Nesta postagem de blog, examinaremos algumas das principais métricas e status ao monitorar um servidor Percona para MySQL para nos ajudar a ajustar a configuração do servidor MySQL para um longo prazo. Apenas para avisar, o Percona Server tem algumas métricas de monitoramento que estão disponíveis apenas nesta compilação. Ao comparar na versão 8.0.20, os 51 status a seguir estão disponíveis apenas no Percona Server for MySQL, que não estão disponíveis no MySQL Community Server do Oracle upstream:
- Binlog_snapshot_file
- Binlog_snapshot_position
- Binlog_snapshot_gtid_executed
- Com_create_compression_dictionary
- Com_drop_compression_dictionary
- Com_lock_tables_for_backup
- Com_show_client_statistics
- Com_show_index_statistics
- Com_show_table_statistics
- Com_show_thread_statistics
- Com_show_user_statistics
- Innodb_background_log_sync
- Innodb_buffer_pool_pages_LRU_flushed
- Innodb_buffer_pool_pages_made_not_young
- Innodb_buffer_pool_pages_made_young
- Innodb_buffer_pool_pages_old
- Innodb_checkpoint_age
- Innodb_ibuf_free_list
- Innodb_ibuf_segment_size
- Innodb_lsn_current
- Innodb_lsn_flushed
- Innodb_lsn_last_checkpoint
- Innodb_master_thread_active_loops
- Innodb_master_thread_idle_loops
- Innodb_max_trx_id
- Innodb_oldest_view_low_limit_trx_id
- Innodb_pages0_read
- Innodb_purge_trx_id
- Innodb_purge_undo_no
- Innodb_secondary_index_triggered_cluster_reads
- Innodb_secondary_index_triggered_cluster_reads_avoided
- Innodb_buffered_aio_submitted
- Innodb_scan_pages_contiguous
- Innodb_scan_pages_disjointed
- Innodb_scan_pages_total_seek_distance
- Innodb_scan_data_size
- Innodb_scan_deleted_recs_size
- Innodb_scrub_log
- Innodb_scrub_background_page_reorganizations
- Innodb_scrub_background_page_splits
- Innodb_scrub_background_page_split_failures_underflow
- Innodb_scrub_background_page_split_failures_out_of_filespace
- Innodb_scrub_background_page_split_failures_missing_index
- Innodb_scrub_background_page_split_failures_unknown
- Innodb_encryption_n_merge_blocks_encrypted
- Innodb_encryption_n_merge_blocks_decrypted
- Innodb_encryption_n_rowlog_blocks_encrypted
- Innodb_encryption_n_rowlog_blocks_decrypted
- Innodb_encryption_redo_key_version
- Threadpool_idle_threads
- Threadpool_threads
Confira a página Extended InnoDB Status para obter mais informações sobre cada uma das métricas de monitoramento acima. Observe que alguns status extras, como o pool de threads, estão disponíveis apenas no MySQL Enterprise da Oracle. Confira a documentação do Percona Server for MySQL 8.0 para ver todas as melhorias especificamente para esta compilação sobre o MySQL Community Server 8.0 da Oracle.
Para recuperar o status global do MySQL, basta usar uma das seguintes instruções:
mysql> SHOW GLOBAL STATUS;
mysql> SHOW GLOBAL STATUS LIKE '%connect%'; -- list all status that contain string "connect"
mysql> SELECT * FROM performance_schema.global_status;
mysql> SELECT * FROM performance_schema.global_status WHERE VARIABLE_NAME LIKE '%connect%'; -- list all status that contain string "connect"Estado e visão geral do banco de dados
Começaremos com o status de uptime, o número de segundos que o servidor esteve ativo.
Todos os status com_* são as variáveis do contador de instruções que indicam o número de vezes que cada instrução foi executada. Há uma variável de status para cada tipo de instrução. Por exemplo, com_delete e com_update contam as instruções DELETE e UPDATE, respectivamente. O com_delete_multi e com_update_multi são semelhantes, mas se aplicam a instruções DELETE e UPDATE que usam sintaxe de várias tabelas.
