Uma das muitas melhorias do plano de execução no SQL Server 2012 foi a adição de informações de uso e reserva de thread para planos de execução paralela. Esta postagem analisa exatamente o que esses números significam e fornece informações adicionais para entender a execução paralela.
Considere a seguinte consulta executada em uma versão ampliada do banco de dados AdventureWorks:
SELECT
BP.ProductID,
cnt = COUNT_BIG(*)
FROM dbo.bigProduct AS BP
JOIN dbo.bigTransactionHistory AS BTH
ON BTH.ProductID = BP.ProductID
GROUP BY BP.ProductID
ORDER BY BP.ProductID; O otimizador de consultas escolhe um plano de execução paralela:
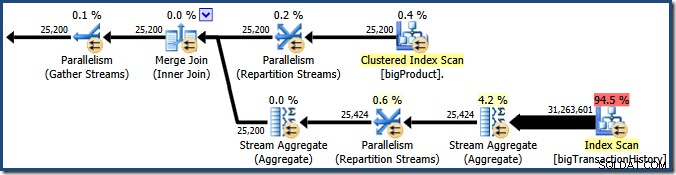
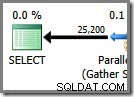
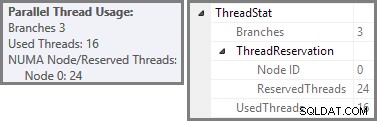
O Plan Explorer mostra detalhes de uso de encadeamento paralelo na dica de ferramenta do nó raiz. Para ver as mesmas informações no SSMS, clique no nó raiz do plano, abra a janela Propriedades e expanda o ThreadStat nó. Usando uma máquina com oito processadores lógicos disponíveis para uso do SQL Server, as informações de uso de thread de uma execução típica dessa consulta são mostradas abaixo, Plan Explorer à esquerda, exibição SSMS à direita:
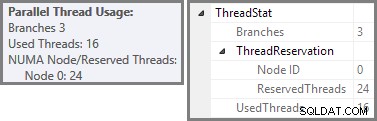
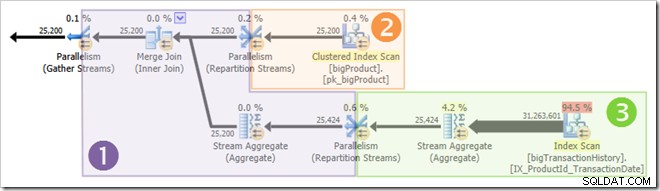
A captura de tela mostra que o mecanismo de execução reservou 24 threads para essa consulta e acabou usando 16 deles. Também mostra que o plano de consulta tem três ramificações , embora não diga exatamente o que é uma ramificação. Se você leu meu artigo do Simple Talk sobre execução de consultas paralelas, saberá que ramificações são seções de um plano de consulta paralela delimitado por operadores de troca. O diagrama abaixo desenha os limites e numera os ramos (clique para ampliar):

Ramo Dois (Laranja)
Vamos ver o branch dois com um pouco mais de detalhes primeiro:
Em um grau de paralelismo (DOP) de oito, há oito threads executando essa ramificação do plano de consulta. É importante entender que este é todo o plano de execução no que diz respeito a esses oito tópicos – eles não têm conhecimento do plano mais amplo.
Em um plano de execução serial, um único thread lê dados de uma fonte de dados, processa as linhas por meio de vários operadores de plano e retorna os resultados ao destino (que pode ser uma janela de resultados de consulta SSMS ou uma tabela de banco de dados, por exemplo).
Em uma filial de um plano de execução paralela, a situação é muito semelhante:cada thread lê os dados de uma fonte, processa as linhas por meio de vários operadores de plano e retorna os resultados ao destino. As diferenças são que o destino é um operador de troca (paralelismo) e a fonte de dados também pode ser uma troca.
Na ramificação laranja, a fonte de dados é um Clustered Index Scan e o destino é o lado direito de uma troca de Repartição Streams. O lado direito de uma troca é conhecido como lado do produtor , porque se conecta a uma ramificação que adiciona dados à troca.
Os oito encadeamentos no ramo laranja cooperam para varrer a tabela e adicionar linhas à troca. A troca monta linhas em pacotes do tamanho de uma página. Uma vez que um pacote está cheio, ele é empurrado pela exchange para o outro lado. Se a troca tiver outro pacote vazio disponível para ser preenchido, o processo continuará até que todas as linhas da fonte de dados tenham sido processadas (ou a troca ficar sem pacotes vazios).
