Os bancos de dados precisam ser executados de maneira ideal, mas isso não é uma tarefa tão fácil. O banco de dados ESQUEMA DE INFORMAÇÕES pode ser sua arma secreta na guerra da otimização do banco de dados.
Estamos acostumados a criar bancos de dados usando uma interface gráfica ou uma série de comandos SQL. Isso é completamente bom, mas também é bom entender um pouco sobre o que está acontecendo em segundo plano. Isso é importante para a criação, manutenção e otimização de um banco de dados, e também é uma boa maneira de rastrear as mudanças que acontecem “nos bastidores”.
Neste artigo, veremos algumas consultas SQL que podem ajudá-lo a analisar o funcionamento de um banco de dados MySQL.
O banco de dados INFORMATION_SCHEMA
Já discutimos o
INFORMATION_SCHEMA banco de dados neste artigo. Se você ainda não leu, eu definitivamente sugiro que você faça isso antes de continuar. Se você precisar de uma atualização no
INFORMATION_SCHEMA banco de dados – ou se você decidir não ler o primeiro artigo – aqui estão alguns fatos básicos que você precisa saber:- O
INFORMATION_SCHEMAbanco de dados faz parte do padrão ANSI. Estaremos trabalhando com MySQL, mas outros RDBMSs têm suas variantes. Você pode encontrar versões para banco de dados H2, HSQLDB, MariaDB, Microsoft SQL Server e PostgreSQL. - Este é o banco de dados que acompanha todos os outros bancos de dados no servidor; encontraremos descrições de todos os objetos aqui.
- Como qualquer outro banco de dados, o
INFORMATION_SCHEMAO banco de dados contém várias tabelas relacionadas e informações sobre diferentes objetos. - Você pode consultar este banco de dados usando SQL e usar os resultados para:
- Monitorar o status e o desempenho do banco de dados e
- Gere código automaticamente com base nos resultados da consulta.
Agora vamos passar a consultar o banco de dados INFORMATION_SCHEMA. Começaremos analisando o modelo de dados que vamos usar.
O modelo de dados
O modelo que usaremos neste artigo é mostrado abaixo.
Este é um modelo simplificado que nos permite armazenar informações sobre turmas, instrutores, alunos e outros detalhes relacionados. Passemos brevemente pelas tabelas.
Armazenaremos a lista de instrutores no
lecturer tabela. Para cada palestrante, gravaremos um first_name e um last_name . A
class tabela lista todas as classes que temos em nossa escola. Para cada registro nesta tabela, armazenaremos o class_name , o ID do palestrante, uma start_date planejada e end_date e quaisquer class_details adicionais . Por uma questão de simplicidade, vou assumir que temos apenas um professor por aula. As aulas são geralmente organizadas como uma série de palestras. Geralmente requerem um ou mais exames. Armazenaremos listas de palestras e exames relacionados na
lecture e exam mesas. Ambos terão o ID da classe relacionada e o start_time esperado e end_time . Agora precisamos de alunos para nossas aulas. Uma lista de todos os alunos é armazenada no arquivo
student tabela. Mais uma vez, armazenaremos apenas o first_name e o last_name de cada aluno. A última coisa que precisamos fazer é acompanhar as atividades dos alunos. Armazenaremos uma lista de todas as aulas para as quais um aluno se inscreveu, o registro de frequência do aluno e os resultados de seus exames. Cada uma das três tabelas restantes –
on_class , on_lecture e on_exam – terá uma referência ao aluno e uma referência à tabela apropriada. Somente o on_exam tabela terá um valor adicional:nota. Sim, este modelo é muito simples. Poderíamos acrescentar muitos outros detalhes sobre alunos, professores e turmas. Poderíamos armazenar valores históricos quando os registros são atualizados ou excluídos. Ainda assim, este modelo será suficiente para os propósitos deste artigo.
