O mecanismo de execução de consulta do SQL Server tem duas maneiras de implementar uma operação lógica de 'união de todos', usando os operadores físicos Concatenação e Concatenação de junção de mesclagem. Embora a operação lógica seja a mesma, existem diferenças importantes entre os dois operadores físicos que podem fazer uma enorme diferença na eficiência de seus planos de execução.
O otimizador de consulta faz um trabalho razoável ao escolher entre as duas opções em muitos casos, mas está longe de ser perfeito nessa área. Este artigo descreve as oportunidades de ajuste de consulta apresentadas pela Concatenação de junção de mesclagem e detalha os comportamentos internos e as considerações que você precisa conhecer para aproveitá-la ao máximo.
Concatenação

O operador Concatenação é relativamente simples:sua saída é o resultado da leitura completa de cada uma de suas entradas em sequência. O operador Concatenação é um n-ário operador físico, o que significa que pode ter '2...n' entradas. Para ilustrar, vamos revisitar o exemplo baseado em AdventureWorks do meu artigo anterior, "Reescrevendo consultas para melhorar o desempenho":
SELECT * INTO dbo.TH FROM Production.TransactionHistory; CREATE UNIQUE CLUSTERED INDEX CUQ_TransactionID ON dbo.TH (TransactionID); CREATE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID);
A consulta a seguir lista os IDs de produtos e transações para seis produtos específicos:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711;
Ele produz um plano de execução com um operador de Concatenação com seis entradas, como visto no SQL Sentry Plan Explorer:
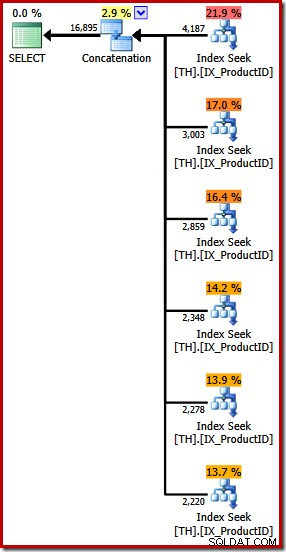
O plano acima apresenta uma Busca de Índice separada para cada ID de produto listado, na mesma ordem especificada na consulta (lendo de cima para baixo). A busca de índice mais alta é para o produto 870, a próxima é para o produto 873, depois 921 e assim por diante. Nada disso é comportamento garantido, é claro, é apenas algo interessante de observar.
Mencionei antes que o operador Concatenação forma sua saída lendo suas entradas em sequência. Quando esse plano é executado, há uma boa chance de que o conjunto de resultados mostre linhas para o produto 870 primeiro, depois 873, 921, 712, 707 e, finalmente, o produto 711. Novamente, isso não é garantido porque não especificamos um ORDER Cláusula BY, mas mostra como a Concatenação opera internamente.
