“Mas funcionou bem em nosso servidor de desenvolvimento!”
Quantas vezes eu ouvi quando problemas de desempenho de consulta SQL ocorreram aqui e ali? Eu mesmo disse isso no passado. Presumi que uma consulta executada em menos de um segundo funcionaria bem em servidores de produção. Mas eu estava errado.
Você pode se relacionar com essa experiência? Se você ainda está neste barco hoje por qualquer motivo, este post é para você. Ele fornecerá uma métrica melhor para ajustar o desempenho da consulta SQL. Vamos falar sobre três das figuras mais críticas em STATISTICS IO.
Como exemplo, usaremos o banco de dados de exemplo AdventureWorks.
Antes de começar a executar as consultas abaixo, ative STATISTICS IO. Veja como fazer isso em uma janela de consulta:
USE AdventureWorks
GO
SET STATISTICS IO ONDepois de executar uma consulta com STATISTICS IO ON, mensagens diferentes aparecerão. Você pode vê-los na guia Mensagens da janela de consulta no SQL Server Management Studio (consulte a Figura 1):
Agora que terminamos a introdução curta, vamos nos aprofundar.
1. Altas leituras lógicas
O primeiro ponto em nossa lista é o culpado mais comum – leituras lógicas altas.
As leituras lógicas são o número de páginas lidas do cache de dados. Uma página tem 8 KB de tamanho. O cache de dados, por outro lado, refere-se à RAM usada pelo SQL Server.
As leituras lógicas são cruciais para o ajuste de desempenho. Esse fator define quanto um SQL Server precisa para produzir o conjunto de resultados necessário. Portanto, a única coisa a lembrar é:quanto mais altas forem as leituras lógicas, mais tempo o SQL Server precisará funcionar. Isso significa que sua consulta será mais lenta. Reduza o número de leituras lógicas e você aumentará o desempenho da consulta.
Mas por que usar leituras lógicas em vez de tempo decorrido?
- O tempo decorrido depende de outras coisas feitas pelo servidor, não apenas da sua consulta.
- O tempo decorrido pode mudar do servidor de desenvolvimento para o servidor de produção. Isso acontece quando os dois servidores têm capacidades e configurações de hardware e software diferentes.
Confiar no tempo decorrido fará com que você diga:“Mas funcionou bem em nosso servidor de desenvolvimento!” cedo ou tarde.
Por que usar leituras lógicas em vez de leituras físicas?
- As leituras físicas são o número de páginas lidas dos discos para o cache de dados (na memória). Uma vez que as páginas necessárias em uma consulta estejam no cache de dados, não há necessidade de relê-las dos discos.
- Quando a mesma consulta for executada novamente, as leituras físicas serão zero.
As leituras lógicas são a escolha lógica para ajustar o desempenho da consulta SQL.
Para ver isso em ação, vamos a um exemplo.
Exemplo de leituras lógicas
Suponha que você precise obter a lista de clientes com pedidos enviados no último dia 11 de julho de 2011. Você tem a seguinte consulta bastante simples:
SELECT
d.FirstName
,d.MiddleName
,d.LastName
,d.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM Sales.SalesOrderHeader a
INNER JOIN Sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'É direto. Esta consulta terá a seguinte saída:

Em seguida, você verifica o resultado STATISTICS IO desta consulta:

A saída mostra as leituras lógicas de cada uma das quatro tabelas usadas na consulta. No total, a soma das leituras lógicas é 729. Você também pode ver as leituras físicas com uma soma total de 21. No entanto, tente executar novamente a consulta e ela será zero.
