Em uma dica recente, descrevi um cenário em que uma instância do SQL Server 2016 parecia estar lutando com os tempos de checkpoint. O log de erros foi preenchido com um número alarmante de entradas do FlushCache como esta:
FlushCache: cleaned up 394031 bufs with 282252 writes in 65544 ms (avoided 21 new dirty bufs) for db 19:0
average writes per second: 4306.30 writes/sec
average throughput: 46.96 MB/sec, I/O saturation: 53644, context switches 101117
last target outstanding: 639360, avgWriteLatency 1 Fiquei um pouco perplexo com esse problema, já que o sistema certamente não era desleixado - muitos núcleos, 3 TB de memória e armazenamento XtremIO. E nenhuma dessas mensagens do FlushCache foi emparelhada com os avisos de E/S de 15 segundos no log de erros. Ainda assim, se você empilhar um monte de bancos de dados de alta transação lá, o processamento do ponto de verificação pode ficar bastante lento. Não tanto por causa da E/S direta, mas mais reconciliação que precisa ser feita com um grande número de páginas sujas (não apenas de commit transações) espalhadas por uma quantidade tão grande de memória e potencialmente aguardando o lazywriter (já que há apenas um para toda a instância).
Fiz uma leitura rápida de "refresco" de alguns posts muito valiosos:
- Como funcionam os pontos de verificação e o que é registrado
- Pontos de verificação do banco de dados (SQL Server)
- O que o checkpoint faz para tempdb?
- Um mito de DBA do SQL Server por dia:(15/30) checkpoint grava apenas páginas de transações confirmadas
- As mensagens do FlushCache podem não ser uma parada de E/S real
- Ponto de verificação indireto e tempdb – o bom, o ruim e o agendador que não rende
- Alterar o tempo de recuperação desejado de um banco de dados
- Como funciona:quando a mensagem FlushCache é adicionada ao log de erros do SQL Server?
- Mudanças no comportamento do ponto de verificação do SQL Server 2016
- Intervalo de recuperação de destino e ponto de verificação indireto - novo padrão de 60 segundos no SQL Server 2016
- SQL 2016 – Ele simplesmente roda mais rápido:padrão de ponto de verificação indireto
- SQL Server:grande RAM e checkpoint de banco de dados
Rapidamente decidi que queria rastrear as durações dos pontos de verificação para alguns desses bancos de dados mais problemáticos, antes e depois de alterar o intervalo de recuperação de destino de 0 (da maneira antiga) para 60 segundos (da nova maneira). Em janeiro, peguei emprestada uma sessão de Extended Events da amiga e colega canadense Hannah Vernon:
CREATE EVENT SESSION CheckpointTracking ON SERVER
ADD EVENT sqlserver.checkpoint_begin
(
WHERE
(
sqlserver.database_id = 19 -- db4
OR sqlserver.database_id = 78 -- db2
...
)
)
, ADD EVENT sqlserver.checkpoint_end
