Você gosta de analisar strings? Nesse caso, uma das funções de string indispensáveis a serem usadas é SQL SUBSTRING. É uma daquelas habilidades que um desenvolvedor deve ter para qualquer linguagem.
Então como você faz isso?
Pontos importantes na análise de string
Suponha que você seja novo na análise. Quais pontos importantes você precisa lembrar?
- Saiba quais informações estão incorporadas na string.
- Obtenha as posições exatas de cada informação em uma string. Você pode ter que contar todos os caracteres dentro da string.
- Saiba o tamanho ou comprimento de cada informação em uma string.
- Use a função de string correta que pode extrair facilmente cada informação na string.
Conhecer todos esses fatores irá prepará-lo para usar SQL SUBSTRING() e passar argumentos para ele.
Sintaxe SQL SUBSTRING

A sintaxe de SQL SUBSTRING é a seguinte:
SUBSTRING(expressão de string, início, comprimento)
- expressão de string – um string literal ou uma expressão SQL que retorna uma string.
- iniciar – um número onde a extração começará. Também é baseado em 1 – o primeiro caractere no argumento de expressão de string deve começar com 1, não com 0. No SQL Server, é sempre um número positivo. No MySQL ou Oracle, no entanto, pode ser positivo ou negativo. Se negativo, a varredura começa no final da string.
- comprimento – o comprimento dos caracteres a serem extraídos. O SQL Server exige isso. No MySQL ou Oracle, é opcional.
4 Exemplos SQL SUBSTRING
1. Usando SQL SUBSTRING para extrair de uma string literal
Vamos começar com um exemplo simples usando uma string literal. Usamos o nome de um famoso grupo feminino coreano, BlackPink, e a Figura 1 ilustra como SUBSTRING funcionará:

O código abaixo mostra como vamos extraí-lo:
-- extract 'black' from BlackPink (English)
SELECT SUBSTRING('BlackPink',1,5) AS result
Agora, vamos também inspecionar o conjunto de resultados na Figura 2:
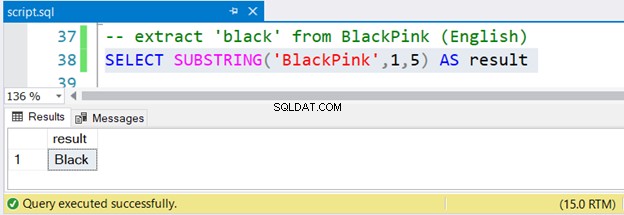
Não é fácil?
Para extrair Preto do BlackPink , você começa na posição 1 e termina na posição 5. Desde BlackPink é coreano, vamos descobrir se SUBSTRING funciona em caracteres coreanos Unicode.
(ISENÇÃO DE RESPONSABILIDADE :Eu não posso falar, ler ou escrever coreano, então peguei a tradução coreana da Wikipedia. Também usei o Google Tradutor para ver quais caracteres correspondem a Preto e Rosa . Por favor, me perdoe se estiver errado. Ainda assim, espero que o ponto que estou tentando esclarecer venha і transversalmente)
Vamos pegar a string em coreano (veja a Figura 3). Os caracteres coreanos usados são traduzidos para BlackPink:

Agora, veja o código abaixo. Extrairemos dois caracteres correspondentes a Preto .
-- extract 'black' from BlackPink (Korean)
SELECT SUBSTRING(N'블랙핑크',1,2) AS result
Você notou a string coreana precedida por N ? Ele usa caracteres Unicode e o SQL Server assume NVARCHAR e deve ser precedido por N . Essa é a única diferença na versão em inglês. Mas será que vai rodar bem? Veja a Figura 4:
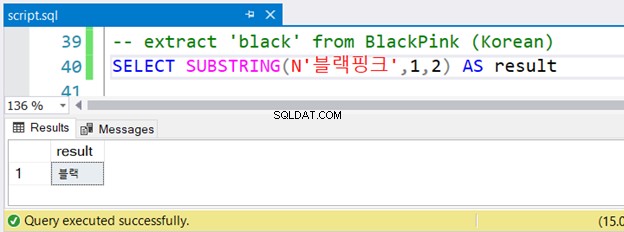
Correu sem erros.
