Em outubro passado, desafiamos o público do nosso PyBites a criar um aplicativo da web para navegar melhor no feed Daily Python Tip. Neste artigo, compartilharei o que construí e aprendi ao longo do caminho.
Neste artigo você vai aprender:
- Como clonar o repositório do projeto e configurar o aplicativo.
- Como usar a API do Twitter por meio do módulo Tweepy para carregar os tweets.
- Como usar o SQLAlchemy para armazenar e gerenciar os dados (dicas e hashtags).
- Como criar um aplicativo da Web simples com o Bottle, um micro framework da Web semelhante ao Flask.
- Como usar o framework pytest para adicionar testes.
- Como a orientação do Better Code Hub levou a um código mais sustentável.
Se você quiser acompanhar, lendo o código em detalhes (e possivelmente contribuir), sugiro que faça um fork do repositório. Vamos começar.
Configuração do projeto
Primeiro, Namespaces são uma ótima ideia então vamos fazer nosso trabalho em um ambiente virtual. Usando o Anaconda eu crio assim:
$ virtualenv -p <path-to-python-to-use> ~/virtualenvs/pytip
Crie um banco de dados de produção e de teste no Postgres:
$ psql
psql (9.6.5, server 9.6.2)
Type "help" for help.
# create database pytip;
CREATE DATABASE
# create database pytip_test;
CREATE DATABASE
Precisaremos de credenciais para nos conectar ao banco de dados e à API do Twitter (crie um novo aplicativo primeiro). De acordo com as melhores práticas, a configuração deve ser armazenada no ambiente, não no código. Coloque as seguintes variáveis env no final de ~/virtualenvs/pytip/bin/activate , o script que trata da ativação/desativação do seu ambiente virtual, certificando-se de atualizar as variáveis do seu ambiente:
export DATABASE_URL='postgres://postgres:password@localhost:5432/pytip'
# twitter
export CONSUMER_KEY='xyz'
export CONSUMER_SECRET='xyz'
export ACCESS_TOKEN='xyz'
export ACCESS_SECRET='xyz'
# if deploying it set this to 'heroku'
export APP_LOCATION=local
Na função de desativação do mesmo script, eu os desconfiguro para manter as coisas fora do escopo do shell ao desativar (sair) do ambiente virtual:
unset DATABASE_URL
unset CONSUMER_KEY
unset CONSUMER_SECRET
unset ACCESS_TOKEN
unset ACCESS_SECRET
unset APP_LOCATION
Agora é um bom momento para ativar o ambiente virtual:
$ source ~/virtualenvs/pytip/bin/activate
Clone o repositório e, com o ambiente virtual habilitado, instale os requisitos:
$ git clone https://github.com/pybites/pytip && cd pytip
$ pip install -r requirements.txt
Em seguida, importamos a coleção de tweets com:
$ python tasks/import_tweets.py
Em seguida, verifique se as tabelas foram criadas e os tweets foram adicionados:
$ psql
\c pytip
pytip=# \dt
List of relations
Schema | Name | Type | Owner
--------+----------+-------+----------
public | hashtags | table | postgres
public | tips | table | postgres
(2 rows)
pytip=# select count(*) from tips;
count
-------
222
(1 row)
pytip=# select count(*) from hashtags;
count
-------
27
(1 row)
pytip=# \q
Agora vamos executar os testes:
$ pytest
========================== test session starts ==========================
platform darwin -- Python 3.6.2, pytest-3.2.3, py-1.4.34, pluggy-0.4.0
rootdir: realpython/pytip, inifile:
collected 5 items
tests/test_tasks.py .
tests/test_tips.py ....