(
WHERE
(
sqlserver.database_id = 19 -- db4
OR sqlserver.database_id = 78 -- db2
...
)
)
ADD TARGET package0.event_file
(
SET filename = N'L:\SQL\CP\CheckPointTracking.xel',
max_file_size = 50, -- MB
max_rollover_files = 50
)
WITH
(
MAX_MEMORY = 4096 KB,
MAX_DISPATCH_LATENCY = 30 SECONDS,
TRACK_CAUSALITY = ON,
STARTUP_STATE = ON
);
GO
ALTER EVENT SESSION CheckpointTracking ON SERVER
STATE = START; Marquei a hora em que alterei cada banco de dados e analisei os resultados dos dados de eventos estendidos usando uma consulta publicada na dica original. Os resultados mostraram que, após a mudança para pontos de verificação indiretos, cada banco de dados passou de pontos de verificação com média de 30 segundos para pontos de verificação com média de menos de um décimo de segundo (e muito menos pontos de verificação na maioria dos casos também). Há muito o que descompactar neste gráfico, mas estes são os dados brutos que usei para apresentar meu argumento (clique para ampliar):
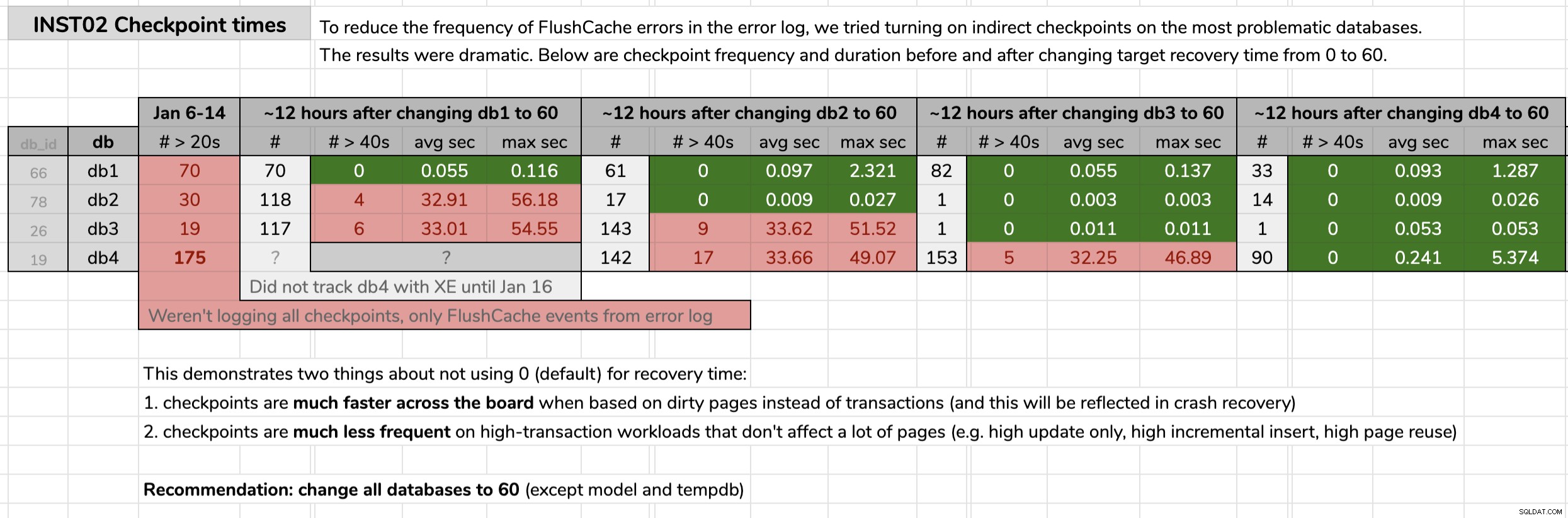 Minha evidência
Minha evidência Depois de provar meu caso nesses bancos de dados problemáticos, recebi luz verde para implementar isso em todos os nossos bancos de dados de usuários em todo o nosso ambiente. No desenvolvimento primeiro e depois na produção, executei o seguinte por meio de uma consulta CMS para obter um medidor de quantos bancos de dados estávamos falando:
DECLARE @sql nvarchar(max) = N'';
SELECT @sql += CASE
WHEN (ag.role = N'PRIMARY' AND ag.ag_status = N'READ_WRITE') OR ag.role IS NULL THEN N'
ALTER DATABASE ' + QUOTENAME(d.name) + N' SET TARGET_RECOVERY_TIME = 60 SECONDS;'
ELSE N'
PRINT N''-- fix ' + QUOTENAME(d.name) + N' on Primary.'';'
END
FROM sys.databases AS d
OUTER APPLY
(
SELECT role = s.role_desc,
ag_status = DATABASEPROPERTYEX(c.database_name, N'Updateability')
FROM sys.dm_hadr_availability_replica_states AS s
INNER JOIN sys.availability_databases_cluster AS c
ON s.group_id = c.group_id
AND d.name = c.database_name
WHERE s.is_local = 1
) AS ag
WHERE d.target_recovery_time_in_seconds <> 60
AND d.database_id > 4
AND d.[state] = 0
AND d.is_in_standby = 0
AND d.is_read_only = 0;
SELECT DatabaseCount = @@ROWCOUNT, Version = @@VERSION, cmd = @sql;
--EXEC sys.sp_executesql @sql; Algumas observações sobre a consulta:
database_id > 4
Eu não queria tocar emmasterde jeito nenhum, e eu não queria alterartempdbainda porque não estamos no SQL Server 2017 CU mais recente (consulte KB #4497928 por um motivo pelo qual esse detalhe é importante). O último excluimodel, também, porque alterar o modelo afetariatempdbno próximo failover/reinicialização. Eu poderia ter mudadomsdb, e posso voltar a fazer isso em algum momento, mas meu foco aqui era em bancos de dados de usuários.