Dê uma olhada nas leituras lógicas de SalesOrderHeader . Você quer saber por que ele tem 689 leituras lógicas? Talvez você tenha pensado em inspecionar o plano de execução da consulta abaixo:
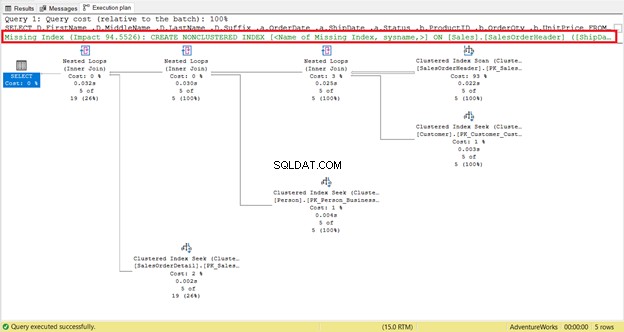
Por um lado, há uma verificação de índice que aconteceu em SalesOrderHeader com um custo de 93%. O que poderia estar acontecendo? Suponha que você verificou suas propriedades:
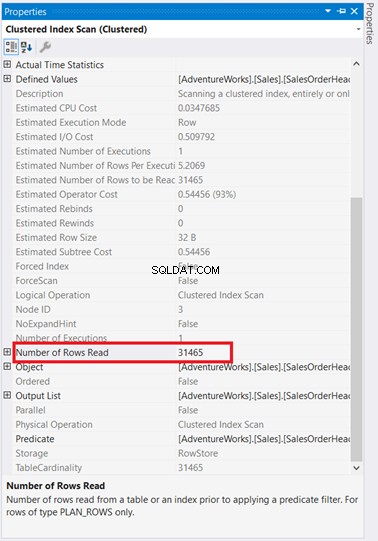
Uau! 31.465 linhas lidas para apenas 5 linhas retornadas? É um absurdo!
Reduzindo o número de leituras lógicas
Não é tão difícil diminuir essas 31.465 linhas lidas. O SQL Server já nos deu uma pista. Prossiga para o seguinte:
ETAPA 1:siga a recomendação do SQL Server e adicione o índice ausente
Você notou a recomendação de índice ausente no plano de execução (Figura 4)? Isso resolverá o problema?
Há uma maneira de descobrir:
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader_ShipDate]
ON [Sales].[SalesOrderHeader] ([ShipDate])Execute novamente a consulta e veja as alterações nas leituras lógicas STATISTICS IO.

Como você pode ver em STATISTICS IO (Figura 6), há uma tremenda diminuição nas leituras lógicas de 689 para 17. As novas leituras lógicas gerais são 57, o que é uma melhoria significativa de 729 leituras lógicas. Mas para ter certeza, vamos inspecionar o plano de execução novamente.
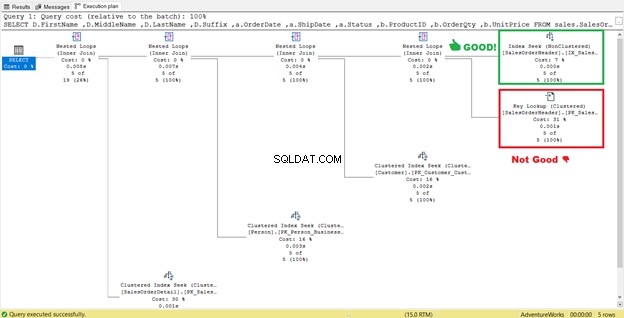
Parece que há uma melhoria no plano, resultando em leituras lógicas reduzidas. A varredura de índice agora é uma busca de índice. O SQL Server não precisará mais inspecionar linha por linha para obter os registros com o Shipdate='07/11/2011′ . Mas algo ainda está à espreita nesse plano, e não está certo.
Você precisa do passo 2.
ETAPA 2:altere o índice e adicione às colunas incluídas:OrderDate, Status e CustomerID
Você vê o operador Key Lookup no plano de execução (Figura 7)? Isso significa que o índice não clusterizado criado não é suficiente – o processador de consultas precisa usar o índice clusterizado novamente.
Vamos verificar suas propriedades.
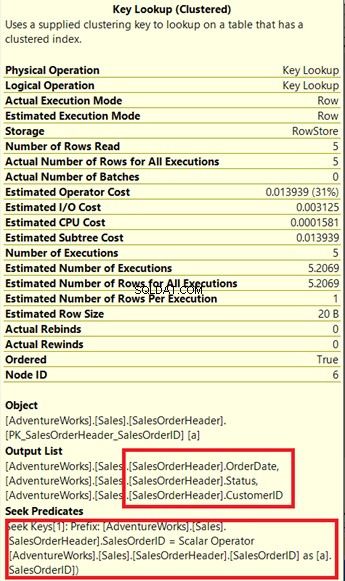
Observe a caixa anexada na Lista de saída . Acontece que precisamos de OrderDate , Estado e CustomerID no conjunto de resultados. Para obter esses valores, o processador de consultas usou o índice clusterizado (consulte Procurar predicados ) para chegar à mesa.
Precisamos remover essa pesquisa de chave. A solução é incluir a OrderDate , Estado e CustomerID colunas no índice criado anteriormente.
