Mover seus dados para um serviço de nuvem pública é uma grande decisão. Todos os principais fornecedores de nuvem oferecem serviços de banco de dados em nuvem, sendo o Amazon RDS for MySQL provavelmente o mais popular.
Neste blog, veremos de perto o que é, como funciona e comparamos seus prós e contras.
RDS (Relational Database Service) é uma oferta da Amazon Web Services. Em suma, é um Banco de Dados como Serviço, onde a Amazon implanta e opera seu banco de dados. Ele cuida de tarefas como backup e correção do software de banco de dados, bem como alta disponibilidade. Alguns bancos de dados são suportados pelo RDS, mas aqui estamos interessados principalmente no MySQL - a Amazon suporta MySQL e MariaDB. Há também o Aurora, que é o clone do MySQL da Amazon, aprimorado, principalmente na área de replicação e alta disponibilidade.
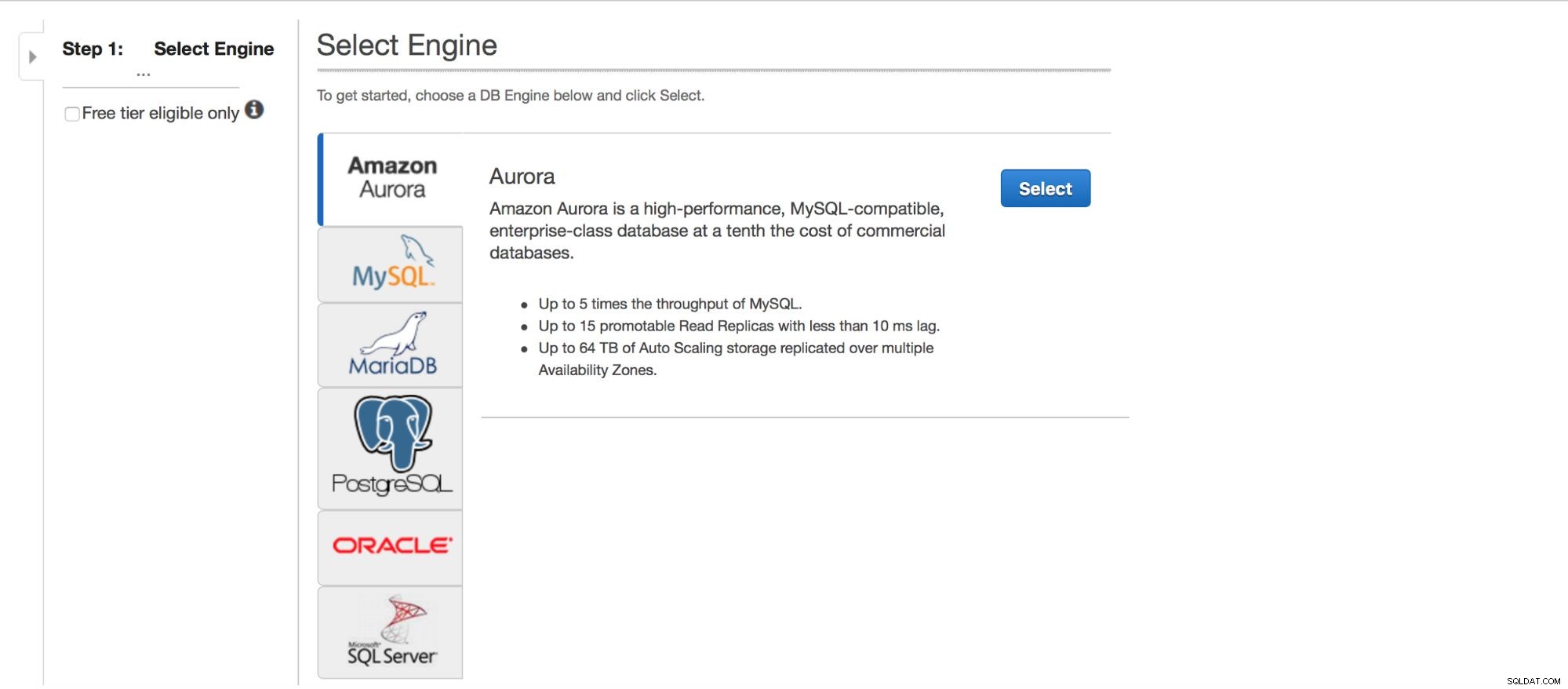
Implantando MySQL via RDS
Vamos dar uma olhada na implantação do MySQL via RDS. Escolhemos o MySQL e, em seguida, somos apresentados a alguns padrões de implantação para escolher.
