Queria entrar com a opção de resolver sua tarefa com BigQuery puro (SQL padrão)
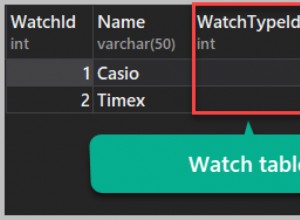
Pré-requisitos/suposições :os dados de origem estão em
sandbox.temp.id1_id2_pairs Você deve substituir isso pelo seu próprio ou se quiser testar com dados fictícios da sua pergunta - você pode criar esta tabela como abaixo (é claro substituir
sandbox.temp com seu próprio project.dataset ) 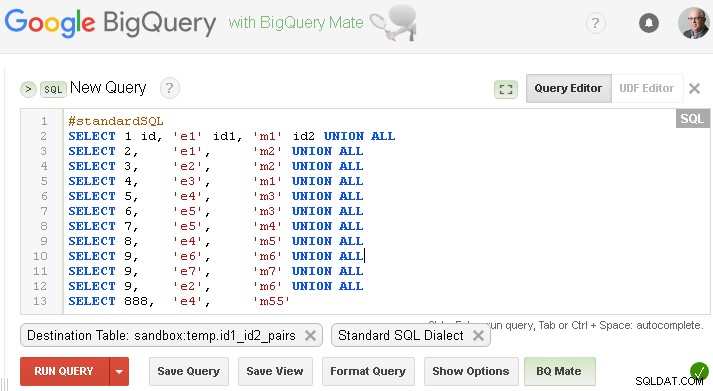
Certifique-se de definir a respectiva tabela de destino
Observação :você pode encontrar todas as respectivas consultas (como texto) na parte inferior desta resposta, mas por enquanto estou ilustrando minha resposta com capturas de tela - para que tudo seja apresentado - consulta, resultado e opções usadas
Assim, serão três etapas:
Etapa 1 - Inicialização
Aqui, apenas fazemos o agrupamento inicial de id1 com base em conexões com id2:
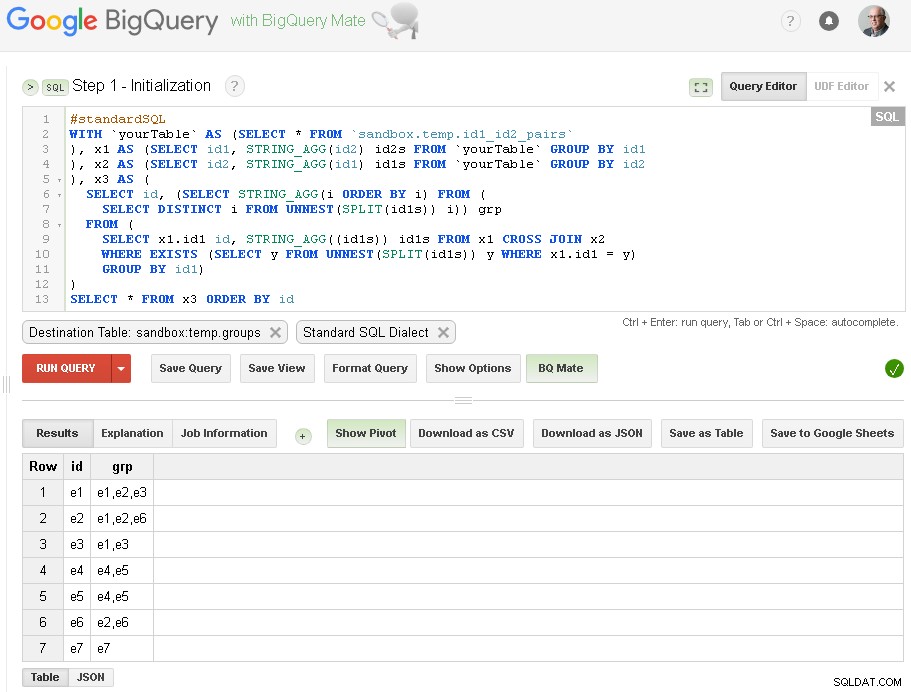
Como você pode ver aqui - criamos uma lista de todos os valores id1 com as respectivas conexões com base em uma conexão simples de um nível por meio de id2
A tabela de saída é
sandbox.temp.groups Etapa 2 - Agrupando iterações
Em cada iteração vamos enriquecer o agrupamento com base nos grupos já estabelecidos.