Um "Plano de Execução" SSIS
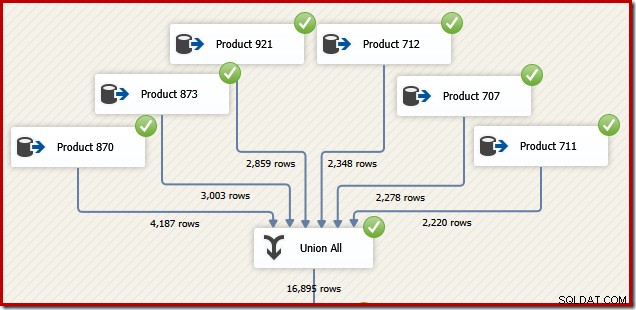
Por motivos que farão sentido em breve, considere como podemos projetar um pacote SSIS para executar a mesma tarefa. Certamente também poderíamos escrever tudo como uma única instrução T-SQL no SSIS, mas a opção mais interessante é criar uma fonte de dados separada para cada produto e usar um componente SSIS "Union All" no lugar da Concatenação do SQL Server operador:
Agora imagine que precisamos da saída final desse fluxo de dados na ordem de ID de transação. Uma opção seria adicionar um componente Sort explícito após o Union All:
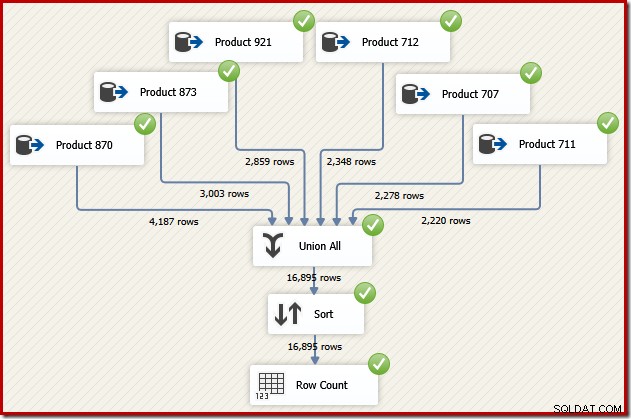
Isso certamente faria o trabalho, mas um designer SSIS qualificado e experiente perceberia que há uma opção melhor:leia os dados de origem para cada produto no pedido de ID de transação (utilizando o índice) e use uma operação de preservação de pedido para combinar os conjuntos .
No SSIS, o componente que combina linhas de dois fluxos de dados classificados em um único fluxo de dados classificado é chamado de "Mesclar". Um fluxo de dados SSIS redesenhado que usa Mesclar para retornar as linhas desejadas na ordem de ID de transação segue:
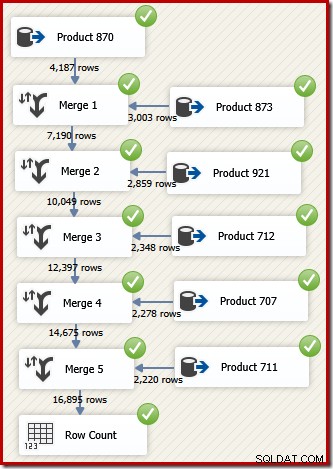
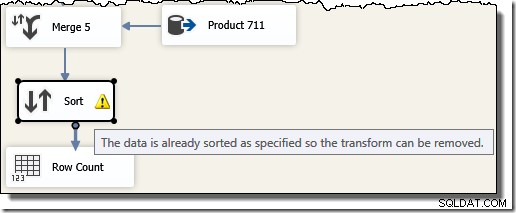
Observe que precisamos de cinco componentes Merge separados porque Merge é um componente binário, diferente do componente SSIS "Union All", que era n-ary . O novo fluxo de mesclagem produz resultados em ordem de ID de transação, sem exigir um componente de classificação caro (e bloqueante). De fato, se tentarmos adicionar um Sort on Transaction ID após o Merge final, o SSIS mostrará um aviso para nos informar que o fluxo já está classificado da maneira desejada:
O ponto do exemplo SSIS agora pode ser revelado. Observe o plano de execução escolhido pelo otimizador de consulta do SQL Server quando solicitamos que ele retorne os resultados da consulta T-SQL original na ordem de ID de transação (adicionando uma cláusula ORDER BY):
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711 ORDER BY TransactionID;
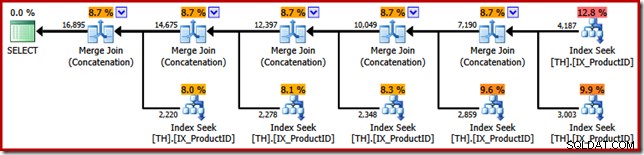
As semelhanças com o pacote SSIS Merge são impressionantes; até mesmo para a necessidade de cinco operadores binários "Merge". A única diferença importante é que o SSIS tem componentes separados para "Merge Join" e "Merge", enquanto o SQL Server usa o mesmo operador principal para ambos.