========================== 5 passed in 0.61 seconds ==========================
E, por último, execute o aplicativo Bottle com:
$ python app.py
Navegue até https://localhost:8080 e voilà:você verá as dicas classificadas de acordo com a popularidade. Clicando em um link de hashtag à esquerda ou usando a caixa de pesquisa, você pode filtrá-los facilmente. Aqui vemos os pandas dicas por exemplo:
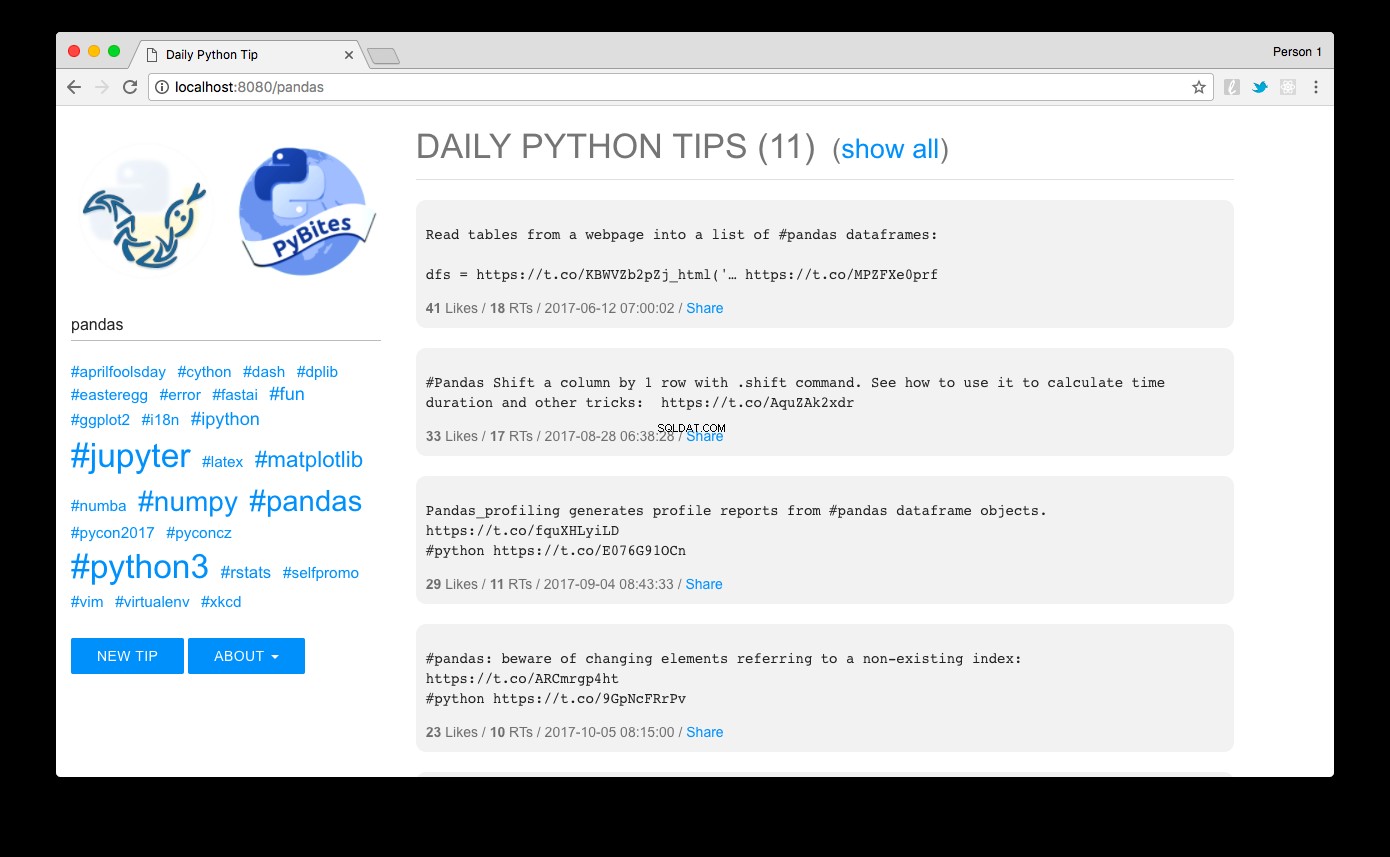
O design eu fiz com o MUI - um framework CSS leve que segue as diretrizes de Material Design do Google.
