única de deslocamento
O primeiro artigo de Aaron testou a computação de uma única mediana em uma tabela de dez milhões de linhas:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id); A solução de Peter Larsson usando o
OFFSET extensão é:DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); O código acima codifica o resultado da contagem das linhas na tabela. Todos os métodos testados para calcular a mediana precisam dessa contagem para calcular os números das linhas medianas, portanto, é um custo constante. Deixar a operação de contagem de linhas fora do tempo evita uma possível fonte de variação.
O plano de execução para o
OFFSET solução é mostrada abaixo:
O operador Top rapidamente pula as linhas desnecessárias, passando apenas uma ou duas linhas necessárias para calcular a mediana para o Stream Aggregate. Quando executada com um cache quente e uma coleção de planos de execução desativados, essa consulta é executada por 910 ms em média no meu laptop. Esta é uma máquina com um processador Intel i7 740QM rodando a 1,73 GHz com Turbo desabilitado (para consistência).
Média Agrupada OFFSET
O segundo artigo de Aaron testou o desempenho do cálculo de uma mediana por grupo, usando uma tabela de vendas de um milhão de linhas com dez mil entradas para cada um dos cem vendedores:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount); Novamente, a solução de melhor desempenho usa
OFFSET :DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
SELECT d.SalesPerson, w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z WITH (PAGLOCK)
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w(Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); A parte importante do plano de execução é mostrada abaixo:

A linha superior do plano se preocupa em encontrar a contagem de linhas do grupo para cada vendedor. A linha inferior usa os mesmos elementos de plano vistos para a solução mediana de grupo único para calcular a mediana para cada vendedor. Quando executado com um cache quente e planos de execução desativados, essa consulta é executada em 320 ms em média no meu laptop.
Usando um cursor dinâmico
Pode parecer loucura pensar em usar um cursor para calcular a mediana. Os cursores Transact SQL têm uma reputação (principalmente bem merecida) de serem lentos e ineficientes. Também se pensa frequentemente que os cursores dinâmicos são o pior tipo de cursor. Esses pontos são válidos em algumas circunstâncias, mas nem sempre.
Os cursores do Transact SQL são limitados ao processamento de uma única linha por vez, portanto, podem ser lentos se muitas linhas precisarem ser buscadas e processadas. No entanto, esse não é o caso do cálculo da mediana:tudo o que precisamos fazer é localizar e buscar um ou dois valores médios com eficiência . Um cursor dinâmico é muito adequado para esta tarefa, como veremos.
Cursor dinâmico mediano único
A solução de cursor dinâmico para um único cálculo de mediana consiste nas seguintes etapas:
- Crie um cursor rolável dinâmico sobre a lista ordenada de itens.
- Calcule a posição da primeira linha mediana.
- Reposicione o cursor usando
FETCH RELATIVE. - Decida se uma segunda linha é necessária para calcular a mediana.
- Se não, retorne o valor mediano único imediatamente.
- Caso contrário, busque o segundo valor usando
FETCH NEXT. - Calcule a média dos dois valores e retorne.
Observe como essa lista reflete o procedimento simples para encontrar a mediana fornecida no início deste artigo. Uma implementação completa do código Transact SQL é mostrada abaixo:
-- Dynamic cursor
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE
@RowCount bigint, -- Total row count
@Row bigint, -- Median row number
@Amount1 integer, -- First amount
@Amount2 integer, -- Second amount
@Median float; -- Calculated median
SET @RowCount = 10000000;
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
DECLARE Median CURSOR
LOCAL
SCROLL
DYNAMIC
READ_ONLY
FOR
SELECT
O.val
FROM dbo.obj AS O
ORDER BY
O.val;
OPEN Median;
-- Calculate the position of the first median row
SET @Row = (@RowCount + 1) / 2;
-- Move to the row
FETCH RELATIVE @Row
FROM Median
INTO @Amount1;
IF @Row = (@RowCount + 2) / 2
BEGIN
-- No second row, median is the single value we have
SET @Median = @Amount1;
END
ELSE
BEGIN
-- Get the second row
FETCH NEXT
FROM Median
INTO @Amount2;
-- Calculate the median value from the two values
SET @Median = (@Amount1 + @Amount2) / 2e0;
END;
SELECT Median = @Median;
SELECT DynamicCur = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); O plano de execução para o
FETCH RELATIVE A instrução mostra o cursor dinâmico reposicionando com eficiência para a primeira linha necessária para o cálculo da mediana: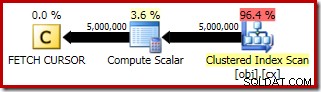
O plano para o
FETCH NEXT (necessário apenas se houver uma segunda linha do meio, como nesses testes) é uma busca de linha única da posição salva do cursor: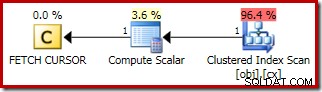
As vantagens de usar um cursor dinâmico aqui são:
- Evita percorrer todo o conjunto (a leitura pára depois que as linhas medianas são encontradas); e
- Nenhuma cópia temporária dos dados é feita em tempdb , como seria para um cursor estático ou de conjunto de chaves.