Para listar todo o processo em execução pelo MySQL, basta executar uma das seguintes instruções:
mysql> SHOW PROCESSLIST;
mysql> SHOW FULL PROCESSLIST;
mysql> SELECT * FROM information_schema.processlist;
mysql> SELECT * FROM information_schema.processlist WHERE command <> 'sleep'; -- list all active processes except 'sleep' command.Conexões e Threads
Conexões atuais
A proporção de conexões atualmente abertas (encadeamento de conexão). Se a proporção for alta, isso indica que há muitas conexões simultâneas com o servidor MySQL e pode levar a um erro "Muitas conexões". Para obter a porcentagem de conexão:
Current connections(%) = (threads_connected / max_connections) x 100Um bom valor deve ser de 80% e abaixo. Tente aumentar a variável max_connections ou inspecione as conexões usando SHOW FULL PROCESSLIST. Quando ocorrerem erros de "Muitas conexões", o servidor de banco de dados MySQL ficará indisponível para o não superusuário até que algumas conexões sejam liberadas. Observe que aumentar a variável max_connections também pode aumentar o consumo de memória do MySQL.
Máximo de conexões já vistas
A proporção de conexões máximas com o servidor MySQL que já foi vista. Um cálculo simples seria:
Max connections ever seen(%) = (max_used_connections / max_connections) x 100O bom valor deve estar abaixo de 80%. Se a proporção for alta, isso indica que o MySQL atingiu um número alto de conexões que levaria a um erro de 'muitas conexões'. Inspecione a proporção de conexões atuais para ver se ela está realmente baixa de forma consistente. Caso contrário, aumente a variável max_connections. Verifique o status max_used_connections_time para indicar quando o status max_used_connections atingiu seu valor atual.
Taxa de acertos do cache de threads
O status de threads_created é o número de threads criados para lidar com conexões. Se threads_created for grande, você pode querer aumentar o valor thread_cache_size. A taxa de acertos/erros do cache pode ser calculada como:
Threads cache hit rate (%) = (threads_created / connections) x 100É uma fração que indica a taxa de acertos do cache de thread. Quanto mais próximo menos de 50%, melhor. Se o seu servidor vê centenas de conexões por segundo, você deve normalmente definir thread_cache_size alto o suficiente para que a maioria das novas conexões usem threads em cache.
Desempenho da consulta
Verificações de tabela completa
A proporção de varreduras completas da tabela, uma operação que requer a leitura de todo o conteúdo de uma tabela, em vez de apenas partes selecionadas usando um índice. Esse valor é alto se você estiver fazendo muitas consultas que exigem classificação de resultados ou varreduras de tabela. Geralmente, isso sugere que as tabelas não estão indexadas corretamente ou que suas consultas não são escritas para aproveitar os índices que você possui. Para calcular a porcentagem de varreduras de tabela completas:
Full table scans (%) = (handler_read_rnd_next + handler_read_rnd) /
(handler_read_rnd_next + handler_read_rnd + handler_read_first + handler_read_next + handler_read_key + handler_read_prev)
x 100O bom valor deve estar abaixo de 25%. Examine a saída do log de consulta lenta do MySQL para descobrir as consultas abaixo do ideal.
Selecionar associação completa
O status de select_full_join é o número de junções que executam varreduras de tabela porque não usam índices. Se este valor não for 0, você deve verificar cuidadosamente os índices de suas tabelas.
Selecionar verificação de intervalo
O status de select_range_check é o número de junções sem chaves que verificam o uso de chaves após cada linha. Se não for 0, você deve verificar cuidadosamente os índices de suas tabelas.
Classificar passes
A proporção de passagens de mesclagem que o algoritmo de classificação teve que fazer. Se esse valor for alto, você deve considerar aumentar o valor de sort_buffer_size e read_rnd_buffer_size. Um cálculo de razão simples é:
Sort passes = sort_merge_passes / (sort_scan + sort_range)Um valor de razão inferior a 3 deve ser um bom valor. Se você quiser aumentar o sort_buffer_size ou read_rnd_buffer_size, tente aumentar em pequenos incrementos até atingir a proporção aceitável.
