O DBA MySQL típico pode estar familiarizado trabalhando e gerenciando um banco de dados OLTP (Online Transaction Processing) como parte de sua rotina diária. Você pode estar familiarizado com o funcionamento e como gerenciar operações complexas. Embora o mecanismo de armazenamento padrão fornecido pelo MySQL seja bom o suficiente para OLAP (Processamento Analítico Online), é bastante simplista, especialmente aqueles que gostariam de aprender inteligência artificial ou que lidam com previsão, mineração de dados, análise de dados.
Neste blog, vamos discutir o MariaDB ColumnStore. O conteúdo será adaptado para o benefício do MySQL DBA que pode ter menos entendimento com o ColumnStore e como ele pode ser aplicável para aplicativos OLAP (Online Analytical Processing).
OLTP x OLAP
OLTP
Recursos relacionados Analytics com MariaDB AX - o armazenamento de dados colunar de código aberto Uma introdução aos bancos de dados de série temporal Cargas de trabalho de banco de dados OLTP/Analytics híbridos no cluster Galera usando escravos assíncronosA atividade típica do MySQL DBA para lidar com esse tipo de dados é usando OLTP (Online Transaction Processing). O OLTP é caracterizado por grandes transações de banco de dados fazendo inserções, atualizações ou exclusões. Os bancos de dados do tipo OLTP são especializados para processamento rápido de consultas e manutenção da integridade dos dados ao serem acessados em vários ambientes. Sua eficácia é medida pelo número de transações por segundo (tps). É bastante comum que as tabelas de relacionamento pai-filho (após a implementação do formulário de normalização) reduzam dados redundantes em uma tabela.
Os registros em uma tabela geralmente são processados e armazenados sequencialmente de maneira orientada a linhas e são altamente indexados com chaves exclusivas para otimizar a recuperação ou gravação de dados. Isso também é comum para o MySQL, especialmente ao lidar com grandes inserções ou altas gravações simultâneas ou inserções em massa. A maioria dos mecanismos de armazenamento suportados pelo MariaDB são aplicáveis a aplicativos OLTP - InnoDB (o mecanismo de armazenamento padrão desde 10.2), XtraDB, TokuDB, MyRocks ou MyISAM/Aria.
Aplicativos como CMS, FinTech, Web Apps geralmente lidam com gravações e leituras pesadas e geralmente exigem alto rendimento. Para que esses aplicativos funcionem, muitas vezes é necessário um profundo conhecimento em alta disponibilidade, redundância, resiliência e recuperação.
OLAP
O OLAP lida com os mesmos desafios que o OLTP, mas usa uma abordagem diferente (especialmente ao lidar com a recuperação de dados). O OLAP lida com conjuntos de dados maiores e é comum para armazenamento de dados, geralmente usado para aplicativos do tipo business intelligence. É comumente usado para Gerenciamento de Desempenho de Negócios, Planejamento, Orçamento, Previsão, Relatórios Financeiros, Análise, Modelos de Simulação, Descoberta de Conhecimento e Relatórios de Data Warehouse.
Os dados armazenados no OLAP normalmente não são tão críticos quanto os armazenados no OLTP. Isso ocorre porque a maioria dos dados pode ser simulada vindo do OLTP e, em seguida, pode ser alimentada em seu banco de dados OLAP. Esses dados geralmente são usados para carregamento em massa, geralmente necessários para análises de negócios que eventualmente são renderizadas em gráficos visuais. O OLAP também realiza análises multidimensionais de dados de negócios e fornece resultados que podem ser usados para cálculos complexos, análise de tendências ou modelagem de dados sofisticada.
O OLAP geralmente armazena dados de forma persistente usando um formato colunar. No MariaDB ColumnStore, no entanto, os registros são divididos com base em suas colunas e são armazenados separadamente em um arquivo. Dessa forma, a recuperação de dados é muito eficiente, pois verifica apenas a coluna relevante referida em sua consulta de instrução SELECT.
Pense assim, o processamento OLTP lida com suas transações de dados diárias e cruciais que executam seu aplicativo de negócios, enquanto o OLAP ajuda você a gerenciar, prever, analisar e comercializar melhor seu produto - os blocos de construção de um aplicativo de negócios.
O que é MariaDB ColumnStore?
