O SQL Server tradicionalmente evita fornecer soluções nativas para algumas das questões estatísticas mais comuns, como calcular uma mediana. De acordo com a WikiPedia, "mediana é descrita como o valor numérico que separa a metade superior de uma amostra, uma população ou uma distribuição de probabilidade, da metade inferior. A mediana de uma lista finita de números pode ser encontrada organizando todas as observações de valor mais baixo para o valor mais alto e escolhendo o do meio. Se houver um número par de observações, então não há um único valor médio; a mediana é geralmente definida como a média dos dois valores do meio."
Em termos de uma consulta do SQL Server, a principal coisa que você vai tirar disso é que você precisa "organizar" (classificar) todos os valores. A classificação no SQL Server geralmente é uma operação bastante cara se não houver um índice de suporte e adicionar um índice para oferecer suporte a uma operação que provavelmente não é solicitada, muitas vezes pode não valer a pena.
Vamos examinar como normalmente resolvemos esse problema em versões anteriores do SQL Server. Primeiro vamos criar uma tabela muito simples para que possamos observar que nossa lógica está correta e derivando uma mediana precisa. Podemos testar as duas tabelas a seguir, uma com número par de linhas e outra com número ímpar de linhas:
CREATE TABLE dbo.EvenRows ( id INT PRIMARY KEY, val INT );
CREATE TABLE dbo.OddRows ( id INT PRIMARY KEY, val INT );
INSERT dbo.EvenRows(id,val)
SELECT 1, 6
UNION ALL SELECT 2, 11
UNION ALL SELECT 3, 4
UNION ALL SELECT 4, 4
UNION ALL SELECT 5, 15
UNION ALL SELECT 6, 14
UNION ALL SELECT 7, 4
UNION ALL SELECT 8, 9;
INSERT dbo.OddRows(id,val)
SELECT 1, 6
UNION ALL SELECT 2, 11
UNION ALL SELECT 3, 4
UNION ALL SELECT 4, 4
UNION ALL SELECT 5, 15
UNION ALL SELECT 6, 14
UNION ALL SELECT 7, 4;
DECLARE @Median DECIMAL(12, 2); Apenas por observação casual, podemos ver que a mediana para a tabela com linhas ímpares deve ser 6 e para a tabela par deve ser 7,5 ((6+9)/2). Então agora vamos ver algumas soluções que vêm sendo utilizadas ao longo dos anos:
SQL Server 2000
No SQL Server 2000, estávamos restritos a um dialeto T-SQL muito limitado. Estou investigando essas opções para comparação porque algumas pessoas ainda estão executando o SQL Server 2000 e outras podem ter atualizado, mas, como seus cálculos de mediana foram escritos "no passado", o código ainda pode ter essa aparência hoje.
2000_A – máximo de uma metade, mínimo da outra
Essa abordagem pega o valor mais alto dos primeiros 50%, o valor mais baixo dos últimos 50% e os divide por dois. Isso funciona para linhas pares ou ímpares porque, no caso par, os dois valores são as duas linhas do meio e, no caso ímpar, os dois valores são, na verdade, da mesma linha.
