A IRI agora também oferece funções de pesquisa difusa, tanto em seu banco de dados gratuito quanto em ferramentas de criação de perfil de arquivo simples, e como bibliotecas de funções de campo disponíveis em IRI CoSort, FieldShield e Voracity para aumentar a qualidade dos dados, a segurança e os recursos de MDM. Este é o primeiro de uma série de artigos sobre soluções de pesquisa difusa IRI que abordam sua aplicação para melhorar a qualidade dos dados.
Introdução
A veracidade ou confiabilidade dos dados de uma das grandes palavras 'V' (junto com volume, variedade, velocidade e valor) sobre as quais IRI et al falam no contexto de gerenciamento de dados e informações corporativas. Geralmente, o IRI define dados em dúvida como tendo um ou mais destes atributos:
- Baixa qualidade, porque é inconsistente, impreciso ou incompleto
- Ambíguo (pense em MDM), impreciso (não estruturado) ou enganoso (mídia social)
- Preconceituoso (pergunta da pesquisa), barulhento (supérfluo ou contaminado) ou anormal (outliers)
- Inválido por qualquer outro motivo (os dados estão corretos e precisos para o uso pretendido?)
- Inseguro – contém PII ou segredos e está devidamente mascarado, reversível, etc.?
Este artigo se concentra apenas em novas soluções de busca difusa para o primeiro problema, qualidade de dados. Outros artigos neste blog discutem como o software IRI aborda os outros quatro problemas de veracidade; peça ajuda para encontrá-los se não puder.
Sobre a pesquisa difusa
As pesquisas difusas encontram palavras ou frases (valores) semelhantes, mas não necessariamente idênticas, a outras palavras ou frases (valores). Esse tipo de pesquisa tem muitos usos, como encontrar erros de sequência, erros de ortografia, caracteres transpostos e outros que abordaremos mais adiante.
Fazer uma pesquisa difusa por palavras ou frases aproximadas pode ajudar a encontrar dados que podem ser duplicatas de dados armazenados anteriormente. No entanto, a entrada do usuário ou a correção automática podem ter alterado os dados de alguma forma para que os registros pareçam independentes.
O restante do artigo abordará quatro funções de pesquisa difusa que a IRI agora suporta, como usá-las para vasculhar seus dados e retornar esses registros aproximando o valor da pesquisa.
1. Levenshtein
O algoritmo Levenshtein funciona pegando duas palavras ou frases e contando quantas etapas de edição serão necessárias para transformar uma palavra ou frase em outra. Quanto menos passos forem necessários, maior a probabilidade de a palavra ou frase corresponder. As etapas que a função Levenshtein pode seguir são:
- Inserção de um caractere na palavra ou frase
- Exclusão de um caractere da palavra ou frase
- Substituição de um caractere em uma palavra ou frase por outro
Veja a seguir um programa CoSort SortCL (script de trabalho) que demonstra como usar a função de pesquisa difusa Levenshtein:
/INFILE=LevenshteinSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=LevenshteinOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(FS_RESULT=fs_levenshtein(NAME, "Barney Oakley"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE FS_RESULT GT 50
Existem duas partes que devem ser usadas para produzir a saída desejada.
FS_Result=fs_levenshtein(NAME, "Barney Oakley")
Essa linha chama a função fs_levenshtein e armazena o resultado no campo FS_RESULT. A função recebe dois parâmetros de entrada:
- O campo para executar a pesquisa difusa (NAME em nosso exemplo)
- A string com a qual o campo de entrada será comparado ("Barney Oakley" em nosso exemplo).
/INCLUDE WHERE FS_RESULT GT 50
Esta linha compara o campo FS_RESULT e verifica se é maior que 50, então somente registros com um FS_RESULT maior que 50 são gerados. O seguinte mostra a saída do nosso exemplo.

Como a saída mostra, esse tipo de pesquisa é útil para encontrar:
- Nomes concatenados
- Ruído
- Erros de ortografia
- Caracteres transpostos
- Erros de transcrição
- Erros de digitação
A função Levenshtein também é útil para identificar erros comuns de entrada de dados. No entanto, é o que leva mais tempo para executar dos quatro algoritmos, pois compara todos os caracteres de uma string com todos os caracteres da outra.
2. Coeficiente de dados
O coeficiente de dados, ou algoritmo de dados, divide palavras ou frases em pares de caracteres, compara esses pares e conta as correspondências. Quanto mais correspondências as palavras tiverem, maior a probabilidade de a palavra em si ser uma correspondência.
O script SortCL a seguir demonstra a função de pesquisa difusa do coeficiente de dados.
/INFILE=DiceSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=DiceOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(FS_RESULT=fs_dice(NAME, "Robert Thomas Smith"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE FS_RESULT GT 50
Há duas partes que devem ser usadas para nos fornecer a saída desejada.