Para ser claro, os operadores Merge Join (Concatenação) no plano de execução do SQL Server não realizando uma junção; o motor simplesmente reutiliza o mesmo operador físico para implementar a união preservadora de todos os pedidos.
Escrevendo planos de execução no SQL Server
O SSIS não possui uma linguagem de especificação de fluxo de dados, nem um otimizador para transformar tal especificação em uma tarefa de fluxo de dados executável. Cabe ao designer de pacotes do SSIS perceber que é possível uma mesclagem que preserva a ordem, definir as propriedades do componente (como chaves de classificação) adequadamente e comparar o desempenho. Isso requer mais esforço (e habilidade) por parte do designer, mas fornece um grau muito bom de controle.
A situação no SQL Server é o oposto:escrevemos uma consulta especificação usando a linguagem T-SQL, então dependa do otimizador de consulta para explorar as opções de implementação e escolher uma eficiente. Não temos a opção de construir um plano de execução diretamente. Na maioria das vezes, isso é altamente desejável:o SQL Server sem dúvida seria menos popular se cada consulta exigisse que escrevêssemos um pacote no estilo SSIS.
No entanto (como explicado no meu post anterior), o plano escolhido pelo otimizador pode ser sensível ao T-SQL usado para descrever os resultados desejados. Repetindo o exemplo desse artigo, poderíamos ter escrito a consulta T-SQL original usando uma sintaxe alternativa:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
Essa consulta especifica exatamente o mesmo conjunto de resultados de antes, mas o otimizador não considera um plano de preservação de ordem (concatenação de mesclagem), optando por varrer o índice clusterizado (uma opção muito menos eficiente):
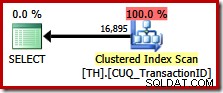
Aproveitando a preservação de pedidos no SQL Server
Evitar ordenações desnecessárias pode levar a ganhos de eficiência significativos, quer se trate de SSIS ou SQL Server. Alcançar esse objetivo pode ser mais complicado e difícil no SQL Server porque não temos um controle tão refinado sobre o plano de execução, mas ainda há coisas que podemos fazer.
Especificamente, entender como o operador de Concatenação de Junção de Mesclagem do SQL Server funciona internamente pode nos ajudar a continuar escrevendo T-SQL relacional e claro, enquanto incentiva o otimizador de consulta a considerar as opções de processamento de preservação de ordem (fusão) quando apropriado.
Como funciona a concatenação de junção de mesclagem

Um Merge Join regular requer que ambas as entradas sejam classificadas nas chaves de junção. A concatenação de junção de mesclagem, por outro lado, simplesmente mescla dois fluxos já ordenados em um único fluxo ordenado – não há junção, como tal.
Isso levanta a questão:qual é exatamente a 'ordem' que é preservada?
No SSIS, temos que definir as propriedades da chave de classificação nas entradas Merge para definir a ordenação. SQL Server não tem equivalente a isso. A resposta para a pergunta acima é um pouco complicada, então vamos passo a passo.
