Suas responsabilidades como DBA (ou
DBCC CHECKDB . Você pode chegar até lá criando um plano de manutenção simples com uma "Tarefa de verificação de integridade do banco de dados" - no entanto, na minha opinião, isso é apenas marcar uma caixa de seleção. 
Se você olhar mais de perto, há muito pouco que você pode fazer para controlar como a tarefa funciona. Mesmo o painel Propriedades bastante expansivo expõe muitas configurações para o subplano de manutenção, mas praticamente nada sobre o
DBCC comandos que ele irá executar. Pessoalmente, acho que você deve adotar uma abordagem muito mais proativa e controlada de como você executa seu CHECKDB operações em ambientes de produção, criando seus próprios trabalhos e criando manualmente seu DBCC comandos. Você pode adaptar sua agenda ou os próprios comandos para diferentes bancos de dados – por exemplo, o banco de dados de associação ASP.NET provavelmente não é tão crucial quanto seu banco de dados de vendas e pode tolerar verificações menos frequentes e/ou menos completas. Mas para seus bancos de dados cruciais, pensei em montar uma postagem para detalhar algumas das coisas que investigaria para minimizar a interrupção
DBCC comandos podem causar – e de quais mitos e alarido de marketing você deve ter cuidado. E quero agradecer a Paul "Mr. DBCC" Randal (@PaulRandal) por fornecer informações valiosas – não apenas para este post específico, mas também pelos conselhos intermináveis que ele fornece em seu blog, #sqlhelp e no treinamento de imersão em SQLskills. Por favor, tome todas essas ideias com um grão de sal e faça o seu melhor para realizar testes adequados em seu ambiente – nem todas essas sugestões produzirão melhor desempenho em todos os ambientes. Mas você deve a si mesmo, seus usuários e seus stakeholders pelo menos considerar o impacto que seu
CHECKDB operações podem ter, e tomar medidas para mitigar esses efeitos sempre que possível – sem introduzir riscos desnecessários por não verificar as coisas certas. Reduza o ruído e consuma todos os erros
Não importa onde você está executando
CHECKDB , sempre use o WITH NO_INFOMSGS opção. Isso simplesmente suprime toda a saída irrelevante que apenas informa quantas linhas existem em cada tabela; se estiver interessado nessas informações, você pode obtê-las em consultas simples em DMVs e não enquanto DBCC está correndo. Suprimir a saída torna muito menos provável que você perca uma mensagem crítica enterrada em toda essa saída feliz. Da mesma forma, você deve sempre usar o
WITH ALL_ERRORMSGS opção, mas especialmente se você estiver executando o SQL Server 2008 RTM ou SQL Server 2005 (nesses casos, você poderá ver a lista de erros por objeto truncado para 200). Para qualquer CHECKDB operações que não sejam verificações ad-hoc rápidas, você deve considerar direcionar a saída para um arquivo. O Management Studio está limitado a 1.000 linhas de saída de DBCC CHECKDB , portanto, você pode perder alguns erros se exceder esse número. Embora não seja estritamente um problema de desempenho, o uso dessas opções impedirá que você execute o processo novamente. Isso é particularmente crítico se você estiver no meio da recuperação de desastres.
Descarregue as verificações lógicas sempre que possível
Na maioria dos casos,
CHECKDB passa a maior parte de seu tempo realizando verificações lógicas dos dados. Se você puder realizar essas verificações em uma cópia verdadeira dos dados, você pode concentrar seus esforços na estrutura física de seus sistemas de produção e usar o servidor secundário para lidar com todas as verificações lógicas e aliviar essa carga do primário. Por servidor secundário , quero dizer apenas o seguinte:- O local onde você testa suas restaurações completas – porque você testa suas restaurações, certo?
Outras pessoas (mais notavelmente a gigantesca força de marketing que é a Microsoft) podem ter convencido você de que outras formas de servidores secundários são adequadas para
DBCC Verificações. Por exemplo:- um secundário legível do Grupo de Disponibilidade AlwaysOn;
- um instantâneo de um banco de dados espelhado;
- um log enviado secundário;
- Espelhamento de SAN;
- ou outras variações…
Infelizmente, esse não é o caso, e nenhum desses secundários é um local válido e confiável para realizar suas verificações como alternativa ao primário. Apenas um backup um para um pode servir como uma cópia verdadeira; qualquer outra coisa que dependa de coisas como a aplicação de backups de log para obter um estado consistente não refletirá de maneira confiável os problemas de integridade no primário.
