Introdução
- Existem algumas regras específicas que precisam ser seguidas ao criar os objetos de banco de dados. Para melhorar o desempenho de um banco de dados, uma chave primária, índices clusterizados e não clusterizados e restrições devem ser atribuídos a uma tabela. Embora sigamos todas essas regras, linhas duplicadas ainda podem ocorrer em uma tabela.
- É sempre uma boa prática usar as chaves do banco de dados. O uso das chaves do banco de dados reduzirá as chances de obter registros duplicados em uma tabela. Mas se os registros duplicados já estiverem presentes em uma tabela, existem maneiras específicas que são usadas para remover esses registros duplicados.
Maneiras de remover linhas duplicadas
- Uso de DELETE JOIN instrução para remover linhas duplicadas
A instrução DELETE JOIN é fornecida no MySQL que ajuda a remover linhas duplicadas de uma tabela.
Considere um banco de dados com o nome "studentdb". Criaremos uma tabela student nele.
mysql> USE studentdb;
Database changed
mysql> CREATE TABLE student (Stud_ID INT, Stud_Name VARCHAR(20), Stud_City VARCHAR(20), Stud_email VARCHAR(255), Stud_Age INT);
Query OK, 0 rows affected (0.15 sec)
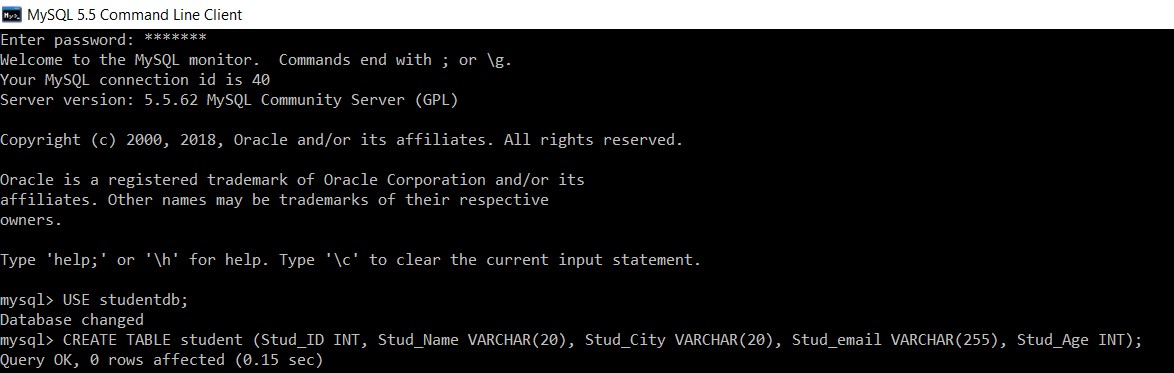
Criamos com sucesso uma tabela 'student' no banco de dados 'studentdb'.
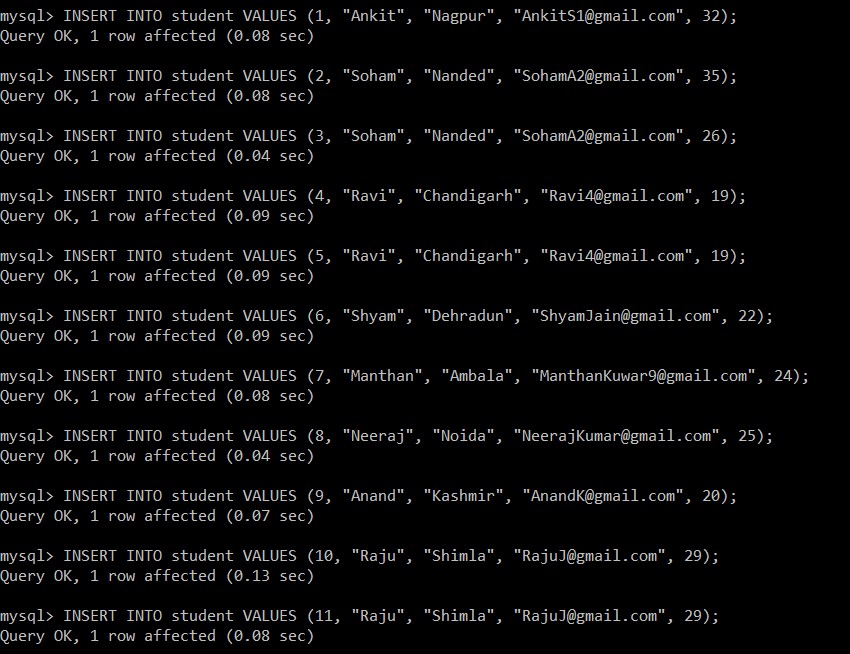
Agora, escreveremos as seguintes consultas para inserir dados na tabela de alunos.