SELECT @Median = (
(SELECT MAX(val) FROM
(SELECT TOP 50 PERCENT val
FROM dbo.EvenRows ORDER BY val, id) AS t)
+ (SELECT MIN(val) FROM
(SELECT TOP 50 PERCENT val
FROM dbo.EvenRows ORDER BY val DESC, id DESC) AS b)
) / 2.0; 2000_B – #tabela temporária
Este exemplo primeiro cria uma tabela #temp e, usando o mesmo tipo de matemática acima, determina as duas linhas "intermediárias" com a ajuda de uma
IDENTITY contígua coluna ordenada pela coluna val. (A ordem de atribuição de IDENTITY os valores só podem ser confiáveis por causa do MAXDOP contexto.) CREATE TABLE #x
(
i INT IDENTITY(1,1),
val DECIMAL(12, 2)
);
CREATE CLUSTERED INDEX v ON #x(val);
INSERT #x(val)
SELECT val
FROM dbo.EvenRows
ORDER BY val OPTION (MAXDOP 1);
SELECT @Median = AVG(val)
FROM #x AS x
WHERE EXISTS
(
SELECT 1
FROM #x
WHERE x.i - (SELECT MAX(i) / 2.0 FROM #x) IN (0, 0.5, 1)
);
SQL Server 2005, 2008, 2008 R2
O SQL Server 2005 introduziu algumas novas funções de janela interessantes, como
ROW_NUMBER() , que pode ajudar a resolver problemas estatísticos como mediana um pouco mais fácil do que poderíamos no SQL Server 2000. Todas essas abordagens funcionam no SQL Server 2005 e superior:2005_A – números de linha de duelo
Este exemplo usa
ROW_NUMBER() para subir e descer os valores uma vez em cada direção e, em seguida, encontra o "meio" uma ou duas linhas com base nesse cálculo. Isso é bastante semelhante ao primeiro exemplo acima, com uma sintaxe mais fácil:SELECT @Median = AVG(1.0 * val)
FROM
(
SELECT val,
ra = ROW_NUMBER() OVER (ORDER BY val, id),
rd = ROW_NUMBER() OVER (ORDER BY val DESC, id DESC)
FROM dbo.EvenRows
) AS x
WHERE ra BETWEEN rd - 1 AND rd + 1; 2005_B – número da linha + contagem
Este é bastante semelhante ao acima, usando um único cálculo de
ROW_NUMBER() e, em seguida, usando o total de COUNT() para encontrar o "meio" uma ou duas linhas:SELECT @Median = AVG(1.0 * Val)
FROM
(
SELECT val,
c = COUNT(*) OVER (),
rn = ROW_NUMBER() OVER (ORDER BY val)
FROM dbo.EvenRows
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2); 2005_C – variação no número de linhas + contagem
O colega MVP Itzik Ben-Gan me mostrou este método, que obtém a mesma resposta que os dois métodos acima, mas de uma maneira ligeiramente diferente:
SELECT @Median = AVG(1.0 * val)
FROM
(
SELECT o.val, rn = ROW_NUMBER() OVER (ORDER BY o.val), c.c
FROM dbo.EvenRows AS o
CROSS JOIN (SELECT c = COUNT(*) FROM dbo.EvenRows) AS c
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2);
SQL Server 2012
No SQL Server 2012, temos novos recursos de janelas no T-SQL que permitem que cálculos estatísticos como mediana sejam expressos de forma mais direta. Para calcular a mediana para um conjunto de valores, podemos usar
PERCENTILE_CONT() . Também podemos usar a nova extensão "paging" para o ORDER BY cláusula (OFFSET / FETCH ). 2012_A – nova funcionalidade de distribuição
Esta solução usa um cálculo muito direto usando distribuição (se você não quiser a média entre os dois valores do meio no caso de um número par de linhas).
SELECT @Median = PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY val) OVER () FROM dbo.EvenRows;
2012_B – truque de paginação
Este exemplo implementa um uso inteligente de
OFFSET / FETCH (e não exatamente aquele para o qual foi planejado) – simplesmente passamos para a linha que é um antes da metade da contagem e, em seguida, pegamos as próximas uma ou duas linhas, dependendo se a contagem foi par ou ímpar. Obrigado a Itzik Ben-Gan por apontar essa abordagem. DECLARE @c BIGINT = (SELECT COUNT(*) FROM dbo.EvenRows);
SELECT AVG(1.0 * val)
FROM (
SELECT val FROM dbo.EvenRows
ORDER BY val
OFFSET (@c - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @c % 2) ROWS ONLY
) AS x;
Mas qual tem melhor desempenho?
