JP (Anotação de persistência Java ) é a solução padrão do Java para preencher a lacuna entre modelos de domínio orientados a objetos e sistemas de banco de dados relacionais. A ideia é mapear classes Java para tabelas relacionais e propriedades dessas classes para as linhas da tabela. Isso muda a semântica da experiência geral de codificação Java, colaborando perfeitamente duas tecnologias diferentes dentro do mesmo paradigma de programação. Este artigo fornece uma visão geral e sua implementação de suporte em Java.
Uma visão geral
Os bancos de dados relacionais são talvez a mais estável de todas as tecnologias de persistência disponíveis na computação, em vez de todas as complexidades envolvidas. Isso porque hoje, mesmo na era dos chamados “big data”, os bancos de dados relacionais “NoSQL” estão constantemente em demanda e prosperando. Bancos de dados relacionais são tecnologia estável não por meras palavras, mas por sua existência ao longo dos anos. O NoSQL pode ser bom para lidar com grandes quantidades de dados estruturados na empresa, mas as inúmeras cargas de trabalho transacionais são melhor tratadas por meio de bancos de dados relacionais. Além disso, existem algumas ótimas ferramentas analíticas associadas a bancos de dados relacionais.
Para se comunicar com banco de dados relacional, o ANSI padronizou uma linguagem chamada SQL (Linguagem de consulta estruturada ). Uma instrução escrita nesta linguagem pode ser usada para definir e manipular dados. Mas, o problema do SQL ao lidar com o Java é que eles têm uma estrutura sintática incompatível e muito diferente no núcleo, ou seja, o SQL é procedural, enquanto o Java é orientado a objetos. Assim, busca-se uma solução funcional tal que Java possa falar de forma orientada a objetos e a base de dados relacional ainda seja capaz de se entender. JPA é a resposta a essa chamada e fornece o mecanismo para estabelecer uma solução de trabalho entre os dois.
Relacional ao Mapeamento de Objetos
Programas Java interagem com bancos de dados relacionais usando o JDBC (Conectividade de banco de dados Java ) API. Um driver JDBC é a chave para a conectividade e permite que um programa Java manipule esse banco de dados usando a API JDBC. Uma vez que a conexão é estabelecida, o programa Java dispara consultas SQL na forma de String s para comunicar as operações de criação, inserção, atualização e exclusão. Isso é suficiente para todos os propósitos práticos, mas inconveniente do ponto de vista de um programador Java. E se a estrutura das tabelas relacionais puder ser remodelada em classes Java puras e você puder lidar com elas da maneira usual orientada a objetos? A estrutura de uma tabela relacional é uma representação lógica de dados em forma de tabela. As tabelas são compostas de colunas que descrevem os atributos da entidade e as linhas são a coleção de entidades. Por exemplo, uma tabela EMPLOYEE pode conter as seguintes entidades com seus atributos.
| Emp_number | Nome | dept_no | Salário | Local |
| 112233 | Pedro | 123 | 1200 | LA |
| 112244 | Raio | 234 | 1300 | NY |
| 112255 | Sandip | 123 | 1400 | NJ |
| 112266 | Kalpana | 234 | 1100 | LA |
As linhas são exclusivas por chave primária (emp_number) em uma tabela; isso permite uma pesquisa rápida. Uma tabela pode estar relacionada a uma ou mais tabelas por alguma chave, como uma chave estrangeira (dept_no), que se relaciona com a linha equivalente em outra tabela.
De acordo com a especificação Java Persistence 2.1, o JPA adiciona suporte para geração de esquema, métodos de conversão de tipo, uso de gráfico de entidade em consultas e operação de localização, contexto de persistência não sincronizado, invocação de procedimento armazenado e injeção em classes de ouvinte de entidade. Ele também inclui aprimoramentos na linguagem de consulta Java Persistence, na API Criteria e no mapeamento de consultas nativas.
Resumindo, faz de tudo para dar a ilusão de que não há parte procedimental ao lidar com bancos de dados relacionais e tudo é orientado a objetos.