Desempenho do InnoDB
Taxa de acerto do conjunto de buffers do InnoDB
A proporção da frequência com que suas páginas são recuperadas da memória em vez do disco. Se o valor for baixo durante a inicialização inicial do MySQL, aguarde algum tempo para o buffer pool aquecer. Para obter a taxa de acertos do buffer pool, use a instrução SHOW ENGINE INNODB STATUS:
mysql> SHOW ENGINE INNODB STATUS\G
...
----------------------
BUFFER POOL AND MEMORY
----------------------
...
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000
...O melhor valor é a taxa de acerto de 1000/10000. Para um valor menor, por exemplo, a taxa de acerto de 986/1000 indica que de 1000 leituras de página, ele conseguiu ler páginas na RAM 986 vezes. Nas 14 vezes restantes, o MySQL teve que ler as páginas do disco. Simplificando, 1000 / 1000 é o melhor valor que estamos tentando alcançar aqui, o que significa que os dados acessados com frequência se encaixam totalmente na RAM.
Aumentar a variável innodb_buffer_pool_size ajudará muito a acomodar mais espaço para o MySQL trabalhar. No entanto, certifique-se de ter recursos de RAM suficientes com antecedência. A remoção de índices redundantes também pode ajudar. Se você tiver várias instâncias de buffer pool, certifique-se de que a taxa de acertos para cada instância atinja 1.000/1.000.
Páginas sujas do InnoDB
A proporção de quantas vezes o InnoDB precisa ser liberado. Durante a carga pesada de gravação, é normal que essa porcentagem aumente.
Um cálculo simples seria:
InnoDB dirty pages(%) = (innodb_buffer_pool_pages_dirty / innodb_buffer_pool_pages_total) x 100Um bom valor deve ser de 75% e abaixo. Se a porcentagem de páginas sujas permanecer alta por muito tempo, convém aumentar o pool de buffers ou obter discos mais rápidos para evitar gargalos de desempenho.
InnoDB Aguarda Checkpoint
A proporção de quantas vezes o InnoDB precisa ler ou criar uma página onde não há páginas limpas disponíveis. Normalmente, as gravações no InnoDB Buffer Pool acontecem em segundo plano. No entanto, se for necessário ler ou criar uma página e não houver páginas limpas disponíveis, também é necessário aguardar que as páginas sejam liberadas primeiro. O contador innodb_buffer_pool_wait_free conta quantas vezes isso aconteceu. Para calcular a proporção de esperas do InnoDB para checkpoints, podemos usar o seguinte cálculo:
InnoDB waits for checkpoint = innodb_buffer_pool_wait_free / innodb_buffer_pool_write_requestsSe innodb_buffer_pool_wait_free for maior que 0, é um forte indicador de que o buffer pool do InnoDB é muito pequeno e as operações tiveram que esperar por um checkpoint. Aumentar o innodb_buffer_pool_size geralmente diminuirá o innodb_buffer_pool_wait_free, assim como essa proporção. Um bom valor de razão deve ficar abaixo de 1.
InnoDB Aguarda Redolog
A proporção de contenção de redo log. Verifique innodb_log_waits e, se continuar aumentando, aumente o innodb_log_buffer_size. Também pode significar que os discos estão muito lentos e não podem sustentar a E/S do disco, talvez devido ao pico de carga de gravação. Use o seguinte cálculo para calcular a taxa de espera do log de redo:
InnoDB waits for redolog = innodb_log_waits / innodb_log_writesUm bom valor de proporção deve estar abaixo de 1. Caso contrário, aumente o innodb_log_buffer_size.
Tabelas
Uso do cache de tabela
A proporção de uso do cache de tabela para todos os encadeamentos. Um cálculo simples seria:
Table cache usage(%) = (opened_tables / table_open_cache) x 100O bom valor deve ser inferior a 80%. Aumente a variável table_open_cache até que a porcentagem atinja um bom valor.
Taxa de acertos do cache de tabela
A proporção do uso de acertos do cache de tabela. Um cálculo simples seria:
Table cache hit ratio(%) = (open_tables / opened_tables) x 100Um bom valor de taxa de acertos deve ser de 90% e acima. Caso contrário, aumente a variável table_open_cache até que a taxa de acertos atinja um bom valor.