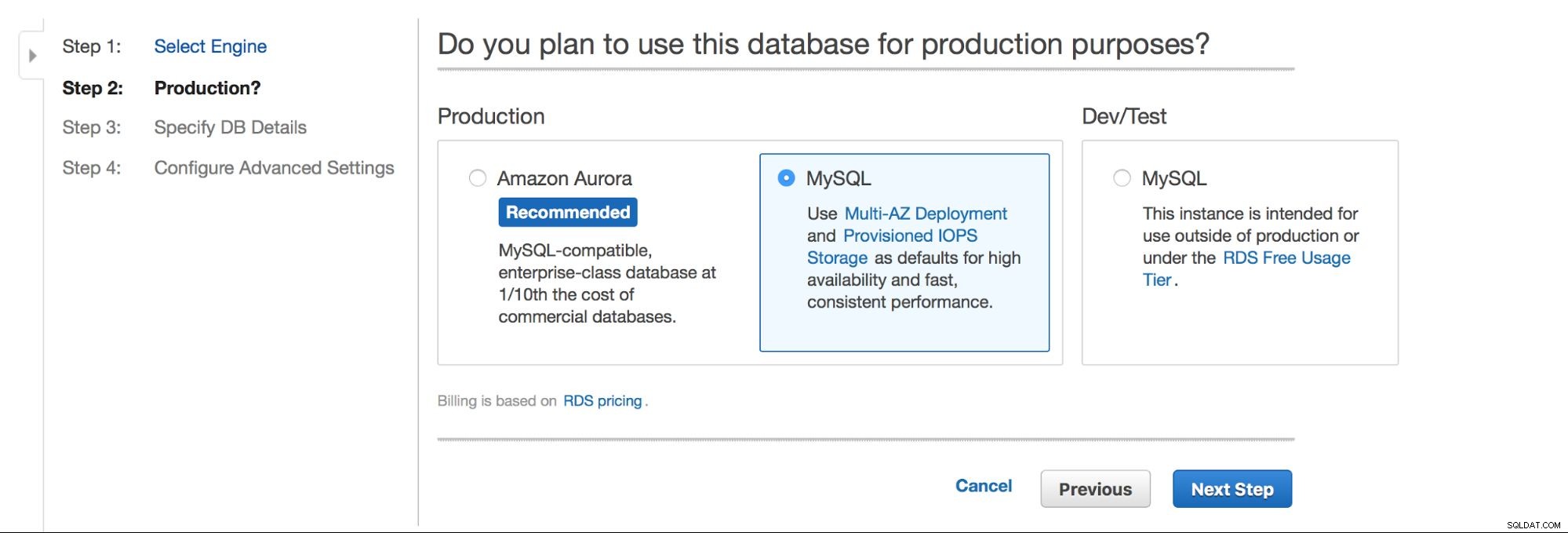
A principal escolha é - queremos ter alta disponibilidade ou não? Aurora também é promovida.
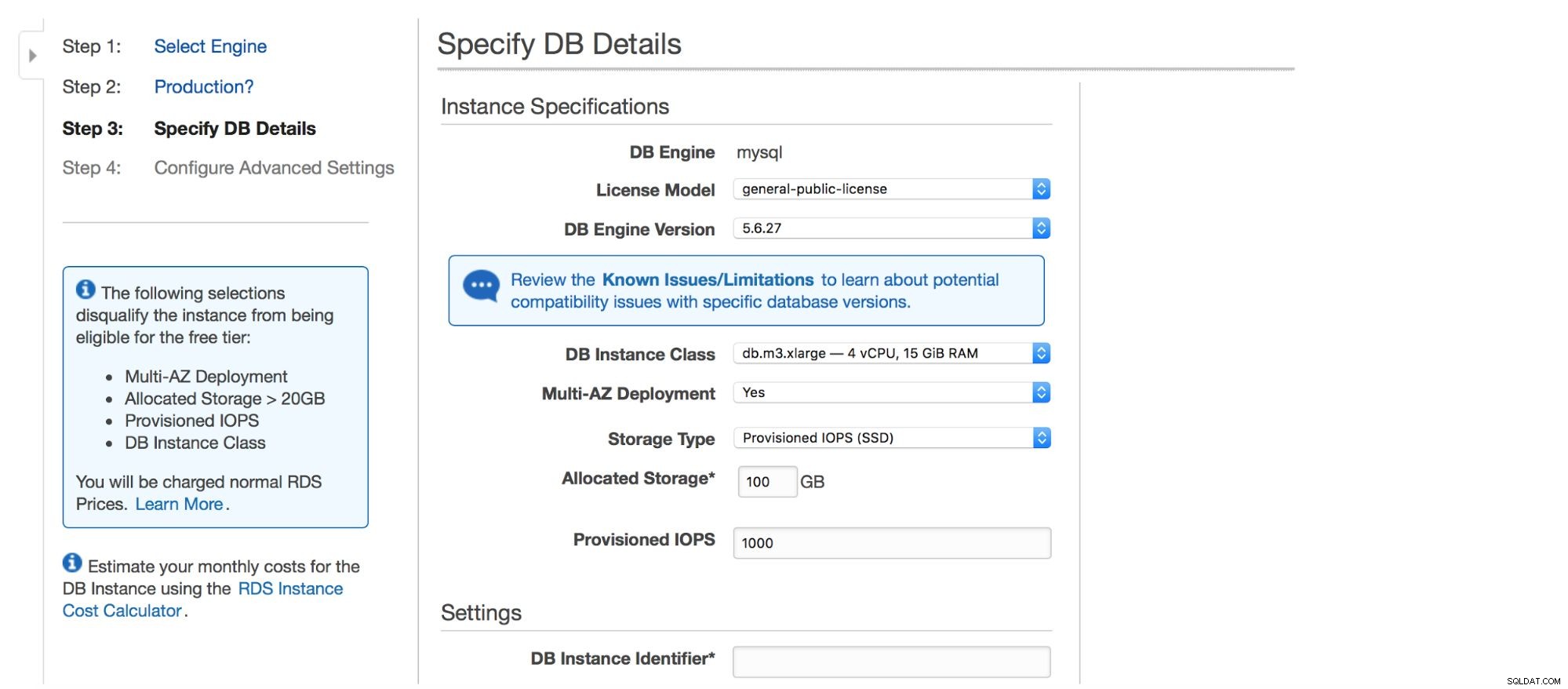
A próxima caixa de diálogo nos dá algumas opções para personalizar. Você pode escolher uma das muitas versões do MySQL - várias versões 5.5, 5.6 e 5.7 estão disponíveis. Instância de banco de dados - você pode escolher entre os tamanhos de instância típicos disponíveis em uma determinada região.
