Índices são impulsionadores de velocidade em bancos de dados SQL. Eles podem ser agrupados ou não agrupados. Mas o que isso significa e onde você deve aplicar cada um?
Eu conheço essa sensação. Eu estive lá. Os iniciantes geralmente ficam confusos sobre qual índice usar em quais colunas. No entanto, mesmo os especialistas precisam refletir sobre essa questão antes de tomar uma decisão, e situações diferentes exigem decisões diferentes. Como você verá mais tarde, há consultas em que um índice clusterizado se destacará em comparação com um índice não clusterizado e vice-versa.
Ainda assim, primeiro, temos que conhecer cada um deles. Se você está procurando a mesma informação, hoje é seu dia de sorte.
Este artigo lhe dirá quais são esses índices e quando usar cada um. Claro, haverá exemplos de código para você experimentar na prática. Então, pegue suas batatas fritas ou pizza e um refrigerante ou café e prepare-se para mergulhar nesta jornada perspicaz.
Preparar?
O que é índice agrupado
Um índice clusterizado é um índice que define a ordem de classificação física das linhas em uma tabela ou exibição.
Para ver isso na forma real, vamos usar o Funcionário tabela no AdventureWorks2017 base de dados.
A chave primária também é um índice clusterizado e a chave é baseada no BusinessEntityID coluna. Ao fazer um SELECT nesta tabela sem um ORDER BY, você verá que está ordenado pela chave primária.
Experimente você mesmo usando o código abaixo:
USE AdventureWorks2017
GO
SELECT TOP 10 * FROM HumanResources.Employee
GO
Agora, veja o resultado na Figura 1:
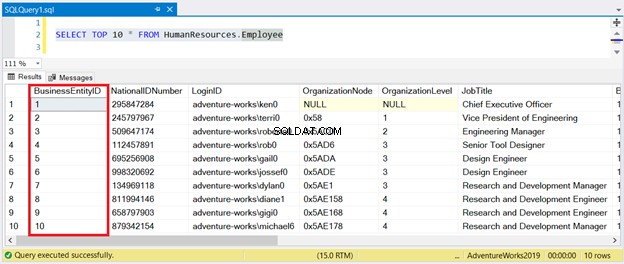
Como você pode ver, não é necessário classificar o conjunto de resultados com BusinessEntityID . O índice clusterizado cuida disso.
Ao contrário dos índices não clusterizados, você só pode ter 1 índice clusterizado por tabela. E se tentarmos isso no Funcionário tabela?
CREATE CLUSTERED INDEX IX_Employee_NationalID
ON HumanResources.Employee (NationalIDNumber)
GO
Temos um erro semelhante abaixo:
Msg 1902, Level 16, State 3, Line 4
Cannot create more than one clustered index on table 'HumanResources.Employee'. Drop the existing clustered index 'PK_Employee_BusinessEntityID' before creating another.
Quando usar um índice clusterizado?
Uma coluna é a melhor candidata a um índice clusterizado se uma das seguintes condições for verdadeira:
- É usado em um grande número de consultas na cláusula WHERE e nas junções.
- Ela será usada como chave estrangeira para outra tabela e, finalmente, para junções.
- Valores de coluna exclusivos.
- É menos provável que o valor mude.
- Essa coluna é usada para consultar um intervalo de valores. Operadores como>, <,>=, <=ou BETWEEN são usados com a coluna na cláusula WHERE.
Mas os índices clusterizados não são bons se a coluna ou colunas
- mudar com frequência
- são chaves largas ou uma combinação de colunas com um tamanho de chave grande.
