Encontrei uma solução que se baseia nas propriedades dos dados na tabela. Prefiro ter uma solução mais geral que não dependa dos dados atuais, mas por enquanto é a melhor que tenho.
O problema com a consulta original:
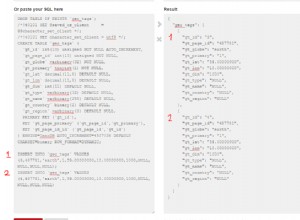
SELECT P, Y, Z FROM SomeTable WHERE FirstX <= ? AND LastX >= ? LIMIT 10;
é que a execução pode exigir a varredura de uma grande porcentagem das entradas no
FirstX ,LastX ,P index quando a primeira condição FirstX <= ? é satisfeito por uma grande porcentagem das linhas. O que fiz para reduzir o tempo de execução foi observar que
LastX-FirstX é relativamente pequeno. Executei a consulta:
SELECT MAX(LastX-FirstX) FROM SomeTable;
e obtive
4200000 . Isso significa que
FirstX >= LastX – 4200000 para todas as linhas da tabela. Então, para satisfazer
LastX >= ? , também devemos satisfazer FirstX >= ? – 4200000 . Assim, podemos adicionar uma condição à consulta da seguinte forma:
SELECT P, Y, Z FROM SomeTable WHERE FirstX <= ? AND FirstX >= ? - 4200000 AND LastX >= ? LIMIT 10;
No exemplo que testei na pergunta, o número de entradas de índice processadas foi reduzido de
2104820 para 18 e o tempo de execução foi reduzido de 0,563 segundos para 0,0003 segundos . Testei a nova consulta com o mesmo
120000 valores de X . A saída foi idêntica à consulta antiga. O tempo caiu de mais de 10 horas para 5,5 minutos , que é 100 vezes mais rápido .