Criando um banco de dados
Estamos prontos para criar um banco de dados em nosso servidor local e examinar o que está acontecendo dentro dele. Vamos exportar o modelo (em Vertabelo) usando o “
Generate SQL script " botão. Em seguida, criaremos um banco de dados na instância do MySQL Server. Chamei meu banco de dados de “
classes_and_students ”. A próxima coisa que precisamos fazer é executar um script SQL gerado anteriormente.
Agora temos o banco de dados com todos os seus objetos (tabelas, chaves primárias e estrangeiras, chaves alternativas).
Tamanho do banco de dados
Após a execução do script, os dados sobre as “
classes and students ” é armazenado no INFORMATION_SCHEMA base de dados. Esses dados estão em muitas tabelas diferentes. Não vou listá-los todos novamente aqui; fizemos isso no artigo anterior. Vamos ver como podemos usar o SQL padrão neste banco de dados. Vou começar com uma pergunta muito importante:
SET @table_schema = "classes_and_students";
SELECT
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_LENGTH + INFORMATION_SCHEMA.TABLES.INDEX_LENGTH ) / 1024 / 1024, 2) AS "DB Size (in MB)",
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_FREE )/ 1024 / 1024, 2) AS "Free Space (in MB)"
FROM INFORMATION_SCHEMA.TABLES
WHERE INFORMATION_SCHEMA.TABLES.TABLE_SCHEMA = @table_schema;
Estamos consultando apenas o INFORMATION_SCHEMA.TABLES mesa aqui. Esta tabela deve nos dar detalhes mais do que suficientes sobre todas as tabelas no servidor. Observe que filtrei apenas as tabelas do "classes_and_students " banco de dados usando o SET variável na primeira linha e depois usando esse valor na consulta. A maioria das tabelas contém as colunas TABLE_NAME e TABLE_SCHEMA , que denotam a tabela e o esquema/banco de dados aos quais esses dados pertencem.
Esta consulta retornará o tamanho atual de nosso banco de dados e o espaço livre reservado para nosso banco de dados. Aqui está o resultado real:

Como esperado, o tamanho do nosso banco de dados vazio é inferior a 1 MB e o espaço livre reservado é muito maior.
Tamanhos e propriedades da tabela
A próxima coisa interessante a fazer seria observar os tamanhos das tabelas em nosso banco de dados. Para isso, usaremos a seguinte consulta:
SET @table_schema = "classes_and_students";
SELECT
INFORMATION_SCHEMA.TABLES.TABLE_NAME,
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_LENGTH + INFORMATION_SCHEMA.TABLES.INDEX_LENGTH ) / 1024 / 1024, 2) "Table Size (in MB)",
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_FREE )/ 1024 / 1024, 2) AS "Free Space (in MB)",
MAX( INFORMATION_SCHEMA.TABLES.TABLE_ROWS) AS table_rows_number,
MAX( INFORMATION_SCHEMA.TABLES.AUTO_INCREMENT) AS auto_increment_value
FROM INFORMATION_SCHEMA.TABLES
WHERE INFORMATION_SCHEMA.TABLES.TABLE_SCHEMA = @table_schema
GROUP BY INFORMATION_SCHEMA.TABLES.TABLE_NAME
ORDER BY 2 DESC;
A consulta é quase idêntica à anterior, com uma exceção:o resultado é agrupado no nível da tabela.
Aqui está uma imagem do resultado retornado por esta consulta:
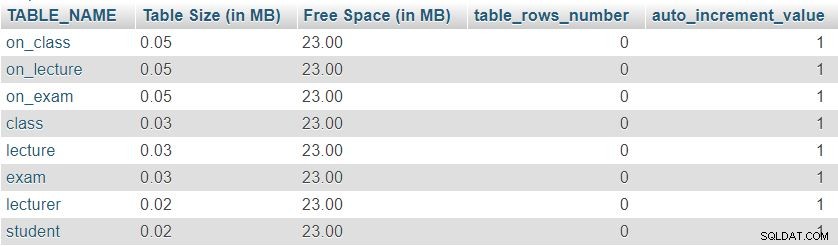
Primeiro, podemos notar que todas as oito tabelas têm um mínimo “Tamanho da tabela” reservado para definição de tabela, que inclui as colunas, chave primária e índice. O "Espaço Livre" é distribuído igualmente entre todas as tabelas.