Então, em vez de tentar descarregar suas verificações lógicas para um secundário e nunca realizá-las no primário, aqui está o que sugiro:
- Certifique-se de testar com frequência as restaurações de seus backups completos. E não, isso não inclui
COPY_ONLYbackups de um secundário de AG, pelas mesmas razões acima – isso só seria válido no caso de você ter acabado de iniciar o secundário com uma restauração completa. - Execute
DBCC CHECKDBmuitas vezes contra o completo restaurar, antes de fazer qualquer outra coisa. Novamente, a repetição de registros de log neste ponto invalidará este banco de dados como uma cópia verdadeira da fonte. - Execute
DBCC CHECKDBem relação ao seu primário, talvez dividido de maneiras sugeridas por Paul Randal e/ou em uma programação menos frequente e/ou usandoPHYSICAL_ONLYMais frequentes do que não. Isso pode depender da frequência e da confiabilidade com que você está se apresentando (2). - Nunca assuma que as verificações no secundário são suficientes. Mesmo com uma réplica exata do banco de dados primário, ainda há problemas físicos que podem ocorrer no subsistema de E/S do primário que nunca se propagará para o secundário.
- Sempre analise
DBCCsaída. Apenas executá-lo e ignorá-lo, para verificá-lo em alguma lista, é tão útil quanto executar backups e alegar sucesso sem nunca testar se você pode realmente restaurar esse backup quando necessário.
Experimente com os sinalizadores de rastreamento 2549, 2562 e 2566
Eu fiz alguns testes completos de dois sinalizadores de rastreamento (2549 e 2562) e descobri que eles podem gerar melhorias substanciais de desempenho, no entanto, Lonny relata que eles não são mais necessários ou úteis. Se você estiver em 2016 ou mais recente, pule esta seção inteira . Se você estiver em uma versão mais antiga, esses dois sinalizadores de rastreamento são descritos com muito mais detalhes no KB #2634571, mas basicamente:
- Sinalizador de rastreamento 2549
- Isso otimiza o processo checkdb tratando cada arquivo de banco de dados individual como residente em um disco subjacente exclusivo. Isso pode ser usado se seu banco de dados tiver um único arquivo de dados ou se você souber que cada arquivo de banco de dados está, de fato, em uma unidade separada. Se seu banco de dados tiver vários arquivos e eles compartilharem um único eixo de conexão direta, você deve ter cuidado com esse sinalizador de rastreamento, pois pode causar mais danos do que benefícios.
IMPORTANTE :sql.sasquatch relata uma regressão neste comportamento de sinalizador de rastreamento no SQL Server 2014.
- Isso otimiza o processo checkdb tratando cada arquivo de banco de dados individual como residente em um disco subjacente exclusivo. Isso pode ser usado se seu banco de dados tiver um único arquivo de dados ou se você souber que cada arquivo de banco de dados está, de fato, em uma unidade separada. Se seu banco de dados tiver vários arquivos e eles compartilharem um único eixo de conexão direta, você deve ter cuidado com esse sinalizador de rastreamento, pois pode causar mais danos do que benefícios.
- Sinalizador de rastreamento 2562
- Este sinalizador trata todo o processo checkdb como um único lote, ao custo de maior utilização de tempdb (até 5% do tamanho do banco de dados).
- Usa um algoritmo melhor para determinar como ler páginas do banco de dados, reduzindo a contenção de travas (especificamente para
DBCC_MULTIOBJECT_SCANNER). Observe que esse aprimoramento específico está no caminho de código do SQL Server 2012, portanto, você se beneficiará dele mesmo sem o sinalizador de rastreamento. Isso pode evitar erros como:
Ocorreu tempo limite ao aguardar a trava:classe 'DBCC_MULTIOBJECT_SCANNER'.