A fonte da consulta é a tabela de saída da etapa anterior (
sandbox.temp.groups ) e Destino é a mesma tabela (sandbox.temp.groups ) com Sobrescrever 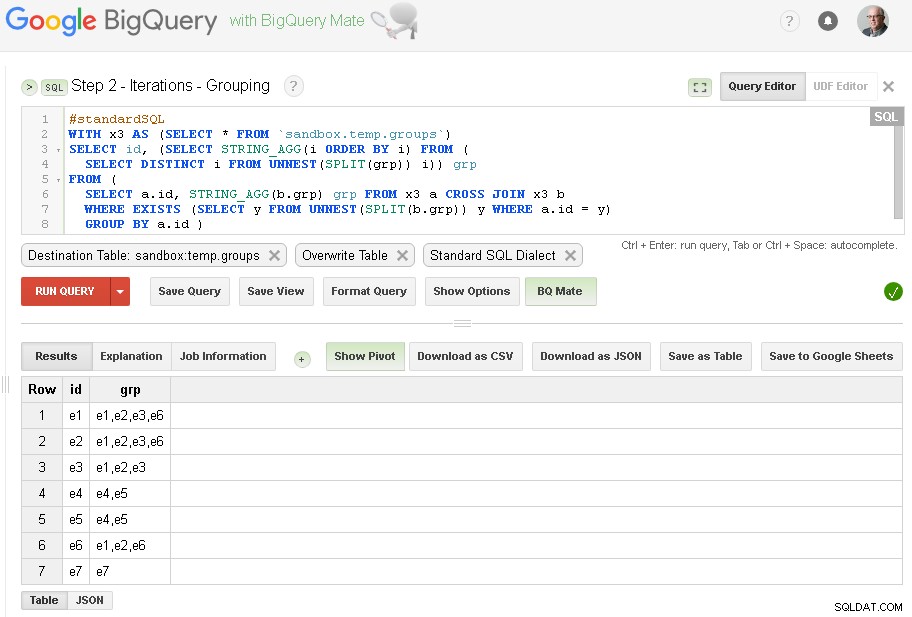
Continuaremos as iterações até que a contagem de grupos encontrados seja a mesma da iteração anterior
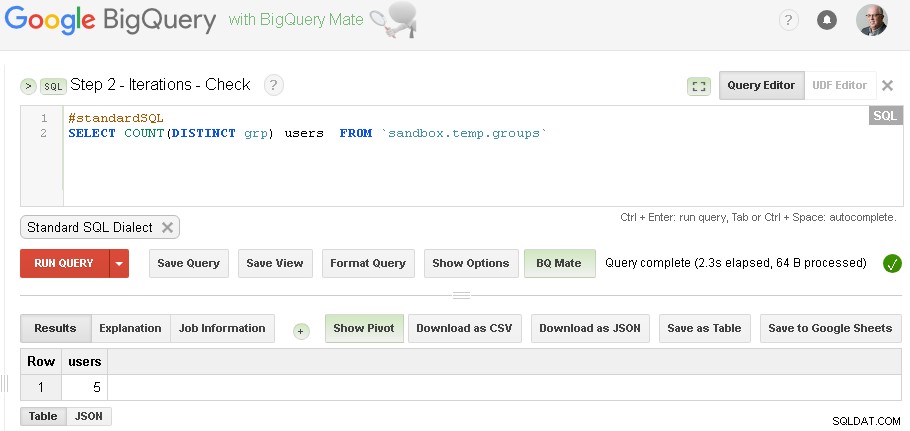
Observação :você pode apenas ter duas guias de interface do usuário da Web do BigQuery abertas (como é mostrado acima) e sem alterar nenhum código, basta executar o Grouping e, em seguida, Check repetidamente até a iteração convergir
(para dados específicos que usei na seção de pré-requisitos - tive três iterações - a primeira iteração produziu 5 usuários, a segunda iteração produziu 3 usuários e a terceira iteração produziu novamente 3 usuários - o que indicou que terminamos com iterações.
Claro, no caso da vida real - o número de iterações pode ser mais do que apenas três - então precisamos de algum tipo de automação (veja a respectiva seção na parte inferior da resposta).
