Um Sistema de Gerenciamento de Banco de Dados é o cofre da informação. Tentaremos projetar o Sistema de Gerenciamento de Banco de Dados para que o banco de dados permaneça bem gerenciado e atendendo aos propósitos.
Neste artigo, discutiremos o projeto e a administração de sistemas de banco de dados de grande porte. Usaremos várias constituições que incluirão tecnologias de banco de dados, armazenamento, distribuição de dados, ativos de servidor, padrão de arquitetura e alguns outros.
De preferência, devemos procurar um banco de dados de grande porte no domínio Telco, plataformas de comércio eletrônico, domínio de seguros, sistema bancário, saúde, sistema de energia, etc. Devemos manter alguns parâmetros em mente antes de escolher a tecnologia de banco de dados correta. ou seja, Tráfego, TPS (Transações por Segundo), armazenamento estimado por dia, HA e DR.
Projetando um banco de dados de grande porte
Ao construir nosso banco de dados, devemos prestar atenção a vários parâmetros, porque muitas vezes é muito problemático alterar o banco de dados por um substituto. Vamos considerá-los agora.
Tecnologia de banco de dados
A tecnologia de banco de dados é o fator principal. Se você escolher o sistema de gerenciamento de banco de dados certo, ele ajudará sua empresa a funcionar com eficiência e sem esforço.
Existem várias tecnologias de banco de dados com muitos recursos. No entanto, ao trabalhar com tecnologias de banco de dados de código aberto, você pode não obter acesso a alguns recursos explícitos de soluções predefinidas. Tecnologias de banco de dados corporativos como Microsoft SQL Server, Oracle, etc. as forneceriam.
Muitas tecnologias de banco de dados corporativos implementam HA (alta disponibilidade), DR (recuperação de desastres), espelhamento, replicação de dados, réplica de leitura secundária e soluções de negócios configuráveis consideravelmente mais convenientes e prontas. Eles podem ou não estar presentes em bancos de dados de código aberto.
Existem muitas razões. Por exemplo, às vezes descobrimos que a arquitetura existente está sendo perturbada porque os fatores mencionados acima não são funcionais como precisamos deles.
Armazenamento
O armazenamento afeta drasticamente o desempenho da solução de negócios. As soluções de negócios exigem armazenamento ou SSD de primeira classe com uma certa quantidade de IOPS. No entanto, é assim? No local ou na nuvem, o tamanho e o tipo de armazenamento determinam os custos de infraestrutura.
Ao considerar o desempenho do armazenamento, precisamos prestar atenção ao tipo de dados e ao comportamento do processamento de dados. Precisamos optar pela seleção de armazenamento de acordo com os dados do usuário e o processamento dos mesmos. Se o usuário for usar vários bancos de dados, precisamos fornecer a opção de armazenamento na SAN para diferentes bancos de dados para os tipos de dados e o comportamento de processamento de dados.
O engenheiro de banco de dados fornecerá uma melhor retrospectiva nos vários bancos de dados necessários para o cálculo de IOPS se os usuários não precisarem de armazenamento premium.
Distribuição de dados
A maioria das tecnologias de banco de dados recentes (SQL ou NoSQL) oferece recursos de particionamento ou Sharding.
- A partição redistribui dados no sistema de arquivos com base na chave de partição.
- A fragmentação distribui informações entre os nós do banco de dados e os dados seriam armazenados na mesma máquina ou em uma máquina diferente.
Fundamentalmente, cada serviço de banco de dados ou tabela de banco de dados não exigirá os recursos de particionamento/fragmentação de dados. Eles só precisam ser aplicados em bancos de dados que contenham objetos de tamanho maior. Isso vai melhorar o desempenho.
Recursos de servidor
Diferentes máquinas requerem diferentes tipos e tamanhos de memória e CPU. Você deve considerar os ativos de nível de hardware, como Memória, Processador, etc. Por exemplo, uma máquina que precisa lidar com bancos de dados maiores ou vários bancos de dados precisará de mais memória e CPUs. Portanto, a qualidade da Memória e do Processador é significativa. Ele vai lidar com diferentes tipos de processadores disponíveis no mercado com diferentes caches de CPU.