- Clique com o botão direito do mouse em IX_SalesOrderHeader_ShipDate no SSMS.
- Selecione Propriedades .
- Clique nas colunas incluídas guia.
- Adicionar Data do pedido , Estado e CustomerID .
- Clique em OK .
Depois de recriar o índice, execute novamente a consulta. Isso removerá a Pesquisa de chave e reduzir as leituras lógicas?

Funcionou! De 17 leituras lógicas para 2 (Figura 9).
E a Pesquisa de chave ?
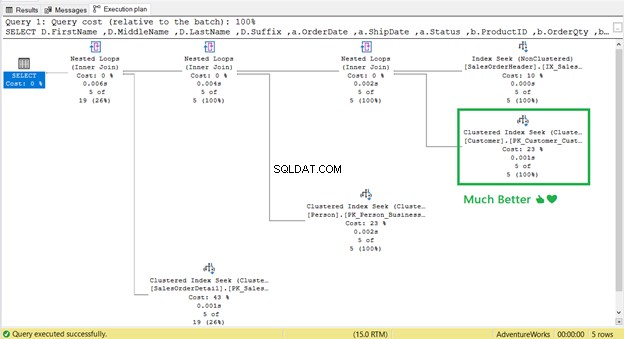
Foi-se! Pesquisa de índice agrupado substituiu a pesquisa de chave.
A lição
Então, o que aprendemos?
Uma das principais maneiras de reduzir as leituras lógicas e melhorar o desempenho da consulta SQL é criar um índice apropriado. Mas há uma pegadinha. Em nosso exemplo, reduziu as leituras lógicas. Às vezes, o oposto estará certo. Isso também pode afetar o desempenho de outras consultas relacionadas.
Portanto, verifique sempre o STATISTICS IO e o plano de execução após a criação do índice.
2. Leituras Lógicas de Lob Alto
É muito parecido com o ponto 1, mas lidará com tipos de dados texto , ntext , imagem , varchar (máximo ), nvarchar (máximo ), varbinário (máximo ) ou colunas páginas de índice.
Vamos nos referir a um exemplo:gerar leituras lógicas de lob.
Exemplo de leituras lógicas de Lob
Suponha que você queira exibir um produto com seu preço, cor, imagem em miniatura e uma imagem maior em uma página da web. Assim, você cria uma consulta inicial como a mostrada abaixo:
SELECT
a.ProductID
,a.Name AS ProductName
,a.ListPrice
,a.Color
,b.Name AS ProductSubcategory
,d.ThumbNailPhoto
,d.LargePhoto
FROM Production.Product a
INNER JOIN Production.ProductSubcategory b ON a.ProductSubcategoryID = b.ProductSubcategoryID
INNER JOIN Production.ProductProductPhoto c ON a.ProductID = c.ProductID
INNER JOIN Production.ProductPhoto d ON c.ProductPhotoID = d.ProductPhotoID
WHERE b.ProductCategoryID = 1 -- Bikes
ORDER BY ProductSubcategory, ProductName, a.ColorEntão, você o executa e vê a saída como a abaixo:

Como você é um cara (ou garota) de alto desempenho, você verifica imediatamente o STATISTICS IO. Aqui está:

Parece um pouco de sujeira em seus olhos. 665 lob leituras lógicas? Você não pode aceitar isso. Sem mencionar 194 leituras lógicas de cada ProductPhoto e ProductProductPhoto mesas. Você realmente acha que essa consulta precisa de algumas mudanças.
Reduzindo leituras lógicas de Lob
A consulta anterior teve 97 linhas retornadas. Todas as 97 motos. Você acha que isso é bom para exibir em uma página da web?
Um índice pode ajudar, mas por que não simplificar a consulta primeiro? Dessa forma, você pode ser seletivo sobre o que o SQL Server retornará. Você pode reduzir as leituras lógicas do lob.
- Adicione um filtro para a subcategoria do produto e deixe o cliente escolher. Em seguida, inclua isso na cláusula WHERE.
- Remova a ProductSubcategory coluna, pois você adicionará um filtro para a subcategoria do produto.
- Remova a Foto grande coluna. Consulte isso quando o usuário selecionar um produto específico.
- Use paginação. O cliente não poderá ver todas as 97 bicicletas de uma vez.