Monitoramento de métricas com ClusterControl
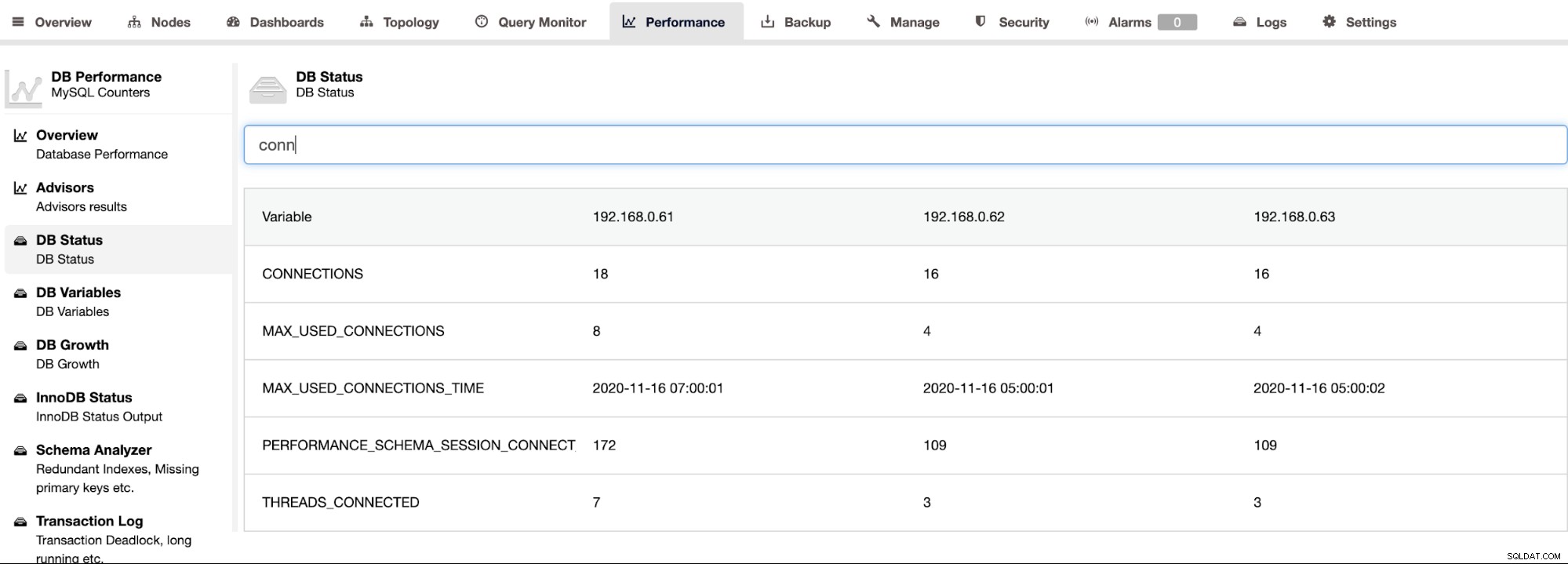
O ClusterControl é compatível com o Percona Server for MySQL e fornece uma visualização agregada de todos os nós em um cluster na página ClusterControl -> Performance -> DB Status. Isso fornece uma abordagem centralizada para procurar todos os status em todos os hosts com a capacidade de filtrar o status, conforme mostrado na captura de tela a seguir:
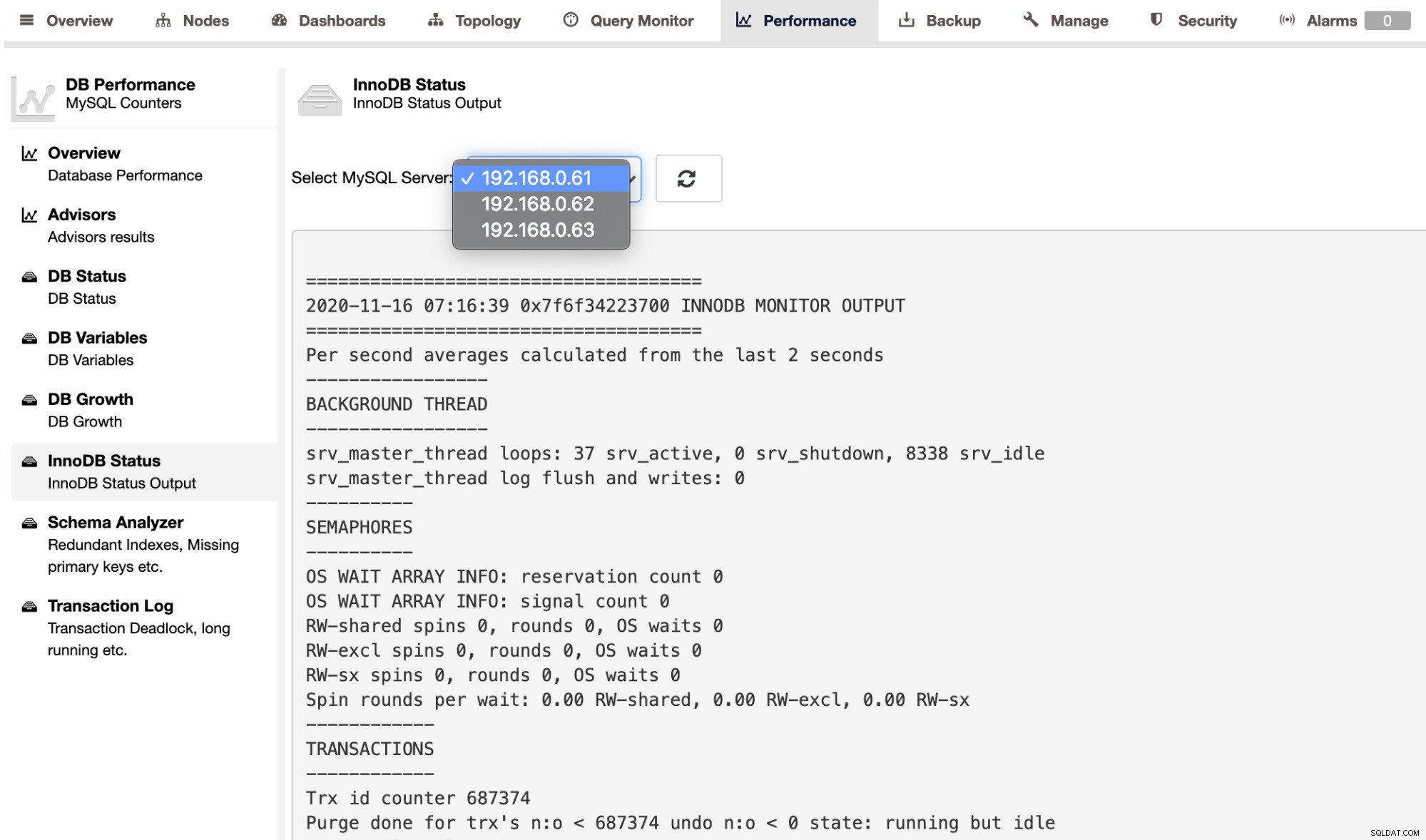