Etapa 3 – Agrupamento final
Quando o agrupamento id1 estiver concluído - podemos adicionar o agrupamento final para id2
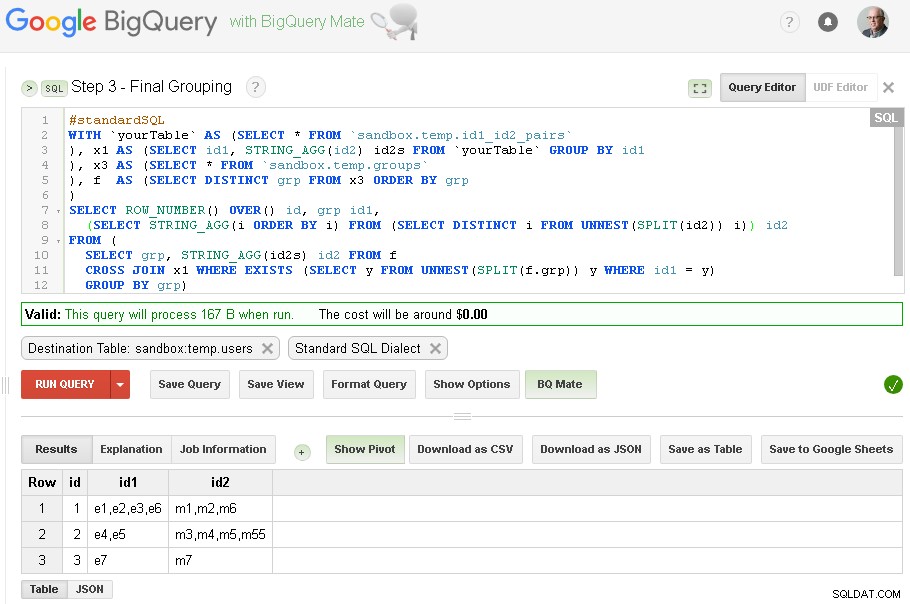
O resultado final agora está em
sandbox.temp.users tabela Consultas usadas (não se esqueça de definir as respectivas tabelas de destino e sobrescrever quando necessário, conforme a lógica e as capturas de tela descritas acima):
Pré-requisitos:
#standardSQL
SELECT 1 id, 'e1' id1, 'm1' id2 UNION ALL
SELECT 2, 'e1', 'm2' UNION ALL
SELECT 3, 'e2', 'm2' UNION ALL
SELECT 4, 'e3', 'm1' UNION ALL
SELECT 5, 'e4', 'm3' UNION ALL
SELECT 6, 'e5', 'm3' UNION ALL
SELECT 7, 'e5', 'm4' UNION ALL
SELECT 8, 'e4', 'm5' UNION ALL
SELECT 9, 'e6', 'm6' UNION ALL
SELECT 9, 'e7', 'm7' UNION ALL
SELECT 9, 'e2', 'm6' UNION ALL
SELECT 888, 'e4', 'm55'
Passo 1
#standardSQL
WITH `yourTable` AS (select * from `sandbox.temp.id1_id2_pairs`
), x1 AS (SELECT id1, STRING_AGG(id2) id2s FROM `yourTable` GROUP BY id1
), x2 AS (SELECT id2, STRING_AGG(id1) id1s FROM `yourTable` GROUP BY id2
), x3 AS (
SELECT id, (SELECT STRING_AGG(i ORDER BY i) FROM (
SELECT DISTINCT i FROM UNNEST(SPLIT(id1s)) i)) grp
FROM (
SELECT x1.id1 id, STRING_AGG((id1s)) id1s FROM x1 CROSS JOIN x2
WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(id1s)) y WHERE x1.id1 = y)
GROUP BY id1)
)
SELECT * FROM x3
Passo 2 - Agrupamento
#standardSQL
WITH x3 AS (select * from `sandbox.temp.groups`)
SELECT id, (SELECT STRING_AGG(i ORDER BY i) FROM (
SELECT DISTINCT i FROM UNNEST(SPLIT(grp)) i)) grp
FROM (
SELECT a.id, STRING_AGG(b.grp) grp FROM x3 a CROSS JOIN x3 b
WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(b.grp)) y WHERE a.id = y)
GROUP BY a.id )
Passo 2 - Verifique
#standardSQL
SELECT COUNT(DISTINCT grp) users FROM `sandbox.temp.groups`
etapa 3
#standardSQL
WITH `yourTable` AS (select * from `sandbox.temp.id1_id2_pairs`
), x1 AS (SELECT id1, STRING_AGG(id2) id2s FROM `yourTable` GROUP BY id1
), x3 as (select * from `sandbox.temp.groups`
), f AS (SELECT DISTINCT grp FROM x3 ORDER BY grp
)
SELECT ROW_NUMBER() OVER() id, grp id1,
(SELECT STRING_AGG(i ORDER BY i) FROM (SELECT DISTINCT i FROM UNNEST(SPLIT(id2)) i)) id2
FROM (
SELECT grp, STRING_AGG(id2s) id2 FROM f
CROSS JOIN x1 WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(f.grp)) y WHERE id1 = y)
GROUP BY grp)
Automação :
Claro, o "processo" acima pode ser executado manualmente no caso de as iterações convergirem rapidamente - então você terminará com 10-20 execuções. Mas em casos mais reais, você pode automatizar isso facilmente com qualquer cliente da sua escolha