A próxima opção é uma escolha muito importante - você deseja usar a implantação multi-AZ ou não? Isso é tudo sobre alta disponibilidade. Se você não quiser usar a implantação multi-AZ, uma única instância será instalada. Em caso de falha, um novo será gerado e seu volume de dados será remontado a ele. Esse processo leva algum tempo, durante o qual seu banco de dados não estará disponível. Claro, você pode minimizar esse impacto usando escravos e promovendo um deles, mas não é um processo automatizado. Se você deseja ter alta disponibilidade automatizada, deve usar a implantação multi-AZ. O que acontecerá é que duas instâncias de banco de dados serão criadas. Um é visível para você. Uma segunda instância, em uma zona de disponibilidade separada, não é visível para o usuário. Ele atuará como uma cópia de sombra, pronta para assumir o tráfego assim que o nó ativo falhar. Ainda não é uma solução perfeita, pois o tráfego precisa ser alternado da instância com falha para a sombra. Em nossos testes, levou ~45s para realizar um failover, mas, obviamente, pode depender do tamanho da instância, desempenho de E/S etc. Mas é muito melhor do que o failover não automatizado, onde apenas os escravos estão envolvidos.
Por fim, temos as configurações de armazenamento - tipo, tamanho, PIOPS (quando aplicável) e configurações do banco de dados - identificador, usuário e senha.
Na próxima etapa, mais algumas opções estão aguardando a entrada do usuário.
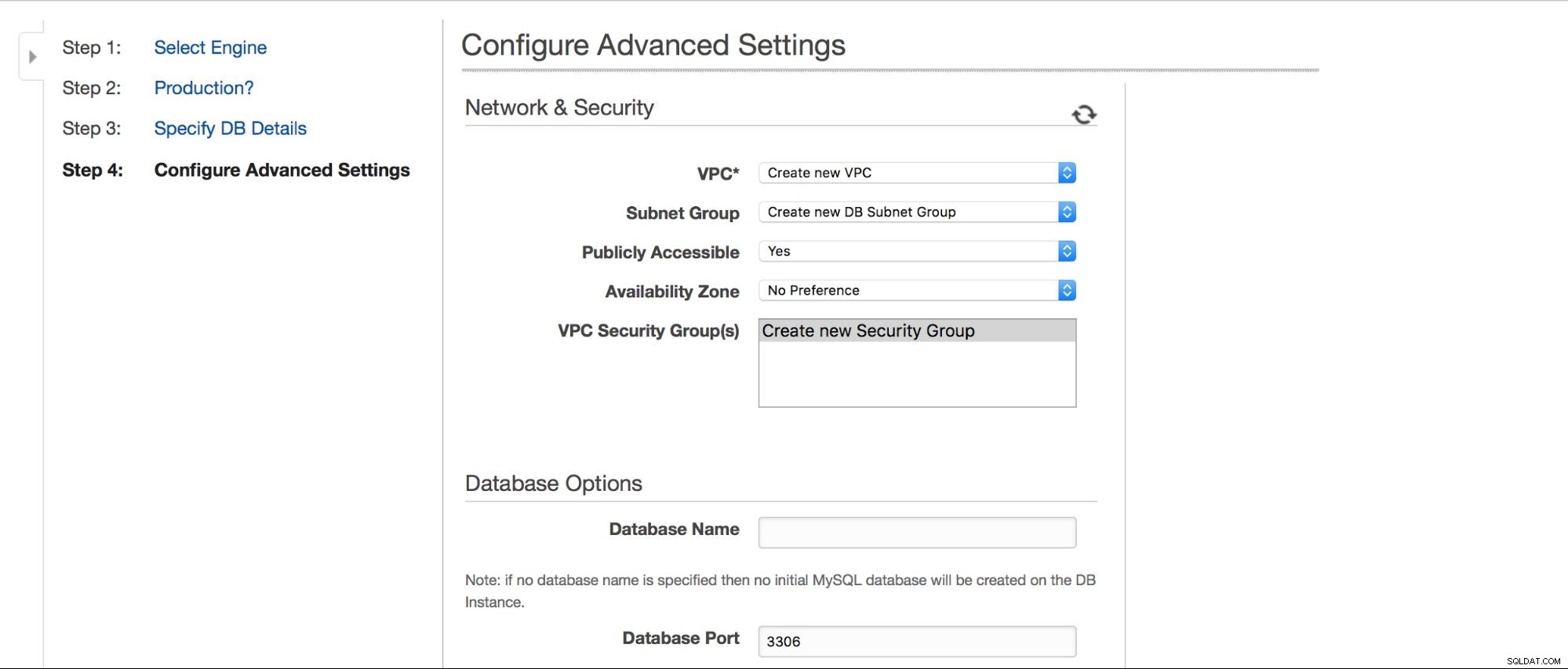
Podemos escolher onde a instância deve ser criada:VPC, sub-rede, se está disponível publicamente ou não (como em - se um IP público deve ser atribuído à instância do RDS), zona de disponibilidade e grupo de segurança da VPC. Então, temos as opções de banco de dados:primeiro esquema a ser criado, porta, grupos de parâmetros e opções, se tags de metadados devem ser incluídas em snapshots ou não, configurações de criptografia.