Podemos ver o número de linhas processadas em cada thread usando a visualização Plan Tree no Plan Explorer:
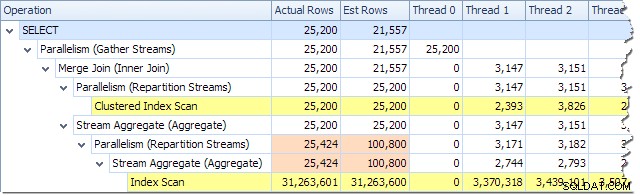
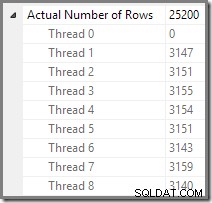
O Plan Explorer facilita a visualização de como as linhas são distribuídas entre os encadeamentos para todos as operações físicas no plano. No SSMS, você está limitado a ver a distribuição de linhas para um único operador de plano. Para fazer isso, clique em um ícone de operador, abra a janela Propriedades e expanda o nó Número real de linhas. O gráfico abaixo mostra as informações do SSMS para o nó Repartição Streams na borda entre as ramificações laranja e roxa:
Ramo Três (Verde)
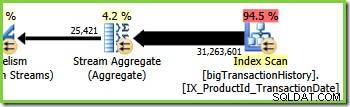
A ramificação três é semelhante à ramificação dois, mas contém um operador Stream Aggregate extra. O galho verde também tem oito fios, perfazendo um total de dezesseis vistos até agora. Os oito encadeamentos de ramificação verde leem dados de uma varredura de índice não clusterizado, executam algum tipo de agregação e passam os resultados para o lado do produtor de outra troca de fluxos de repartição.
A dica de ferramenta do Plan Explorer para o Stream Aggregate mostra que ele está agrupando por ID do produto e computando uma expressão rotulada
partialagg1005 :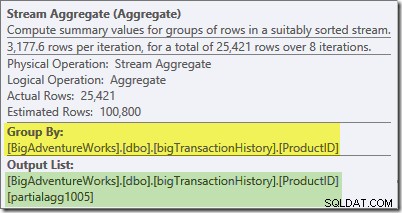
A guia Expressões mostra que a expressão é o resultado da contagem das linhas em cada grupo:

O Stream Aggregate está calculando um valor parcial (também conhecido como 'local') agregado. O qualificador parcial (ou local) significa simplesmente que cada thread calcula a agregação nas linhas que vê. As linhas do Index Scan são distribuídas entre os encadeamentos usando um esquema baseado em demanda:não há distribuição fixa de linhas antecipadamente; os threads recebem um intervalo de linhas da varredura à medida que as solicitam. Quais linhas terminam em quais threads é essencialmente aleatória porque depende de problemas de tempo e outros fatores.
Cada thread vê linhas diferentes da verificação, mas linhas com o mesmo ID do produto pode ser visto por mais de um segmento. A agregação é 'parcial' porque os subtotais de um determinado grupo de IDs de produto podem aparecer em mais de um encadeamento; é 'local' porque cada thread calcula seu resultado com base apenas nas linhas que recebe. Por exemplo, digamos que haja 1.000 linhas para o ID do produto nº 1 na tabela. Um encadeamento pode ver 432 dessas linhas, enquanto outro pode ver 568. Ambos os encadeamentos terão um parcial contagem de linhas para o ID do produto nº 1 (432 em um segmento, 568 no outro).
A agregação parcial é uma otimização de desempenho porque reduz a contagem de linhas antes do que seria possível. Na ramificação verde, a agregação antecipada resulta em menos linhas sendo montadas em pacotes e enviadas pela troca do Repartition Stream.
Ramo 1 (roxo)

O galho roxo tem mais oito fios, totalizando vinte e quatro até agora. Cada thread nesta ramificação lê linhas das duas trocas de Repartição Streams e grava linhas em uma troca de Gather Streams. Essa ramificação pode parecer complicada e desconhecida, mas está apenas lendo linhas de uma fonte de dados e enviando resultados para um destino, como qualquer outro plano de consulta.
O lado direito do plano mostra os dados sendo lidos do outro lado das duas trocas de Repartição Streams vistas nos ramos laranja e verde. Este lado (esquerdo) da bolsa é conhecido como consumidor lado, porque os threads anexados aqui estão lendo (consumindo) linhas. Os oito segmentos de ramificação roxa são consumidores de dados nas duas trocas de Repartição Streams.