- Os dois sinalizadores de rastreamento acima estão disponíveis nas seguintes versões:
SQL Server 2008 Service Pack 2 Atualização Cumulativa 9+
(10.00.4330 -> 10.00.5499)
SQL Server 2008 Service Pack 3 Atualização Cumulativa 4+
(10.00.5775+)
Atualização Cumulativa do SQL Server 2008 R2 RTM 11+
(10.50.1809 -> 10.50.2424)
SQL Server 2008 R2 Service Pack 1 Atualização Cumulativa 4+
(10.50.2796 -> 10.50.3999)
SQL Server 2008 R2 Service Pack 2
(10.50.4000+)
SQL Server 2012, todas as versões
(11.00.2100+)
- Sinalizador de rastreamento 2566
- Se você ainda estiver usando o SQL Server 2005, esse sinalizador de rastreamento, introduzido em 2005 SP2 CU#9 (9.00.3282) (embora não documentado no artigo da base de conhecimento da atualização cumulativa, KB #953752), tenta corrigir o baixo desempenho de
DATA_PURITYverifica em sistemas baseados em x64. Em um ponto, você pode ver mais detalhes no KB # 945770, mas parece que o artigo foi removido do site de suporte da Microsoft e da máquina WayBack. Esse sinalizador de rastreamento não deve ser necessário em versões mais modernas do SQL Server, pois o problema no processador de consultas foi corrigido.
- Se você ainda estiver usando o SQL Server 2005, esse sinalizador de rastreamento, introduzido em 2005 SP2 CU#9 (9.00.3282) (embora não documentado no artigo da base de conhecimento da atualização cumulativa, KB #953752), tenta corrigir o baixo desempenho de
Se você for usar qualquer um desses sinalizadores de rastreamento, recomendo configurá-los no nível da sessão usando
DBCC TRACEON em vez de um sinalizador de rastreamento de inicialização. Não apenas permite desativá-los sem ter que alternar o SQL Server, mas também permite implementá-los apenas ao executar determinados CHECKDB comandos, ao contrário de operações que usam qualquer tipo de reparo. Reduzir o impacto de E/S:otimizar tempdb
DBCC CHECKDB pode fazer uso pesado de tempdb, portanto, certifique-se de planejar a utilização de recursos lá. Isso geralmente é uma boa coisa a fazer em qualquer caso. Para CHECKDB você desejará alocar espaço adequadamente para tempdb; a última coisa que você quer é para CHECKDB progresso (e quaisquer outras operações simultâneas) para ter que esperar por um crescimento automático. Você pode ter uma ideia dos requisitos usando WITH ESTIMATEONLY , como Paulo explica aqui. Esteja ciente de que a estimativa pode ser bastante baixa devido a um bug no SQL Server 2008 R2. Além disso, se você estiver usando o sinalizador de rastreamento 2562, certifique-se de acomodar os requisitos de espaço adicionais. E, claro, todos os conselhos típicos para otimizar o tempdb em praticamente qualquer sistema também são apropriados aqui:certifique-se de que o tempdb esteja em seu próprio conjunto de rápido fusos, certifique-se de que está dimensionado para acomodar todas as outras atividades simultâneas sem ter que crescer, verifique se você está usando um número ideal de arquivos de dados, etc. Alguns outros recursos que você pode considerar:
- Otimizando o desempenho do tempdb (MSDN)
- Planejamento de capacidade para tempdb (MSDN)
- Um mito de DBA do SQL Server por dia:(30/12) o tempdb deve sempre ter um arquivo de dados por núcleo de processador
Reduza o impacto de E/S:controle o instantâneo
Para executar
CHECKDB , as versões modernas do SQL Server tentarão criar um instantâneo oculto de seu banco de dados na mesma unidade (ou em todas as unidades se seus arquivos de dados abrangerem várias unidades). Você não pode controlar este mecanismo, mas se quiser controlar onde CHECKDB opera, crie seu próprio instantâneo primeiro (é necessário o Enterprise Edition) em qualquer unidade que desejar e execute o DBCC comando contra o instantâneo. Em ambos os casos, você desejará executar esta operação durante um tempo de inatividade relativo, para minimizar a atividade de copiar na gravação que passará pelo instantâneo. E você não vai querer que esse agendamento entre em conflito com nenhuma operação de gravação pesada, como manutenção de índice ou ETL. Você pode ter visto sugestões para forçar
CHECKDB para executar no modo offline usando o WITH TABLOCK opção. Eu recomendo fortemente contra esta abordagem. Se seu banco de dados estiver sendo usado ativamente, escolher essa opção apenas deixará os usuários frustrados. E se o banco de dados não estiver sendo usado ativamente, você não economizará espaço em disco evitando um instantâneo, pois não haverá atividade de cópia na gravação para armazenar. Reduza o impacto de E/S:evite erros 665/1450/1452
Em alguns casos, você pode ver um dos seguintes erros:
O sistema operacional retornou o erro 1450 (existem recursos de sistema insuficientes para concluir o serviço solicitado.) para o SQL Server durante uma gravação no deslocamento 0x[…] no arquivo com identificador 0x[…]. Isso geralmente é uma condição temporária e o SQL Server continuará tentando a operação novamente. Se a condição persistir, ações imediatas devem ser tomadas para corrigi-la.