Também podemos ver o número de linhas atualmente em cada tabela e o valor atual do auto_increment propriedade para cada tabela. Como todas as tabelas estão completamente vazias, não temos dados e auto_increment é definido como 1 (um valor que será atribuído à próxima linha inserida).
Chaves primárias
Cada tabela deve ter um valor de chave primária definido, portanto, é aconselhável verificar se isso é verdade para nosso banco de dados. Uma maneira de fazer isso é juntar uma lista de todas as tabelas com uma lista de restrições. Isso deve nos dar as informações que precisamos.
SET @table_schema = "classes_and_students";
SELECT
tab.TABLE_NAME,
COUNT(*) AS PRI_number
FROM INFORMATION_SCHEMA.TABLES tab
LEFT JOIN (
SELECT
INFORMATION_SCHEMA.COLUMNS.TABLE_SCHEMA,
INFORMATION_SCHEMA.COLUMNS.TABLE_NAME
FROM INFORMATION_SCHEMA.COLUMNS
WHERE INFORMATION_SCHEMA.COLUMNS.TABLE_SCHEMA = @table_schema
AND INFORMATION_SCHEMA.COLUMNS.COLUMN_KEY = 'PRI'
) col
ON tab.TABLE_SCHEMA = col.TABLE_SCHEMA
AND tab.TABLE_NAME = col.TABLE_NAME
WHERE tab.TABLE_SCHEMA = @table_schema
GROUP BY
tab.TABLE_NAME;
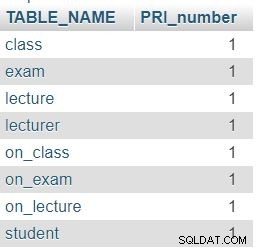
Também usamos o INFORMATION_SCHEMA.COLUMNS tabela nesta consulta. Enquanto a primeira parte da consulta simplesmente retornará todas as tabelas do banco de dados, a segunda parte (depois de LEFT JOIN ) contará o número de PRIs nessas tabelas. Usamos LEFT JOIN porque queremos ver se uma tabela tem 0 PRI nas COLUMNS tabela.
Como esperado, cada tabela em nosso banco de dados contém exatamente uma coluna de chave primária (PRI).
“Ilhas”?
“Ilhas” são tabelas completamente separadas do resto do modelo. Eles acontecem quando uma tabela não contém chaves estrangeiras e não é referenciada em nenhuma outra tabela. Isso realmente não deve ocorrer a menos que haja uma boa razão, por exemplo. quando as tabelas contêm parâmetros ou armazenam resultados ou relatórios dentro do modelo.
SET @table_schema = "classes_and_students";
SELECT
tab.TABLE_NAME,
(CASE WHEN f1.number_referenced IS NULL THEN 0 ELSE f1.number_referenced END) AS number_referenced,
(CASE WHEN f2.number_referencing IS NULL THEN 0 ELSE f2.number_referencing END) AS number_referencing
FROM INFORMATION_SCHEMA.TABLES tab
LEFT JOIN
-- # table was used as a reference
(
SELECT
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME,
COUNT(*) AS number_referenced
FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA = @table_schema
GROUP BY
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME
) f1
ON tab.TABLE_SCHEMA = f1.REFERENCED_TABLE_SCHEMA
AND tab.TABLE_NAME = f1.REFERENCED_TABLE_NAME
LEFT JOIN
-- # of references in the table
(
SELECT
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_NAME,
COUNT(*) AS number_referencing
FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA = @table_schema
AND INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME IS NOT NULL
GROUP BY
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_NAME
) f2
ON tab.TABLE_SCHEMA = f2.TABLE_SCHEMA
AND tab.TABLE_NAME = f2.TABLE_NAME
WHERE tab.TABLE_SCHEMA = @table_schema;
Qual é a ideia por trás dessa consulta? Bem, estamos usando o INFORMATION_SCHEMA.KEY_COLUMN_USAGE table para testar se alguma coluna na tabela é uma referência a outra tabela ou se alguma coluna é usada como referência em qualquer outra tabela. A primeira parte da consulta seleciona todas as tabelas. Após o primeiro LEFT JOIN, contamos o número de vezes que qualquer coluna desta tabela foi usada como referência. Após o segundo LEFT JOIN, contamos o número de vezes que qualquer coluna desta tabela fez referência a qualquer outra tabela.
