Python é muito popular nos dias de hoje. Como o Python é uma linguagem de programação de uso geral, ele também pode ser usado para executar o processo Extract, Transform, Load (ETL). Diferentes módulos ETL estão disponíveis, mas hoje vamos ficar com a combinação de Python e MySQL. Usaremos Python para invocar procedimentos armazenados e preparar e executar instruções SQL.
Usaremos duas abordagens semelhantes, mas diferentes. Primeiro, invocaremos procedimentos armazenados que farão todo o trabalho e, depois disso, analisaremos como poderíamos fazer o mesmo processo sem procedimentos armazenados usando código MySQL em Python.
Preparar? Antes de nos aprofundarmos, vamos dar uma olhada no modelo de dados – ou modelos de dados, pois há dois deles neste artigo.
Os modelos de dados
Precisaremos de dois modelos de dados, um para armazenar nossos dados operacionais e outro para armazenar nossos dados de relatórios.
O primeiro modelo é mostrado na imagem acima. Esse modelo é usado para armazenar dados operacionais (ao vivo) para um negócio baseado em assinatura. Para obter mais informações sobre esse modelo, dê uma olhada em nosso artigo anterior, Criando um DWH, Parte Um:Um Modelo de Dados de Negócios de Assinatura.
Separar dados operacionais e de relatórios geralmente é uma decisão muito sábia. Para conseguir essa separação, precisaremos criar um data warehouse (DWH). Já fizemos isso; você pode ver o modelo na imagem acima. Esse modelo também é descrito em detalhes na postagem Criando um DWH, Parte Dois:Um Modelo de Dados de Negócios de Assinatura.
Finalmente, precisamos extrair dados do banco de dados ativo, transformá-los e carregá-los em nosso DWH. Já fizemos isso usando procedimentos armazenados SQL. Você pode encontrar uma descrição do que queremos alcançar junto com alguns exemplos de código em Criando um Data Warehouse, Parte 3:Um Modelo de Dados Corporativos de Assinatura.
Se você precisar de informações adicionais sobre DWHs, recomendamos a leitura destes artigos:
- O esquema em estrela
- O esquema de floco de neve
- Esquema em estrela versus esquema em floco de neve.
Nossa tarefa hoje é substituir os procedimentos armazenados SQL pelo código Python. Estamos prontos para fazer alguma mágica em Python. Vamos começar usando apenas procedimentos armazenados em Python.
Método 1:ETL usando procedimentos armazenados
Antes de começarmos a descrever o processo, é importante mencionar que temos dois bancos de dados em nosso servidor.
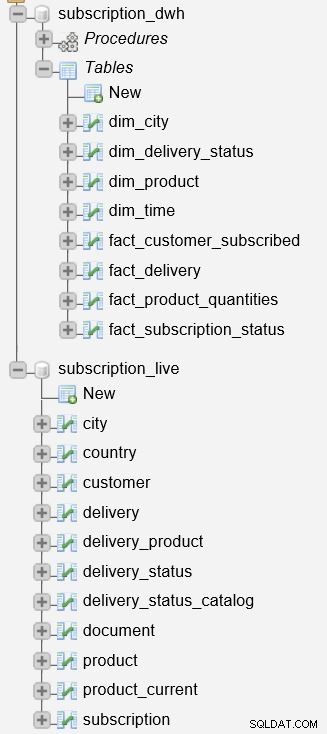
A subscription_live banco de dados é usado para armazenar dados transacionais/ao vivo, enquanto o subscription_dwh é o nosso banco de dados de relatórios (DWH).
Já descrevemos os procedimentos armazenados usados para atualizar as tabelas de dimensões e fatos. Eles lerão os dados do subscription_live banco de dados, combine-o com dados no subscription_dwh banco de dados e insira novos dados no subscription_dwh base de dados. Esses dois procedimentos são:
p_update_dimensions– Atualiza as tabelas de dimensãodim_timeedim_city.p_update_facts– Atualiza duas tabelas de fatos,fact_customer_subscribedefact_subscription_status.
Se você quiser ver o código completo desses procedimentos, leia Criando um Data Warehouse, Parte 3:Um Modelo de Dados Corporativos de Assinatura.
Agora estamos prontos para escrever um script Python simples que se conectará ao servidor e executará o processo de ETL. Vamos primeiro dar uma olhada no script inteiro (etl_procedures.py ). Em seguida, explicaremos as partes mais importantes.