Detalhes de implementação
O banco de dados e SQLAlchemy
Eu usei SQLAlchemy para fazer interface com o banco de dados para evitar ter que escrever muito SQL (redundante).
Em dicas/modelos.py , definimos nossos modelos -
Hashtag e Tip - que SQLAlchemy irá mapear para tabelas de banco de dados:from sqlalchemy import Column, Sequence, Integer, String, DateTime
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Hashtag(Base):
__tablename__ = 'hashtags'
id = Column(Integer, Sequence('id_seq'), primary_key=True)
name = Column(String(20))
count = Column(Integer)
def __repr__(self):
return "<Hashtag('%s', '%d')>" % (self.name, self.count)
class Tip(Base):
__tablename__ = 'tips'
id = Column(Integer, Sequence('id_seq'), primary_key=True)
tweetid = Column(String(22))
text = Column(String(300))
created = Column(DateTime)
likes = Column(Integer)
retweets = Column(Integer)
def __repr__(self):
return "<Tip('%d', '%s')>" % (self.id, self.text)
Em dicas/db.py , importamos esses modelos e agora ficou fácil trabalhar com o banco de dados, por exemplo, para fazer interface com o
Hashtag modelo:def get_hashtags():
return session.query(Hashtag).order_by(Hashtag.name.asc()).all()
E:
def add_hashtags(hashtags_cnt):
for tag, count in hashtags_cnt.items():
session.add(Hashtag(name=tag, count=count))
session.commit()
Consulte a API do Twitter
Precisamos recuperar os dados do Twitter. Para isso, criei tasks/import_tweets.py . Eu empacotei isso em tarefas porque deve ser executado em um cronjob diário para procurar novas dicas e atualizar estatísticas (número de curtidas e retuítes) em tweets existentes. Por uma questão de simplicidade, tenho as tabelas recriadas diariamente. Se começarmos a confiar nas relações FK com outras tabelas, definitivamente devemos escolher instruções de atualização em vez de excluir + adicionar.
Usamos esse script na configuração do projeto. Vamos ver o que ele faz com mais detalhes.
Primeiro, criamos um objeto de sessão da API que passamos para tweepy.Cursor. Esse recurso da API é muito legal:lida com paginação, iterando pela linha do tempo. Pela quantidade de dicas - 222 no momento em que escrevo isso - é muito rápido. O
exclude_replies=True e include_rts=False argumentos são convenientes porque queremos apenas os próprios tweets do Daily Python Tip (não retuítes). Extrair hashtags das dicas requer muito pouco código.
Primeiro, defini um regex para uma tag:
TAG = re.compile(r'#([a-z0-9]{3,})')
Então, usei
findall para obter todas as etiquetas. Eu os passei para collections.Counter que retorna um dict como objeto com as tags como chaves e conta como valores, ordenados em ordem decrescente por valores (mais comuns). Excluí a tag python muito comum que distorceria os resultados.
def get_hashtag_counter(tips):
blob = ' '.join(t.text.lower() for t in tips)
cnt = Counter(TAG.findall(blob))
if EXCLUDE_PYTHON_HASHTAG:
cnt.pop('python', None)
return cnt
Por fim, o
import_* funções em tasks/import_tweets.py faça a importação real dos tweets e hashtags, chamando add_* Métodos de banco de dados das dicas diretório/pacote. Criar um aplicativo web simples com Bottle
Com este pré-trabalho feito, fazer um aplicativo da web é surpreendentemente fácil (ou não tão surpreendente se você usou o Flask antes).
Antes de mais nada, conheça a Garrafa:
Bottle é um micro web-framework WSGI rápido, simples e leve para Python. Ele é distribuído como um módulo de arquivo único e não tem dependências além da Python Standard Library.
Legal. O aplicativo da web resultante é composto por <30 LOC e pode ser encontrado em app.py.
Para este aplicativo simples, basta um único método com um argumento de tag opcional. Semelhante ao Flask, o roteamento é tratado com decoradores. Se chamado com uma tag, filtra as dicas na tag, senão mostra todas. O decorador de exibição define o modelo a ser usado. Assim como o Flask (e o Django), retornamos um dict para uso no template.
