Quando iniciamos um projeto de data warehouse, a primeira coisa que fazemos é definir as tabelas dimensionais. As tabelas dimensionais são os bits interessantes, a estrutura em torno da qual construímos nossas medições. Eles vêm em muitas formas e tamanhos. Neste artigo, vamos dar uma olhada em cada tipo de tabela dimensional.
As tabelas dimensionais fornecem contexto para os processos de negócios que desejamos medir. Eles nos dizem tudo o que precisamos saber sobre um evento. Como eles dão substância às medições (ou seja, tabelas de fatos) do sistema de data warehouse (DWH), gastamos mais tempo em sua definição e identificação do que em qualquer outro aspecto do projeto. Tabelas de fatos definir As medições; tabelas dimensionais fornecem contexto. (Para ler mais sobre tabelas de fatos, confira esses posts sobre data warehousing, esquema em estrela, esquema em floco de neve e fatos sobre tabelas de fatos).
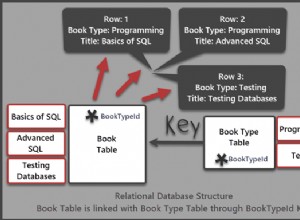
A principal característica das tabelas de dimensão é sua múltipla quantidade de atributos . Atributos são as colunas que resumimos, filtramos ou agregamos. Possuem baixa cardinalidade e geralmente são textuais e temporais. As tabelas dimensionais têm uma chave primária baseada na chave de negócios subjacente ou uma chave substituta . Essa chave primária é a base para unir a tabela de dimensões a uma ou mais tabelas de fatos.
Em comparação com as tabelas de fatos, as tabelas de dimensão são pequenas em tamanho, fáceis de armazenar e têm pouco impacto no desempenho.
Vamos agora dar uma olhada em algumas das tabelas de dimensão que você encontrará em um ambiente de data warehouse.
Uma Tabela Dimensional Comum:A Dimensão Conformada
Começaremos com um tipo básico:a dimensão conformada. Eles contêm vários atributos, que podem ser endereçados em várias tabelas de origem, mas que se referem ao mesmo domínio (cliente, contrato, negócio, etc.) Dimensões conformadas são usadas com muitos fatos e devem ser únicas para valor de grão/domínio no data warehouse.
Exemplo:
Vejamos uma tabela dimensional típica,
DIM_CUSTOMER . Definimos:
id– A chave primária da tabela de dimensões.cust_natural_key– A chave natural para o cliente.first_name– O primeiro nome do cliente.last_name– O sobrenome do cliente.address_residence– O endereço residencial do cliente.date_of_birth– A data de nascimento do cliente.marital_status– O cliente é casado? Definido como Y (sim) ou N (não).gender– O sexo do cliente, M (masculino) ou F (feminino).
Os atributos da tabela de dimensões dependem da necessidade de negócios. Podemos expandir esse tipo de tabela para armazenar informações específicas do setor (data de inadimplência, atividade etc.)
Tabelas dimensionais de mudança lenta
Com o passar do tempo, as dimensões podem mudar seus valores. Nos parágrafos a seguir, examinaremos as dimensões classificadas por como elas armazenam (ou não armazenam) dados históricos.
Digamos que você tenha uma dimensão de cliente. Alguns atributos provavelmente mudarão ao longo da vida do cliente – por exemplo, número de telefone, endereço, estado civil, etc. Esse tipo de tabela é o que Ralph Kimball chama de dimensão de mudança lenta, ou SCD.
O SCD vem em muitos tipos; oito deles são bastante comuns. Destes, você verá mais os tipos 0 a 4; os tipos 5, 6 e 7 são híbridos dos cinco primeiros. (Nota:O esquema de numeração desses SCDs começa com 0 em vez de 1.)
Os SCDs híbridos oferecem mais flexibilidade e melhor desempenho, mas ao custo da simplicidade. Usamos esses tipos de tabela quando precisamos fazer análises analíticas de atual dados com alguns históricos considerações.
SCD Tipo 0:Encher uma vez
Este é o tipo mais básico de tabela de dimensões:você a preenche uma vez e nunca preenchê-lo novamente. Considere isso como um dado referencial. Um exemplo típico disso é a dimensão de data. Não precisamos preencher esta dimensão com cada carga DWH. A tabela dimensional não muda com o tempo. Você não pode obter mais datas ou alterar datas.
A tabela de fatos se conecta aos atributos originais da dimensão.
Exemplo
Vejamos a dimensão do tempo:
A estrutura é bastante simples:
id– Chave substitutatime_date– Data realtime_day– Dia do mêstime_week– Semana do anotime_month– Mês em um anotime_year– Representação numérica de um ano
SCD Tipo 1:reescrevendo dados
Como o nome sugere, reescrevemos esse tipo de tabela dimensional a cada carga DWH. Não precisamos manter um histórico deles, mas esperamos que haja algumas mudanças.