Considere o exemplo a seguir, que solicita uma concatenação de mesclagem de duas tabelas de heap não indexadas (o caso mais simples):
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT * FROM @T1 AS T1 UNION ALL SELECT * FROM @T2 AS T2 OPTION (MERGE UNION);
Essas duas tabelas não têm índices e não há cláusula ORDER BY. Que ordenação a concatenação de junção de mesclagem 'preservará'? Para lhe dar um momento para pensar sobre isso, vamos primeiro olhar para o plano de execução produzido para a consulta acima nas versões do SQL Server antes 2012:
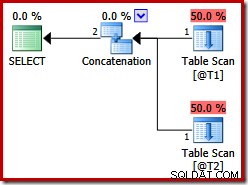
Não há concatenação de junção de mesclagem, apesar da dica de consulta:antes do SQL Server 2012, essa dica funciona apenas com UNION, não com UNION ALL. Para obter um plano com o operador de mesclagem desejado, precisamos desabilitar a implementação de um UNION ALL (UNIA) lógico usando o operador físico Concatenation (CON). Observe que o seguinte não está documentado e não é suportado para uso em produção:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT * FROM @T1 AS T1 UNION ALL SELECT * FROM @T2 AS T2 OPTION (QUERYRULEOFF UNIAtoCON);
Essa consulta produz o mesmo plano que o SQL Server 2012 e 2014 fazem apenas com a dica de consulta MERGE UNION:
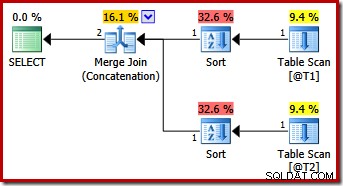
Talvez inesperadamente, o plano de execução apresenta classificações explícitas em ambas as entradas para a mesclagem. As propriedades de classificação são:
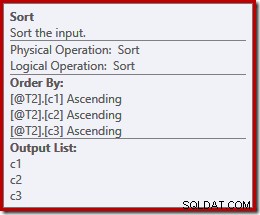
Faz sentido que uma mesclagem de preservação de ordem exija uma ordenação de entrada consistente, mas por que ela escolheu (c1, c2, c3) em vez de, digamos, (c3, c1, c2) ou (c2, c3, c1)? Como ponto de partida, as entradas de concatenação de mesclagem são classificadas na lista de projeção de saída. A estrela de seleção na consulta se expande para (c1, c2, c3) para que seja a ordem escolhida.
Classificar por lista de projeção de saída de mesclagem
Para ilustrar ainda mais o ponto, podemos expandir o select-star nós mesmos (como deveríamos!) escolhendo uma ordem diferente (c3, c2, c1) enquanto estamos nisso:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT c3, c2, c1 FROM @T1 AS T1 UNION ALL SELECT c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
As classificações agora mudam para corresponder (c3, c2, c1):
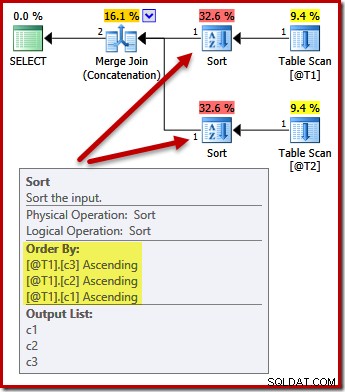
Novamente, a consulta saída order (assumindo que adicionamos alguns dados às tabelas) não é garantido para ser classificado como mostrado, porque não temos cláusula ORDER BY. Esses exemplos destinam-se simplesmente a mostrar como o otimizador seleciona uma ordem de classificação de entrada inicial, na ausência de qualquer outro motivo para classificar.
Ordens de classificação conflitantes
Agora considere o que acontece se deixarmos a lista de projeções como (c3, c2, c1) e adicionarmos um requisito para ordenar os resultados da consulta por (c1, c2, c3). As entradas para a mesclagem ainda serão classificadas (c3, c2, c1) com uma classificação pós-fusão em (c1, c2, c3) para satisfazer o ORDER BY?
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT c3, c2, c1 FROM @T1 AS T1 UNION ALL SELECT c3, c2, c1 FROM @T2 AS T2 ORDER BY c1, c2, c3 OPTION (MERGE UNION);
Não. O otimizador é inteligente o suficiente para evitar classificar duas vezes:
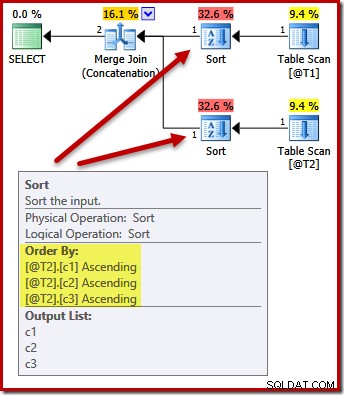
Classificar ambas as entradas em (c1, c2, c3) é perfeitamente aceitável para a concatenação de mesclagem, portanto, nenhuma classificação dupla é necessária.