Exemplos
Os índices clusterizados podem ser criados usando o código T-SQL ou qualquer ferramenta GUI do SQL Server. Você pode fazer isso no T-SQL na criação da tabela, assim:
CREATE TABLE [Person].[Person](
[BusinessEntityID] [int] NOT NULL,
[PersonType] [nchar](2) NOT NULL,
[NameStyle] [dbo].[NameStyle] NOT NULL,
[Title] [nvarchar](8) NULL,
[FirstName] [dbo].[Name] NOT NULL,
[MiddleName] [dbo].[Name] NULL,
[LastName] [dbo].[Name] NOT NULL,
[Suffix] [nvarchar](10) NULL,
[EmailPromotion] [int] NOT NULL,
[AdditionalContactInfo] [xml](CONTENT [Person].[AdditionalContactInfoSchemaCollection]) NULL,
[Demographics] [xml](CONTENT [Person].[IndividualSurveySchemaCollection]) NULL,
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_Person_BusinessEntityID] PRIMARY KEY CLUSTERED
(
[BusinessEntityID] ASC
)
GO
Ou você pode fazer isso usando ALTER TABLE depois de criando a tabela sem um índice clusterizado:
ALTER TABLE Person.Person ADD CONSTRAINT [PK_Person_BusinessEntityID] PRIMARY KEY CLUSTERED (BusinessEntityID)
GO
Outra maneira é usar CREATE CLUSTERED INDEX:
CREATE CLUSTERED INDEX [PK_Person_BusinessEntityID] ON Person.Person (BusinessEntityID)
GO
Mais uma alternativa é usar uma ferramenta do SQL Server como SQL Server Management Studio ou dbForge Studio para SQL Server.
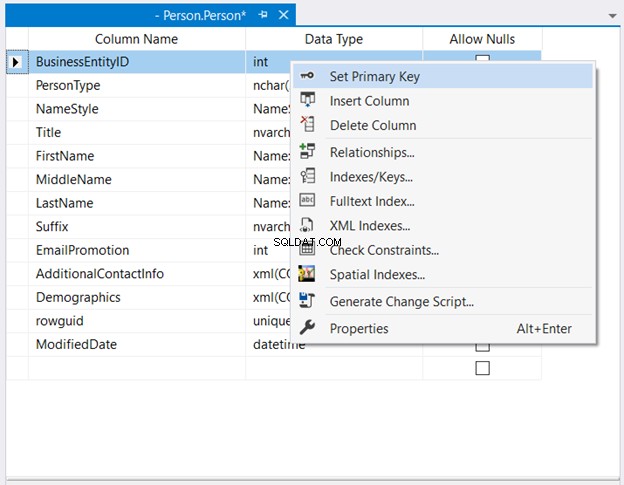
No Explorador de Objetos , expanda os nós do banco de dados e da tabela. Em seguida, clique com o botão direito do mouse na tabela desejada e selecione Design . Por fim, clique com o botão direito do mouse na coluna que você deseja que seja a chave primária> Definir chave primária > Salve as alterações na tabela.
A Figura 2 abaixo mostra onde BusinessEntityID é definido como a chave primária.
Além de criar um índice clusterizado de coluna única, você pode usar várias colunas. Veja um exemplo em T-SQL:
CREATE CLUSTERED INDEX [IX_Person_LastName_FirstName_MiddleName] ON [Person].[Person]
(
[LastName] ASC,
[FirstName] ASC,
[MiddleName] ASC
)
GO
Depois de criar esse índice clusterizado, a Pessoa tabela será classificada fisicamente por Sobrenome , Nome e Nome do meio .
Uma das vantagens dessa abordagem é o desempenho aprimorado da consulta com base no nome. Além disso, ele classifica os resultados por nome sem especificar ORDER BY. Mas note que se o nome mudar, a tabela terá que ser reorganizada. Embora isso não aconteça todos os dias, o impacto pode ser enorme se a mesa for muito grande.
O que é índice não agrupado
Um índice não clusterizado é um índice com uma chave e um ponteiro para as linhas ou chaves de índice clusterizado. Esse índice pode ser aplicado a tabelas e exibições.
Ao contrário dos índices clusterizados, aqui a estrutura é separada da tabela. Como é separado, ele precisa de um ponteiro para as linhas da tabela, também chamado de localizador de linha. Assim, cada entrada em um índice não clusterizado contém um localizador e um valor de chave.