MariaDB ColumnStore é um mecanismo de armazenamento colunar conectável que é executado no MariaDB Server. Ele utiliza uma arquitetura paralela de dados distribuídos, mantendo a mesma interface ANSI SQL que é usada em todo o portfólio de servidores MariaDB. Esse mecanismo de armazenamento existe há algum tempo, pois foi originalmente portado do InfiniDB (um código agora extinto que ainda está disponível no github.) Ele foi projetado para dimensionamento de big data (para processar petabytes de dados), escalabilidade linear e real -tempo de resposta a consultas de análise. Ele aproveita os benefícios de E/S do armazenamento colunar; compactação, projeção just-in-time e particionamento horizontal e vertical para oferecer um excelente desempenho ao analisar grandes conjuntos de dados.
Por fim, MariaDB ColumnStore é a espinha dorsal de seu produto MariaDB AX como o principal mecanismo de armazenamento usado por essa tecnologia.
Como o MariaDB ColumnStore é diferente do InnoDB?
O InnoDB é aplicável para processamento OLTP que exige que seu aplicativo responda da maneira mais rápida possível. É útil se sua aplicação estiver lidando com essa natureza. Por outro lado, MariaDB ColumnStore é uma escolha adequada para gerenciar transações de big data ou grandes conjuntos de dados que envolvem junções complexas, agregação em diferentes níveis de hierarquia de dimensão, projetar um total financeiro para uma ampla faixa de anos ou usar seleções de igualdade e intervalo . Essas abordagens usando ColumnStore não exigem que você indexe esses campos, pois pode ser executado com bastante rapidez. O InnoDB não pode realmente lidar com esse tipo de desempenho, embora não haja impedimento de tentar isso, como é possível com o InnoDB, mas a um custo. Isso requer que você adicione índices, o que adiciona grandes quantidades de dados ao armazenamento em disco. Isso significa que pode levar mais tempo para concluir sua consulta e pode não terminar se estiver preso em um loop de tempo.
Arquitetura do MariaDB ColumnStore
Vejamos a arquitetura MariaDB ColumStore abaixo:
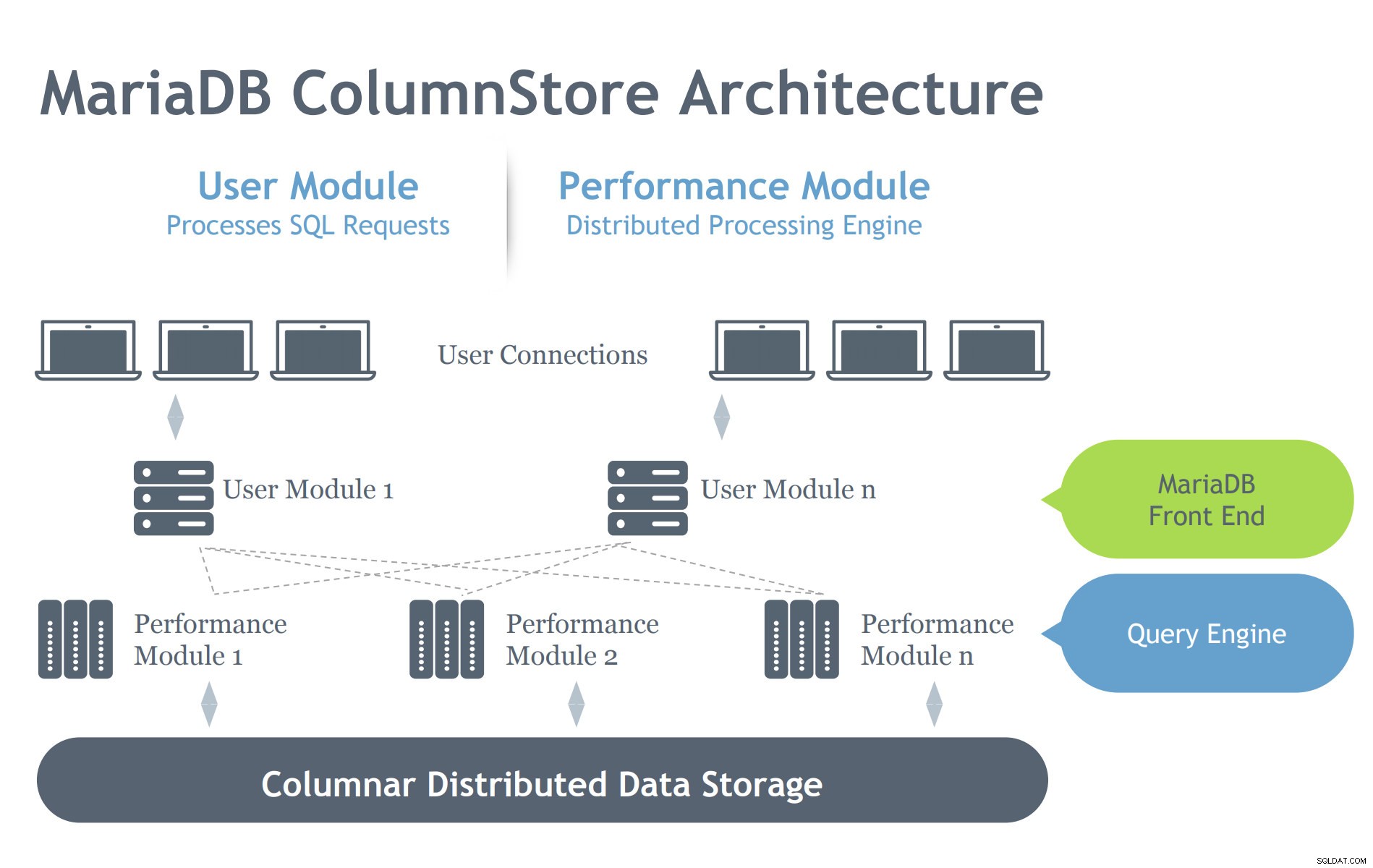 Imagem cortesia da apresentação MariaDB ColumnStore
Imagem cortesia da apresentação MariaDB ColumnStore Em contraste com a arquitetura InnoDB, o ColumnStore contém dois módulos que denotam que sua intenção é trabalhar eficientemente em um ambiente arquitetural distribuído. O InnoDB destina-se a ser dimensionado em um servidor, mas abrange vários nós interconectados, dependendo da configuração do cluster. Assim, o ColumnStore possui vários níveis de componentes que cuidam dos processos solicitados ao MariaDB Server. Vamos cavar nestes componentes abaixo:
- Módulo de usuário (UM):O UM é responsável por analisar as solicitações SQL em um conjunto otimizado de etapas de trabalho primitivas executadas por um ou mais servidores PM. A UM é, portanto, responsável pela otimização de consultas e orquestração da execução de consultas pelos servidores PM. Embora várias instâncias de UM possam ser implantadas em uma implantação de vários servidores, uma única UM é responsável por cada consulta individual. Um balanceador de carga de banco de dados, como MariaDB MaxScale, pode ser implantado para balancear adequadamente as solicitações externas em relação aos servidores de UM individuais.
- Módulo de desempenho (PM):o PM executa etapas de trabalho granulares recebidas de um UM de maneira multissegmentada. O ColumnStore permite a distribuição do trabalho em vários módulos de desempenho. A UM é composta pelo processo MariaDB mysqld e pelo processo ExeMgr.
- Mapas de Extensão:ColumnStore mantém metadados sobre cada coluna em um objeto distribuído compartilhado conhecido como Mapa de Extensão. O servidor de UM faz referência ao Mapa de Extensão para ajudar a gerar as etapas de trabalho primitivas corretas. O servidor PM faz referência ao Mapa de Extensão para identificar os blocos de disco corretos a serem lidos. Cada coluna é composta por um ou mais arquivos e cada arquivo pode conter várias extensões. Tanto quanto possível, o sistema tenta alocar armazenamento físico contíguo para melhorar o desempenho de leitura.
- Armazenamento:ColumnStore pode usar armazenamento local ou armazenamento compartilhado (por exemplo, SAN ou EBS) para armazenar dados. O uso de armazenamento compartilhado permite que o processamento de dados faça failover para outro nó automaticamente em caso de falha de um servidor PM.
Abaixo está como MariaDB ColumnStore processa a consulta,
- Os clientes emitem uma consulta ao servidor MariaDB em execução no módulo de usuário. O servidor executa uma operação de tabela para todas as tabelas necessárias para atender à solicitação e obtém o plano de execução da consulta inicial.
- Usando a interface do mecanismo de armazenamento MariaDB, ColumnStore converte o objeto de tabela do servidor em objetos ColumnStore. Esses objetos são então enviados para os processos do Módulo do Usuário.