Para recuperar a saída SHOW ENGINE INNODB STATUS para um servidor individual, você pode use a página Desempenho -> Status do InnoDB, conforme mostrado abaixo:
ClusterControl também fornece consultores integrados que você pode usar para rastrear seu banco de dados atuação. Esse recurso está acessível em ClusterControl -> Performance -> Advisors:
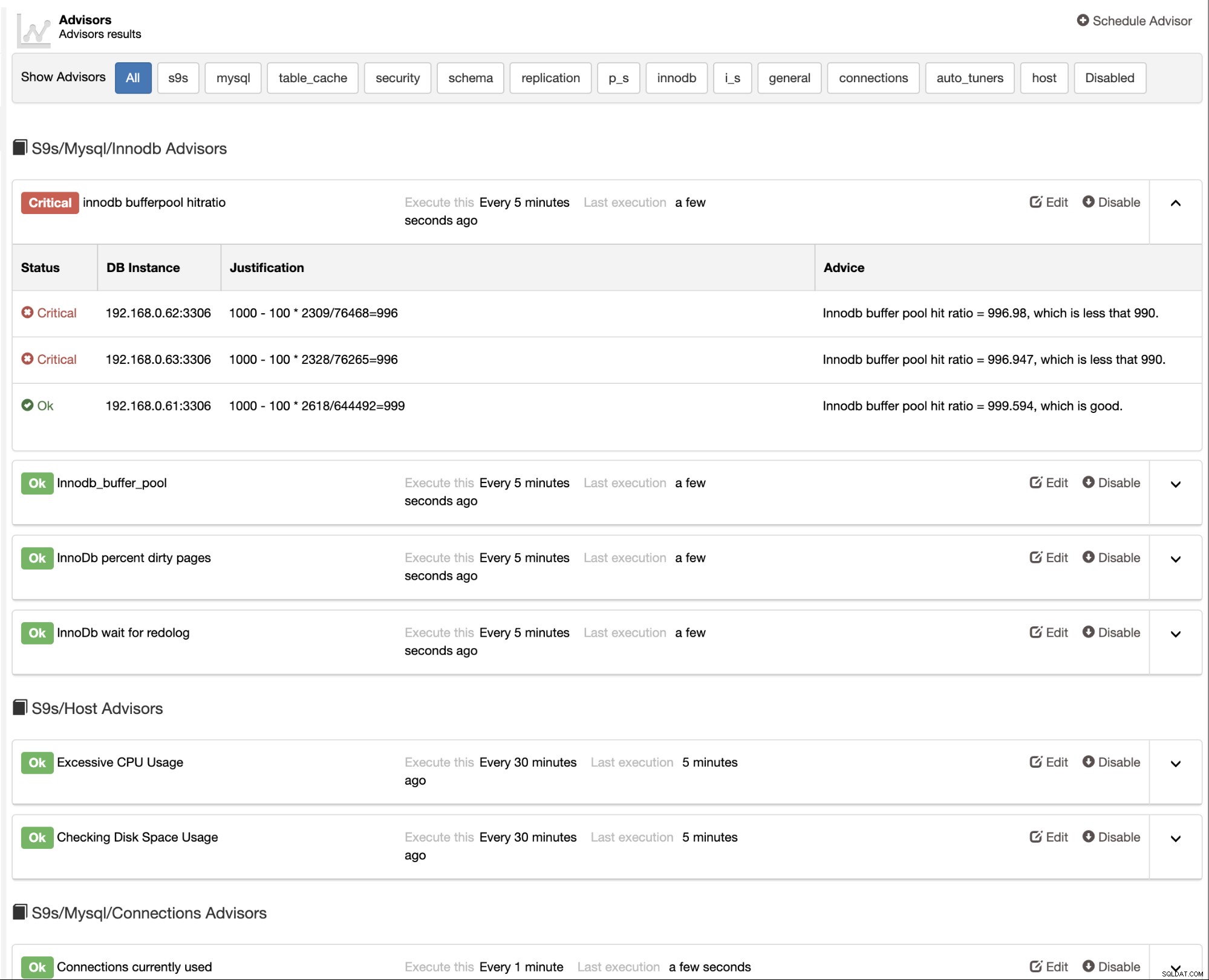