O sistema operacional retornou o erro 665 (a operação solicitada não pôde ser concluída devido a uma limitação do sistema de arquivos) no SQL Server durante uma gravação no deslocamento 0x[…] no arquivo '[arquivo]'
Existem algumas dicas aqui para reduzir o risco desses erros durante o
CHECKDB operações e reduzindo seu impacto em geral – com várias correções disponíveis, dependendo do seu sistema operacional e da versão do SQL Server:- Erros de arquivos esparsos:1450 ou 665 devido à fragmentação de arquivos:correções e soluções alternativas
- SQL Server relata erro de sistema operacional 1450 ou 1452 ou 665 (repetições)
Reduzir o impacto da CPU
DBCC CHECKDB é multithread por padrão (mas apenas na Enterprise Edition). Se o seu sistema é limitado pela CPU ou você quer apenas CHECKDB para usar menos CPU ao custo de uma execução mais longa, você pode considerar reduzir o paralelismo de duas maneiras diferentes:- Use o Resource Governor a partir de 2008, contanto que você esteja executando o Enterprise Edition. Para direcionar apenas comandos DBCC para um determinado pool de recursos ou grupo de carga de trabalho, você terá que escrever uma função de classificador que possa identificar as sessões que realizarão esse trabalho (por exemplo, um login específico ou um job_id).
- Use o sinalizador de rastreamento 2528 para desativar o paralelismo para
DBCC CHECKDB(assim comoCHECKFILEGROUPeCHECKTABLE). O sinalizador de rastreamento 2528 é descrito aqui. Claro que isso só é válido na Enterprise Edition, porque apesar do que o Books Online diz atualmente, a verdade é queCHECKDBnão fica paralelo na Standard Edition. - Enquanto o
DBCCo comando em si não suportaMAXDOP(pelo menos antes do SQL Server 2014 SP2), ele respeita a configuração globalmax degree of parallelism. Provavelmente não é algo que eu faria em produção, a menos que não tivesse outras opções, mas essa é uma maneira abrangente de controlar certosDBCCcomandos se você não puder direcioná-los mais explicitamente.
Estávamos pedindo um melhor controle sobre o número de CPUs que
DBCC CHECKDB usa, mas eles foram negados repetidamente até o SQL Server 2014 SP2. Então agora você pode adicionar WITH MAXDOP = n ao comando. Minhas descobertas
Eu queria demonstrar algumas dessas técnicas em um ambiente que eu pudesse controlar. Instalei o AdventureWorks2012 e o expandi usando o script ampliador AW escrito por Jonathan Kehayias (blog | @SQLPoolBoy), que aumentou o banco de dados para cerca de 7 GB. Então eu executei uma série de