- O módulo de usuário converte o plano de execução MariaDB e otimiza os objetos fornecidos em um plano de execução ColumnStore. Em seguida, determina as etapas necessárias para executar a consulta e a ordem em que elas precisam ser executadas.
- O Módulo do Usuário então consulta o Mapa de Extensão para determinar quais Módulos de Desempenho consultar para os dados de que precisa, então realiza a Eliminação de Extensão, eliminando da lista quaisquer Módulos de Desempenho que contenham apenas dados fora do intervalo do que a consulta exige.
- O módulo de usuário envia comandos para um ou mais módulos de desempenho para realizar operações de E/S de bloco.
- O módulo ou módulos de desempenho realizam filtragem de predicado, processamento de junção, agregação inicial de dados de armazenamento local ou externo e, em seguida, enviam os dados de volta ao módulo de usuário.
- O módulo do usuário realiza a agregação final do conjunto de resultados e compõe o conjunto de resultados para a consulta.
- O Módulo de Usuário / ExeMgr implementa quaisquer cálculos de função de janela, bem como qualquer classificação necessária no conjunto de resultados. Em seguida, ele retorna o conjunto de resultados para o servidor.
- O MariaDB Server executa quaisquer funções de lista de seleção, operações ORDER BY e LIMIT no conjunto de resultados.
- O MariaDB Server retorna o conjunto de resultados para o cliente.
Paradigmas de execução de consultas
Vamos cavar um pouco mais sobre como o ColumnStore executa a consulta e quando isso impacta.
O ColumnStore difere dos mecanismos de armazenamento MySQL/MariaDB padrão, como o InnoDB, pois o ColumnStore obtém desempenho apenas verificando as colunas necessárias, utilizando o particionamento mantido pelo sistema e utilizando vários threads e servidores para dimensionar o tempo de resposta da consulta. O desempenho é beneficiado quando você inclui apenas as colunas necessárias para a recuperação de dados. Isso significa que o asterisco ganancioso (*) em sua consulta de seleção tem um impacto significativo em comparação com um SELECT
Assim como com o InnoDB e outros mecanismos de armazenamento, o tipo de dados também tem importância no desempenho do que você usou. Se você tem uma coluna que só pode ter valores de 0 a 100, declare isso como um tinyint, pois isso será representado com 1 byte em vez de 4 bytes para int. Isso reduzirá o custo de E/S em 4 vezes. Para tipos de string, um limite importante é char(9) e varchar(8) ou superior. Cada arquivo de armazenamento de coluna usa um número fixo de bytes por valor. Isso permite a pesquisa posicional rápida de outras colunas para formar a linha. Atualmente, o limite superior para armazenamento de dados colunar é de 8 bytes. Portanto, para strings maiores que isso, o sistema mantém uma extensão de 'dicionário' adicional onde os valores são armazenados. O arquivo de extensão colunar armazena um ponteiro no dicionário. Portanto, é mais caro ler e processar uma coluna varchar(8) do que uma coluna char(8), por exemplo. Portanto, sempre que possível, você obterá um melhor desempenho se puder utilizar strings mais curtas, especialmente se evitar a pesquisa de dicionário. Todos os tipos de dados TEXT/BLOB na versão 1.1 em diante utilizam um dicionário e fazem uma pesquisa de vários blocos de 8 KB para recuperar esses dados, se necessário, quanto mais longos forem os dados, mais blocos serão recuperados e maior será o impacto potencial no desempenho.
Em um sistema baseado em linha, adicionar colunas redundantes aumenta o custo geral da consulta, mas em um sistema colunar, um custo só ocorre se a coluna for referenciada. Portanto, colunas adicionais devem ser criadas para oferecer suporte a diferentes caminhos de acesso. Por exemplo, armazene uma parte inicial de um campo em uma coluna para permitir pesquisas mais rápidas, mas também armazene o valor do formulário longo como outra coluna. As varreduras em um código mais curto ou coluna de porção inicial serão mais rápidas.
As junções de consulta são otimizadas e prontas para junções em grande escala e evitam a necessidade de índices e a sobrecarga do processamento de loop aninhado. ColumnStore mantém estatísticas de tabela para determinar a ordem de junção ideal. Abordagens semelhantes compartilham com o InnoDB, como se a junção for muito grande para a memória da UM, ela usa a junção baseada em disco para concluir a consulta.