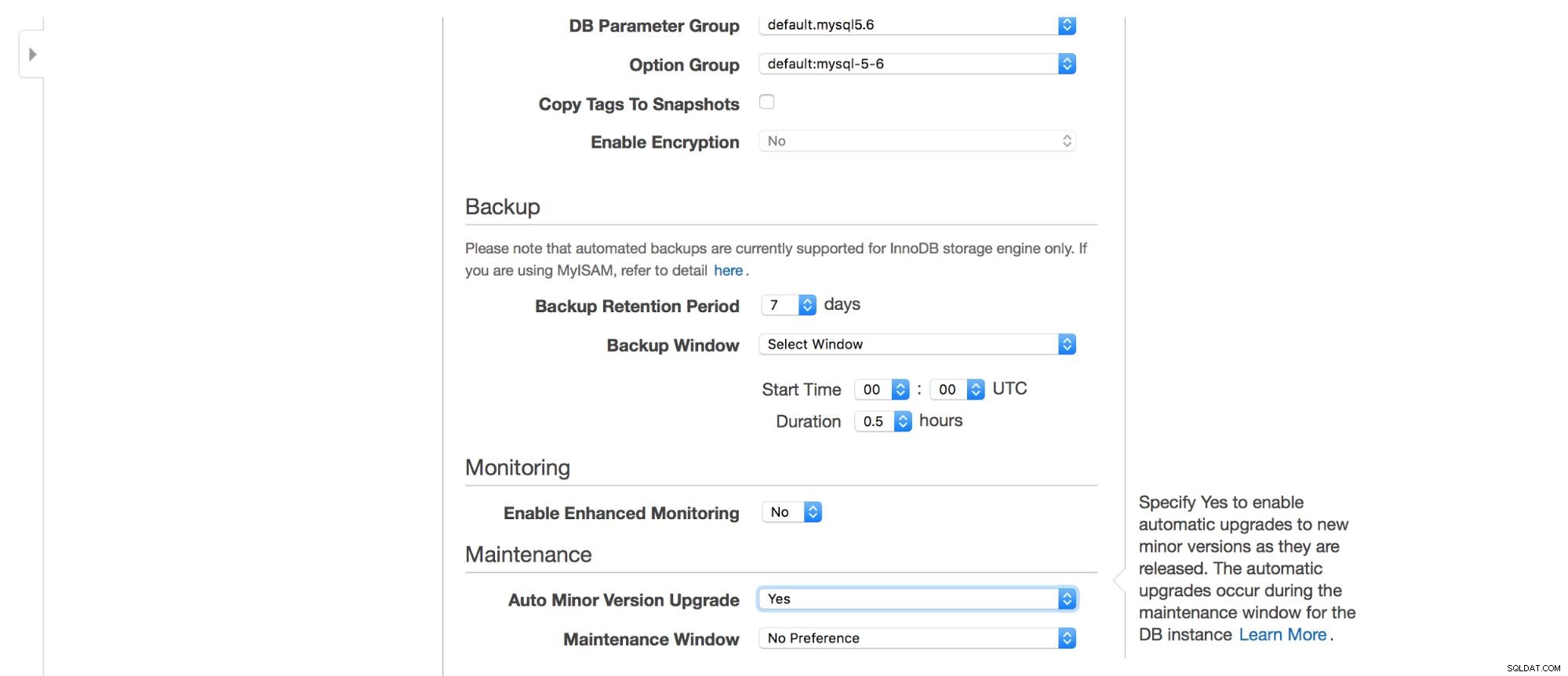
Em seguida, opções de backup - por quanto tempo você deseja manter seus backups? Quando você gostaria que eles fossem levados? Uma configuração semelhante está relacionada a manutenções - às vezes, os administradores da Amazon precisam realizar manutenção em sua instância do RDS - isso acontecerá dentro de uma janela predefinida que você pode definir aqui. Observe que não há opção de não escolher pelo menos 30 minutos para a janela de manutenção, é por isso que ter uma instância multi-AZ em produção é realmente importante. A manutenção pode resultar na reinicialização do nó ou falta de disponibilidade por algum tempo. Sem multi-AZ, você precisa aceitar esse tempo de inatividade. Com a implantação multi-AZ, ocorre o failover.
Por fim, temos configurações relacionadas ao monitoramento adicional - queremos habilitá-lo ou não?
Gerenciando RDS
Neste capítulo, veremos mais de perto como gerenciar o MySQL RDS. Não passaremos por todas as opções disponíveis, mas gostaríamos de destacar alguns dos recursos que a Amazon disponibilizou.