# import MySQL connectorimport mysql.connector# connect to serverconnection =mysql.connector.connect(user='', password=' ', host='127.0.0.1')print('Connected to database.')cursor =connection.cursor()# Eu atualizo as dimensõescursor.callproc('subscription_dwh.p_update_dimensions')print('Tabelas de dimensões atualizadas.')# II atualizo fatoscursor.callproc('subscription_dwh.p_update_facts')print('Fact tabelas atualizadas.')# commit &close connectioncursor.close()connection.commit()connection.close()print('Desconectado do banco de dados.')
etl_procedures.py
Importando módulos e conectando ao banco de dados
Python usa módulos para armazenar definições e instruções. Você pode usar um módulo existente ou escrever o seu próprio. Usar módulos existentes simplificará sua vida porque você está usando código pré-escrito, mas escrever seu próprio módulo também é muito útil. Ao sair do interpretador Python e executá-lo novamente, você perderá funções e variáveis definidas anteriormente. Claro, você não quer digitar o mesmo código repetidamente. Para evitar isso, você pode armazenar suas definições em um módulo e importá-las para o Python.
Voltar para etl_procedures.py . Em nosso programa, começamos importando o MySQL Connector:
# import MySQL connectorimport mysql.connector
O MySQL Connector para Python é usado como um driver padronizado que se conecta a um servidor/banco de dados MySQL. Você precisará baixá-lo e instalá-lo se não tiver feito isso anteriormente. Além de se conectar ao banco de dados, ele oferece vários métodos e propriedades para trabalhar com um banco de dados. Usaremos alguns deles, mas você pode conferir a documentação completa aqui.
Em seguida, precisaremos nos conectar ao nosso banco de dados:
# connect to serverconnection =mysql.connector.connect(user='', password=' ', host='127.0.0.1')print('Connected to database.')cursor =connection .cursor()
A primeira linha se conectará a um servidor (neste caso, estou me conectando à minha máquina local) usando suas credenciais (substituir
conexão =mysql.connector.connect(user='', password=' ', host='127.0.0.1', database=' ')
Conectei-me intencionalmente apenas a um servidor e não a um banco de dados específico porque usarei dois bancos de dados localizados no mesmo servidor.
O próximo comando – print – está aqui apenas uma notificação de que fomos conectados com sucesso. Embora não tenha significado de programação, pode ser usado para depurar o código se algo der errado no script.
A última linha desta parte é:
cursor =connection.cursor()
Os cursores são a estrutura do manipulador usada para trabalhar com os dados. Vamos usá-los para recuperar dados do banco de dados (SELECT), mas também para modificar os dados (INSERT, UPDATE, DELETE). Antes de usar um cursor, precisamos criá-lo. E é isso que esta linha faz.
Procedimentos de chamada
A parte anterior era geral e poderia ser usada para outras tarefas relacionadas ao banco de dados. A seguinte parte do código é especificamente para ETL:chamar nossos procedimentos armazenados com o
cursor.callproc comando. Se parece com isso:# 1. atualizar as dimensõescursor.callproc('subscription_dwh.p_update_dimensions')print('Tabelas de dimensões atualizadas.')# 2. atualizar fatoscursor.callproc('subscription_dwh.p_update_facts')print('Tabelas de fatos atualizadas.')
A chamada de procedimentos é bastante autoexplicativa. Após cada chamada, um comando de impressão foi adicionado. Novamente, isso apenas nos dá uma notificação de que tudo correu bem.
Confirmar e Fechar
A parte final do script confirma as alterações do banco de dados e fecha todos os objetos usados:
# commit &close connectioncursor.close()connection.commit()connection.close()print('Desconectado do banco de dados.')
A chamada de procedimentos é bastante autoexplicativa. Após cada chamada, um comando de impressão foi adicionado. Novamente, isso apenas nos dá uma notificação de que tudo correu bem.
Comprometer-se é essencial aqui; sem ele, não haverá alterações no banco de dados, mesmo se você chamar um procedimento ou executar uma instrução SQL.