Índices não clusterizados não classificam fisicamente a tabela com base na chave.
As chaves de índice para índices não agrupados têm um tamanho máximo de 1700 bytes. Você pode ignorar esse limite adicionando colunas incluídas. Esse método é bom se sua consulta precisar cobrir mais colunas sem aumentar o tamanho da chave.
Você também pode criar índices não clusterizados filtrados. Isso reduzirá o custo de manutenção do índice e o armazenamento, melhorando o desempenho da consulta.
Quando usar um índice não agrupado?
Uma coluna ou colunas são boas candidatas para índices não clusterizados se o seguinte for verdadeiro:
- A coluna ou colunas são usadas em uma cláusula ou junção WHERE.
- A consulta não retornará um grande conjunto de resultados.
- É necessária a correspondência exata na cláusula WHERE usando o operador de igualdade.
Exemplos
Este comando criará um índice exclusivo e não agrupado no Employee tabela:
CREATE UNIQUE NONCLUSTERED INDEX [AK_Employee_NationalIDNumber] ON [HumanResources].[Employee]
(
[NationalIDNumber] ASC
)
GO
Além de uma tabela, você pode criar um índice não clusterizado para uma exibição:
CREATE NONCLUSTERED INDEX [IDX_vProductAndDescription_ProductModel] ON [Production].[vProductAndDescription]
(
[ProductModel] ASC
)
GO
Outras perguntas comuns e respostas satisfatórias
Quais são as diferenças entre índices agrupados e não agrupados?
Pelo que você viu anteriormente, você já pode formar ideias sobre como são os diferentes índices clusterizados e não clusterizados. Mas vamos colocá-lo em uma mesa para facilitar a referência.
| Informações | Índice agrupado | Índice não agrupado |
| Aplica-se a | Tabelas e visualizações | Tabelas e visualizações |
| Permitido por Tabela | 1 | 999 |
| Tamanho da chave | 900 bytes | 1700 bytes |
| Colunas por chave de índice | 32 | 32 |
| Bom para | Consultas de intervalo (>,<,>=, <=, BETWEEN) | Correspondências exatas (=) |
| Colunas incluídas sem chave | Não permitido | Permitido |
| Filtro com condição | Não permitido | Permitido |
As chaves primárias devem ser índices agrupados ou não agrupados?
Uma chave primária é uma restrição. Depois de tornar uma coluna uma chave primária, um índice clusterizado é criado automaticamente a partir dela, a menos que um índice clusterizado existente já esteja em vigor.
Não confunda uma chave primária com um índice clusterizado! Uma chave primária também pode ser a chave de índice clusterizado. Mas uma chave de índice clusterizado pode ser outra coluna diferente da chave primária.
Tomemos outro exemplo. Na Pessoa tabela de AdventureWorks201 7, temos o BusinessEntityID chave primária. É também a chave de índice clusterizado. Você pode descartar esse índice clusterizado. Em seguida, crie um índice clusterizado com base em Sobrenome , Nome e Nome do meio . A chave primária ainda é o BusinessEntityID coluna.
Mas suas chaves primárias devem sempre ser agrupadas?
Depende. Reveja a pergunta sobre quando usar um índice clusterizado.
Se uma coluna ou colunas aparecerem em sua cláusula WHERE em muitas consultas, isso é um candidato a um índice clusterizado. Mas outra consideração é a largura da chave de índice clusterizado. Muito amplo – e o tamanho de cada índice não agrupado aumentará se existirem. Lembre-se de que os índices não clusterizados também usam a chave de índice clusterizado como um ponteiro. Portanto, mantenha sua chave de índice clusterizada o mais restrita possível.
Se um grande número de consultas usar a chave primária na cláusula WHERE, deixe-a também como a chave de índice clusterizado. Caso contrário, crie sua chave primária como um índice não clusterizado.
Mas e se você ainda não tiver certeza? Em seguida, você pode avaliar o benefício de desempenho de uma coluna quando ela está em cluster ou não. Então, sintonize a próxima seção sobre isso.