A diferença entre um SCD Tipo 0 e um Tipo 1 não está na estrutura da tabela. Tem a ver com a atualização dos dados. Você nunca atualiza os dados em um Tipo 0, mas às vezes o faz em um Tipo 1.
Uma tabela regravável é a maneira mais simples de lidar com alterações (excluir/inserir), mas agrega pouco valor comercial. Depois de definir uma tabela de dimensões como essa, é difícil instalar o rastreamento histórico.
A tabela de fatos se conecta aos atributos atuais da dimensão.
Exemplo
Vejamos a dimensão da conta:
Sua estrutura é a seguinte:
id– A chave substituta da tabelaaccount_name– O nome da contaaccount_type– A categoria da contaaccount_activity– Sinaliza diferentes tipos de atividade
Se olharmos para os dados antes da mudança, veremos isso:
Se o tipo de conta foi alterado, os dados seriam simplesmente substituídos:
SCD Tipo 2:rastreamento de atributos históricos por linha
Esta é a forma mais comum de rastreamento histórico em um sistema DWH. As tabelas SCD Tipo 2 adicionam novas linhas para cada alteração histórica de atributos dimensionais entre Cargas DWH . Nesse tipo, definimos a chave primária como uma chave substituta porque a chave de negócios terá várias representações ao longo do tempo. Quando as linhas que contêm a alteração de dados são alteradas, definimos um novo valor para a chave substituta que corresponde ao valor na tabela de fatos. Precisamos adicionar pelo menos duas colunas,
valid_from e valid_to , para armazenar o histórico dessa maneira. A tabela de fatos se conecta aos atributos históricos da dimensão por meio da chave substituta. A agregação é feita na chave natural .
Exemplo
Vejamos a tabela de dimensões do cliente anterior, agora expandida com duas colunas de data:
Vejamos os dados:
Pontos a considerar:
- Como podemos sinalizar a linha atual,
valid_to? (Geralmente com 31.12.9999, ou NULL .) - Como podemos sinalizar a primeira linha,
valid_from? (Geralmente com 01.01.1900, ou a data da primeira inserção). - Você define uma linha inclusiva ou exclusiva? (Acima, usamos um
valid_frominclusivo e um exclusivovalid_to).
SCD Tipo 3:rastreamento de atributos históricos por coluna
Assim como no SCD Tipo 2, esse tipo adiciona algo para representar valores históricos. Nesse caso, porém, estamos adicionando novas colunas. Eles representam o valor de um atributo de linha dimensional antes de ser alterado. Normalmente, mantemos apenas a versão anterior do atributo.
Observação:este SCD raramente é usado.
A tabela de fatos se conecta aos atributos atuais e anteriores da dimensão.
Exemplo
Vejamos a dimensão do cliente, desta vez com um endereço residencial anterior:
Neste exemplo, adicionamos uma nova coluna,
previous_address_residence , para representar o endereço antigo do cliente. Se olharmos para o nosso exemplo inicial, os dados nesta tabela ficariam assim:Todas as informações históricas, exceto o endereço anterior do cliente, são perdidas.
SCD Tipo 4:Adicionando uma Minidimensão
Este tipo de cota não é baseado em alterações estruturais (Tipo 3) ou de valor (Tipo 2). Em vez disso, é baseado em alterações de design no modelo. Se nossa tabela dimensional contiver dados altamente voláteis – ou seja, dados que mudam com frequência – o tamanho da tabela dimensional aumentaria significativamente.
Para mitigar isso, extraímos os atributos voláteis em uma minidimensão . Essas minidimensões poderiam então ser agregadas ao nível relevante para o negócio. No entanto, essa agregação deve não ser confundido com agregação de fatos . O exemplo vai esclarecer isso.
A tabela de fatos se conecta aos atributos históricos da dimensão.
Exemplo
Vejamos um exemplo de um simples data mart financeiro. Suponha que você precise acompanhar o atraso de alguns clientes em seus pagamentos. Vamos chamar esse atributo de dias vencidos ou DPD. Se rastreássemos o DPD todos os dias em uma dimensão do Tipo 2, o tamanho da tabela logo explodiria além dos limites gerenciáveis. Então, extraímos o atributo e encontramos períodos de DPD relevantes para os negócios – digamos, em incrementos de 30 dias (0-30 DPD, 30-60 DPD, 60-90 DPD, etc.)
Podemos pegar outros atributos de alta volatilidade, como idade, e construir períodos relevantes para os negócios para eles também (por exemplo, 20-30 anos, 30-40 anos etc.)