Executando o script
A última coisa que precisamos fazer é executar nosso script. Usaremos os seguintes comandos no Python Shell para conseguir isso:
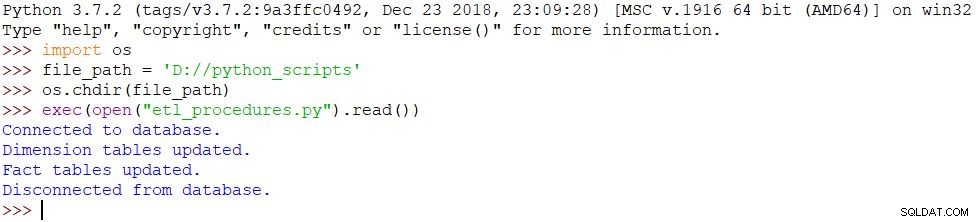
import osfile_path ='D://python_scripts'os.chdir(file_path)exec(open("etl_procedures.py").read())
O script é executado e todas as alterações são feitas no banco de dados de acordo. O resultado pode ser visto na imagem abaixo.
Método 2:ETL usando Python e MySQL
A abordagem apresentada acima não difere muito da abordagem de chamar procedimentos armazenados diretamente no MySQL. A única diferença é que agora temos um script que fará todo o trabalho para nós.
Poderíamos usar outra abordagem:colocar tudo dentro do script Python. Incluiremos instruções Python, mas também prepararemos consultas SQL e as executaremos no banco de dados. O banco de dados de origem (ao vivo) e o banco de dados de destino (DWH) são os mesmos do exemplo com procedimentos armazenados.
Antes de nos aprofundarmos nisso, vamos dar uma olhada no script completo (etl_queries.py ):
from datetime import date# import MySQL connectorimport mysql.connector# connect to serverconnection =mysql.connector.connect(user='', password='', host='127.0.0.1')print ('Conectado ao banco de dados.')# 1. update dimension# 1.1 update dim_time# data - ontemyesterday =date.fromordinal(date.today().toordinal()-1)yesterday_str ='"' + str(ontem) + ' "'# teste se a data já está na tabelacursor =connection.cursor()query =( "SELECT COUNT(*) " "FROM subscription_dwh.dim_time " "WHERE time_date =" + yesterday_str)cursor.execute(query)result =cursor .fetchall()yesterday_subscription_count =int(result[0][0])if yesterday_subscription_count ==0:yesterday_year ='YEAR("' + str(ontem) + '")' yesterday_month ='MONTH("' + str(ontem) ) + '")' yesterday_week ='WEEK("' + str(ontem) + '")' ontem_weekday ='WEEKDAY("' + str(ontem) + '")' query =( "INSERT INTO subscription_dwh.`dim_time `(`time_date`, `time_year`, `time_month`, `time_week` , `time_weekday`, `ts`) " " VALUES (" + ontem_str + ", " + ontem_year + ", " + ontem_mês + ", " + ontem_week + ", " + ontem_weekday + ", Now())") cursor .execute(query)# 1.2 update dim_cityquery =( "INSERT INTO subscription_dwh.`dim_city`(`city_name`, `postal_code`, `country_name`, `ts`) " "SELECT city_live.city_name, city_live.postal_code, country_live.country_name , Now() " "FROM subscription_live.city city_live " "INNER JOIN subscription_live.country country_live ON city_live.country_id =country_live.id " "LEFT JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name =city_dwh.city_name AND city_live.postal_code =city_dwh. postal_code AND country_live.country_name =city_dwh.country_name " "ONDE cidade_dwh.id IS NULL")cursor.execute(query)print('Tabelas de dimensão atualizadas.')# 2. atualizar fatos# 2.1 atualizar clientes inscritos# excluir dados antigos para o same datequery =( "DELETE subscription_dwh.`fact_customer_subscribed`.* " "DE subscription_dwh.`fa ct_customer_subscribed` " "INNER JOIN subscription_dwh.`dim_time` ON subscription_dwh.`fact_customer_subscribed`.`dim_time_id` =subscription_dwh.`dim_time`.`id` " "WHERE subscription_dwh.`dim_time`.`time_date` =" + yesterday_str)cursor. execute(query)# insert new dataquery =( "INSERT INTO subscription_dwh.`fact_customer_subscribed`(`dim_city_id`, `dim_time_id`, `total_active`, `total_inactive`, `daily_new`, `daily_canceled`, `ts`) " " SELECT city_dwh.id AS dim_ctiy_id, time_dwh.id AS dim_time_id, SUM(CASE WHEN customer_live.active =1 THEN 1 ELSE 0 END) AS total_active, SUM(CASE WHEN customer_live.active =0 THEN 1 ELSE 0 END) AS total_inactive, SUM( CASE WHEN customer_live.active =1 AND DATE(customer_live.time_updated) =@time_date THEN 1 ELSE 0 END) AS daily_new, SUM(CASE WHEN customer_live.active =0 AND DATE(customer_live.time_updated) =@time_date THEN 1 ELSE 0 END ) AS daily_canceled, MIN(NOW()) AS ts " "FROM subscription_live.