Qual é mais rápido:índice agrupado ou não agrupado?
Boa pergunta. Não há regra geral. Você precisa verificar as leituras lógicas e o plano de execução de suas consultas.
Nosso breve experimento incluirá cópias das seguintes tabelas do AdventureWorks2017 base de dados:
- Pessoa
- BusinessEntityAddress
- Endereço
- Tipo de endereço
Aqui está o roteiro:
IF NOT EXISTS(SELECT name FROM sys.databases WHERE name = 'TestDatabase')
BEGIN
CREATE DATABASE TestDatabase
END
USE TestDatabase
GO
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Person_pkClustered')
BEGIN
SELECT
BusinessEntityID
,LastName
,FirstName
,MiddleName
,Suffix
,PersonType
,Title
INTO Person_pkClustered FROM AdventureWorks2017.Person.Person
ALTER TABLE Person_pkClustered
ADD CONSTRAINT [PK_Person_BusinessEntityID2] PRIMARY KEY CLUSTERED (BusinessEntityID)
CREATE NONCLUSTERED INDEX [IX_Person_Name2] ON Person_pkClustered (LastName, FirstName, MiddleName, Suffix)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Person_pkNonClustered')
BEGIN
SELECT
BusinessEntityID
,LastName
,FirstName
,MiddleName
,Suffix
,PersonType
,Title
INTO Person_pkNonClustered FROM AdventureWorks2017.Person.Person
CREATE CLUSTERED INDEX [IX_Person_Name1] ON Person_pkNonClustered (LastName, FirstName, MiddleName, Suffix)
ALTER TABLE Person_pkNonClustered
ADD CONSTRAINT [PK_Person_BusinessEntityID1] PRIMARY KEY NONCLUSTERED (BusinessEntityID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'AddressType')
BEGIN
SELECT * INTO AddressType FROM AdventureWorks2017.Person.AddressType
ALTER TABLE AddressType
ADD CONSTRAINT [PK_AddressType] PRIMARY KEY CLUSTERED (AddressTypeID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Address')
BEGIN
SELECT * INTO Address FROM AdventureWorks2017.Person.Address
ALTER TABLE Address
ADD CONSTRAINT [PK_Address] PRIMARY KEY CLUSTERED (AddressID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'BusinessEntityAddress')
BEGIN
SELECT * INTO BusinessEntityAddress FROM AdventureWorks2017.Person.BusinessEntityAddress
ALTER TABLE BusinessEntityAddress
ADD CONSTRAINT [PK_BusinessEntityAddress] PRIMARY KEY CLUSTERED (BusinessEntityID, AddressID, AddressTypeID)
END
GO
Usando a estrutura acima, compararemos as velocidades de consulta para índices clusterizados e não clusterizados.
Temos 2 cópias da Pessoa tabela. O primeiro usará BusinessEntityID como a chave de índice primária e clusterizada. O segundo ainda usa BusinessEntityID como chave primária. O índice clusterizado é baseado em Sobrenome , Nome , Nome do meio e Sufixo .
Vamos começar.
CONSULTE CORRESPONDÊNCIAS EXATAS COM BASE NO SOBRENOME
Primeiro, vamos fazer uma consulta simples. Além disso, precisa ativar STATISTICS IO. Em seguida, colamos os resultados em statisticsparser.com para uma apresentação tabular.
SET STATISTICS IO ON
GO
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, p.Title
FROM Person_pkClustered p
WHERE p.LastName = 'Martinez' OR p.LastName = 'Smith'
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkNonClustered p
WHERE p.LastName = 'Martinez' OR p.LastName = 'Smith'
SET STATISTICS IO OFF
GO
A expectativa é que o primeiro SELECT seja mais lento porque a cláusula WHERE não corresponde à chave do índice clusterizado. Mas vamos verificar as leituras lógicas.