CHECKDB comandos contra ele, e cronometrado-los. Eu usei uma baunilha simples DBCC CHECKDB por conta própria, então todos os outros comandos usaram WITH NO_INFOMSGS, ALL_ERRORMSGS . Em seguida, quatro testes com (a) nenhum sinalizador de rastreamento, (b) 2549, (c) 2562 e (d) ambos 2549 e 2562. Em seguida, repeti esses quatro testes, mas adicionei o PHYSICAL_ONLY opção, que ignora todas as verificações lógicas. Os resultados (média de mais de 10 execuções de teste) estão dizendo: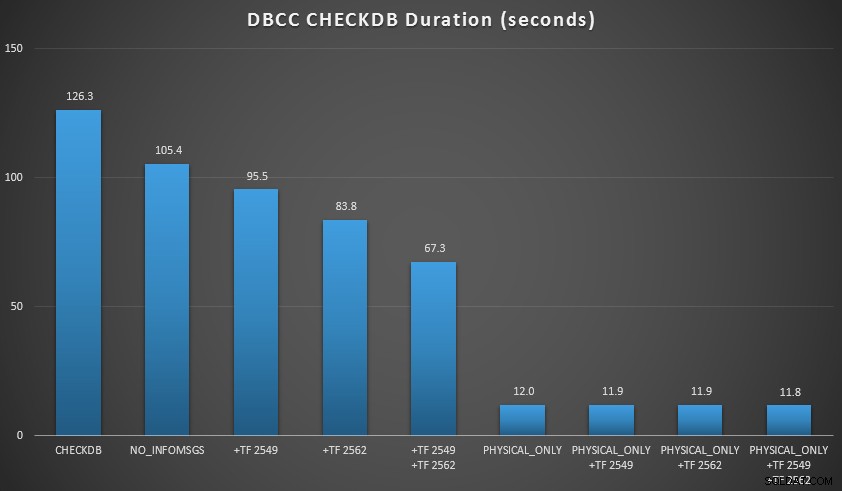
Resultados do CHECKDB em relação ao banco de dados de 7 GB
Então expandi o banco de dados um pouco mais, fazendo muitas cópias das duas tabelas ampliadas, levando a um tamanho de banco de dados ao norte de 70 GB, e executei os testes novamente. Os resultados, novamente em média em 10 execuções de teste:
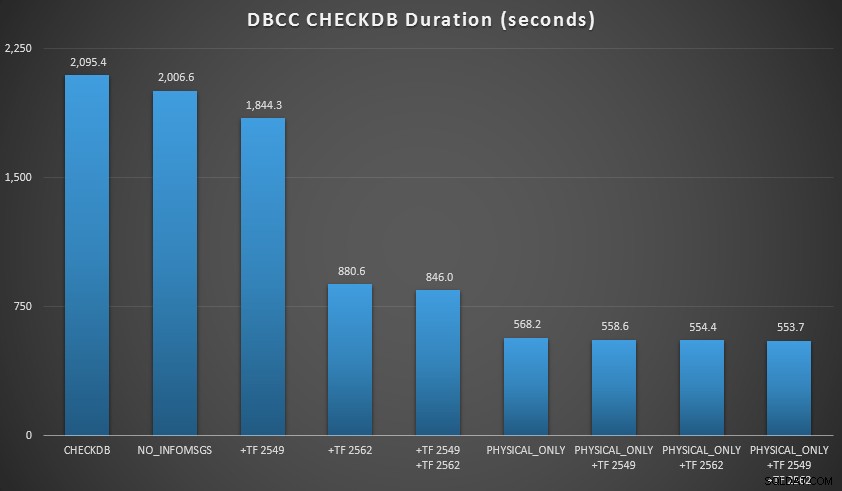
Resultados do CHECKDB em relação ao banco de dados de 70 GB
Nesses dois cenários, aprendi o seguinte (mais uma vez, tendo em mente que sua milhagem pode variar e que você precisará realizar seus próprios testes para tirar conclusões significativas):
- Quando tenho que realizar verificações lógicas:
- Em tamanhos de banco de dados pequenos, o
NO_INFOMSGSA opção pode reduzir significativamente o tempo de processamento quando as verificações são executadas no SSMS. Em bancos de dados maiores, no entanto, esse benefício diminui, pois o tempo e o trabalho gastos na transmissão das informações tornam-se uma parte insignificante da duração geral. 21 segundos de 2 minutos é substancial; 88 segundos em 35 minutos, nem tanto. - Os dois sinalizadores de rastreamento que testei tiveram um impacto significativo no desempenho, representando uma redução de tempo de execução de 40 a 60% quando ambos foram usados juntos.
- Em tamanhos de banco de dados pequenos, o
- Quando posso enviar verificações lógicas para um servidor secundário (novamente, supondo que estou realizando verificações lógicas em outro lugar em relação a uma cópia verdadeira ):
- Posso reduzir o tempo de processamento na minha instância principal em 70-90% em comparação com um
CHECKDBpadrão ligue sem opções. - No meu cenário, os sinalizadores de rastreamento tiveram muito pouco impacto na duração ao executar
PHYSICAL_ONLYcheques.