Implementação de JPA
JPA descreve o gerenciamento de dados relacionais no aplicativo Java. É uma especificação e há várias implementações dela. Algumas implementações populares são Hibernate, EclipseLink e Apache OpenJPA. A JPA define os metadados por meio de anotações em classes Java ou por meio de arquivos de configuração XML. No entanto, podemos usar XML e anotação para descrever os metadados. Nesse caso, a configuração XML substitui as anotações. Isso é razoável porque as anotações são gravadas com o código Java, enquanto os arquivos de configuração XML são externos ao código Java. Portanto, posteriormente, se houver, é necessário fazer alterações nos metadados; no caso de configuração baseada em anotação, requer acesso direto ao código Java. Isso pode nem sempre ser possível. Nesse caso, podemos escrever uma configuração de metadados nova ou alterada em um arquivo XML sem qualquer sugestão de alteração no código original e ainda ter o efeito desejado. Essa é a vantagem de usar a configuração XML. No entanto, a configuração baseada em anotação é mais conveniente de usar e é a escolha popular entre os programadores.
- Hibernar é a mais popular e avançada entre todas as implementações de JPA devido à Red Hat. Ele usa seus próprios ajustes e recursos adicionados que podem ser usados além de sua implementação JPA. Tem uma comunidade maior de usuários e está bem documentado. Alguns dos recursos proprietários adicionais são suporte para multilocação, associação de entidades não associadas em consultas, gerenciamento de carimbo de data/hora e assim por diante.
- EclipseLink é baseado no TopLink e é uma implementação de referência das versões JPA. Ele fornece funcionalidades JPA padrão além de alguns recursos proprietários interessantes, como suporte de multilocação, manipulação de eventos de alteração de banco de dados e assim por diante.
Usando JPA em um programa Java SE
Para usar JPA em um programa Java, você precisa de um provedor JPA, como Hibernate ou EclipseLink, ou qualquer outra biblioteca. Além disso, você precisa de um driver JDBC que se conecte ao banco de dados relacional específico. Por exemplo, no código a seguir, usamos as seguintes bibliotecas:
- Provedor: EclipseLink
- Driver JDBC: Driver JDBC para MySQL (Conector/J)
Estabeleceremos uma relação entre duas tabelas – Empregado e Departamento – como um para um e um para muitos, conforme ilustrado no diagrama EER a seguir (consulte a Figura 1).
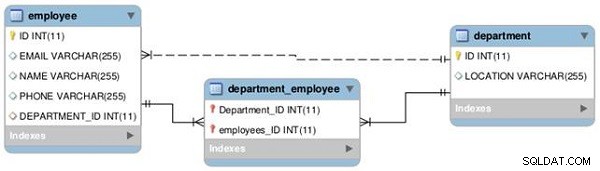
Figura 1: Relações de tabela
O funcionário tabela é mapeada para uma classe de entidade usando anotação da seguinte forma:
package org.mano.jpademoapp;
import javax.persistence.*;
@Entity
@Table(name = "employee")
public class Employee {
@Id
private int id;
private String name;
private String phone;
private String email;
@OneToOne
private Department department;
public Employee() {
super();
}
public Employee(int id, String name, String phone,
String email) {
super();
this.id = id;
this.name = name;
this.phone = phone;
this.email = email;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public Department getDepartment() {
return department;
}
public void setDepartment(Department department) {
this.department = department;
}
}
E o departamento table é mapeada para uma classe de entidade da seguinte forma:
package org.mano.jpademoapp;
import java.util.*;
import javax.persistence.*;
@Entity
@Table(name = "department")
public class Department {
@Id
private int id;
private String location;
@OneToMany
private List<Employee> employees = new ArrayList<>();
public Department() {
super();
}
public Department(int id, String location) {
super();
this.id = id;
this.location = location;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getLocation() {
return location;
}
public void setLocation(String location) {
this.location = location;
}
public List<Employee> getEmployees() {
return employees;
}
public void setEmployees(List<Employee> employees) {
this.employees = employees;
}
}
O arquivo de configuração, persistence.xml , é criado no META-INF diretório. Esse arquivo contém a configuração da conexão, como driver JDBC utilizado, nome de usuário e senha para acesso ao banco de dados e outras informações relevantes exigidas pelo provedor JPA para estabelecer a conexão com o banco de dados.