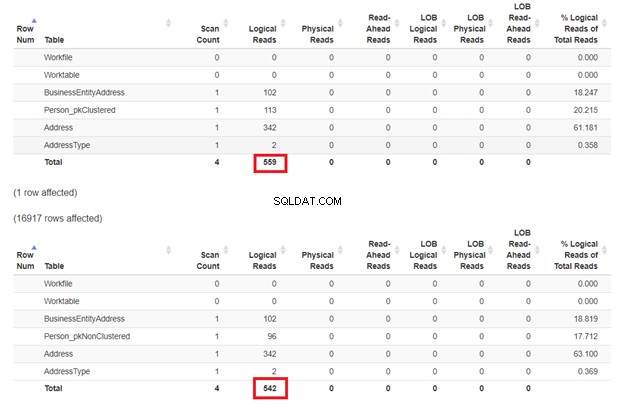
Conforme esperado na Figura 3, Person_pkClustered teve leituras mais lógicas. Portanto, a consulta precisa de mais E/S. O motivo? A tabela é classificada por BusinessEntityID . No entanto, a segunda tabela tem o índice clusterizado com base no nome. Como a consulta deseja um resultado com base no nome, Person_pkNonClustered vitórias. Quanto menos leituras lógicas, mais rápida a consulta.
O que mais está acontecendo? Confira a Figura 4.
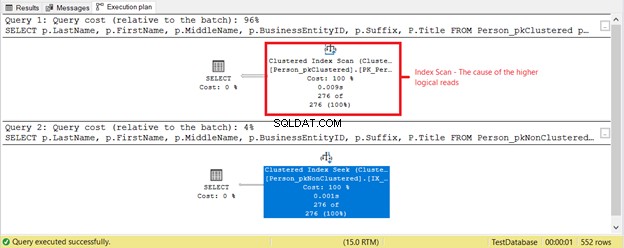
Algo mais aconteceu com base no plano de execução na Figura 4. Por que uma varredura de índice clusterizado está no primeiro SELECT em vez de uma busca de índice? O culpado é o Título coluna no SELECT. Não é coberto por nenhum dos índices existentes. O otimizador do SQL Server considerou mais rápido usar o índice clusterizado com base em BusinessEntityID. Em seguida, o SQL Server verificou os sobrenomes corretos e obteve o primeiro nome, o nome do meio e o título.
Remova o Título coluna, e o operador usado será Index Seek . Por quê? Como o restante dos campos é coberto pelo índice não agrupado com base em Sobrenome , Nome , Nome do meio e Sufixo . Também inclui BusinessEntityID como o localizador de chave de índice clusterizado.
CONSULTA DE INTERVALO COM BASE NO ID DA ENTIDADE COMERCIAL
Índices clusterizados podem ser bons para consultas de intervalo. É sempre assim? Vamos descobrir usando o código abaixo.
SET STATISTICS IO ON
GO
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkClustered p
WHERE p.BusinessEntityID >= 285 AND p.BusinessEntityID <= 290
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkNonClustered p
WHERE p.BusinessEntityID >= 285 AND p.BusinessEntityID <= 290
SET STATISTICS IO OFF
GO
A listagem precisa de linhas com base em um intervalo de BusinessEntityIDs de 285 para 290. Novamente, os índices clusterizados e não clusterizados das 2 tabelas estão intactos. Agora, vamos ter as leituras lógicas na Figura 5. O vencedor esperado é Person_pkClustered porque a chave primária também é a chave de índice clusterizado.

Você vê leituras lógicas mais baixas em Person_pkClustered ? Os índices clusterizados provaram seu valor em consultas de intervalo nesse cenário. Vamos ver o que mais o plano de execução revelará na Figura 6.