Advisors são basicamente miniprogramas executados pelo ClusterControl em um tempo programado como cron empregos. Você pode agendar um orientador clicando no botão "Agendar Orientador" e escolher qualquer orientador existente na árvore de objetos do Developer Studio:
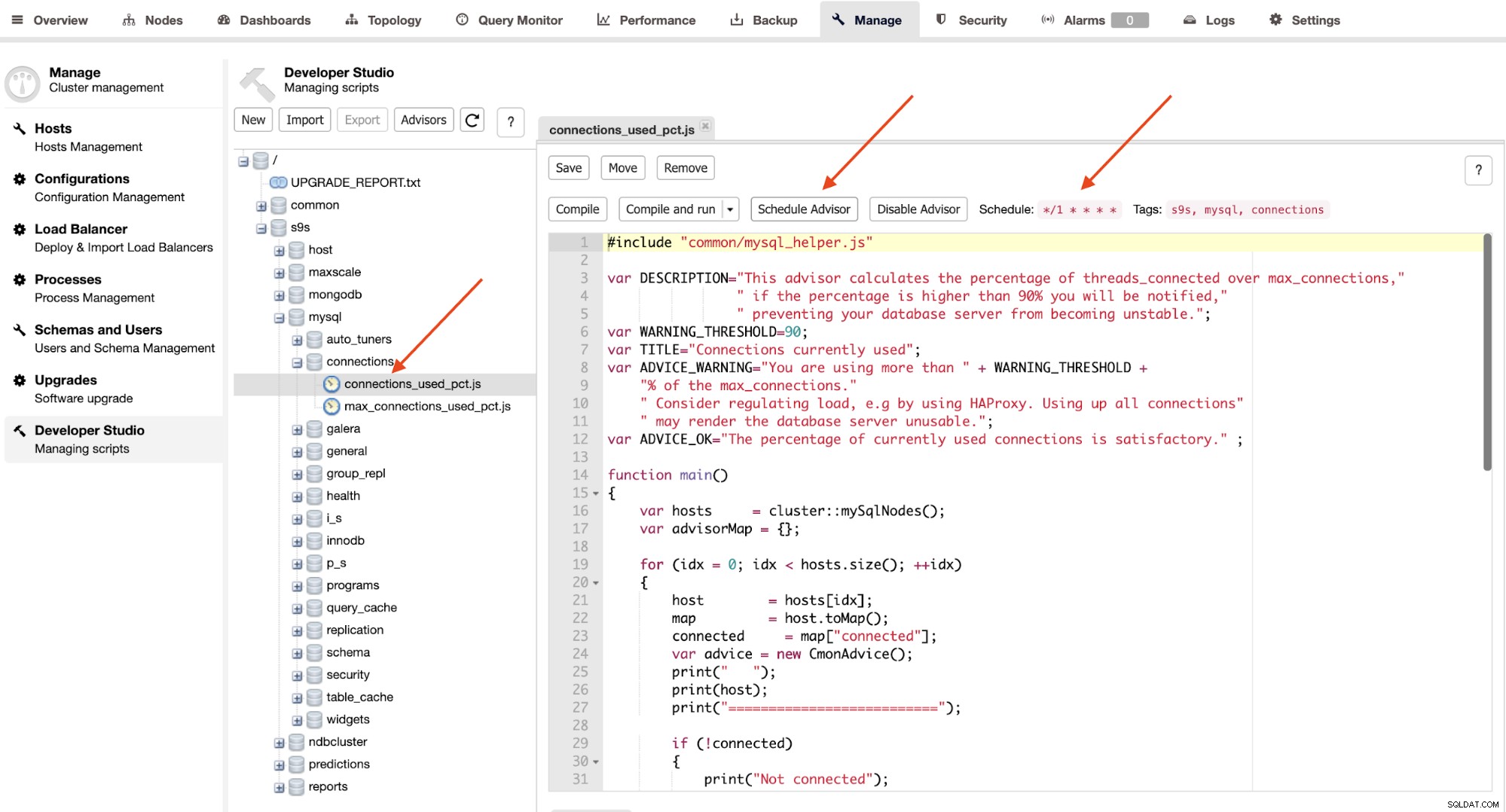
Clique no botão "Schedule Advisor" para definir o agendamento, argumento para passe e também as tags do orientador. Você também pode compilar o orientador para ver a saída imediatamente clicando no botão "Compilar e executar", onde você verá a seguinte saída em "Mensagens" abaixo dela:

Você pode criar seu próprio orientador consultando este Guia do desenvolvedor, escrito em ClusterControl Domain Specific Language (muito semelhante ao Javascript) ou personalize um orientador existente para se adequar às suas políticas de monitoramento. Resumindo, a função de monitoramento do ClusterControl pode ser estendida com possibilidades ilimitadas através do ClusterControl Advisors.