Fotos
O MySQL RDS usa volumes do EBS como armazenamento, portanto, pode usar instantâneos do EBS para diferentes propósitos. Backups, escravos - todos baseados em instantâneos. Você pode criar instantâneos manualmente ou eles podem ser tirados automaticamente, quando houver necessidade. É importante ter em mente que os snapshots do EBS, em geral (não apenas em instâncias RDS), adicionam alguma sobrecarga às operações de E/S. Se você quiser tirar um instantâneo, espere que seu desempenho de E/S caia. A menos que você use a implantação multi-AZ. Nesse caso, a instância “sombra” será usada como fonte de instantâneos e nenhum impacto será visível na instância de produção.
Guia de DevOps para gerenciamento de banco de dados de vários novesSaiba mais sobre o que você precisa saber para automatizar e gerenciar seus bancos de dados de código abertoBaixe gratuitamente
Backups
Os backups são baseados em instantâneos. Conforme mencionado acima, você pode definir seu agendamento e retenção de backup ao criar uma nova instância. Claro, você pode editar essas configurações posteriormente, através da opção “modificar instância”.
A qualquer momento, você pode restaurar um instantâneo - você precisa ir para a seção de instantâneos, escolher o instantâneo que deseja restaurar e será apresentada uma caixa de diálogo semelhante à que você viu quando criou uma nova instância. Isso não é uma surpresa, pois você só pode restaurar um instantâneo em uma nova instância - não há como restaurá-lo em uma das instâncias RDS existentes. Pode ser uma surpresa, mas mesmo em ambiente de nuvem, pode fazer sentido reutilizar hardware (e instâncias que você já possui). Em um ambiente compartilhado, o desempenho de uma única instância virtual pode ser diferente - você pode preferir manter o perfil de desempenho com o qual já está familiarizado. Infelizmente, não é possível no RDS.
Outra opção no RDS é a recuperação pontual – recurso muito importante, requisito para quem precisa cuidar bem de seus dados. Aqui as coisas são mais complexas e menos brilhantes. Para começar, é importante ter em mente que o MySQL RDS oculta os logs binários do usuário. Você pode alterar algumas configurações e listar os binlogs criados, mas não tem acesso direto a eles - para fazer qualquer operação, incluindo usá-los para recuperação, você só pode usar a interface do usuário ou CLI. Isso limita suas opções ao que a Amazon permite que você faça e permite que você restaure seu backup até o último “tempo restaurável” que é calculado em um intervalo de 5 minutos. Portanto, se seus dados foram removidos às 9h33, você poderá restaurá-los apenas até o estado às 9h30. A recuperação pontual funciona da mesma maneira que a restauração de instantâneos - uma nova instância é criada.
Escalonamento, replicação
MySQL RDS permite expansão através da adição de novos escravos. Quando um escravo é criado, um instantâneo do mestre é tirado e usado para criar um novo host. Essa parte funciona muito bem. Infelizmente, você não pode criar nenhuma topologia de replicação mais complexa como uma envolvendo mestres intermediários. Você não pode criar uma configuração mestre-mestre, o que deixa qualquer HA nas mãos da Amazon (e implantações multi-AZ). Pelo que podemos dizer, não há como habilitar o GTID (não que você possa se beneficiar dele, pois não tem controle sobre a replicação, nem CHANGE MASTER no RDS), apenas posições regulares e antiquadas de log binário.
A falta de GTID torna inviável o uso de replicação multithread - embora seja possível definir um número de trabalhadores usando grupos de parâmetros RDS, sem GTID isso é inutilizável. O principal problema é que não há como localizar uma única posição de log binário em caso de falha - alguns trabalhadores podem estar atrasados, outros podem ser mais avançados. Se você usar o evento aplicado mais recente, perderá dados que ainda não foram aplicados por esses trabalhadores “atrasados”. Se você usar o evento mais antigo, provavelmente acabará com erros de “chave duplicada” causados por eventos aplicados por aqueles trabalhadores mais avançados. Claro, existe uma maneira de resolver esse problema, mas não é trivial e demorado - definitivamente não é algo que você possa automatizar facilmente.
Os usuários criados no MySQL RDS não têm privilégio SUPER, então as operações, que são simples no MySQL autônomo, não são triviais no RDS. A Amazon decidiu usar procedimentos armazenados para capacitar o usuário a fazer algumas dessas operações. Pelo que podemos dizer, vários problemas em potencial são abordados, embora nem sempre tenha sido o caso - lembramos quando você não podia alternar para o próximo log binário no mestre. Uma falha de mestre + corrupção de log binário pode tornar todos os escravos quebrados - agora existe um procedimento para isso:rds_next_master_log .
Um escravo pode ser promovido manualmente a um mestre. Isso permitiria que você criasse algum tipo de HA em cima do mecanismo multi-AZ (ou ignorando-o), mas tornou-se inútil pelo fato de você não poder reescravizar nenhum dos escravos existentes para o novo mestre. Lembre-se, você não tem nenhum controle sobre a replicação. Isso torna todo o exercício fútil - a menos que seu mestre possa acomodar todo o seu tráfego. Depois de promover um novo mestre, você não poderá fazer failover para ele porque ele não possui escravos para lidar com sua carga. A geração de novos escravos levará tempo, pois os instantâneos do EBS precisam ser criados primeiro e isso pode levar horas. Então, você precisa aquecer a infraestrutura antes de colocar carga nela.