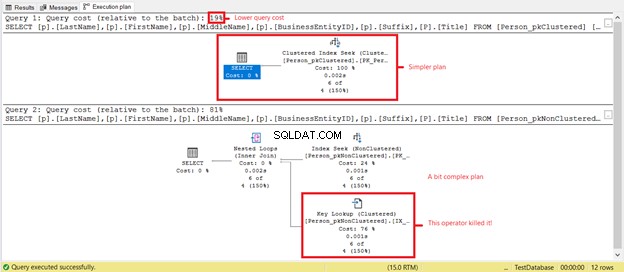
O primeiro SELECT tem um plano mais simples e custo de consulta mais baixo com base na Figura 7. Isso também suporta leituras lógicas mais baixas. Enquanto isso, o segundo SELECT tem um operador Key Lookup que desacelera a consulta. O culpado? Novamente, é o Título coluna. Remova a coluna na consulta ou adicione-a como uma coluna incluída no índice não clusterizado. Então, você terá um plano melhor e leituras lógicas mais baixas.
CONSULTE CORRESPONDÊNCIAS EXATAS COM UM JOIN
Muitas instruções SELECT incluem junções. Vamos fazer alguns testes. Aqui começamos com correspondências exatas:
SET STATISTICS IO ON
GO
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE P.LastName = 'Martinez'
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkNonClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE P.LastName = 'Martinez'
SET STATISTICS IO OFF
GO
Esperamos que o segundo SELECT de Person_pkNonClustered com um índice clusterizado no nome terá menos leituras lógicas. Mas é? Consulte a Figura 7.
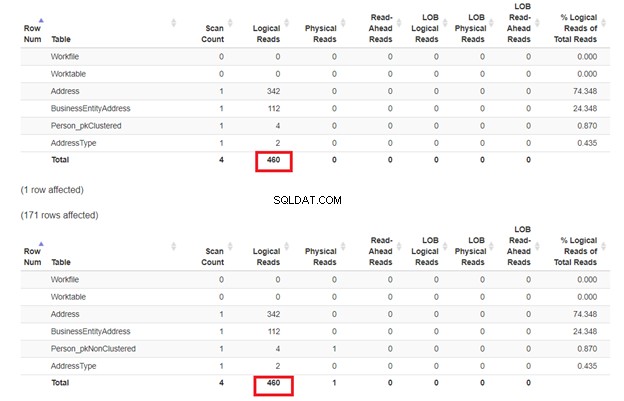
Parece que o índice não clusterizado no nome funcionou bem. As leituras lógicas são as mesmas. Se você verificar o plano de execução, a diferença nos operadores é o Clustered Index Seek em Person_pkNonClustered , e a Busca de Índice em Person_pkClustered .
Portanto, precisamos verificar as leituras lógicas e o plano de execução para ter certeza.
CONSULTA DE INTERVALO COM JOINS
Como nossas expectativas podem ser diferentes da realidade, vamos tentar com consultas de intervalo. Índices clusterizados geralmente são bons com isso. Mas e se você incluir uma junção?
SET STATISTICS IO ON
GO
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE p.BusinessEntityID BETWEEN 100 AND 19000
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkNonClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE p.BusinessEntityID BETWEEN 100 AND 19000
SET STATISTICS IO OFF
GO
Agora, inspecione as leituras lógicas dessas 2 consultas na Figura 8:
O que aconteceu? Na Figura 9, a realidade morde Person_pkClustered . Mais custo de E/S foi observado em comparação com Person_pkNonClustered . Isso é diferente do que esperamos. Mas com base nesta resposta do fórum, uma busca de índice não clusterizado pode ser mais rápida do que a busca de índice clusterizado quando todas as colunas na consulta estão 100% cobertas no índice. No nosso caso, a consulta para Person_pkNonClustered cobriu as colunas usando o índice não clusterizado (BusinessEntityID - chave; Sobrenome , Nome , Nome do meio , Sufixo – ponteiro para chave de índice clusterizado).
INSERIR DESEMPENHO
Em seguida, tente testar o desempenho do INSERT nas mesmas tabelas.
