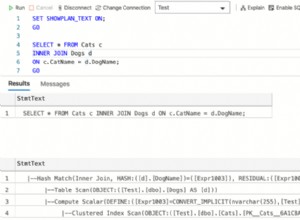
Uma visualização funciona como uma tabela , mas não é uma tabela. Ela nunca existe; é apenas uma instrução SQL preparada que é executada quando você faz referência ao nome da visualização. IE:
CREATE VIEW foo AS
SELECT * FROM bar
SELECT * FROM foo
...é equivalente a executar:
SELECT x.*
FROM (SELECT * FROM bar) x
Um MySQLDump nunca conterá linhas a serem inseridas em uma visão...
Isso, infelizmente, é por design (embora questionável). Existem inúmeras limitações para visualizações do MySQL, que estão documentadas:https://dev.mysql.com/doc/refman/5.0/en/create-view.html
Então, se for apenas uma tabela/instrução preparada imaginária, isso significa que teoricamente tem o mesmo desempenho (ou até menos) que uma tabela/consulta normal?
Não.
Uma tabela pode ter índices associados, o que pode tornar a recuperação de dados mais rápida (com algum custo para inserção/atualização). Alguns bancos de dados suportam visualizações "materializadas", que são visualizações que podem ter índices aplicados a elas - o que não deve ser uma surpresa que o MySQL não suporte dada a funcionalidade de visualização limitada (que só começou na v5 IIRC, muito tarde para o jogo).
Como uma exibição é uma tabela derivada, o desempenho da exibição é tão bom quanto a consulta na qual ela é construída. Se essa consulta for ruim, o problema de desempenho será apenas uma bola de neve ... Dito isso, ao consultar uma exibição - se uma referência de coluna de exibição na cláusula WHERE não estiver envolvida em uma função (IE:
WHERE v.column LIKE ... , não WHERE LOWER(t.column) LIKE ... ), o otimizador pode enviar os critérios (chamados de predicado) para a consulta original - tornando-a mais rápida.