O lado esquerdo da ramificação roxa mostra as linhas sendo gravadas no produtor lado de uma troca Gather Streams. Os mesmos oito tópicos (que são consumidores nas trocas do Repartition Streams) estão realizando um produtor papel aqui.
Cada thread na ramificação roxa executa todos os operadores da ramificação, assim como uma única thread executa todas as operações em um plano de execução serial. A principal diferença é que existem oito threads rodando simultaneamente, cada um trabalhando em uma linha diferente em um determinado momento, usando diferentes instâncias dos operadores do plano de consulta.
O Stream Aggregate neste branch é um global agregar. Ele combina os agregados parciais (locais) calculados no ramo verde (lembre-se do exemplo de uma contagem de 432 em um encadeamento e 568 no outro) para produzir um total combinado para cada ID de produto. A dica de ferramenta do Plan Explorer mostra a expressão de resultado global, rotulada Expr1004:
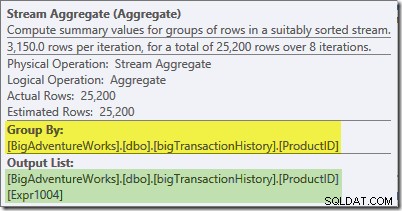
O resultado global correto por ID do produto é calculado pela soma dos agregados parciais, conforme a guia Expressões ilustra:
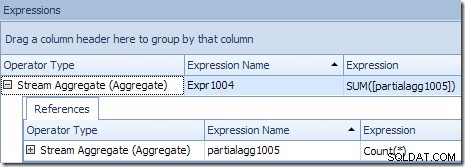
Para continuar nosso exemplo (imaginário), o resultado correto de 1.000 linhas para o ID do produto nº 1 é obtido pela soma dos dois subtotais de 432 e 568.
Cada um dos oito encadeamentos de ramificação roxa lê dados do lado do consumidor das duas trocas Gather Streams, calcula os agregados globais, executa o Merge Join no ID do produto e adiciona linhas à troca Gather Streams na extremidade esquerda da ramificação roxa. O processo central não é muito diferente de um plano serial comum; as diferenças estão em onde as linhas são lidas, para onde são enviadas e como as linhas são distribuídas entre os encadeamentos…
Distribuição de linhas de troca
O leitor alerta estará se perguntando sobre alguns detalhes neste momento. Como a ramificação roxa consegue calcular os resultados corretos por ID do produto mas o ramo verde não conseguiu (os resultados para o mesmo ID do produto foram espalhados por muitos encadeamentos)? Além disso, se houver oito junções de mesclagem separadas (uma por encadeamento), como o SQL Server garante que as linhas que serão unidas terminem na mesma instância da junção?
Ambas as perguntas podem ser respondidas observando a forma como os dois Repartição Streams trocam linhas de rota do lado do produtor (nos ramos verde e laranja) para o lado do consumidor (no ramo roxo). Vamos olhar primeiro para a troca de Repartição Streams que faz fronteira com os ramos laranja e roxo:
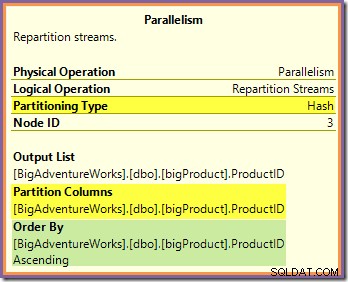
Essa troca roteia as linhas de entrada (da ramificação laranja) usando uma função de hash aplicada à coluna de ID do produto. O efeito é que todas as linhas de um ID de produto específico são garantidas para ser roteado para o mesmo fio de ramificação roxa. Os fios laranja e roxo nada sabem desse roteamento; tudo isso é tratado internamente pela bolsa.
Tudo o que os encadeamentos laranja sabem é que estão retornando linhas para o iterador pai que as solicitou (o lado do produtor da troca). Da mesma forma, todos os threads roxos 'sabem' é que estão lendo linhas de uma fonte de dados. A troca determina em qual pacote uma linha de fio laranja de entrada entrará e pode ser qualquer um dos oito pacotes candidatos. Da mesma forma, a troca determina de qual pacote ler uma linha para satisfazer uma solicitação de leitura de um encadeamento roxo.