Observe que não podemos especificar um
FAST_FORWARD cursor aqui (deixando a escolha de um plano estático ou dinâmico para o otimizador) porque o cursor precisa ser rolável para suportar FETCH RELATIVE . Dinâmico é a melhor escolha aqui de qualquer maneira. Quando executada com um cache quente e uma coleção de plano de execução desativada, essa consulta é executada por 930 ms em média na minha máquina de teste. Isso é um pouco mais lento que os 910 ms para o
OFFSET solução, mas o cursor dinâmico é significativamente mais rápido do que os outros métodos testados por Aaron e Rob e não requer o SQL Server 2012 (ou posterior). Não vou repetir o teste dos outros métodos anteriores a 2012 aqui, mas como exemplo do tamanho da lacuna de desempenho, a seguinte solução de numeração de linhas leva 1550 ms em média (70% mais lento):
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O WITH (PAGLOCK)
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT RowNumber = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); 
Teste de cursor dinâmico mediano agrupado
É simples estender a solução de cursor dinâmico mediano único para calcular medianas agrupadas. Por uma questão de consistência, vou usar cursores aninhados (sim, realmente):
- Abra um cursor estático sobre os vendedores e as contagens de linhas.
- Calcule a mediana para cada pessoa usando um novo cursor dinâmico a cada vez.
- Salve cada resultado em uma variável de tabela à medida que avançamos.
O código é mostrado abaixo:
-- Timing
DECLARE @s datetime2 = SYSUTCDATETIME();
-- Holds results
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
-- Variables
DECLARE
@SalesPerson integer, -- Current sales person
@RowCount bigint, -- Current row count
@Row bigint, -- Median row number
@Amount1 float, -- First amount
@Amount2 float, -- Second amount
@Median float; -- Calculated median
-- Row counts per sales person
DECLARE SalesPersonCounts
CURSOR
LOCAL
FORWARD_ONLY
STATIC
READ_ONLY
FOR
SELECT
SalesPerson,
COUNT_BIG(*)
FROM dbo.Sales
GROUP BY SalesPerson
ORDER BY SalesPerson;
OPEN SalesPersonCounts;
-- First person
FETCH NEXT
FROM SalesPersonCounts
INTO @SalesPerson, @RowCount;
WHILE @@FETCH_STATUS = 0
BEGIN
-- Records for the current person
-- Note dynamic cursor
DECLARE Person CURSOR
LOCAL
SCROLL
DYNAMIC
READ_ONLY
FOR
SELECT
S.Amount
FROM dbo.Sales AS S
WHERE
S.SalesPerson = @SalesPerson
ORDER BY
S.Amount;
OPEN Person;
-- Calculate median row 1
SET @Row = (@RowCount + 1) / 2;
-- Move to median row 1
FETCH RELATIVE @Row
FROM Person
INTO @Amount1;
IF @Row = (@RowCount + 2) / 2
BEGIN
-- No second row, median is the single value
SET @Median = @Amount1;
END
ELSE
BEGIN
-- Get the second row
FETCH NEXT
FROM Person
INTO @Amount2;
-- Calculate the median value
SET @Median = (@Amount1 + @Amount2) / 2e0;
END;
-- Add the result row
INSERT @Result (SalesPerson, Median)
VALUES (@SalesPerson, @Median);
-- Finished with the person cursor
CLOSE Person;
DEALLOCATE Person;
-- Next person
FETCH NEXT
FROM SalesPersonCounts
INTO @SalesPerson, @RowCount;
END;
---- Results
--SELECT
-- R.SalesPerson,
-- R.Median
--FROM @Result AS R;
-- Tidy up
CLOSE SalesPersonCounts;
DEALLOCATE SalesPersonCounts;
-- Show elapsed time
SELECT NestedCur = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); O cursor externo é deliberadamente estático porque todas as linhas nesse conjunto serão tocadas (também, um cursor dinâmico não está disponível devido à operação de agrupamento na consulta subjacente). Não há nada particularmente novo ou interessante para ver nos planos de execução desta vez.