Falta de privilégio SUPER
Como dissemos anteriormente, o RDS não concede privilégios SUPER aos usuários e isso se torna irritante para quem está acostumado a tê-lo no MySQL. Tenha como certo que, nas primeiras semanas, você aprenderá com que frequência é necessário fazer coisas que você faz com bastante frequência - como eliminar consultas ou operar o esquema de desempenho. No RDS, você terá que se ater a uma lista predefinida de procedimentos armazenados e usá-los em vez de fazer as coisas diretamente. Você pode listar todos eles usando a seguinte consulta:
SELECT specific_name FROM information_schema.routines;Assim como na replicação, várias tarefas são cobertas, mas se você acabou em uma situação que ainda não foi coberta, não terá sorte.
Interoperabilidade e configurações de nuvem híbrida
Esta é outra área em que o RDS não tem flexibilidade. Digamos que você queira criar uma configuração mista de nuvem/local - você tem uma infraestrutura RDS e gostaria de criar alguns escravos no local. O principal problema que você enfrentará é que não há como mover dados do RDS, exceto fazer um dump lógico. Você pode tirar instantâneos de dados do RDS, mas não tem acesso a eles e não pode movê-los para fora da AWS. Você também não tem acesso físico à instância para usar xtrabackup, rsync ou mesmo cp. A única opção para você é usar mysqldump, mydumper ou ferramentas semelhantes. Isso adiciona complexidade (conjunto de caracteres e configurações de agrupamento podem causar problemas) e é demorado (leva muito tempo para despejar e carregar dados usando ferramentas de backup lógicas).
É possível configurar a replicação entre o RDS e uma instância externa (nos dois sentidos, portanto, a migração de dados para o RDS também é possível), mas pode ser um processo muito demorado.
Por outro lado, se você deseja permanecer em um ambiente RDS e abranger sua infraestrutura em todo o Atlântico ou da costa leste a oeste dos EUA, o RDS permite que você faça isso - você pode facilmente escolher uma região ao criar um novo escravo.
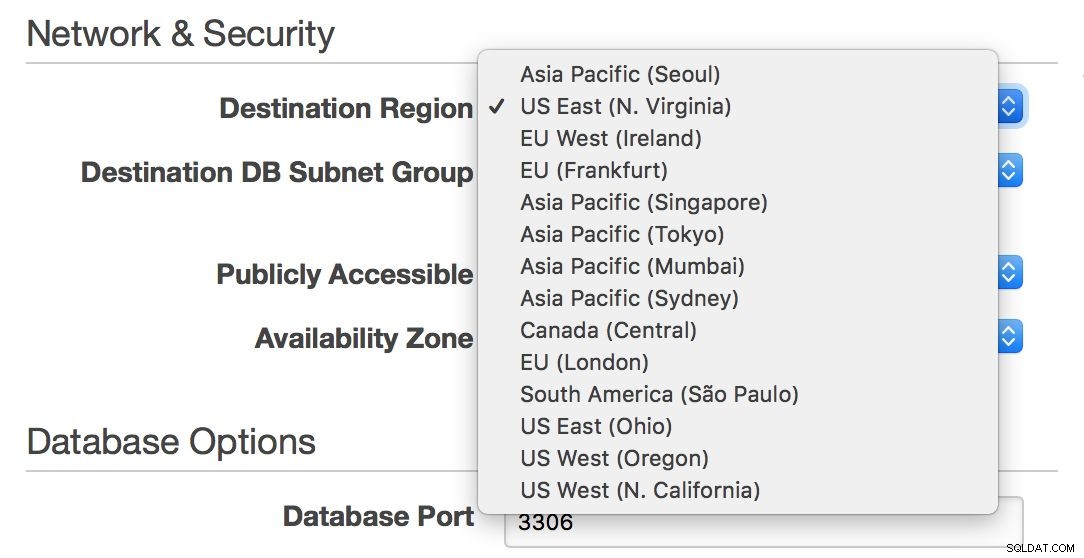
Infelizmente, se você quiser mover seu mestre de uma região para outra, isso praticamente não é possível sem tempo de inatividade - a menos que seu único nó possa lidar com todo o seu tráfego.