FS_Result=fs_dice(NAME, "Robert Thomas Smith")
Essa linha chama a função fs_dice e armazena o resultado no campo FS_RESULT. A função recebe dois parâmetros de entrada:
- O campo para executar a pesquisa difusa (NAME em nosso exemplo).
- A String com a qual o campo de entrada será comparado (“Robert Thomas Smith” em nosso exemplo).
/INCLUDE WHERE FS_RESULT GT 50
Esta linha compara o campo FS_RESULT e verifica se é maior que 50, então somente registros com um FS_RESULT maior que 50 são gerados. O seguinte mostra a saída do nosso exemplo.
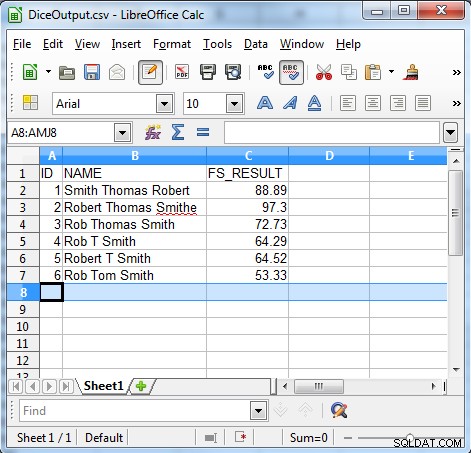
Como a saída mostra, o algoritmo do coeficiente de dados é útil para encontrar dados inconsistentes, como:
- Erros de sequência
- Correções involuntárias
- Apelidos
- Iniciais e apelidos
- Uso imprevisível de iniciais
- Localização
O algoritmo de dados é mais rápido que o Levenshtein, mas pode se tornar menos preciso quando há muitos erros simples, como erros de digitação.
3. Metafone e 4. Soundex
os algoritmos Metaphone e Soundex comparam palavras ou frases com base em seus sons fonéticos. O Soundex faz isso lendo a palavra ou frase e analisando caracteres individuais, enquanto o Metaphone analisa caracteres individuais e grupos de caracteres. Em seguida, ambos fornecem códigos com base na ortografia e na pronúncia da palavra.
O script SortCL a seguir demonstra as funções de pesquisa Soundex e Metasphone:
/INFILE=SoundexSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=SoundexOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(SE_RESULT=fs_soundex(NAME, "John"), POSITION=3, SEPARATOR=",") /FIELD=(MP_RESULT=fs_metaphone(NAME, "John"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE (SE_RESULT GT 0) OR (MP_RESULT GT 0)
Em cada caso, existem três partes que devem ser usadas para nos dar a saída desejada.
SE_RESULT=fs_soundex(NAME, "John") MP_RESULT=fs_metaphone(NAME, "John")
A linha chama a função e armazena o resultado no campo RESULT. As funções usam dois parâmetros de entrada:
- O campo para executar a pesquisa difusa (NAME em nosso exemplo)
- O xstring com o qual o campo de entrada será comparado ("John" em nosso exemplo)
/INCLUDE WHERE (SE_RESULT GT 0) OR (MP_RESULT GT 0)
Essa linha compara os campos SE_RESULT e MP_RESULT e verifica e retorna a linha se um deles for maior que 0.
Soundex retorna 100 para uma correspondência ou 0 se não for uma correspondência. Metaphone tem resultados mais específicos e retorna 100 para uma correspondência forte, 66 para uma correspondência normal e 33 para uma correspondência menor.
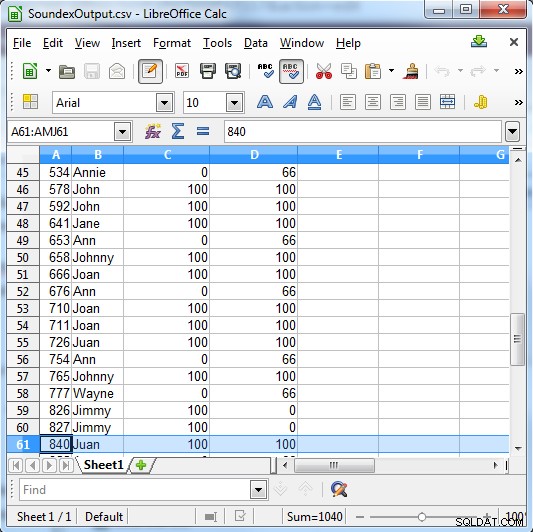
Coluna C mostra os resultados do Soundex. Ccoluna D mostra os resultados do Metaphone
Como a saída mostra, esse tipo de pesquisa é útil para encontrar:
- Erros fonéticos
Envie comentários sobre este artigo abaixo e, se estiver interessado em usar essas funções, entre em contato com seu representante IRI. Consulte nosso próximo artigo sobre como usar esses algoritmos no assistente de consolidação de dados (qualidade) do IRI Workbench.