- Posso reduzir o tempo de processamento na minha instância principal em 70-90% em comparação com um
Claro, e eu não posso enfatizar isso o suficiente, esses são bancos de dados relativamente pequenos e usados apenas para que eu pudesse realizar testes repetidos e medidos em um período de tempo razoável. Este servidor tinha 80 CPUs lógicas e 128 GB de RAM, e eu era o único usuário. A duração e a interação com outras cargas de trabalho no sistema podem distorcer um pouco esses resultados. Aqui está um rápido vislumbre do uso típico da CPU, usando o SQL Sentry, durante um dos
CHECKDB operações (e nenhuma das opções realmente mudou o impacto geral na CPU, apenas a duração):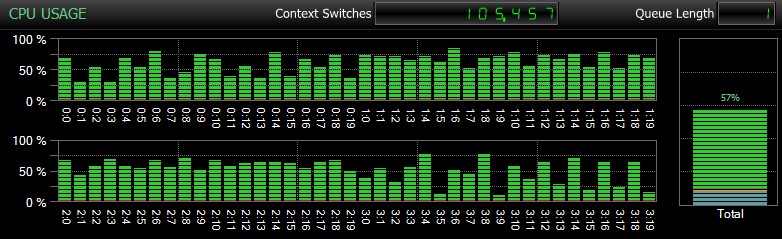
Impacto da CPU durante CHECKDB – modo de amostra
E aqui está outra visualização, mostrando perfis de CPU semelhantes para três amostras diferentes
CHECKDB operações no modo histórico (eu sobrepus uma descrição dos três testes amostrados neste intervalo):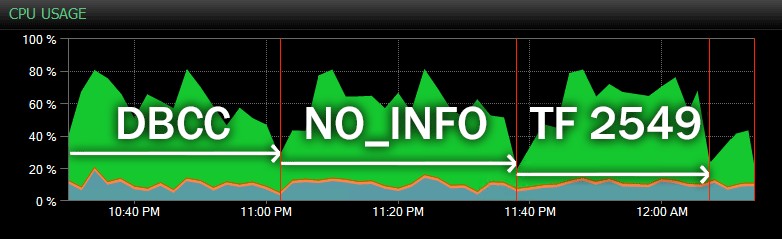
Impacto da CPU durante CHECKDB – modo histórico
Em bancos de dados ainda maiores, hospedados em servidores mais ocupados, você pode ver efeitos diferentes, e sua milhagem provavelmente varia. Portanto, faça sua devida diligência e teste essas opções e rastreie sinalizadores durante uma carga de trabalho simultânea típica antes de decidir como você deseja abordar
CHECKDB . Conclusão
DBCC CHECKDB é uma parte muito importante, mas muitas vezes subvalorizada, de sua responsabilidade como DBA ou arquiteto e crucial para a proteção dos dados de sua empresa. Não assuma essa responsabilidade de ânimo leve e faça o possível para garantir que você não sacrifique nada para reduzir o impacto em suas instâncias de produção. Mais importante:olhe além das folhas de dados de marketing para ter certeza de que você entende completamente o quão válidas são essas promessas e se você está disposto a apostar os dados da sua empresa nelas. Ignorar alguns cheques ou transferi-los para locais secundários inválidos pode ser um desastre esperando para acontecer. Você também deve considerar a leitura destes artigos PSS:
- Um CHECKDB mais rápido – Parte I
- Um CHECKDB mais rápido – Parte II
- Um CHECKDB mais rápido – Parte III
- Um CHECKDB mais rápido – Parte IV (SQL CLR UDTs)
E este post de Brent Ozar:
- 3 maneiras de executar o DBCC CHECKDB mais rapidamente
Finalmente, se você tiver uma pergunta não resolvida sobre
DBCC CHECKDB , poste-o na tag de hash #sqlhelp no twitter. Paul verifica essa etiqueta com frequência e, como sua foto deve aparecer no artigo principal do Books Online, é provável que, se alguém puder respondê-la, ele possa. Se for muito complexo para 140 caracteres, você pode perguntar aqui (e garantirei que Paul o veja em algum momento) ou postar em um site de fórum como o Database Administrators Stack Exchange.