Para agregações, o ColumnStore distribui a avaliação agregada o máximo possível. Isso significa que ele compartilha na UM e no PM para lidar com consultas especialmente ou com um número muito grande de valores na(s) coluna(s) agregada(s). Select count(*) é otimizado internamente para selecionar o menor número de bytes de armazenamento em uma tabela. Isso significa que ele escolheria a coluna CHAR(1) (usa 1 byte) sobre a coluna INT que leva 4 bytes. A implementação ainda respeita a semântica ANSI em que o select count(*) incluirá nulos na contagem total, em oposição a um select (COL-N) explícito que exclui nulos na contagem.
Ordenar por e limite são implementados no final pelo processo do servidor mariadb na tabela de conjunto de resultados temporário. Isso foi mencionado na etapa 9 sobre como o ColumnStore processa a consulta. Então, tecnicamente, os resultados são passados para o MariaDB Server para classificar os dados.
Para consultas complexas que usam subconsultas, é basicamente a mesma abordagem em que são executadas em sequência e gerenciadas pela UM, da mesma forma que as funções do Windows são tratadas pela UM, mas usa um processo de classificação mais rápido dedicado, portanto, é basicamente mais rápido.
O particionamento de seus dados é fornecido pelo ColumnStore, que usa Extent Maps, que mantém os valores mínimo/máximo dos dados da coluna e fornece um intervalo lógico para particionamento e elimina a necessidade de indexação. O Extent Maps também fornece particionamento manual de tabelas, visualizações materializadas, tabelas de resumo e outras estruturas e objetos que os bancos de dados baseados em linhas devem implementar para obter desempenho de consulta. Existem certos benefícios para valores em colunas quando eles estão em ordem ou semi-ordem, pois isso permite um particionamento de dados muito eficaz. Com os valores mínimo e máximo, os mapas de extensão inteira após o filtro e a exclusão serão eliminados. Veja esta página em seu manual sobre Extent Elimination. Isso geralmente funciona particularmente bem para dados de séries temporais ou valores semelhantes que aumentam ao longo do tempo.
Instalando o MariaDB ColumnStore
Instalar o MariaDB ColumnStore pode ser simples e direto. MariaDB tem uma série de notas aqui que você pode consultar. Para este blog, nosso ambiente de destino de instalação é o CentOS 7. Você pode acessar este link https://downloads.mariadb.com/ColumnStore/1.2.4/ e verificar os pacotes baseados em seu ambiente de SO. Veja as etapas detalhadas abaixo para ajudá-lo a acelerar:
### Note: The installation details is ideal for root user installation
cd /root/
wget https://downloads.mariadb.com/ColumnStore/1.2.4/centos/x86_64/7/mariadb-columnstore-1.2.4-1-centos7.x86_64.rpm.tar.gz
tar xzf mariadb-columnstore-1.0.7-1-centos7.x86_64.rpm.tar.gz
sudo yum -y install boost expect perl perl-DBI openssl zlib snappy libaio perl-DBD-MySQL net-tools wget jemalloc
sudo rpm -ivh mariadb-columnstore*.rpmUma vez feito, você precisa executar postConfigure comando para finalmente instalar e configurar seu MariaDB ColumnStore. Nesta instalação de exemplo, há dois nós que configurei em execução na máquina vagrant:
csnode1:192.168.2.10
csnode2:192.168.2.20
Ambos os nós são definidos em seus respectivos /etc/hosts e ambos os nós são definidos para ter seus Módulos de Usuário e Desempenho combinados em ambos os hosts. A instalação é um pouco trivial no início. Por isso, compartilhamos como você pode configurá-lo para ter uma base. Veja os detalhes abaixo para o processo de instalação de amostra:
[example@sqldat.com ~]# /usr/local/mariadb/columnstore/bin/postConfigure -d
This is the MariaDB ColumnStore System Configuration and Installation tool.
It will Configure the MariaDB ColumnStore System and will perform a Package
Installation of all of the Servers within the System that is being configured.
IMPORTANT: This tool requires to run on the Performance Module #1
Prompting instructions:
Press 'enter' to accept a value in (), if available or
Enter one of the options within [], if available, or
Enter a new value
===== Setup System Server Type Configuration =====
There are 2 options when configuring the System Server Type: single and multi
'single' - Single-Server install is used when there will only be 1 server configured
on the system. It can also be used for production systems, if the plan is
to stay single-server.