`customer` customer_live " "INNER JOIN subscri ption_live.`city` city_live ON customer_live.city_id =city_live.id " "INNER JOIN subscription_live.`country` country_live ON city_live.country_id =country_live.id " "INNER JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name =city_dwh.city_name AND city_live .postal_code =city_dwh.postal_code AND country_live.country_name =city_dwh.country_name " "INNER JOIN subscription_dwh.dim_time time_dwh ON time_dwh.time_date =" + yesterday_str + " " "GROUP BY city_dwh.id, time_dwh.id")cursor.execute(query )# 2.2 atualizar status de assinatura# excluir dados antigos para a mesma consulta de data =( "DELETE subscription_dwh.`fact_subscription_status`.* " "FROM subscription_dwh.`fact_subscription_status` " "INNER JOIN subscription_dwh.`dim_time` ON subscription_dwh.`fact_subscription_status`.` dim_time_id` =subscription_dwh.`dim_time`.`id` " "WHERE subscription_dwh.`dim_time`.`time_date` =" + yesterday_str)cursor.execute(query)# insert new dataquery =( "INSERT INTO subscription_dwh.`fact _subscription_status`(`dim_city_id`, `dim_time_id`, `total_active`, `total_inactive`, `daily_new`, `daily_canceled`, `ts`) " "SELECT city_dwh.id AS dim_ctiy_id, time_dwh.id AS dim_time_id, SUM(CASE WHEN subscription_live.active =1 THEN 1 ELSE 0 END) AS total_active, SUM(CASE WHEN subscription_live.active =0 THEN 1 ELSE 0 END) AS total_inactive, SUM(CASE WHEN subscription_live.active =1 AND DATE(subscription_live.time_updated) =@ time_date THEN 1 ELSE 0 END) AS daily_new, SUM(CASE WHEN subscription_live.active =0 AND DATE(subscription_live.time_updated) =@time_date THEN 1 ELSE 0 END) AS daily_canceled, MIN(NOW()) AS ts " "FROM subscription_live .`customer` customer_live " "INNER JOIN subscription_live.`subscription` subscription_live ON subscription_live.customer_id =customer_live.id " "INNER JOIN subscription_live.`city` city_live ON customer_live.city_id =city_live.id " "INNER JOIN subscription_live.`country` country_live ON city_live.country_id =country_live.id " "INNER JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name =city_dwh.city_name AND city_live.postal_code =city_dwh.postal_code AND country_live.country_name =city_dwh.country_name " "INNER JOIN subscription_dwh.dim_time time_dwh ON time_dwh.time_date =" + yesterday_str + " "GROUP BY city_dwh.id, time_dwh.id")cursor.execute(query)print('Tabelas de fatos atualizadas.')# commit &close connectioncursor.close()connection.commit()connection.close()print('Desconectado do banco de dados .')
etl_queries.py
Importando módulos e conectando ao banco de dados
Mais uma vez, precisaremos importar o MySQL usando o seguinte código:
importar mysql.connector
Também importaremos o módulo datetime, conforme mostrado abaixo. Precisamos disso para operações relacionadas a datas em Python:
da data de importação datetime
O processo de conexão com o banco de dados é o mesmo do exemplo anterior.
Atualizando a dimensão dim_time
Para atualizar o dim_time tabela, precisaremos verificar se o valor (de ontem) já está na tabela. Teremos que usar as funções de data do Python (em vez do SQL) para fazer isso:
# data - ontemyesterday =date.fromordinal(date.today().toordinal()-1)yesterday_str ='"' + str(ontem) + '"'
A primeira linha de código retornará a data de ontem na variável date, enquanto a segunda linha armazenará esse valor como uma string. Precisaremos disso como uma string porque vamos concatená-la com outra string quando construirmos a consulta SQL.