Se olharmos os dados na minidimensão do cliente, teríamos algo assim:
Os atributos são:
id– Chave primária substitutaDPD_period– Dias em atrasoDEM_period– Período demográfico
O esquema em estrela simples ficaria assim:
Observe que, para fazer qualquer análise sobre os atributos de ambas as tabelas, teríamos que ligá-los através da tabela de fatos.
SCD Tipo 5:criando uma minidimensão com uma extensão regravável
Esta é a primeira de nossas construções de tabela dimensional híbrida. Em um SCD Tipo 5, adicionamos a versão atual dos dados minidimensionais à tabela dimensional. Devemos ter em mente que adicionaremos apenas o valor atual representação da minidimensão para a dimensão principal.
Recarregamos esta extensão de minidimensão com cada carga (o SCD “regravável” Tipo 1).
Embora a historização dessa extensão possa muito bem levar a problemas de tamanho, já os mitigamos com a minitabela de dimensões.
Usamos essa técnica quando queremos fazer análises diretamente nas tabelas de dimensão.
Exemplo
Expandindo o exemplo anterior com a minidimensão atual, obtemos:
O
dim_mini_customer_current tabela contém os valores de atributo mais recentes que correspondem ao dim_customer tabela. Agora podemos fazer análises específicas do cliente sem passar pela tabela de fatos (o que é muito lento). A tabela de fatos se conecta aos atributos históricos da dimensão.
Tipo 6:Dimensão tipo 2 (linha histórica) com um atributo regravável
Esta é uma construção dimensional muito comum. Adicionamos um atributo que armazena uma coisa, geralmente o último valor conhecido, que reescrevemos a cada carregamento. Isso nos permite agrupar todos os fatos por seu valor atual, enquanto o atributo histórico exibe os dados como estavam quando os eventos aconteceram.
A tabela de fatos se conecta aos valores dimensionais no momento do evento com valores dimensionais extras atuais.
Exemplo
Vamos expandir a tabela de clientes anterior com um
current_address_residence coluna. Agora temos um atributo que atualizaremos para o valor atual, usando a chave natural (
cust_natural_key ). Tipo 7:Dimensões do Tipo 2 (linha histórica) com um espelho atual
Podemos usar esse tipo somente se houver uma chave natural na dimensão da tabela. A chave não deve ser alterada durante a vida da entidade.
A ideia é simples:adicionamos uma representação atual da tabela dimensional ao esquema floco de neve. Em seguida, inserimos a chave natural da nova dimensão na tabela de fatos. (A chave substituta da dimensão histórica ainda está presente.)
A tabela de fatos se conecta aos valores dimensionais no momento do evento e aos valores dimensionais atuais.
Exemplo
Vejamos nosso esquema em estrela da conta do cliente. Adicionamos a nova dimensão,
dim_current_customer , para a tabela de fatos. Esta tabela é conectada à tabela de fatos por meio de uma chave natural, cust_natural_key . Essa construção nos permite fazer consultas analíticas no esquema em estrela com os valores atuais e históricos dos atributos do cliente.
Dimensões do domínio
Uma dimensão de domínio é uma forma simples de tabela dimensional. Ele contém informações sobre o domínio da medida subjacente de um atributo dimensional. Essas tabelas armazenam vários códigos e valores explicativos.
Exemplo
Um exemplo simples seria uma tabela de moedas.
Nesta tabela, armazenamos informações descritivas sobre várias unidades monetárias.
Na minha opinião pessoal, o melhor uso da dimensão do domínio está na documentação dos valores dos dados que encontramos no sistema DWH.
Dimensões do lixo
Os sistemas de origem transacional geram muitos indicadores e sinalizadores. Esses atributos podem ser considerados dados categóricos, mas não são relevantes para os negócios ou autoexplicativos. Podemos arquivar todos esses indicadores e sinalizadores em uma tabela dimensional chamada dimensão lixo . A dimensão lixo é a alternativa ao uso de dimensões degeneradas. Se não quisermos sobrecarregar a tabela de fatos com muitas dimensões degeneradas, criamos uma dimensão de lixo.
Devemos observar que não preenchemos todas as combinações possíveis de indicadores e sinalizadores. Apenas preenchemos os que existem no sistema de origem.
Exemplo
As tabelas de dimensões são os esqueletos do mundo do data warehouse:tudo é construído em torno delas. Eles não são tão grandes quanto as tabelas de fatos, mas sua estrutura pode ser mais complexa.
Você pode montar muitos tipos de tabelas de dimensão, mesmo além das que acabamos de discutir. E quanto ao seu negócio e indústria? Se você combinou tipos de tabelas dimensionais em algo novo, conte-nos sobre isso!