O resultado retornado é:
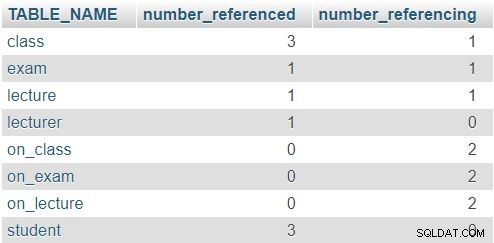
Na linha da class tabela, os números 3 e 1 indicam que esta tabela foi referenciada três vezes (na lecture , exam e on_class tabelas) e que contém um atributo referenciando outra tabela (lecturer_id ). As outras tabelas seguem um padrão semelhante, embora os números reais sejam obviamente diferentes. A regra aqui é que nenhuma linha deve ter um 0 em ambas as colunas.
Adicionando linhas
Até agora, tudo correu como esperado. Importamos com sucesso nosso modelo de dados do Vertabelo para o MySQL Server local. Todas as tabelas contêm chaves, exatamente como queremos, e todas as tabelas estão relacionadas entre si – não há “ilhas” em nosso modelo.
Agora, vamos inserir algumas linhas em nossas tabelas e usar as consultas demonstradas anteriormente para rastrear as alterações em nosso banco de dados.
Depois de adicionar 1.000 linhas na tabela do palestrante, executaremos novamente a consulta a partir de "
Table Sizes and Properties " seção. Ele retornará o seguinte resultado: 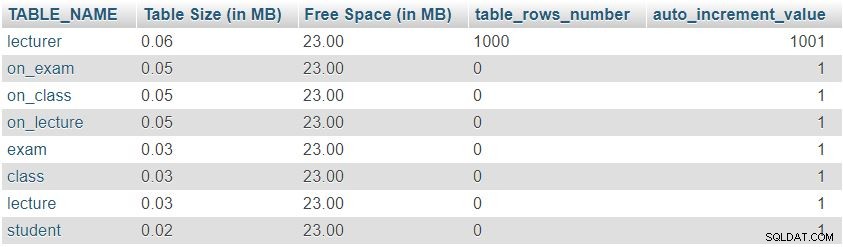
Podemos notar facilmente que o número de linhas e os valores de auto_increment mudaram conforme o esperado, mas não houve alteração significativa no tamanho da tabela.
Este foi apenas um exemplo de teste; em situações da vida real, notamos mudanças significativas. O número de linhas mudará drasticamente em tabelas preenchidas por usuários ou processos automatizados (ou seja, tabelas que não são dicionários). Verificar o tamanho e os valores dessas tabelas é uma maneira muito boa de localizar e corrigir rapidamente comportamentos indesejados.
Quer compartilhar?
Trabalhar com bancos de dados é uma busca constante pelo desempenho ideal. Para ter mais sucesso nessa busca, você deve usar qualquer ferramenta disponível. Hoje vimos algumas consultas que são úteis em nossa luta por um melhor desempenho. Encontrou mais alguma coisa útil? Você já jogou com o
INFORMATION_SCHEMA banco de dados antes? Compartilhe sua experiência nos comentários abaixo. 