Muitas vezes, nos deparamos com problemas que podemos não estar cientes. Não prestamos atenção à utilização e ao papel do cache da CPU do hardware. Mas é crucial para selecionar e atender aos requisitos de hardware com sistemas de banco de dados maiores.
Padrão de arquitetura
No projeto de banco de dados, o padrão Arquitetura sempre tem um papel exemplar. Anteriormente, os sistemas de banco de dados eram projetados de maneira extremamente monolítica. Agora, usamos baseado em Micro-Serviços ou Híbrido (Monolítico + Micro).
O desempenho, a capacidade de expansão e o tempo de inatividade zero dependem muito do padrão de arquitetura e do design do banco de dados. Cada aplicativo pode ter um banco de dados separado e todos os bancos de dados podem ser acoplados livremente entre si. No caso de qualquer aplicativo ou banco de dados ficar inativo, outra parte do produto não será interrompida. Todos os microsserviços seriam independentes e pouco acoplados.
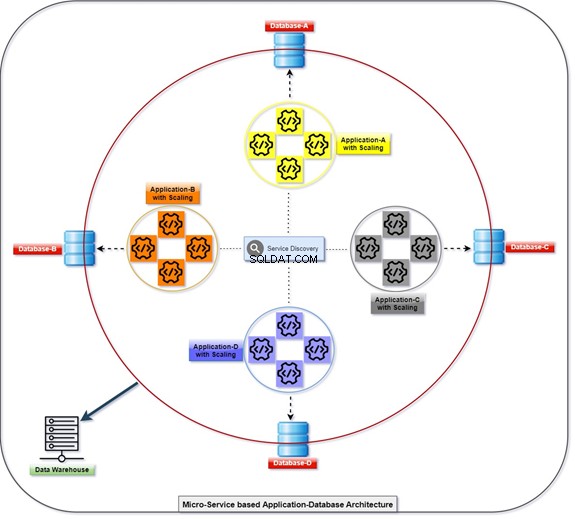
Microserviço
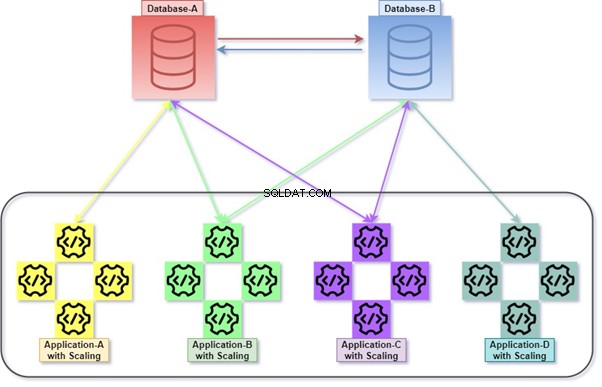
O diagrama abaixo explica como todos os aplicativos estão implantando e se comunicando com a ajuda de seus bancos de dados, que são acoplados livremente ao mesmo tempo. Podemos manipular os dados com T-SQL. As informações serão coletadas ou acumuladas por diversos aplicativos, e o cliente poderá acessar os dados. Consulte o diagrama com o número de aplicativos dimensionados e seu banco de dados integrado.
Monolítico
Qual RDBMS devemos usar? Pode ser Oracle, Microsoft SQL Server, Postgres, MySQL, MongoDB ou qualquer outro banco de dados. A forma convencional de lidar com todas as tabelas ou objetos gerenciados em um ou vários bancos de dados em um único servidor é conhecida como Monolítica.