mysql> INSERT INTO student VALUES (1, "Ankit", "Nagpur", "example@sqldat.com", 32);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (2, "Soham", "Nanded", "example@sqldat.com", 35);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (3, "Soham", "Nanded", "example@sqldat.com", 26);
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO student VALUES (4, "Ravi", "Chandigarh", "example@sqldat.com", 19);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (5, "Ravi", "Chandigarh", "example@sqldat.com", 19);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (6, "Shyam", "Dehradun", "example@sqldat.com", 22);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (7, "Manthan", "Ambala", "example@sqldat.com", 24);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (8, "Neeraj", "Noida", "example@sqldat.com", 25);
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO student VALUES (9, "Anand", "Kashmir", "example@sqldat.com", 20);
Query OK, 1 row affected (0.07 sec)
mysql> INSERT INTO student VALUES (10, "Raju", "Shimla", "example@sqldat.com", 29);
Query OK, 1 row affected (0.13 sec)
mysql> INSERT INTO student VALUES (11, "Raju", "Shimla", "example@sqldat.com", 29);
Query OK, 1 row affected (0.08 sec)
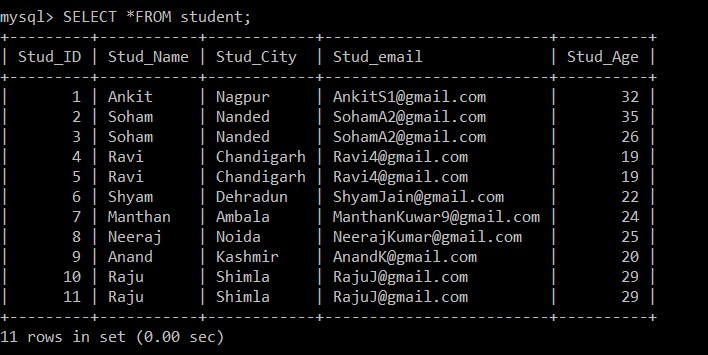
Agora, vamos recuperar todos os registros da tabela de alunos. Consideraremos esta tabela e banco de dados para todos os exemplos a seguir.
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
| 3 | Soham | Nanded | example@sqldat.com | 26 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 5 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
| 11 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
11 rows in set (0.00 sec)
Exemplo 1:
Escreva uma consulta para excluir linhas duplicadas da tabela de alunos usando o DELETE JOIN declaração.
mysql> DELETE s1 FROM student s1 INNER JOIN student s2 WHERE s1.Stud_ID < s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Usamos a consulta DELETE com INNER JOIN. Para implementar o INNER JOIN em uma única tabela, criamos duas instâncias s1 e s2. Então, com a ajuda da cláusula WHERE, verificamos duas condições para descobrir as linhas duplicadas na tabela do aluno. Se o id de e-mail em dois registros diferentes for o mesmo e o id de estudante for diferente, ele será tratado como um registro duplicado de acordo com a condição da cláusula WHERE.
Saída:
Query OK, 3 rows affected (0.20 sec)Os resultados da consulta acima mostram que existem três registros duplicados presentes na tabela do aluno.

Usaremos a consulta SELECT para encontrar os registros duplicados que foram excluídos.
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 3 | Soham | Nanded | example@sqldat.com | 26 |
| 5 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 11 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
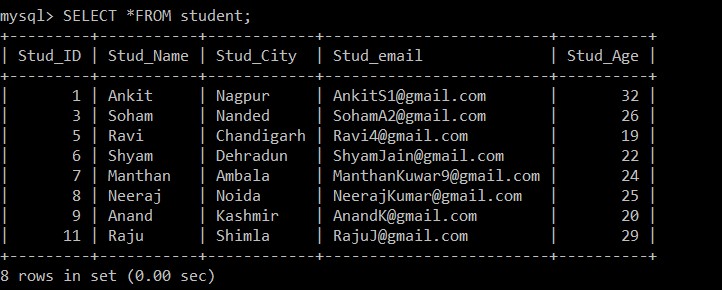
Agora, existem apenas 8 registros presentes na tabela do aluno, pois os três registros duplicados são excluídos da tabela selecionada no momento. De acordo com a seguinte condição:
s1.Stud_ID < s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Se os IDs de e-mail de quaisquer dois registros forem iguais, como o sinal de menor é usado entre o ID do aluno, apenas o registro com IDs de funcionários maiores será mantido e o outro registro duplicado será excluído entre os dois registros.
Exemplo 2:
Escreva uma consulta para excluir linhas duplicadas da tabela de alunos usando a instrução delete join, mantendo o registro duplicado com um ID de funcionário menor e excluindo o outro.
mysql> DELETE s1 FROM student s1 INNER JOIN student s2 WHERE s1.Stud_ID > s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Usamos a consulta DELETE com INNER JOIN. Para implementar o INNER JOIN em uma única tabela, criamos duas instâncias s1 e s2. Então, com a ajuda da cláusula WHERE, verificamos duas condições para descobrir as linhas duplicadas na tabela de alunos. Se o id de e-mail presente em dois registros diferentes for o mesmo e o id de estudante for diferente, será tratado como um registro duplicado de acordo com a condição da cláusula WHERE.