'multi' - Multi-Server install is used when you want to configure multiple servers now or
in the future. With Multi-Server install, you can still configure just 1 server
now and add on addition servers/modules in the future.
Select the type of System Server install [1=single, 2=multi] (2) >
===== Setup System Module Type Configuration =====
There are 2 options when configuring the System Module Type: separate and combined
'separate' - User and Performance functionality on separate servers.
'combined' - User and Performance functionality on the same server
Select the type of System Module Install [1=separate, 2=combined] (1) > 2
Combined Server Installation will be performed.
The Server will be configured as a Performance Module.
All MariaDB ColumnStore Processes will run on the Performance Modules.
NOTE: The MariaDB ColumnStore Schema Sync feature will replicate all of the
schemas and InnoDB tables across the User Module nodes. This feature can be enabled
or disabled, for example, if you wish to configure your own replication post installation.
MariaDB ColumnStore Schema Sync feature, do you want to enable? [y,n] (y) >
NOTE: MariaDB ColumnStore Replication Feature is enabled
Enter System Name (columnstore-1) >
===== Setup Storage Configuration =====
----- Setup Performance Module DBRoot Data Storage Mount Configuration -----
There are 2 options when configuring the storage: internal or external
'internal' - This is specified when a local disk is used for the DBRoot storage.
High Availability Server Failover is not Supported in this mode
'external' - This is specified when the DBRoot directories are mounted.
High Availability Server Failover is Supported in this mode.
Select the type of Data Storage [1=internal, 2=external] (1) >
===== Setup Memory Configuration =====
NOTE: Setting 'NumBlocksPct' to 50%
Setting 'TotalUmMemory' to 25%
===== Setup the Module Configuration =====
----- Performance Module Configuration -----
Enter number of Performance Modules [1,1024] (1) > 2
*** Parent OAM Module Performance Module #1 Configuration ***
Enter Nic Interface #1 Host Name (csnode1) >
Enter Nic Interface #1 IP Address or hostname of csnode1 (unassigned) > 192.168.2.10
Enter Nic Interface #2 Host Name (unassigned) >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm1' (1) >
*** Performance Module #2 Configuration ***
Enter Nic Interface #1 Host Name (unassigned) > csnode2
Enter Nic Interface #1 IP Address or hostname of csnode2 (192.168.2.20) >
Enter Nic Interface #2 Host Name (unassigned) >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm2' () >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm2' () > 2
===== Running the MariaDB ColumnStore MariaDB Server setup scripts =====
post-mysqld-install Successfully Completed
post-mysql-install Successfully Completed
Next step is to enter the password to access the other Servers.
This is either user password or you can default to using a ssh key
If using a user password, the password needs to be the same on all Servers.
Enter password, hit 'enter' to default to using a ssh key, or 'exit' >
===== System Installation =====
System Configuration is complete.
Performing System Installation.
Performing a MariaDB ColumnStore System install using RPM packages
located in the /root directory.
----- Performing Install on 'pm2 / csnode2' -----
Install log file is located here: /tmp/columnstore_tmp_files/pm2_rpm_install.log
MariaDB ColumnStore Package being installed, please wait ... DONE
===== Checking MariaDB ColumnStore System Logging Functionality =====
The MariaDB ColumnStore system logging is setup and working on local server
===== MariaDB ColumnStore System Startup =====
System Configuration is complete.
Performing System Installation.
----- Starting MariaDB ColumnStore on local server -----
MariaDB ColumnStore successfully started
MariaDB ColumnStore Database Platform Starting, please wait .......... DONE
System Catalog Successfully Created
Run MariaDB ColumnStore Replication Setup.. DONE
MariaDB ColumnStore Install Successfully Completed, System is Active
Enter the following command to define MariaDB ColumnStore Alias Commands
. /etc/profile.d/columnstoreAlias.sh
Enter 'mcsmysql' to access the MariaDB ColumnStore SQL console
Enter 'mcsadmin' to access the MariaDB ColumnStore Admin console
NOTE: The MariaDB ColumnStore Alias Commands are in /etc/profile.d/columnstoreAlias.sh
[example@sqldat.com ~]# . /etc/profile.d/columnstoreAlias.sh
[example@sqldat.com ~]#Depois que a instalação e a configuração estiverem concluídas, o MariaDB criará uma configuração mestre/escravo para isso, de modo que o que quer que tenhamos carregado de csnode1, será replicado para csnode2.