Segurança
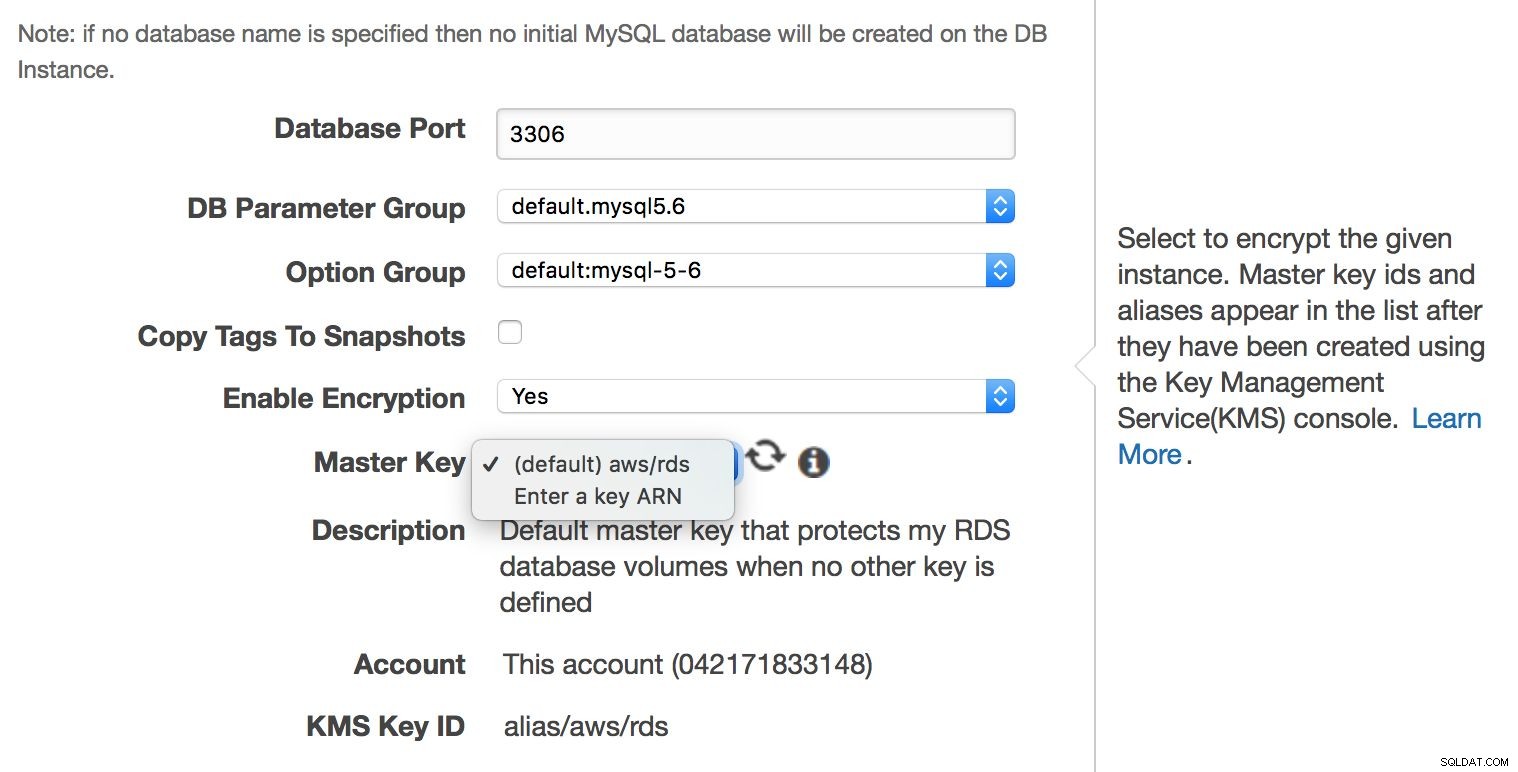
Embora o MySQL RDS seja um serviço gerenciado, nem todos os aspectos relacionados à segurança são atendidos pelos engenheiros da Amazon. A Amazon chama isso de “Modelo de Responsabilidade Compartilhada”. Resumindo, a Amazon cuida da segurança da rede e da camada de armazenamento (para que os dados sejam transferidos de forma segura), sistema operacional (patches, correções de segurança). Por outro lado, o usuário deve cuidar do restante do modelo de segurança. Certifique-se de que o tráfego de e para a instância do RDS seja limitado na VPC, certifique-se de que a autenticação no nível do banco de dados seja feita corretamente (sem contas de usuário MySQL sem senha), verifique se a segurança da API está garantida (as AMIs estão configuradas corretamente e com privilégios mínimos necessários). O usuário também deve cuidar das configurações do firewall (grupos de segurança) para minimizar a exposição do RDS e da VPC a redes externas. Também é responsabilidade do usuário implementar a criptografia de dados em repouso - seja no nível do aplicativo ou no nível do banco de dados, criando uma instância RDS criptografada em primeiro lugar.
A criptografia em nível de banco de dados pode ser habilitada apenas na criação da instância, você não pode criptografar um banco de dados existente já em execução.
Limitações do RDS
Se você planeja usar o RDS ou se já o estiver usando, precisa estar ciente das limitações que acompanham o MySQL RDS.
Falta de privilégio SUPER pode ser, como mencionamos, muito irritante. Embora os procedimentos armazenados cuidem de várias operações, é uma curva de aprendizado, pois você precisa aprender a fazer as coisas de uma maneira diferente. A falta do privilégio SUPER também pode criar problemas no uso de ferramentas externas de monitoramento e tendências - ainda existem algumas ferramentas que podem exigir esse privilégio para alguma parte de sua funcionalidade.
A falta de acesso direto ao diretório de dados e logs do MySQL dificulta a execução de ações que os envolve. Acontece de vez em quando que um DBA precisa analisar logs binários ou erro de cauda, consulta lenta ou log geral. Embora seja possível acessar esses logs no RDS, é mais complicado do que fazer o que você precisa fazendo login no shell no host MySQL. O download local também leva algum tempo e adiciona latência adicional a tudo o que você faz.
Falta de controle sobre a topologia de replicação, alta disponibilidade apenas em implantações multi-AZ. Como você não tem controle sobre a replicação, não pode implementar nenhum tipo de mecanismo de alta disponibilidade em sua camada de banco de dados. Não importa que você tenha vários escravos, você não pode usar alguns deles como candidatos a mestre, porque mesmo que você promova um escravo a mestre, não há como rescravizar os escravos restantes desse novo mestre. Isso força os usuários a usar implantações multi-AZ e aumentar os custos (a instância “sombra” não é gratuita, o usuário tem que pagar por isso).