[state] / is_read_only / is_in_standby
Precisamos ter certeza de que os bancos de dados que estamos tentando alterar estão online e não somente leitura (acertei um que estava definido como somente leitura e terei que voltar a ele mais tarde).
OUTER APPLY (...)
Queremos restringir nossas ações a bancos de dados que são primários em um AG ou não estão em um AG (e também temos que considerar AGs distribuídos, onde podemos ser primários e locais, mas ainda não ser graváveis) . Se você executar a verificação em um secundário, não poderá corrigir o problema, mas ainda deverá receber um aviso sobre isso. Obrigado a Erik Darling por ajudar com essa lógica e Taylor Martell por motivar melhorias.
- Se você tiver instâncias executando versões mais antigas como o SQL Server 2008 R2 (encontrei uma!), será necessário ajustar um pouco isso, pois o
target_recovery_time_in_secondscoluna não existe lá. Eu tive que usar SQL dinâmico para contornar isso em um caso, mas você também pode mover ou remover temporariamente onde essas instâncias se enquadram na hierarquia do CMS. Você também não pode ser preguiçoso como eu e executar o código no Powershell em vez de uma janela de consulta do CMS, onde você pode facilmente filtrar bancos de dados com qualquer número de propriedades antes de atingir problemas de tempo de compilação.
Em produção, havia 102 instâncias (cerca de metade) e 1.590 bancos de dados totais usando a configuração antiga. Tudo estava no SQL Server 2017, então por que essa configuração era tão prevalente? Porque eles foram criados antes que os pontos de verificação indiretos se tornassem o padrão no SQL Server 2016. Aqui está uma amostra dos resultados:
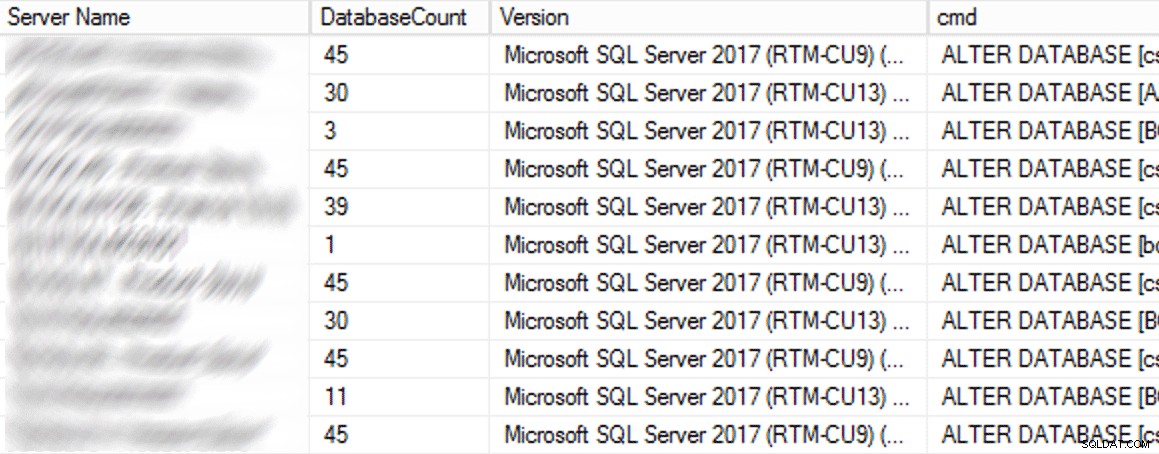 Resultados parciais da consulta do CMS.
Resultados parciais da consulta do CMS. Em seguida, executei a consulta CMS novamente, desta vez com
sys.sp_executesql sem comentários. Demorou cerca de 12 minutos para executar isso em todos os 1.590 bancos de dados. Em uma hora, eu já estava recebendo relatórios de pessoas observando uma queda significativa na CPU em algumas das instâncias mais ocupadas. Ainda tenho mais o que fazer. Por exemplo, preciso testar o possível impacto em
tempdb , e se há algum peso em nosso caso de uso nas histórias de terror que ouvi. E precisamos ter certeza de que a configuração de 60 segundos faz parte de nossa automação e de todas as solicitações de criação de banco de dados, especialmente aquelas com script ou restauradas de backups.