Despejando seu Big Data
Após a instalação, talvez você não tenha dados de amostra para testar. O IMDB compartilhou dados de amostra que você pode baixar em seu site https://www.imdb.com/interfaces/. Para este blog, criei um script que faz tudo para você. Confira aqui https://github.com/paulnamuag/columnstore-imdb-data-load. Basta torná-lo executável e, em seguida, execute o script. Ele fará tudo por você baixando os arquivos, criando o esquema e depois carregando os dados no banco de dados. É simples assim.
Executando suas consultas de exemplo
Agora, vamos tentar executar algumas consultas de amostra.
MariaDB [imdb]> select count(1), 'title_akas' table_name from title_akas union all select count(1), 'name_basics' as table_name from name_basics union all select count(1), 'title_crew' as table_name from title_crew union all select count(1), 'title_episode' as table_name from title_episode union all select count(1), 'title_ratings' as table_name from title_ratings order by 1 asc;
+----------+---------------+
| count(1) | table_name |
+----------+---------------+
| 945057 | title_ratings |
| 3797618 | title_akas |
| 4136880 | title_episode |
| 5953930 | title_crew |
| 9403540 | name_basics |
+----------+---------------+
5 rows in set (0.162 sec)MariaDB [imdb]> select count(*), 'title_akas' table_name from title_akas union all select count(*), 'name_basics' as table_name from name_basics union all select count(*), 'title_crew' as table_name from title_crew union all select count(*), 'title_episode' as table_name from title_episode union all select count(*), 'title_ratings' as table_name from title_ratings order by 2;
+----------+---------------+
| count(*) | table_name |
+----------+---------------+
| 9405192 | name_basics |
| 3797618 | title_akas |
| 5953930 | title_crew |
| 4136880 | title_episode |
| 945057 | title_ratings |
+----------+---------------+
5 rows in set (0.371 sec)Basicamente, é mais rápido e rápido. Existem consultas que você não pode processar da mesma forma que executa com outros mecanismos de armazenamento, como o InnoDB. Por exemplo, eu tentei brincar e fazer algumas consultas tolas e ver como ele reage e resulta em:
MariaDB [imdb]> select a.titleId, a.title, a.region, b.id, b.primaryName, b.profession from title_akas a join name_basics b where b.knownForTitles in (select a.titleId from title_akas) limit 25;
ERROR 1815 (HY000): Internal error: IDB-1000: 'a' and 'title_akas' are not joined.Portanto, encontrei MCOL-1620 e MCOL-131 e aponta para a configuração da variável infinidb_vtable_mode. Ver abaixo:
MariaDB [imdb]> select a.titleId, a.title, a.region, b.id, b.primaryName, b.profession from title_akas a join name_basics b where b.knownForTitles in (select c.titleId from title_akas c) limit 2;
ERROR 1815 (HY000): Internal error: IDB-1000: 'a' and 'b, sub-query' are not joined.Mas configurar infinidb_vtable_mode=0 , o que significa que trata a consulta como um modo de processamento linha a linha genérico e altamente compatível. Alguns componentes da cláusula WHERE podem ser processados pelo ColumnStore, mas as junções são processadas inteiramente pelo mysqld usando um mecanismo de junção de loop aninhado. Ver abaixo:
MariaDB [imdb]> set infinidb_vtable_mode=0;
Query OK, 0 rows affected (0.000 sec)MariaDB [imdb]> select a.titleId, a.title, a.region, b.id, b.primaryName, b.profession from title_akas a join name_basics b where b.knownForTitles in (select c.titleId from title_akas c) limit 2;
+-----------+---------------+--------+-----------+-------------+---------------+
| titleId | title | region | id | primaryName | profession |
+-----------+---------------+--------+-----------+-------------+---------------+
| tt0082880 | Vaticano Show | ES | nm0594213 | Velda Mitzi | miscellaneous |
| tt0082880 | Il pap'occhio | IT | nm0594213 | Velda Mitzi | miscellaneous |
+-----------+---------------+--------+-----------+-------------+---------------+
2 rows in set (13.789 sec)Demorou algum tempo, pois explica que foi processado inteiramente pelo mysqld. Ainda assim, otimizar e escrever boas consultas ainda é a melhor abordagem e não delegar tudo ao ColumnStore.
