No mundo do SQL Server, existem dois tipos de pessoas:aquelas que gostam que todos os seus objetos sejam prefixados e aquelas que não gostam. O primeiro grupo é dividido em duas categorias:aqueles que prefixam procedimentos armazenados com
sp_ , e aqueles que escolhem outros prefixos (como usp_ ou proc_ ). Uma recomendação de longa data é evitar o sp_ prefixo, tanto por motivos de desempenho quanto para evitar ambiguidade ou colisões se você escolher um nome que já existe no catálogo do sistema. As colisões certamente ainda são um problema, mas supondo que você tenha verificado o nome do seu objeto, ainda é um problema de desempenho? TL;versão DR:SIM.
O prefixo sp_ ainda é proibido. Mas neste post vou explicar por que, como o SQL Server 2012 pode levar você a acreditar que esse conselho de advertência não se aplica mais e alguns outros efeitos colaterais potenciais de escolher essa convenção de nomenclatura.
Qual é o problema com sp_?
O
sp_ prefixo não significa o que você acha que significa:a maioria das pessoas pensa que sp significa "procedimento armazenado" quando na verdade significa "especial". Procedimentos armazenados (assim como tabelas e visualizações) armazenados no mestre com um sp_ prefix são acessíveis a partir de qualquer banco de dados sem uma referência adequada (assumindo que uma versão local não existe). Se o procedimento estiver marcado como um objeto do sistema (usando sp_MS_marksystemobject (um procedimento de sistema não documentado e não suportado que define is_ms_shipped para 1), então o procedimento em master será executado no contexto do banco de dados chamador. Vejamos um exemplo simples:CREATE DATABASE sp_test;
GO
USE sp_test;
GO
CREATE TABLE dbo.foo(id INT);
GO
USE master;
GO
CREATE PROCEDURE dbo.sp_checktable
AS
SELECT DB_NAME(), name
FROM sys.tables WHERE name = N'foo';
GO
USE sp_test;
GO
EXEC dbo.sp_checktable; -- runs but returns 0 results
GO
EXEC master..sp_MS_marksystemobject N'dbo.sp_checktable';
GO
EXEC dbo.sp_checktable; -- runs and returns results
GO Resultados:
(0 row(s) affected) sp_test foo (1 row(s) affected)
O problema de desempenho vem do fato de que o master pode ser verificado quanto a um procedimento armazenado equivalente, dependendo se há uma versão local do procedimento e se há de fato um objeto equivalente no master. Isso pode levar a uma sobrecarga extra de metadados, bem como a um
SP:CacheMiss adicional evento. A questão é se essa sobrecarga é tangível. Então vamos considerar um procedimento muito simples em um banco de dados de teste:
CREATE DATABASE sp_prefix; GO USE sp_prefix; GO CREATE PROCEDURE dbo.sp_something AS BEGIN SELECT 'sp_prefix', DB_NAME(); END GO
E procedimentos equivalentes no mestre:
USE master; GO CREATE PROCEDURE dbo.sp_something AS BEGIN SELECT 'master', DB_NAME(); END GO EXEC sp_MS_marksystemobject N'sp_something';
CacheMiss:Fato ou Ficção?