O interessante é o desempenho. Apesar da criação e desalocação repetidas do cursor dinâmico interno, essa solução funciona muito bem no conjunto de dados de teste. Com um cache quente e planos de execução desativados, o script do cursor é concluído em 330 ms em média na minha máquina de teste. Isso é novamente um pouco mais lento que os 320 ms gravado pelo
OFFSET mediana agrupada, mas supera as outras soluções padrão listadas nos artigos de Aaron e Rob por uma grande margem. Novamente, como exemplo da diferença de desempenho em relação aos outros métodos não 2012, a seguinte solução de numeração de linhas é executada por 485 ms em média no meu equipamento de teste (50% pior):
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median numeric(38, 6) NOT NULL
);
INSERT @Result
SELECT
S.SalesPerson,
CA.Median
FROM
(
SELECT
SalesPerson,
NumRows = COUNT_BIG(*)
FROM dbo.Sales
GROUP BY SalesPerson
) AS S
CROSS APPLY
(
SELECT AVG(1.0 * SQ1.Amount) FROM
(
SELECT
S2.Amount,
rn = ROW_NUMBER() OVER (
ORDER BY S2.Amount)
FROM dbo.Sales AS S2 WITH (PAGLOCK)
WHERE
S2.SalesPerson = S.SalesPerson
) AS SQ1
WHERE
SQ1.rn BETWEEN (S.NumRows + 1)/2 AND (S.NumRows + 2)/2
) AS CA (Median);
SELECT RowNumber = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); 
Resumo dos resultados
No teste de mediana única, o cursor dinâmico foi executado por 930 ms versus 910 ms para o
OFFSET método.No teste de mediana agrupada, o cursor aninhado funcionou por 330 ms versus 320 ms para
OFFSET . Em ambos os casos, o método do cursor foi significativamente mais rápido que o outro método não
OFFSET métodos. Se você precisar calcular uma mediana única ou agrupada em uma instância anterior a 2012, um cursor dinâmico ou cursor aninhado realmente pode ser a escolha ideal. Desempenho do cache frio
Alguns de vocês podem estar se perguntando sobre o desempenho do cache frio. Executando o seguinte antes de cada teste:
CHECKPOINT; DBCC DROPCLEANBUFFERS;
Estes são os resultados para o teste de mediana única:
OFFSET método:940 msCursor dinâmico:955 ms
Para a mediana agrupada:
OFFSET método:380 msCursores aninhados:385 ms
Considerações finais
As soluções de cursor dinâmico realmente são significativamente mais rápidas do que as soluções não
OFFSET métodos para medianas simples e agrupadas, pelo menos com esses conjuntos de dados de amostra. Eu deliberadamente escolhi reutilizar os dados de teste de Aaron para que os conjuntos de dados não fossem intencionalmente desviados para o cursor dinâmico. Há talvez ser outras distribuições de dados para as quais o cursor dinâmico não é uma boa opção. No entanto, mostra que ainda há momentos em que um cursor pode ser uma solução rápida e eficiente para o tipo certo de problema. Até mesmo cursores dinâmicos e aninhados. Leitores atentos podem ter notado o
PAGLOCK dica no OFFSET teste de mediana agrupada. Isso é necessário para um melhor desempenho, por razões que abordarei no meu próximo artigo. Sem ele, a solução de 2012 na verdade perde para o cursor aninhado por uma margem decente (590ms versus 330 ms ).