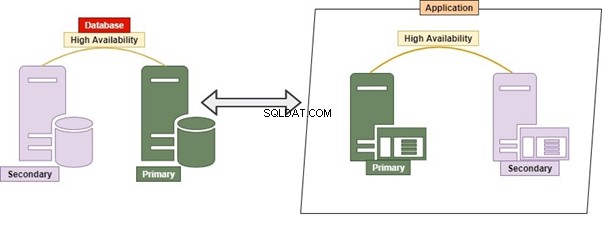
Híbrido
Híbrido é uma permutação de Monolítico e Micro Serviço. É uma prática bastante comum, pois permite inúmeras aplicações, inúmeros bancos de dados e servidores de banco de dados. Numerosos bancos de dados e servidores de banco de dados podem ser fortemente acoplados uns aos outros.
Por exemplo, consultando com JOINs entre tabelas pertencentes a dois ou mais bancos de dados no mesmo servidor de banco de dados ou diferente. Consulta remota usada para recuperação/manipulação de dados com outro servidor de banco de dados.
Tudo é sobre a arquitetura do SQL Server. No entanto, estamos falando da manipulação de dados entre diferentes tabelas dentro de um mesmo banco de dados ou bancos de dados diferentes que podem residir no mesmo servidor ou em servidores diferentes.
Tanto na arquitetura híbrida quanto na monolítica, usamos JOINs entre várias tabelas dentro do mesmo banco de dados ou de bancos de dados diferentes. É bastante complexo quando seguimos os principais padrões de Micro-Serviços, pois a distribuição das tabelas pode ser entre os serviços de banco de dados (Dbas).
Sob as tecnologias de banco de dados Enterprise como Microsoft SQL Server, Oracle, etc., o usuário pode consultar as tabelas do banco de dados distribuído com a ajuda de Linked Server Joins. Mas não está disponível em todas as tecnologias de banco de dados de código aberto. É conhecida como a abordagem Tight-Coupled que pode não funcionar quando o serviço de banco de dados remoto não está disponível.
Agora, vamos discutir como torná-lo solto. Por que precisamos de manipulação de dados entre bancos de dados remotos?
Por que exigimos manipulação de dados entre bancos de dados remotos?
Os usuários exigirão que os dados sejam recuperados de mais de um serviço de banco de dados quando o sistema for projetado com a ajuda de Micro ou Serviços Híbridos. Todo o processo é visto a partir do backend que pode lidar com quantidades de dados manipulados pelo aplicativo.
Quando olhamos para a consulta cruzada de banco de dados em tempo real, sempre juntamos as tabelas de entidade mestre, não as tabelas de metadados. As tabelas mestras não serão maiores que as tabelas de metadados. Para fins de relatório, sempre usamos o data warehouse para reunir todas as informações. Mas isso não é fácil de gerenciar e manter para cada produto. Se projetarmos a solução corporativa, podemos arcar com o depósito. Mas não podemos pagar por produtos pequenos ou médios.
Por exemplo, precisamos de um relatório com os dados de várias tabelas que residem em diferentes bancos de dados. Não é uma tarefa fácil de executar, pois reúne os dados usando diferentes microsserviços e os mescla para produzir o relatório. Portanto, os dados necessários precisam ser sincronizados.
O que podemos usar como solução padrão fazer sincronização de dados de tabela de acoplamento flexível entre dois bancos de dados?
A Replicação de Tabela deve ser usada para sincronização de dados simples entre vários bancos de dados. O exemplo é a replicação de transação para a sincronização de dados Simplex e a Replicação de Mesclagem para a sincronização de dados Duplex fornecida pelo SQL Server.
Existem algumas soluções pagas de terceiros e de código aberto que podem sincronizar os dados entre vários bancos de dados. Mesmo soluções de acoplamento flexível com a ajuda de filas de mensagens, como SQL Server Transaction Replication, podem ser desenvolvidas pelos próprios usuários.
Conclusão
DBAs projetam bancos de dados à sua maneira. Ao arquitetar o banco de dados e escolher o sistema de gerenciamento de banco de dados, eles devem manter muitos aspectos em mente. Apresentamos os fatores mais essenciais para o desenho do banco de dados, especialmente para os bancos de dados de maior porte. Fique ligado nos próximos materiais!