2. Usando SQL SUBSTRING no MySQL com um argumento inicial negativo
Ter um argumento inicial negativo não funcionará no SQL Server. Mas podemos ter um exemplo disso usando o MySQL. Desta vez, vamos extrair Pink do BlackPink . Aqui está o código:
-- Extract 'Pink' from BlackPink using MySQL Substring (English)
select substring('BlackPink',-4,4) as result;
Agora, vamos ter o resultado na Figura 5:
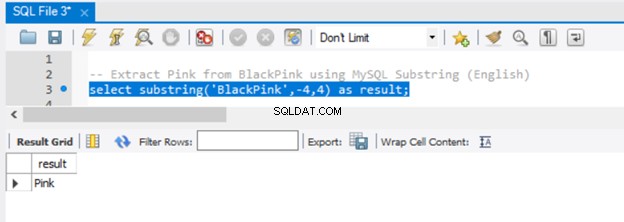
Como passamos -4 para o parâmetro start, a extração começou do final da string, retrocedendo 4 caracteres. Para obter o mesmo resultado no SQL Server, use a função RIGHT().
Caracteres Unicode também funcionam com MySQL SUBSTRING, como você pode ver na Figura 6:
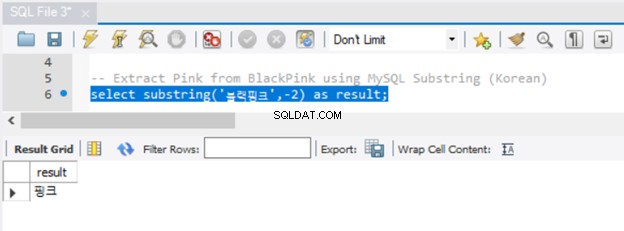
Funcionou muito bem. Mas você notou que não precisamos preceder a string com N? Além disso, observe que existem várias maneiras de obter uma substring no MySQL. Você já viu SUBSTRING. As funções equivalentes no MySQL são SUBSTR() e MID().
3. Analisando substrings com argumentos de início e comprimento variáveis
Infelizmente, nem todas as extrações de string usam argumentos fixos de início e comprimento. Nesse caso, você precisa de CHARINDEX para obter a posição de uma string que está segmentando. Vamos a um exemplo:
DECLARE @lineString NVARCHAR(30) = N'김제니 01/16/example@sqldat.com'
DECLARE @name NVARCHAR(5)
DECLARE @bday DATE
DECLARE @instagram VARCHAR(20)
SET @name = SUBSTRING(@lineString,1,CHARINDEX('@',@lineString)-11)
SET @bday = SUBSTRING(@lineString,CHARINDEX('@',@lineString)-10,10)
SET @instagram = SUBSTRING(@lineString,CHARINDEX('@',@lineString),30)
SELECT @name AS [Name], @bday AS [BirthDate], @instagram AS [InstagramAccount]
No código acima, você precisa extrair um nome em coreano, a data de nascimento e a conta do Instagram.
Começamos com a definição de três variáveis para armazenar essas informações. Depois disso, podemos analisar a string e atribuir os resultados a cada variável.
Você pode pensar que ter inícios e comprimentos fixos é mais simples. Além disso, podemos identificá-lo contando os caracteres manualmente. Mas e se você tiver muitos deles em uma mesa?
Segue nossa análise:
- O único item fixo na string é o @ personagem na conta do Instagram. Podemos obter sua posição na string usando CHARINDEX. Em seguida, usamos essa posição para obter o início e a duração do restante.
- A data de nascimento está em um formato fixo usando MM/dd/aaaa com 10 caracteres.
- Para extrair o nome, começamos em 1. Como a data de nascimento tem 10 caracteres mais o @ caractere, você pode chegar ao caractere final do nome na string. Da posição do @ personagem, voltamos 11 caracteres. A SUBSTRING(@lineString,1,CHARINDEX(‘@’,@lineString)-11) é o caminho a seguir.
- Para obter a data de nascimento, aplicamos a mesma lógica. Obtenha a posição do @ e mova 10 caracteres para trás para obter o valor inicial da data de nascimento. 10 é um comprimento fixo. SUBSTRING(@lineString,CHARINDEX(‘@’,@lineString)-10,10) é como obter a data de nascimento.