@route('/')
@route('/<tag>')
@view('index')
def index(tag=None):
tag = tag or request.query.get('tag') or None
tags = get_hashtags()
tips = get_tips(tag)
return {'search_tag': tag or '',
'tags': tags,
'tips': tips}
De acordo com a documentação, para trabalhar com arquivos estáticos, você adiciona este snippet no topo, após as importações:
@route('/static/<filename:path>')
def send_static(filename):
return static_file(filename, root='static')
Por fim, queremos ter certeza de que executamos apenas no modo de depuração no host local, por isso o
APP_LOCATION env que definimos na configuração do projeto:if os.environ.get('APP_LOCATION') == 'heroku':
run(host="0.0.0.0", port=int(os.environ.get("PORT", 5000)))
else:
run(host='localhost', port=8080, debug=True, reloader=True)
Modelos de garrafa
O Bottle vem com um mecanismo de modelo integrado rápido, poderoso e fácil de aprender chamado SimpleTemplate.
No subdiretório views eu defini um header.tpl , index.tpl e footer.tpl . Para a nuvem de tags, usei um CSS inline simples aumentando o tamanho da tag por contagem, consulte header.tpl :
% for tag in tags:
<a style="font-size: {{ tag.count/10 + 1 }}em;" href="/{{ tag.name }}">#{{ tag.name }}</a>
% end
Em index.tpl fazemos um loop sobre as dicas:
% for tip in tips:
<div class='tip'>
<pre>{{ !tip.text }}</pre>
<div class="mui--text-dark-secondary"><strong>{{ tip.likes }}</strong> Likes / <strong>{{ tip.retweets }}</strong> RTs / {{ tip.created }} / <a href="https://twitter.com/python_tip/status/{{ tip.tweetid }}" target="_blank">Share</a></div>