Saída:
Query OK, 3 rows affected (0.09 sec)Os resultados da consulta acima mostram que existem três registros duplicados presentes na tabela do aluno.

Usaremos a consulta SELECT para encontrar os registros duplicados que foram excluídos.
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
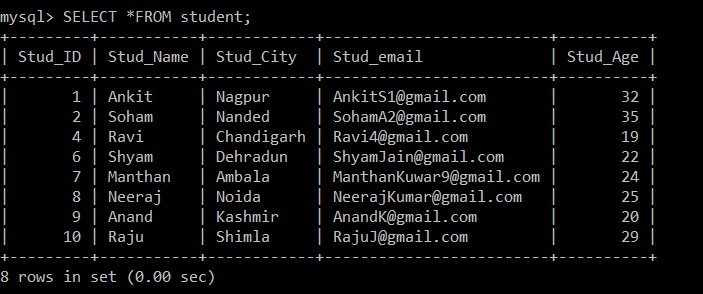
Agora, existem apenas 8 registros presentes na tabela do aluno, pois os três registros duplicados são excluídos da tabela selecionada no momento. De acordo com a seguinte condição:
s1.Stud_ID > s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Se os IDs de e-mail de quaisquer dois registros forem iguais, pois o sinal de maior é usado entre o ID do aluno, apenas o registro com o ID do funcionário menor será mantido e o outro registro duplicado será excluído entre os dois registros.
- Uso de uma tabela intermediária para remover linhas duplicadas
As etapas a seguir devem ser seguidas ao remover as linhas duplicadas com a ajuda de uma tabela intermediária.
- Uma nova tabela deve ser criada, que será igual à tabela real.
- Adicione linhas distintas da tabela real à tabela recém-criada.
- Retire a tabela real e renomeie a nova tabela com o mesmo nome de uma tabela real.
Exemplo:
Escreva uma consulta para excluir os registros duplicados da tabela de alunos usando uma tabela intermediária.
Etapa 1:
Primeiramente, criaremos uma tabela intermediária que será igual à tabela de funcionários.
mysql> CREATE TABLE temp_student LIKE student;
Query OK, 0 rows affected (0.14 sec)

Aqui, ‘employee’ é a tabela original e ‘temp_student’ é a tabela intermediária.
Etapa 2:
Agora, vamos buscar apenas os registros exclusivos da tabela de alunos e inserir todos os registros buscados na tabela temp_student.
mysql> INSERT INTO temp_student SELECT *FROM student GROUP BY Stud_email;
Query OK, 8 rows affected (0.12 sec)
Records: 8 Duplicates: 0 Warnings: 0

Aqui, antes de inserir os registros distintos da tabela de alunos em temp_student, todos os registros duplicados são filtrados por Stud_email. Então, apenas os registros com ID de e-mail exclusivo foram inseridos em temp_student.
Etapa 3:
Em seguida, removeremos a tabela de alunos e renomearemos a tabela temp_student para a tabela de alunos.
mysql> DROP TABLE student;
Query OK, 0 rows affected (0.08 sec)
mysql> ALTER TABLE temp_student RENAME TO student;
Query OK, 0 rows affected (0.08 sec)
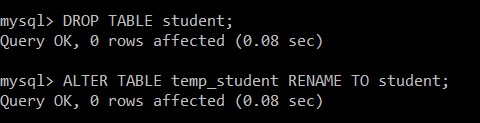
A tabela de alunos é removida com sucesso e temp_student é renomeado para a tabela de alunos, que contém apenas os registros exclusivos.
Em seguida, precisamos verificar se a tabela de alunos agora contém apenas os registros exclusivos. Para verificar isso, usamos a consulta SELECT para ver os dados contidos na tabela do aluno.
mysql> SELECT *FROM student;Saída:
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
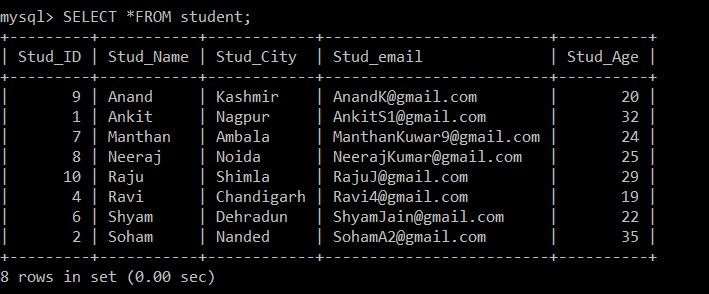
Agora, existem apenas 8 registros presentes na tabela do aluno, pois os três registros duplicados são excluídos da tabela selecionada no momento. Na etapa 2, ao buscar os registros distintos da tabela original e inseri-los em uma tabela intermediária, foi utilizada uma cláusula GROUP BY em Stud_email, para que todos os registros fossem inseridos com base nos ids de e-mail dos alunos. Aqui, apenas o registro com um ID de funcionário inferior é mantido entre os registros duplicados por padrão, e o outro é excluído.