Verificamos que todos os métodos acima produzem os resultados esperados em nossa pequena tabela e sabemos que a versão do SQL Server 2012 tem a sintaxe mais limpa e lógica. Mas qual você deve usar em seu ambiente de produção ocupado? Podemos construir uma tabela muito maior a partir dos metadados do sistema, garantindo que tenhamos muitos valores duplicados. Este script produzirá uma tabela com 10.000.000 inteiros não exclusivos:
USE tempdb; GO CREATE TABLE dbo.obj(id INT IDENTITY(1,1), val INT); CREATE CLUSTERED INDEX x ON dbo.obj(val, id); INSERT dbo.obj(val) SELECT TOP (10000000) o.[object_id] FROM sys.all_columns AS c CROSS JOIN sys.all_objects AS o CROSS JOIN sys.all_objects AS o2 WHERE o.[object_id] > 0 ORDER BY c.[object_id];
No meu sistema, a mediana para esta tabela deve ser 146.099.561. Posso calcular isso rapidamente sem uma verificação manual de 10.000.000 de linhas usando a seguinte consulta:
SELECT val FROM
(
SELECT val, rn = ROW_NUMBER() OVER (ORDER BY val)
FROM dbo.obj
) AS x
WHERE rn IN (4999999, 5000000, 5000001); Resultados:
val rn ---- ---- 146099561 4999999 146099561 5000000 146099561 5000001
Portanto, agora podemos criar um procedimento armazenado para cada método, verificar se cada um produz a saída correta e, em seguida, medir as métricas de desempenho, como duração, CPU e leituras. Iremos realizar todas essas etapas com a tabela existente e também com uma cópia da tabela que não se beneficia do índice clusterizado (nós a descartaremos e recriaremos a tabela como um heap).
Eu criei sete procedimentos implementando os métodos de consulta acima. Para resumir, não vou listá-los aqui, mas cada um é nomeado
dbo.Median_<version> , por exemplo. dbo.Median_2000_A , dbo.Median_2000_B , etc. correspondentes às abordagens descritas acima. Se executarmos esses sete procedimentos usando o SQL Sentry Plan Explorer gratuito, aqui está o que observamos em termos de duração, CPU e leituras (observe que executamos DBCC FREEPROCCACHE e DBCC DROPCLEANBUFFERS entre as execuções):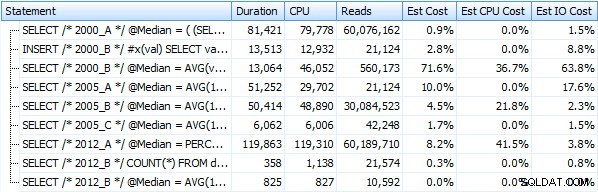
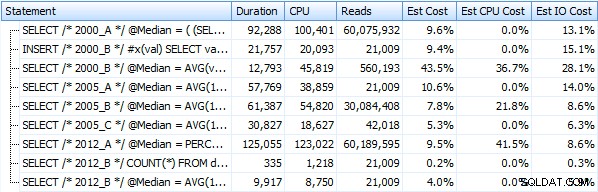
E essas métricas não mudam muito se operarmos contra um heap. A maior mudança percentual foi o método que ainda acabou sendo o mais rápido:o truque de paginação usando OFFSET / FETCH:
Aqui está uma representação gráfica dos resultados. Para deixar mais claro, destaquei o desempenho mais lento em vermelho e a abordagem mais rápida em verde.
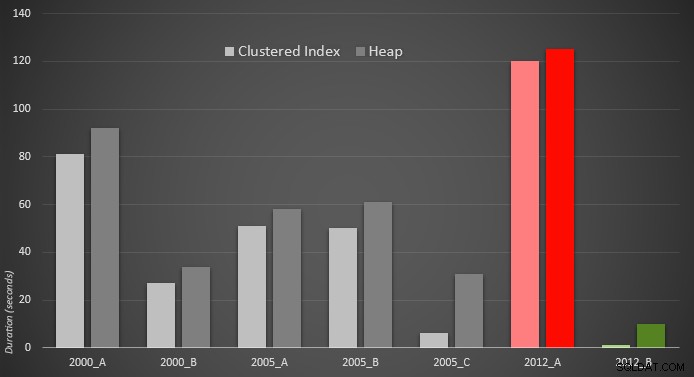
Fiquei surpreso ao ver que, em ambos os casos,
PERCENTILE_CONT() – que foi projetado para esse tipo de cálculo – é realmente pior do que todas as outras soluções anteriores. Acho que isso só serve para mostrar que, embora às vezes a sintaxe mais nova possa facilitar nossa codificação, nem sempre garante que o desempenho melhorará. Também fiquei surpreso ao ver OFFSET / FETCH provam ser tão úteis em cenários que normalmente não parecem se encaixar em seu propósito – paginação. De qualquer forma, espero ter demonstrado qual abordagem você deve usar, dependendo da sua versão do SQL Server (e que a escolha deve ser a mesma se você tem ou não um índice de suporte para o cálculo).