Disponibilidade reduzida devido ao tempo de inatividade planejado. Ao implantar uma instância do RDS, você é forçado a escolher uma janela de tempo semanal de 30 minutos durante a qual as operações de manutenção podem ser executadas em sua instância do RDS. Por um lado, isso é compreensível, pois o RDS é um banco de dados como serviço, de modo que as atualizações de hardware e software de suas instâncias do RDS são gerenciadas por engenheiros da AWS. Por outro lado, isso reduz sua disponibilidade porque você não pode impedir que seu banco de dados mestre fique inativo durante o período de manutenção. Novamente, nesse caso, o uso da configuração multi-AZ aumenta a disponibilidade, pois as alterações ocorrem primeiro na instância de sombra e, em seguida, o failover é executado. O failover em si, no entanto, não é transparente, então, de uma forma ou de outra, você perde o tempo de atividade. Isso força você a projetar seu aplicativo com falhas inesperadas do mestre MySQL em mente. Não que seja um padrão de design ruim - os bancos de dados podem travar a qualquer momento e seu aplicativo deve ser construído de uma maneira que possa suportar até mesmo o cenário mais terrível. É só que com o RDS, você tem opções limitadas para alta disponibilidade.
Opções reduzidas para implementação de alta disponibilidade. Dada a falta de flexibilidade no gerenciamento de topologia de replicação, o único método viável de alta disponibilidade é a implantação multi-AZ. Este método é bom, mas existem ferramentas para replicação do MySQL que minimizariam ainda mais o tempo de inatividade. Por exemplo, MHA ou ClusterControl, quando usado em conexão com ProxySQL, pode fornecer (sob algumas condições, como falta de transações de longa duração) um processo de failover transparente para o aplicativo. Enquanto estiver no RDS, você não poderá usar esse método.
Percepção reduzida sobre o desempenho do seu banco de dados. Embora você possa obter métricas do próprio MySQL, às vezes não é suficiente obter uma visão completa de 10 mil pés da situação. Em algum momento, a maioria dos usuários terá que lidar com problemas realmente estranhos causados por hardware defeituoso ou infraestrutura defeituosa - pacotes de rede perdidos, conexões encerradas abruptamente ou utilização inesperadamente alta da CPU. Quando você tem acesso ao seu host MySQL, você pode aproveitar muitas ferramentas que o ajudam a diagnosticar o estado de um servidor Linux. Ao usar o RDS, você fica limitado a quais métricas estão disponíveis no Cloudwatch, a ferramenta de monitoramento e tendências da Amazon. Qualquer diagnóstico mais detalhado requer entrar em contato com o suporte e solicitar que verifiquem e corrijam o problema. Isso pode ser rápido, mas também pode ser um processo muito longo, com muita comunicação por e-mail.
Bloqueio de fornecedor causado pelo processo complexo e demorado de obter dados do MySQL RDS. O RDS não concede acesso ao diretório de dados do MySQL, portanto, não há como utilizar ferramentas padrão do setor, como xtrabackup, para mover dados de maneira binária. Por outro lado, o RDS sob o capô é um MySQL mantido pela Amazon, é difícil dizer se é 100% compatível com upstream ou não. O RDS está disponível apenas na AWS, portanto, você não poderá fazer uma configuração híbrida.
Resumo
MySQL RDS tem pontos fortes e fracos. Esta é uma ferramenta muito boa para quem deseja focar na aplicação sem ter que se preocupar em operar o banco de dados. Você implanta um banco de dados e começa a emitir consultas. Não há necessidade de criar scripts de backup ou configurar solução de monitoramento porque já é feito por engenheiros da AWS - tudo o que você precisa fazer é usá-lo.
Há também um lado escuro do MySQL RDS. Falta de opções para construir configurações mais complexas e dimensionar fora de apenas adicionar mais escravos. Falta de suporte para melhor alta disponibilidade do que o proposto em implantações multi-AZ. Acesso complicado aos logs do MySQL. Falta de acesso direto ao diretório de dados do MySQL e falta de suporte para backups físicos, o que dificulta a movimentação dos dados para fora da instância do RDS.
Para resumir, o RDS pode funcionar bem para você se você valoriza a facilidade de uso sobre o controle detalhado do banco de dados. Você precisa ter em mente que, em algum momento no futuro, você pode superar o MySQL RDS. Não estamos necessariamente falando aqui apenas de desempenho. É mais sobre as necessidades de sua organização para uma topologia de replicação mais complexa ou uma necessidade de ter uma melhor percepção das operações do banco de dados para lidar rapidamente com diferentes problemas que surgem de tempos em tempos. Nesse caso, se seu conjunto de dados já tiver aumentado de tamanho, pode ser difícil sair do RDS. Antes de tomar qualquer decisão de mover seus dados para o RDS, os gerentes de informações devem considerar os requisitos e restrições de sua organização em áreas específicas.
Nas próximas postagens do blog, mostraremos como levar seus dados do RDS para um local separado. Discutiremos a migração para o EC2 e para a infraestrutura local.