Observe que este plano não garantir que a ordem dos resultados será (c1, c2, c3). O plano tem a mesma aparência dos planos anteriores sem ORDER BY, mas nem todos os detalhes internos são apresentados em planos de execução visíveis ao usuário.
O efeito da exclusividade
Ao escolher uma ordem de classificação para as entradas de mesclagem, o otimizador também é afetado por quaisquer garantias de exclusividade existentes. Considere o exemplo a seguir, com cinco colunas, mas observe as diferentes ordens de colunas na operação UNION ALL:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
O plano de execução inclui ordenações em (c5, c1, c2, c4, c3) para a tabela @T1 e (c5, c4, c3, c2, c1) para a tabela @T2:
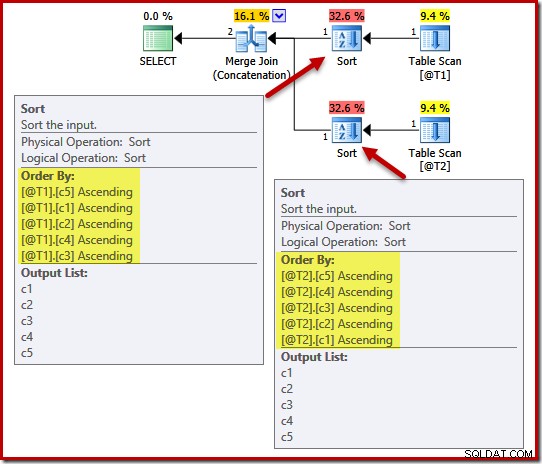
Para demonstrar o efeito da exclusividade nessas classificações, adicionaremos uma restrição UNIQUE à coluna c1 na tabela T1 e à coluna c4 na tabela T2:
DECLARE @T1 AS TABLE (c1 int UNIQUE, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int UNIQUE, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
A questão sobre exclusividade é que o otimizador sabe que pode parar de classificar assim que encontrar uma coluna que seja garantidamente exclusiva. A classificação por colunas adicionais depois que uma chave exclusiva é encontrada não afetará a ordem de classificação final, por definição.
Com as restrições UNIQUE em vigor, o otimizador pode simplificar a lista de classificação (c5, c1, c2, c4, c3) de T1 para (c5, c1) porque c1 é único. Da mesma forma, a lista de classificação (c5, c4, c3, c2, c1) para T2 é simplificada para (c5, c4) porque c4 é uma chave:
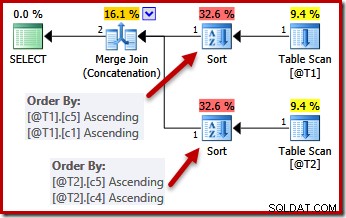
Paralelismo
A simplificação devido a uma chave única não é perfeitamente implementada. Em um plano paralelo, os fluxos são particionados para que todas as linhas da mesma instância da mesclagem terminem no mesmo thread. Esse particionamento do conjunto de dados é baseado nas colunas de mesclagem e não simplificado pela presença de uma chave.
O script a seguir usa o sinalizador de rastreamento não suportado 8649 para gerar um plano paralelo para a consulta anterior (que, caso contrário, permanece inalterado):
DECLARE @T1 AS TABLE (c1 int UNIQUE, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int UNIQUE, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION, QUERYTRACEON 8649);
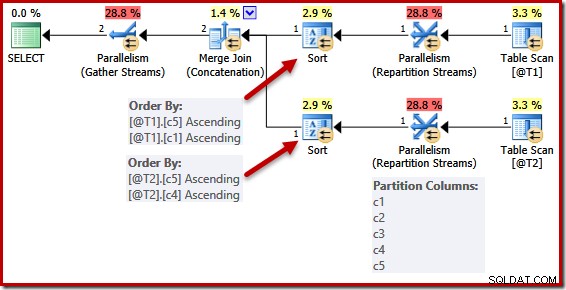
As listas de classificação são simplificadas como antes, mas os operadores Repartição de fluxos ainda particionam em todas as colunas. Se essa simplificação fosse implementada de forma consistente, os operadores de reparticionamento também operariam apenas em (c5, c1) e (c5, c4).