Com base nessas operações descritas acima, alteramos a consulta da seguinte forma:
- Remover ProductSubcategory e Foto grande colunas do conjunto de resultados.
- Use OFFSET e FETCH para acomodar a paginação na consulta. Consulte apenas 10 produtos por vez.
- Adicionar ProductSubcategoryID na cláusula WHERE com base na seleção do cliente.
- Remova a ProductSubcategory coluna na cláusula ORDER BY.
A consulta agora será semelhante a esta:
DECLARE @pageNumber TINYINT
DECLARE @noOfRows TINYINT = 10 -- each page will display 10 products at a time
SELECT
a.ProductID
,a.Name AS ProductName
,a.ListPrice
,a.Color
,d.ThumbNailPhoto
FROM Production.Product a
INNER JOIN Production.ProductSubcategory b ON a.ProductSubcategoryID = b.ProductSubcategoryID
INNER JOIN Production.ProductProductPhoto c ON a.ProductID = c.ProductID
INNER JOIN Production.ProductPhoto d ON c.ProductPhotoID = d.ProductPhotoID
WHERE b.ProductCategoryID = 1 -- Bikes
AND a.ProductSubcategoryID = 2 -- Road Bikes
ORDER BY ProductName, a.Color
OFFSET (@pageNumber-1)*@noOfRows ROWS FETCH NEXT @noOfRows ROWS ONLY
-- change the OFFSET and FETCH values based on what page the user is.Com as alterações feitas, as leituras lógicas do lob melhorarão? STATISTICS IO agora informa:

Foto do produto A tabela agora tem leituras lógicas de 0 lob – de 665 leituras lógicas de lob para nenhuma. Isso é alguma melhoria.
Para levar
Uma das maneiras de reduzir as leituras lógicas do lob é reescrever a consulta para simplificá-la.
Remova as colunas desnecessárias e reduza as linhas retornadas ao mínimo necessário. Quando necessário, use OFFSET e FETCH para paginação.
Para garantir que as alterações de consulta tenham leituras lógicas de lob aprimoradas e o desempenho da consulta SQL, sempre verifique STATISTICS IO.
3. Altas leituras lógicas da tabela de trabalho/arquivo de trabalho
Por fim, são leituras lógicas de Worktable e Arquivo de trabalho . Mas o que são essas tabelas? Por que eles aparecem quando você não os usa em sua consulta?
Ter mesa de trabalho e Arquivo de trabalho aparecer no STATISTICS IO significa que o SQL Server precisa de muito mais trabalho para obter os resultados desejados. Ele recorre ao uso de tabelas temporárias em tempdb , ou seja, Tabelas de trabalho e Arquivos de trabalho . Não é necessariamente prejudicial tê-los na saída STATISTICS IO, desde que as leituras lógicas sejam zero e não causem problemas ao servidor.
Essas tabelas podem aparecer quando houver ORDER BY, GROUP BY, CROSS JOIN, ou DISTINCT, entre outros.
Exemplo de leituras lógicas de tabela de trabalho/arquivo de trabalho
Suponha que você precise consultar todas as lojas sem vendas de determinados produtos.
Você inicialmente vem com o seguinte:
SELECT DISTINCT
a.SalesPersonID
,b.ProductID
,ISNULL(c.OrderTotal,0) AS OrderTotal
FROM Sales.Store a
CROSS JOIN Production.Product b
LEFT JOIN (SELECT
b.SalesPersonID
,a.ProductID
,SUM(a.LineTotal) AS OrderTotal
FROM Sales.SalesOrderDetail a
INNER JOIN Sales.SalesOrderHeader b ON a.SalesOrderID = b.SalesOrderID
WHERE b.SalesPersonID IS NOT NULL
GROUP BY b.SalesPersonID, a.ProductID, b.OrderDate) c ON a.SalesPersonID
= c.SalesPersonID
AND b.ProductID = c.ProductID
WHERE c.OrderTotal IS NULL
ORDER BY a.SalesPersonID, b.ProductIDEsta consulta retornou 3.649 linhas:
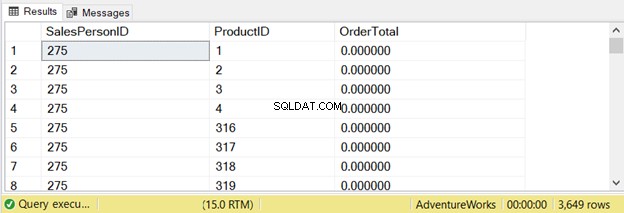
Vamos verificar o que o STATISTICS IO diz:

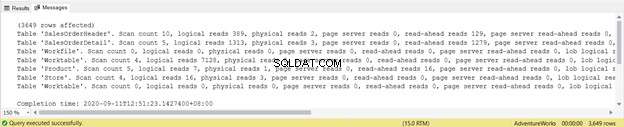
Vale a pena notar que a Tabela de trabalho as leituras lógicas são 7128. As leituras lógicas gerais são 8853. Se você verificar o plano de execução, verá muitos paralelismos, correspondências de hash, spools e varreduras de índice.