</div>
% end
{{ tip.likes }} Curtidas / {{ tip.retweets }} RTs / {{ tip.created }} / Compartilhar
% end Se você estiver familiarizado com Flask e Jinja2, isso deve parecer muito familiar. A incorporação do Python é ainda mais fácil, com menos digitação—
(% ... vs {% ... %} ). Todos os css, imagens (e JS se usarmos) vão para a subpasta estática.
E isso é tudo para fazer um aplicativo web básico com o Bottle. Depois de definir a camada de dados corretamente, é bastante simples.
Adicione testes com pytest
Agora vamos tornar este projeto um pouco mais robusto adicionando alguns testes. Testar o banco de dados exigiu um pouco mais de pesquisa no framework pytest, mas acabei usando o decorador pytest.fixture para configurar e derrubar um banco de dados com alguns tweets de teste.
Em vez de chamar a API do Twitter, usei alguns dados estáticos fornecidos em tweets.json .E, em vez de usar o banco de dados ativo, em tips/db.py , verifico se pytest é o chamador (
sys.argv[0] ). Se sim, eu uso o banco de dados de teste. Provavelmente vou refatorar isso, porque o Bottle suporta trabalhar com arquivos de configuração. A parte da hashtag foi mais fácil de testar (
test_get_hashtag_counter ) porque eu poderia simplesmente adicionar algumas hashtags a uma string de várias linhas. Nenhum acessório necessário. A qualidade do código é importante - Better Code Hub