Além disso, você tem alguma ajuda para analisar suas consultas executando comandos como SELECT calSetTrace(1); ou SELECT calGetStats(); . Você pode usar esse conjunto de comandos, por exemplo, otimizar as consultas baixas e ruins ou visualizar seu plano de consulta. Confira aqui para obter mais detalhes sobre a análise das consultas.
Administrando ColumnStore
Depois de configurar totalmente o MariaDB ColumnStore, ele é fornecido com sua ferramenta chamada mcsadmin, para a qual você pode usar para realizar algumas tarefas administrativas. Você também pode usar esta ferramenta para adicionar outro módulo, atribuir ou mover para DBroots de PM para PM, etc. Confira o manual sobre esta ferramenta.
Basicamente, você pode fazer o seguinte, por exemplo, verificando as informações do sistema:
mcsadmin> getSystemi
getsysteminfo Mon Jun 24 12:55:25 2019
System columnstore-1
System and Module statuses
Component Status Last Status Change
------------ -------------------------- ------------------------
System ACTIVE Fri Jun 21 21:40:56 2019
Module pm1 ACTIVE Fri Jun 21 21:40:54 2019
Module pm2 ACTIVE Fri Jun 21 21:40:50 2019
Active Parent OAM Performance Module is 'pm1'
Primary Front-End MariaDB ColumnStore Module is 'pm1'
MariaDB ColumnStore Replication Feature is enabled
MariaDB ColumnStore set for Distributed Install
MariaDB ColumnStore Process statuses
Process Module Status Last Status Change Process ID
------------------ ------ --------------- ------------------------ ----------
ProcessMonitor pm1 ACTIVE Thu Jun 20 17:36:27 2019 6026
ProcessManager pm1 ACTIVE Thu Jun 20 17:36:33 2019 6165
DBRMControllerNode pm1 ACTIVE Fri Jun 21 21:40:31 2019 19890
ServerMonitor pm1 ACTIVE Fri Jun 21 21:40:33 2019 19955
DBRMWorkerNode pm1 ACTIVE Fri Jun 21 21:40:33 2019 20003
PrimProc pm1 ACTIVE Fri Jun 21 21:40:37 2019 20137
ExeMgr pm1 ACTIVE Fri Jun 21 21:40:42 2019 20541
WriteEngineServer pm1 ACTIVE Fri Jun 21 21:40:47 2019 20660
DDLProc pm1 ACTIVE Fri Jun 21 21:40:51 2019 20810
DMLProc pm1 ACTIVE Fri Jun 21 21:40:55 2019 20956
mysqld pm1 ACTIVE Fri Jun 21 21:40:41 2019 19778
ProcessMonitor pm2 ACTIVE Thu Jun 20 17:37:16 2019 9728
ProcessManager pm2 HOT_STANDBY Fri Jun 21 21:40:26 2019 25211
DBRMControllerNode pm2 COLD_STANDBY Fri Jun 21 21:40:32 2019
ServerMonitor pm2 ACTIVE Fri Jun 21 21:40:35 2019 25560
DBRMWorkerNode pm2 ACTIVE Fri Jun 21 21:40:36 2019 25593
PrimProc pm2 ACTIVE Fri Jun 21 21:40:40 2019 25642
ExeMgr pm2 ACTIVE Fri Jun 21 21:40:44 2019 25715
WriteEngineServer pm2 ACTIVE Fri Jun 21 21:40:48 2019 25768
DDLProc pm2 COLD_STANDBY Fri Jun 21 21:40:50 2019
DMLProc pm2 COLD_STANDBY Fri Jun 21 21:40:50 2019
mysqld pm2 ACTIVE Fri Jun 21 21:40:32 2019 25467
Active Alarm Counts: Critical = 1, Major = 0, Minor = 0, Warning = 0, Info = 0Conclusão
MariaDB ColumnStore é um mecanismo de armazenamento muito poderoso para seu OLAP e processamento de big data. Isso é totalmente de código aberto, o que é muito mais vantajoso do que usar bancos de dados OLAP proprietários e caros disponíveis no mercado. No entanto, existem outras alternativas para tentar, como ClickHouse, Apache HBase ou cstore_fdw da Citus Data. No entanto, nenhum deles está usando MySQL/MariaDB, então pode não ser sua opção viável se você optar por manter as variantes MySQL/MariaDB.