- Finalmente, obter uma conta no Instagram é simples. Comece na posição do @ caractere usando CHARINDEX. Observação:30 é o limite de nome de usuário do Instagram.
Confira os resultados na Figura 7:
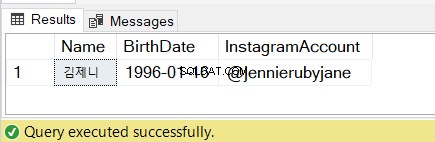
4. Usando SQL SUBSTRING em uma instrução SELECT
Você também pode usar SUBSTRING na instrução SELECT, mas primeiro precisamos ter dados de trabalho. Aqui está o código:
SELECT
CAST(P.LastName AS CHAR(50))
+ CAST(P.FirstName AS CHAR(50))
+ CAST(ISNULL(P.MiddleName,'') AS CHAR(50))
+ CAST(ea.EmailAddress AS CHAR(50))
+ CAST(a.City AS CHAR(30))
+ CAST(a.PostalCode AS CHAR(15)) AS line
INTO PersonContacts
FROM Person.Person p
INNER JOIN Person.EmailAddress ea
ON P.BusinessEntityID = ea.BusinessEntityID
INNER JOIN Person.BusinessEntityAddress bea
ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Person.Address a
ON bea.AddressID = a.AddressID
O código acima forma uma longa string contendo o nome, endereço de e-mail, cidade e código postal. Também queremos armazená-lo nos PersonContacts tabela.
Agora, vamos ter o código para fazer engenharia reversa usando SUBSTRING:
SELECT
TRIM(SUBSTRING(line,1,50)) AS [LastName]
,TRIM(SUBSTRING(line,51,50)) AS [FirstName]
,TRIM(SUBSTRING(line,101,50)) AS [MiddleName]
,TRIM(SUBSTRING(line,151,50)) AS [EmailAddress]
,TRIM(SUBSTRING(line,201,30)) AS [City]
,TRIM(SUBSTRING(line,231,15)) AS [PostalCode]
FROM PersonContacts pc
ORDER BY LastName, FirstName
Como usamos colunas de tamanho fixo, não há necessidade de usar CHARINDEX.
Usando SQL SUBSTRING em uma cláusula WHERE – uma armadilha de desempenho?
É verdade. Ninguém pode impedi-lo de usar SUBSTRING em uma cláusula WHERE. É uma sintaxe válida. Mas e se isso causar problemas de desempenho?
É por isso que provamos isso com um exemplo e depois discutimos como corrigir esse problema. Mas primeiro, vamos preparar nossos dados:
USE AdventureWorks
GO
SELECT * INTO SalesOrders FROM Sales.SalesOrderHeader soh
Não consigo estragar o SalesOrderHeader mesa, então eu joguei em outra mesa. Então, criei o SalesOrderID nos novos Pedidos de vendas tabela uma chave primária.
Agora, estamos prontos para a consulta. Estou usando o dbForge Studio para SQL Server com Modo de criação de perfil de consulta ativado para analisar as consultas.
SELECT
so.SalesOrderID
,so.OrderDate
,so.CustomerID
,so.AccountNumber
FROM SalesOrders so
WHERE SUBSTRING(so.AccountNumber,4,4) = '4030'
Como você vê, a consulta acima funciona bem. Agora, observe o diagrama do plano de perfil de consulta na Figura 8:
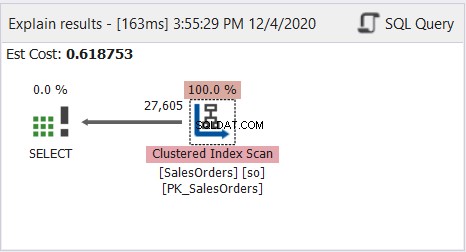
O diagrama do plano parece simples, mas vamos inspecionar as propriedades do nó Clustered Index Scan. Particularmente, precisamos das informações de tempo de execução:
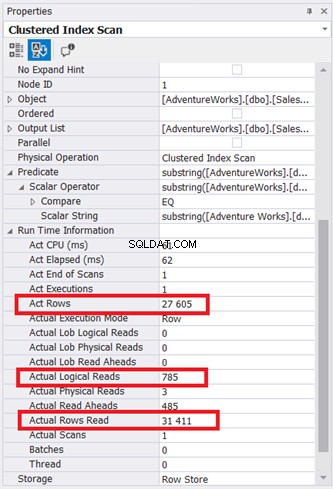
A Ilustração 9 mostra páginas de 785 * 8 KB lidas pelo mecanismo de banco de dados. Observe também que o Real Rows Read é 31.411. É o número total de linhas na tabela. No entanto, a consulta retornou apenas 27.605 linhas reais.