Tenha cuidado para não adquirir uma imagem mental de um determinado fio laranja (produtor) sendo vinculado diretamente a um determinado fio roxo (consumidor). Não é assim que esse plano de consulta funciona. Um produtor de laranja pode acabam enviando linhas para todos os consumidores roxos – o roteamento depende inteiramente do valor da coluna ID do produto em cada linha processada.
Observe também que um pacote de linhas na troca só é transferido quando está cheio (ou quando o lado do produtor fica sem dados). Imagine a troca preenchendo os pacotes uma linha por vez, onde as linhas para um determinado pacote podem vir de qualquer uma das threads do lado do produtor (laranja). Uma vez que um pacote está cheio, ele é passado para o lado do consumidor, onde um segmento de consumidor específico (roxo) pode começar a lê-lo.
A troca de Repartição Streams que faz fronteira com os ramos verde e roxo funciona de maneira muito semelhante:
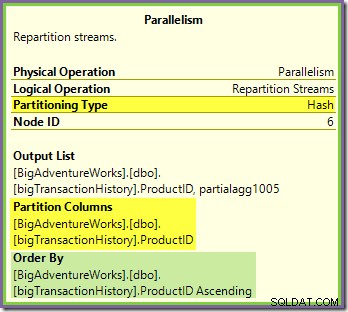
As linhas são roteadas para pacotes nesta troca usando a mesma função de hash na mesma coluna de particionamento quanto à troca laranja-púrpura vista anteriormente. Isso significa que ambos Repartição Streams troca linhas de rota com o mesmo ID de produto para o mesmo encadeamento de ramificação roxa.
Isso explica como o Stream Aggregate na ramificação roxa é capaz de calcular agregados globais – se uma linha com um ID de produto específico for vista em um encadeamento de ramificação roxa específico, esse encadeamento verá todas as linhas para esse ID de produto (e nenhuma outro fio vai).
A coluna de particionamento de troca comum também é a chave de junção para a junção de mesclagem, portanto, todas as linhas que podem se unir têm a garantia de serem processadas pelo mesmo encadeamento (roxo).
Uma última coisa a notar é que ambas as trocas estão preservando pedidos (também conhecido como 'fusão'), conforme mostrado no atributo Order By nas dicas de ferramentas. Isso atende ao requisito de junção de mesclagem de que as linhas de entrada sejam classificadas nas chaves de junção. Observe que as exchanges nunca classificam as linhas, elas podem apenas ser configuradas para preservar pedido existente.
Thread Zero
A parte final do plano de execução fica à esquerda da bolsa Gather Streams. Ele sempre é executado em um único thread - o mesmo usado para executar todo um plano serial regular. Esse thread é sempre rotulado como 'Thread 0' nos planos de execução e às vezes é chamado de thread 'coordenador' (uma designação que não acho particularmente útil).
O thread zero lê as linhas do lado do consumidor (esquerdo) da troca Gather Streams e as retorna ao cliente. Não há iteradores de encadeamento zero além da troca neste exemplo, mas se houvesse, todos eles seriam executados no mesmo encadeamento único. Observe que o Gather Streams também é uma troca de mesclagem (possui um atributo Order By):

Planos paralelos mais complexos podem incluir zonas de execução serial diferentes daquela à esquerda da troca final do Gather Streams. Essas zonas seriais não são executadas no thread zero, mas esse é um detalhe a ser explorado em outro momento.
Tópicos reservados e usados revisitados
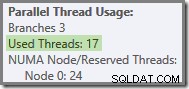
Vimos que este plano paralelo contém três ramos. Isso explica por que o SQL Server reservado 24 fios (três ramos em DOP 8). A questão é por que apenas 16 tópicos são relatados como 'usados' na captura de tela acima.
Há duas partes para a resposta. A primeira parte não se aplica a este plano, mas é importante saber de qualquer maneira. O número de ramificações informadas é o número máximo que pode ser executado simultaneamente .
Como você deve saber, certos operadores de plano estão 'bloqueando' – o que significa que eles precisam consumir todas as suas linhas de entrada antes que possam produzir a primeira linha de saída. O exemplo mais claro de um operador de bloqueio (também conhecido como stop-and-go) é Sort. Uma classificação não pode retornar a primeira linha na sequência classificada antes de ter visto todas as linhas de entrada porque a última linha de entrada pode classificar primeiro.