Se executarmos um teste rápido em nosso banco de dados de teste, veremos que a execução desses procedimentos armazenados nunca invocará as versões do mestre, independentemente de qualificarmos adequadamente o procedimento pelo banco de dados ou pelo esquema (um equívoco comum) ou se marcarmos o versão master como um objeto do sistema:
USE sp_prefix; GO EXEC sp_prefix.dbo.sp_something; GO EXEC dbo.sp_something; GO EXEC sp_something;
Resultados:
sp_prefix sp_prefix sp_prefix sp_prefix sp_prefix sp_prefix
Vamos também executar um Quick Trace
SP:CacheMiss eventos: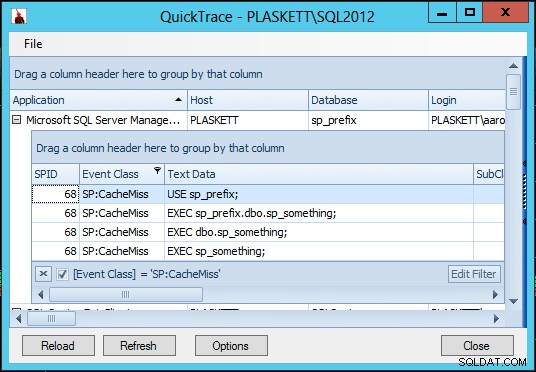
Vemos
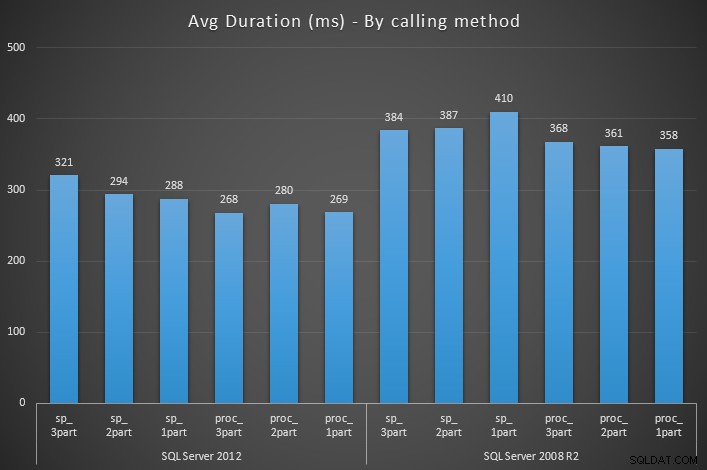
CacheMiss eventos para o lote ad hoc que chama o procedimento armazenado (já que o SQL Server geralmente não se incomoda em armazenar em cache um lote que consiste principalmente em chamadas de procedimento), mas não para o procedimento armazenado em si. Com e sem o sp_something procedimento existente no mestre (e quando existe, com e sem ser marcado como um objeto do sistema), as chamadas para sp_something no banco de dados do usuário nunca chame "acidentalmente" o procedimento no mestre e nunca gere nenhum CacheMiss eventos para o procedimento. Isso foi no SQL Server 2012. Repeti os mesmos testes acima no SQL Server 2008 R2 e encontrei resultados ligeiramente diferentes:
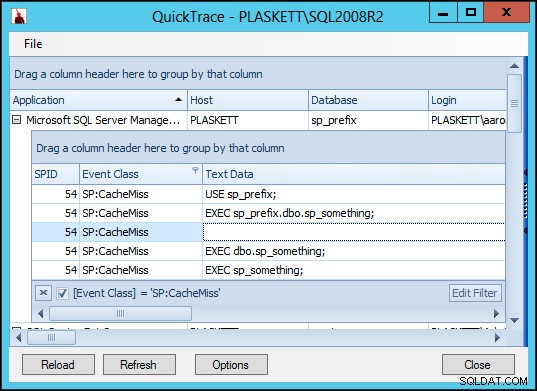
Portanto, no SQL Server 2008 R2, vemos um
CacheMiss adicional evento que não ocorre no SQL Server 2012. Isso ocorre em todos os cenários (nenhum objeto mestre equivalente, um objeto no mestre marcado como um objeto do sistema e um objeto no mestre não marcado como um objeto do sistema). Imediatamente fiquei curioso se esse evento adicional teria algum impacto perceptível no desempenho. Problema de desempenho:fato ou ficção?
Fiz um procedimento adicional sem o
sp_ prefixo para comparar o desempenho bruto, CacheMiss a parte, de lado:USE sp_prefix; GO CREATE PROCEDURE dbo.proc_something AS BEGIN SELECT 'sp_prefix', DB_NAME(); END GO
Portanto, a única diferença entre
sp_something e proc_something . Em seguida, criei procedimentos de wrapper para executá-los 1000 vezes cada, usando EXEC sp_prefix.dbo.<procname> , EXEC dbo.<procname> e EXEC <procname> sintaxe, com procedimentos armazenados equivalentes vivendo no mestre e marcados como um objeto do sistema, vivendo no mestre mas não marcados como um objeto do sistema e não vivendo no mestre. USE sp_prefix;
GO
CREATE PROCEDURE dbo.wrap_sp_3part
AS
BEGIN
DECLARE @i INT = 1;
WHILE @i <= 1000
BEGIN
EXEC sp_prefix.dbo.sp_something;
SET @i += 1;
END
END
GO
CREATE PROCEDURE dbo.wrap_sp_2part
AS
BEGIN
DECLARE @i INT = 1;
WHILE @i <= 1000
BEGIN
EXEC dbo.sp_something;
SET @i += 1;
END
END
GO
CREATE PROCEDURE dbo.wrap_sp_1part
AS
BEGIN
DECLARE @i INT = 1;
WHILE @i <= 1000
BEGIN
EXEC sp_something;
SET @i += 1;
END
END
GO
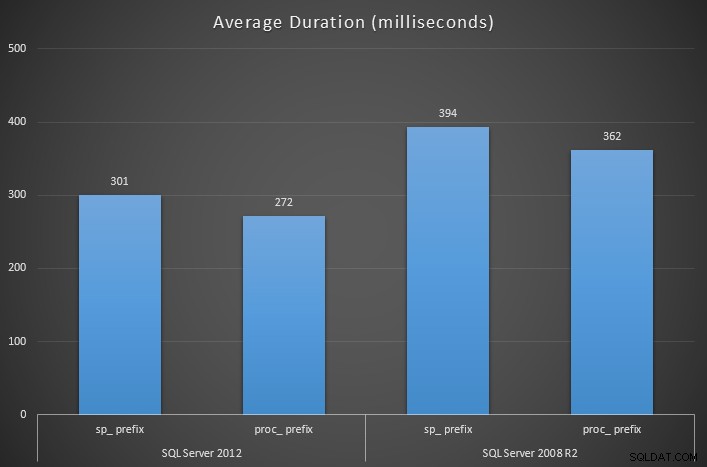
-- repeat for proc_something Medindo a duração do tempo de execução de cada procedimento de wrapper com o SQL Sentry Plan Explorer, os resultados mostram que o uso do
sp_ prefixo tem um impacto significativo na duração média em quase todos os casos (e certamente na média):