Em seguida, precisaremos testar se essa data já está no dim_time tabela. Depois de declarar um cursor, vamos preparar a consulta SQL. Para executar a consulta, usaremos o cursor.execute comando:
# teste se a data já está na tabelacursor =connection.cursor()query =( "SELECT COUNT(*) " "FROM subscription_dwh.dim_time " "WHERE time_date =" + yesterday_str)cursor.execute(query)'" '
Vamos armazenar o resultado da consulta no resultado variável. O resultado terá 0 ou 1 linha, então podemos testar a primeira coluna da primeira linha. Ele conterá 0 ou 1. (Lembre-se, podemos ter a mesma data apenas uma vez em uma tabela de dimensões.)
Caso a data ainda não esteja na tabela, prepararemos as strings que farão parte da consulta SQL:
resultado =cursor.fetchall()yesterday_subscription_count =int(result[0][0])if yesterday_subscription_count ==0:yesterday_year ='YEAR("' + str(ontem) + '")' yesterday_month ='MONTH( "' + str(ontem) + '")' yesterday_week ='WEEK("' + str(ontem) + '")' yesterday_weekday ='WEEKDAY("' + str(ontem) + '")'
Finalmente, vamos construir uma consulta e executá-la. Isso atualizará o dim_time tabela após o commit. Observe que usei o caminho completo para a tabela, incluindo o nome do banco de dados (subscription_dwh ).
query =( "INSERT INTO subscription_dwh.`dim_time`(`time_date`, `time_year`, `time_month`, `time_week`, `time_weekday`, `ts`) " " VALUES (" + yesterday_str + ", " + ontem_ano + ", " + ontem_mês + ", " + ontem_semana + ", " + ontem_semana + ", Now())") cursor.execute(query)
Atualizar a dimensão dim_city
Atualizando o dim_city table é ainda mais simples porque não precisamos testar nada antes da inserção. Na verdade, incluiremos esse teste na consulta SQL.
# 1.2 update dim_cityquery =( "INSERT INTO subscription_dwh.`dim_city`(`city_name`, `postal_code`, `country_name`, `ts`) " "SELECT city_live.city_name, city_live.postal_code, country_live.country_name, Now () " "FROM subscription_live.city city_live " "INNER JOIN subscription_live.country country_live ON city_live.country_id =country_live.id " "LEFT JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name =city_dwh.city_name AND city_live.postal_code =city_dwh.postal_code AND country_live.country_name =city_dwh.country_name " "ONDE cidade_dwh.id É NULO")cursor.execute(consulta)
Aqui preparamos e executamos a consulta SQL. Observe que usei novamente os caminhos completos para as tabelas, incluindo os nomes de ambos os bancos de dados (subscription_live e subscription_dwh ).
Atualizando as Tabelas de Fatos
A última coisa que precisamos fazer é atualizar nossas tabelas de fatos. O processo é quase o mesmo que atualizar as tabelas de dimensão:preparamos as consultas e as executamos. Essas consultas são muito mais complexas, mas são as mesmas usadas nos procedimentos armazenados.
Adicionamos uma melhoria em relação aos procedimentos armazenados:excluindo os dados existentes para a mesma data na tabela de fatos. Isso nos permitirá executar um script várias vezes para a mesma data. No final, precisaremos confirmar a transação e fechar todos os objetos e a conexão.
Executando o script
Temos uma pequena alteração nesta parte, que está chamando um script diferente:
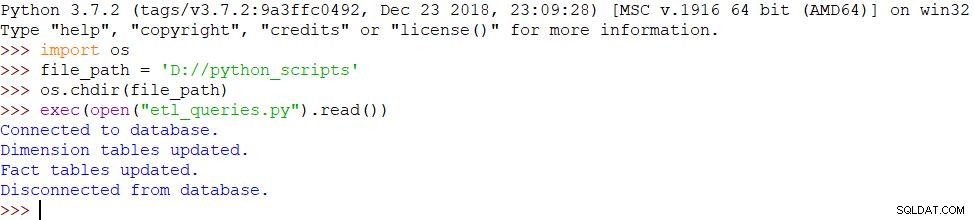
- import os- file_path ='D://python_scripts'- os.chdir(file_path)- exec(open("etl_queries.py").read())
Como usamos as mesmas mensagens e o script foi concluído com sucesso, o resultado é o mesmo:
Como você usaria o Python no ETL?
Hoje vimos um exemplo de execução do processo ETL com um script Python. Existem outras maneiras de fazer isso, por exemplo. uma série de soluções de código aberto que utilizam bibliotecas Python para trabalhar com bancos de dados e realizar o processo de ETL. No próximo artigo, vamos brincar com um deles. Enquanto isso, sinta-se à vontade para compartilhar sua experiência com Python e ETL.