Problemas com índices não exclusivos
A maneira como o otimizador raciocina sobre os requisitos de classificação para concatenação de mesclagem pode resultar em problemas de classificação desnecessários, como mostra o próximo exemplo:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE CLUSTERED INDEX cx ON #T1 (c1); CREATE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1 OPTION (MERGE UNION); DROP TABLE #T1, #T2;
Observando a consulta e os índices disponíveis, esperaríamos um plano de execução que realizasse uma varredura ordenada dos índices clusterizados, usando a concatenação de junção de mesclagem para evitar a necessidade de qualquer classificação. Essa expectativa é plenamente justificada, pois os índices clusterizados fornecem a ordenação especificada na cláusula ORDER BY. Infelizmente, o plano que recebemos inclui dois tipos:
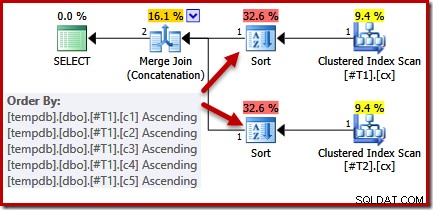
Não há uma boa razão para esses tipos, eles só aparecem porque a lógica do otimizador de consulta é imperfeita. A lista de colunas de saída de mesclagem (c1, c2, c3, c4, c5) é um superconjunto de ORDER BY, mas não há único chave para simplificar essa lista. Como resultado dessa lacuna no raciocínio do otimizador, ele conclui que a mesclagem requer sua entrada classificada em (c1, c2, c3, c4, c5).
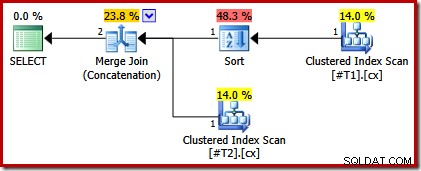
Podemos verificar essa análise modificando o script para tornar único um dos índices clusterizados:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE CLUSTERED INDEX cx ON #T1 (c1); CREATE UNIQUE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1 OPTION (MERGE UNION); DROP TABLE #T1, #T2;
O plano de execução agora tem apenas uma classificação acima da tabela com o índice não exclusivo:
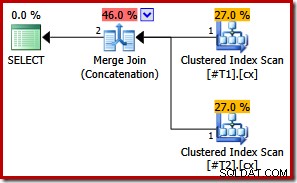
Se agora fizermos ambos índices clusterizados exclusivos, nenhuma classificação aparece:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE UNIQUE CLUSTERED INDEX cx ON #T1 (c1); CREATE UNIQUE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1; DROP TABLE #T1, #T2;
Com ambos os índices exclusivos, as listas de classificação de entrada de mesclagem inicial podem ser simplificadas apenas para a coluna c1. A lista simplificada corresponde exatamente à cláusula ORDER BY, portanto, nenhuma classificação é necessária no plano final:
Observe que nem precisamos da dica de consulta neste último exemplo para obter o plano de execução ideal.
Considerações finais
A eliminação de classificações em um plano de execução pode ser complicada. Em alguns casos, pode ser tão simples quanto modificar um índice existente (ou fornecer um novo) para entregar linhas na ordem necessária. O otimizador de consulta faz um trabalho razoável em geral quando os índices apropriados estão disponíveis.
Em (muitos) outros casos, no entanto, evitar classificações pode exigir uma compreensão muito mais profunda do mecanismo de execução, do otimizador de consulta e dos próprios operadores de plano. Evitar ordenações é, sem dúvida, um tópico avançado de ajuste de consultas, mas também incrivelmente recompensador quando tudo dá certo.