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.1"
xmlns_xsi="https://www.w3.org/2001/XMLSchema-instance"
xsi_schemaLocation="https://xmlns.jcp.org/xml/ns/persistence
https://xmlns.jcp.org/xml/ns/persistence/persistence_2_1.xsd">
<persistence-unit name="JPADemoProject"
transaction-type="RESOURCE_LOCAL">
<class>org.mano.jpademoapp.Employee</class>
<class>org.mano.jpademoapp.Department</class>
<properties>
<property name="javax.persistence.jdbc.driver"
value="com.mysql.jdbc.Driver" />
<property name="javax.persistence.jdbc.url"
value="jdbc:mysql://localhost:3306/testdb" />
<property name="javax.persistence.jdbc.user"
value="root" />
<property name="javax.persistence.jdbc.password"
value="secret" />
<property name="javax.persistence.schema-generation
.database.action"
value="drop-and-create"/>
<property name="javax.persistence.schema-generation
.scripts.action"
value="drop-and-create"/>
<property name="eclipselink.ddl-generation"
value="drop-and-create-tables"/>
</properties>
</persistence-unit>
</persistence>
As entidades não persistem por si mesmas. A lógica deve ser aplicada para manipular entidades para gerenciar seu ciclo de vida persistente. O EntityManager A interface fornecida pelo JPA permite que o aplicativo gerencie e pesquise entidades no banco de dados relacional. Criamos um objeto de consulta com a ajuda de EntityManager para se comunicar com o banco de dados. Para obter EntityManager para um determinado banco de dados, usaremos um objeto que implementa um EntityManagerFactory interface. Há uma estática método, chamado createEntityManagerFactory , em Persistência classe que retorna EntityManagerFactory para a unidade de persistência especificada como uma String argumento. Na implementação rudimentar a seguir, implementamos a lógica.
package org.mano.jpademoapp;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
public enum PersistenceManager {
INSTANCE;
private EntityManagerFactory emf;
private PersistenceManager() {
emf=Persistence.createEntityManagerFactory("JPADemoProject");
}
public EntityManager getEntityManager() {
return emf.createEntityManager();
}
public void close() {
emf.close();
}
}
Agora, estamos prontos para criar a interface principal do aplicativo. Aqui, implementamos apenas a operação de inserção por questões de simplicidade e restrições de espaço.
package org.mano.jpademoapp;
import javax.persistence.EntityManager;
public class Main {
public static void main(String[] args) {
Department d1=new Department(11, "NY");
Department d2=new Department(22, "LA");
Employee e1=new Employee(111, "Peter",
"9876543210", "example@sqldat.com");
Employee e2=new Employee(222, "Ronin",
"993875630", "example@sqldat.com");
Employee e3=new Employee(333, "Kalpana",
"9876927410", "example@sqldat.com");
Employee e4=new Employee(444, "Marc",
"989374510", "example@sqldat.com");
Employee e5=new Employee(555, "Anik",
"987738750", "example@sqldat.com");
d1.getEmployees().add(e1);
d1.getEmployees().add(e3);
d1.getEmployees().add(e4);
d2.getEmployees().add(e2);
d2.getEmployees().add(e5);
EntityManager em=PersistenceManager
.INSTANCE.getEntityManager();
em.getTransaction().begin();
em.persist(e1);
em.persist(e2);
em.persist(e3);
em.persist(e4);
em.persist(e5);
em.persist(d1);
em.persist(d2);
em.getTransaction().commit();
em.close();
PersistenceManager.INSTANCE.close();
}
}
| Observação: Consulte a documentação apropriada da API Java para obter informações detalhadas sobre as APIs usadas no código anterior. |
Conclusão
Como deve ser óbvio, a terminologia central do contexto JPA e Persistence é mais vasta do que o vislumbre dado aqui, mas começar com uma visão geral rápida é melhor do que código sujo longo e intrincado e seus detalhes conceituais. Se você tiver um pouco de experiência em programação no núcleo JDBC, sem dúvida apreciará como o JPA pode tornar sua vida mais simples. Iremos mergulhar mais fundo no JPA gradualmente à medida que avançamos nos próximos artigos.