A tabela inteira foi lida usando o índice clusterizado como referência.
Por quê?
O problema é que o SQL Server precisa saber se 4030 é uma substring de um número de conta. Deve ler e avaliar cada registro. Descarte as linhas que não são iguais e retorne as linhas que precisamos. Ele faz o trabalho, mas não rápido o suficiente.
O que podemos fazer para torná-lo mais rápido?
Evite SUBSTRING na cláusula WHERE e obtenha o mesmo resultado mais rapidamente
O que queremos agora é obter o mesmo resultado sem usar SUBSTRING na cláusula WHERE. Siga os passos abaixo:
- Altere a tabela adicionando uma coluna calculada com um SUBSTRING(AccountNumber, 4,4) Fórmula. Vamos chamá-lo de AccountCategory por falta de um termo melhor.
- Crie um índice não agrupado para a nova AccountCategory coluna. Inclua a OrderDate , Número da conta e CustomerID colunas.
É isso.
Alteramos a cláusula WHERE da consulta para adaptar a nova AccountCategory coluna:
SET STATISTICS IO ON
SELECT
so.SalesOrderID
,so.OrderDate
,so.CustomerID
,so.AccountNumber
FROM SalesOrders so
WHERE so.AccountCategory = '4030'
SET STATISTICS IO OFF
Não há SUBSTRING na cláusula WHERE. Agora, vamos verificar o Diagrama do Plano:
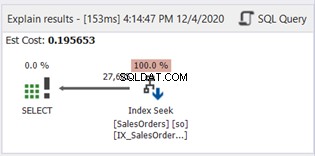
O Index Scan foi substituído pelo Index Seek. Observe também que o SQL Server usou o novo índice na coluna computada. Há também mudanças nas leituras lógicas e nas linhas reais lidas? Veja a Figura 11:
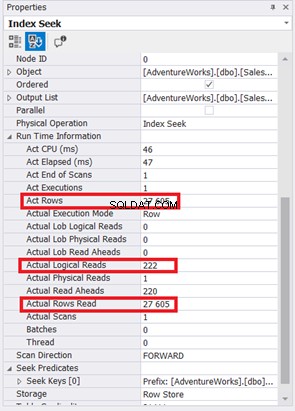
Reduzir de 785 para 222 leituras lógicas é uma grande melhoria, mais de três vezes menos que as leituras lógicas originais. Também minimizou Real Rows Read para apenas as linhas que precisamos.
Assim, usar SUBSTRING na cláusula WHERE não é bom para o desempenho e vale para qualquer outra função de valor escalar usada na cláusula WHERE.
Conclusão
- Os desenvolvedores não podem evitar analisar strings. A necessidade disso surgirá de uma forma ou de outra.
- Na análise de strings, é essencial conhecer as informações dentro da string, as posições de cada informação e seus tamanhos ou comprimentos.
- Uma das funções de análise é SQL SUBSTRING. Ele só precisa da string para analisar, a posição para iniciar a extração e o comprimento da string para extrair.
- SUBSTRING pode ter comportamentos diferentes entre os tipos de SQL, como SQL Server, MySQL e Oracle.
- Você pode usar SUBSTRING com strings literais e strings nas colunas da tabela.
- Também usamos SUBSTRING com caracteres Unicode.
- Usar SUBSTRING ou qualquer função de valor escalar na cláusula WHERE pode reduzir o desempenho da consulta. Corrija isso com uma coluna computada indexada.
Se você achar este post útil, compartilhe-o em suas plataformas de mídia social preferidas ou compartilhe seu comentário abaixo?