Operadores com várias entradas (junções e uniões, por exemplo) podem ser bloqueantes em relação a uma entrada, mas não bloqueantes ('pipelidos') em relação à outra. Um exemplo disso é a junção de hash – a entrada da compilação está bloqueando, mas a entrada do probe está em pipeline. A entrada de compilação está bloqueando porque cria a tabela de hash em relação à qual as linhas do probe são testadas.
A presença de operadores de bloqueio significa que uma ou mais ramificações paralelas podem ser garantido para ser concluído antes que outros possam começar. Onde isso ocorre, o SQL Server pode reutilizar os encadeamentos usados para processar uma ramificação concluída para uma ramificação posterior na sequência. O SQL Server é muito conservador em relação à reserva de encadeamentos, portanto, apenas ramificações garantidas para concluir antes que outro comece, use essa otimização de reserva de encadeamento. Nosso plano de consulta não contém nenhum operador de bloqueio, portanto, a contagem de ramificações relatada é apenas o número total de ramificações.
A segunda parte da resposta é que os encadeamentos ainda podem ser reutilizados se acontecer para concluir antes que um thread em outro branch seja iniciado. O número total de threads ainda é reservado neste caso, mas o uso real pode ser menor. Quantos threads um plano paralelo realmente usa depende de problemas de tempo entre outras coisas e pode variar entre as execuções.
As threads paralelas não começam a ser executadas todas ao mesmo tempo, mas novamente os detalhes disso terão que esperar por outra ocasião. Vamos examinar o plano de consulta novamente para ver como os encadeamentos podem ser reutilizados, apesar da falta de operadores de bloqueio:
É claro que os encadeamentos no ramo um não podem ser concluídos antes que os encadeamentos nos ramos dois ou três sejam iniciados, portanto, não há chance de reutilização de encadeamentos lá. A filial três também é improvável para ser concluído antes da inicialização da ramificação um ou da ramificação dois, pois há muito trabalho a fazer (quase 32 milhões de linhas para agregar).
Filial dois é uma questão diferente. O tamanho relativamente pequeno da tabela de produtos significa que há uma boa chance de que a filial possa concluir seu trabalho antes ramo três é iniciado. Se a leitura da tabela de produtos não resultar em nenhuma E/S física, não demorará muito para que oito encadeamentos leiam as 25.200 linhas e as enviem para a troca de fluxos de repartição de limite laranja-púrpura.
Isso é exatamente o que aconteceu nas execuções de teste usadas para as capturas de tela vistas até agora neste post:os oito encadeamentos do ramo laranja foram concluídos com rapidez suficiente para que pudessem ser reutilizados para o ramo verde. No total, foram utilizados dezesseis threads únicos, então é isso que o plano de execução relata.
Se a consulta for executada novamente com um cache frio, o atraso introduzido pela E/S física é suficiente para garantir que os encadeamentos de ramificação verde sejam iniciados antes que qualquer encadeamento de ramificação laranja seja concluído. Nenhum encadeamento é reutilizado, portanto, o plano de execução informa que todos os 24 encadeamentos reservados foram de fato utilizados:
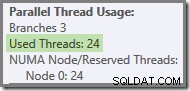
Mais geralmente, qualquer número de 'threads usados' entre os dois extremos (16 e 24 para este plano de consulta) é possível:
Por fim, observe que o encadeamento que executa a parte serial do plano à esquerda do Gather Streams final não é contado nos totais de roscas paralelas. Não é um thread extra adicionado para acomodar a execução paralela.
Considerações finais
A beleza do modelo de troca usado pelo SQL Server para implementar a execução paralela é que toda a complexidade do buffer e movimentação de linhas entre threads está oculta dentro dos operadores de troca (Paralelismo). O restante do plano é dividido em 'ramos' organizados, delimitados por trocas. Dentro de uma filial, cada operador se comporta da mesma forma que em um plano serial – em quase todos os casos, os operadores da filial não têm conhecimento de que o plano mais amplo usa execução paralela.
A chave para entender a execução paralela é (mentalmente) separar o plano paralelo nos limites da troca e imaginar cada ramificação como serial separada DOP planos, todos executando simultaneidade em um subconjunto distinto de linhas. Lembre-se, em particular, que cada plano serial executa todos os operadores nessa ramificação – o SQL Server não execute cada operador em seu próprio thread!
Compreender o comportamento mais detalhado requer um pouco de reflexão, principalmente sobre como as linhas são roteadas dentro das trocas e como o mecanismo garante resultados corretos, mas a maioria das coisas que vale a pena saber exige um pouco de reflexão, não é?