Reduzindo leituras lógicas da tabela de trabalho/arquivo de trabalho
Não consegui construir uma única instrução SELECT com um resultado satisfatório. Assim, a única opção é dividir a instrução SELECT em várias consultas. Ver abaixo:
SELECT DISTINCT
a.SalesPersonID
,b.ProductID
INTO #tmpStoreProducts
FROM Sales.Store a
CROSS JOIN Production.Product b
SELECT
b.SalesPersonID
,a.ProductID
,SUM(a.LineTotal) AS OrderTotal
INTO #tmpProductOrdersPerSalesPerson
FROM Sales.SalesOrderDetail a
INNER JOIN Sales.SalesOrderHeader b ON a.SalesOrderID = b.SalesOrderID
WHERE b.SalesPersonID IS NOT NULL
GROUP BY b.SalesPersonID, a.ProductID
SELECT
a.SalesPersonID
,a.ProductID
FROM #tmpStoreProducts a
LEFT JOIN #tmpProductOrdersPerSalesPerson b ON a.SalesPersonID = b.SalesPersonID AND
a.ProductID = b.ProductID
WHERE b.OrderTotal IS NULL
ORDER BY a.SalesPersonID, a.ProductID
DROP TABLE #tmpProductOrdersPerSalesPerson
DROP TABLE #tmpStoreProductsÉ várias linhas mais longa e usa tabelas temporárias. Agora, vamos ver o que o STATISTICS IO revela:
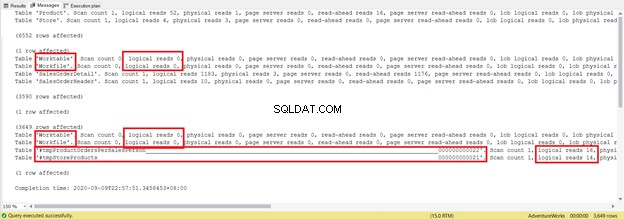
Tente não se concentrar na duração do relatório estatístico – é apenas frustrante. Em vez disso, adicione leituras lógicas de cada tabela.
Para um total de 1.279, é uma diminuição significativa, pois foram 8.853 leituras lógicas da única instrução SELECT.
Não adicionamos nenhum índice às tabelas temporárias. Você pode precisar de um se muitos mais registros forem adicionados a SalesOrderHeader e Detalhes do pedido de vendas . Mas você entendeu o ponto.
Para levar
Às vezes, 1 instrução SELECT parece boa. No entanto, nos bastidores, o oposto é verdadeiro. Tabelas de trabalho e Arquivos de trabalho com altas leituras lógicas retardam o desempenho da consulta SQL.
Se você não consegue pensar em outra maneira de reconstruir a consulta e os índices são inúteis, tente a abordagem “dividir e conquistar”. As Tabelas de trabalho e Arquivos de trabalho ainda pode aparecer na guia Mensagem do SSMS, mas as leituras lógicas serão zero. Portanto, o resultado geral será leituras menos lógicas.
O resultado final no desempenho de consultas SQL e E/S de ESTATÍSTICAS
Qual é o grande problema com essas 3 estatísticas desagradáveis de E/S?
A diferença no desempenho da consulta SQL será como noite e dia se você prestar atenção a esses números e reduzi-los. Apresentamos apenas algumas maneiras de reduzir leituras lógicas como:
- criar índices apropriados;
- simplificando consultas – removendo colunas desnecessárias e minimizando o conjunto de resultados;
- dividir uma consulta em várias consultas.
Há mais como atualizar estatísticas, desfragmentar índices e definir o FILLFACTOR correto. Você pode adicionar mais a isso na seção de comentários?
Se você gostou deste post, compartilhe-o em suas redes sociais favoritas.