O Better Code Hub orienta você a escrever, bem, um código melhor. Antes de escrever os testes, o projeto obteve nota 7:
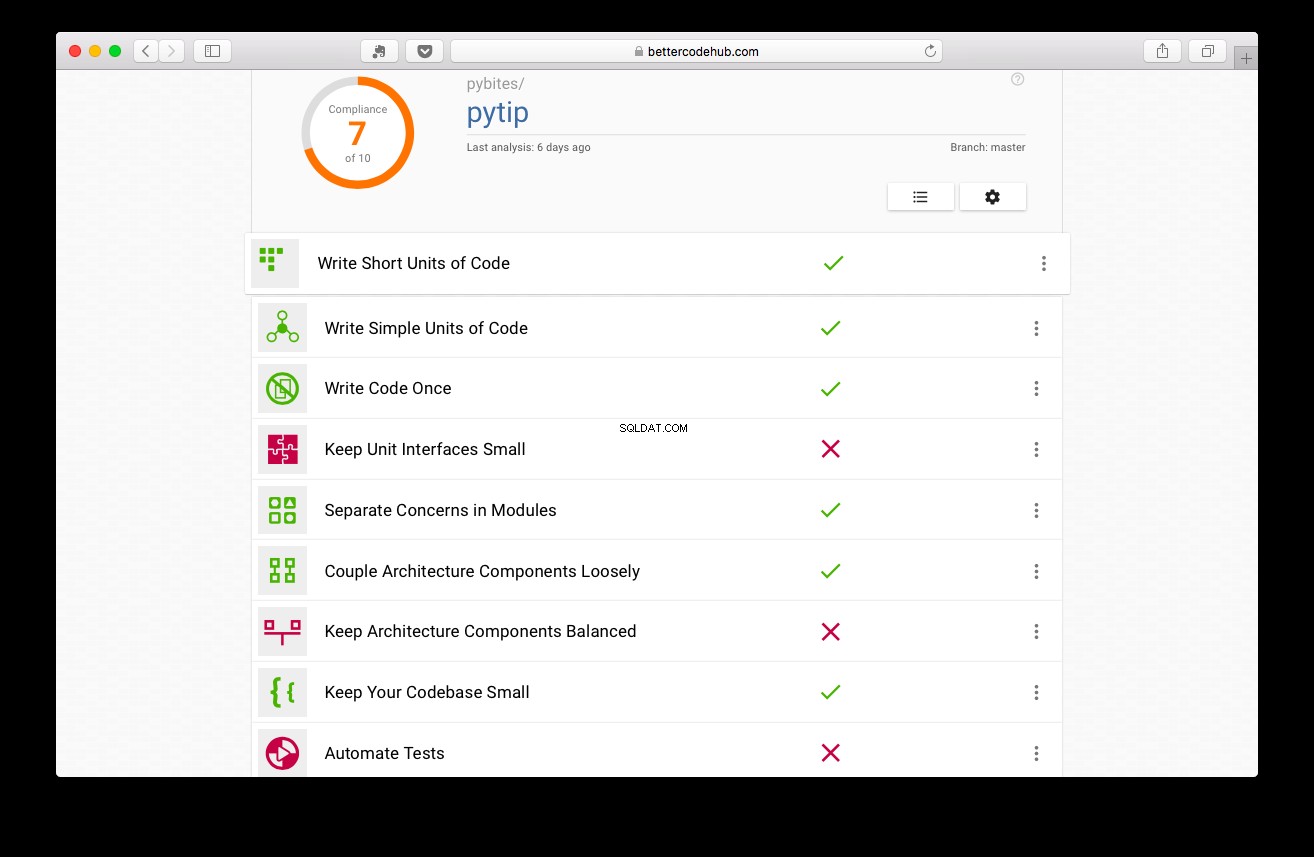
Não é ruim, mas podemos fazer melhor:
-
Aumentei para um 9 tornando o código mais modular, tirando a lógica do banco de dados do app.py (aplicativo web), colocando-o na pasta/pacote de dicas (refactorings 1 e 2)
-
Então, com os testes em vigor, o projeto obteve nota 10:
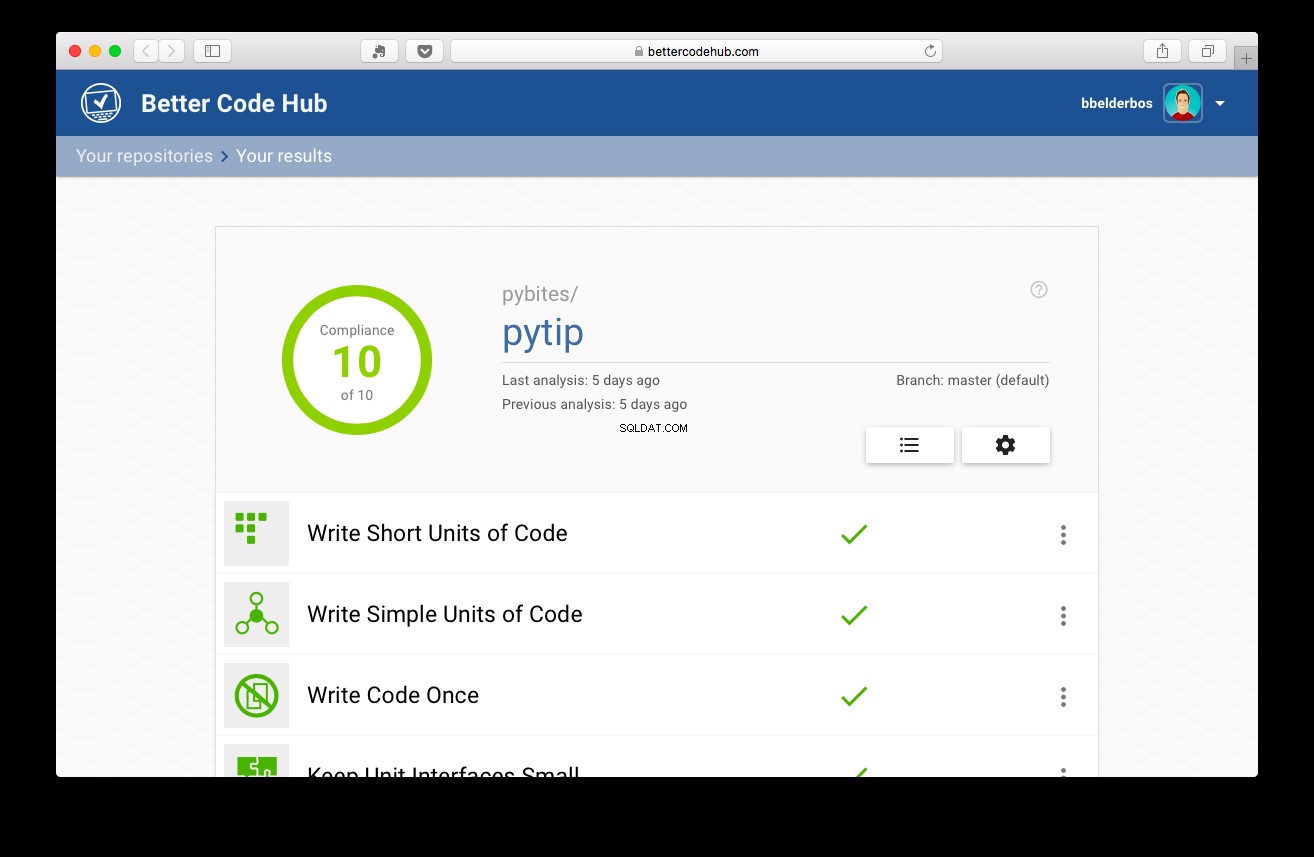
Conclusão e Aprendizagem
Nosso Code Challenge #40 ofereceu algumas boas práticas:
- Criei um aplicativo útil que pode ser expandido (quero adicionar uma API).
- Usei alguns módulos interessantes que valem a pena explorar:Tweepy, SQLAlchemy e Bottle.
- Aprendi mais pytest porque precisava de fixtures para testar a interação com o banco de dados.
- Acima de tudo, tendo que tornar o código testável, o aplicativo ficou mais modular, o que facilitou a manutenção. O Better Code Hub foi de grande ajuda nesse processo.
- Implantei o aplicativo no Heroku usando nosso guia passo a passo.
Desafiamos você
A melhor maneira de aprender e melhorar suas habilidades de codificação é praticar. Na PyBites, solidificamos esse conceito organizando desafios de código Python. Confira nossa coleção crescente, faça o fork do repositório e comece a codificar!
Deixe-nos saber se você construir algo legal fazendo um Pull Request do seu trabalho. Vimos pessoas realmente se esforçando para superar esses desafios, e nós também.
Boa codificação!