SET STATISTICS IO ON
GO
INSERT INTO Person_pkClustered
(BusinessEntityID, LastName, FirstName, MiddleName, Suffix, PersonType, Title)
VALUES (20778, 'Sanchez','Edwin', 'Ilaya', NULL, N'SC', N'Mr.'),
(20779, 'Galilei','Galileo', '', NULL, N'SC', N'Mr.');
INSERT INTO Person_pkNonClustered
(BusinessEntityID, LastName, FirstName, MiddleName, Suffix, PersonType, Title)
VALUES (20778, 'Sanchez','Edwin', 'Ilaya', NULL, N'SC', N'Mr.'),
(20779, 'Galilei','Galileo', '', NULL, N'SC', N'Mr.');
SET STATISTICS IO OFF
GO
A Figura 9 mostra as leituras lógicas INSERT:

Ambos geraram a mesma E/S. Assim, ambos tiveram o mesmo desempenho.
EXCLUIR DESEMPENHO
Nosso último teste envolve DELETE:
SET STATISTICS IO ON
GO
DELETE FROM Person_pkClustered
WHERE LastName='Sanchez'
AND FirstName = 'Edwin'
DELETE FROM Person_pkNonClustered
WHERE LastName='Sanchez'
AND FirstName = 'Edwin'
SET STATISTICS IO OFF
GO
A Figura 10 mostra as leituras lógicas. Observe a diferença.

Por que temos leituras lógicas mais altas em Person_pkClustered ? O problema é que a condição da instrução DELETE é baseada em uma correspondência exata de um nome. O otimizador terá que recorrer primeiro ao índice não clusterizado. Significa mais E/S. Vamos confirmar usando o plano de execução na Figura 11.
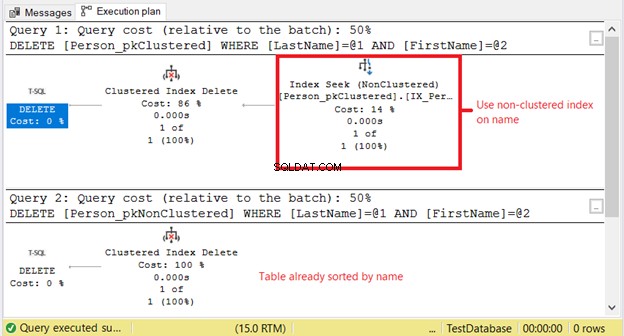
O primeiro SELECT precisa de um Index Seek no índice não clusterizado. O motivo é a cláusula WHERE em Sobrenome e Nome . Enquanto isso, Person_pkNonClustered já está fisicamente classificado por nome devido ao índice clusterizado.
Recomendações
Formar consultas de alto desempenho não é uma questão de sorte. Você não pode simplesmente colocar um índice clusterizado e um não clusterizado e, de repente, suas consultas têm a força de velocidade. Você precisa continuar usando as ferramentas como sua lente para focar nos pequenos detalhes além do conjunto de resultados.
Mas às vezes você simplesmente não tem tempo para fazer tudo isso. Eu acho isso normal. Mas contanto que você não estrague tanto assim, você tem seu trabalho no dia seguinte e pode resolver isso. Isso não será fácil no começo. Na verdade vai ficar confuso. Você também terá muitas perguntas. Mas com prática constante, você pode alcançá-lo. Então, mantenha o queixo erguido.
Lembre-se de que os índices clusterizados e não clusterizados são para impulsionar consultas. Conhecer as principais diferenças, os cenários de uso e as ferramentas o ajudarão em sua busca pela codificação de consultas de alto desempenho.
Espero que esta postagem responda às suas perguntas mais urgentes sobre índices clusterizados e não clusterizados. Você tem algo mais a acrescentar para nossos leitores? A seção Comentários está aberta.
E se você achar este post esclarecedor, compartilhe-o em suas plataformas de mídia social favoritas.
Mais informações sobre índices e desempenho de consultas estão nos artigos abaixo:
- 22 exemplos bacanas de índice SQL para acelerar suas consultas
- Otimização de consultas SQL:5 fatos essenciais para impulsionar suas consultas