MySQL é fácil de instalar e usar, sempre foi popular entre desenvolvedores e administradores de sistema. Por outro lado, implantar um ambiente MySQL pronto para produção para uma carga de trabalho empresarial crítica é uma história diferente. Pode ser um pouco desafiador e requer um conhecimento profundo do banco de dados. Nesta postagem do blog, discutiremos algumas das etapas que devem ser seguidas antes que possamos considerar nossa implantação do MySQL pronta para produção.
Alta disponibilidade

Se você pertence aos sortudos que podem aceitar horas de inatividade, pode parar de ler aqui e pular para o próximo parágrafo. Para 99,999% dos sistemas críticos para os negócios, isso não seria aceitável. Portanto, uma implantação pronta para produção deve incluir medidas de alta disponibilidade. Failover automatizado das instâncias de banco de dados, bem como uma camada de proxy que detecta mudanças na topologia e estado do MySQL e roteia o tráfego de acordo, seria um requisito principal. Existem inúmeras ferramentas que podem ser usadas para construir tais ambientes, por exemplo MHA, MRM ou ClusterControl.
Camada proxy
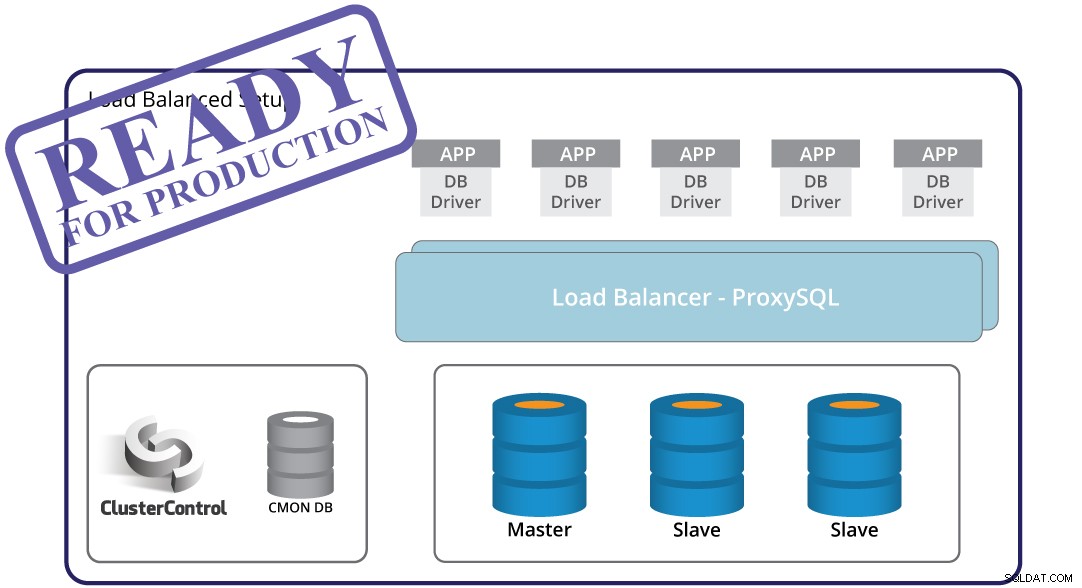
Detecção de falhas mestre, failover automatizado e recuperação - estes são cruciais ao construir uma infraestrutura pronta para produção. Mas por si só, não é suficiente. Ainda há um aplicativo que terá que se adaptar à mudança de topologia desencadeada pelo failover. Obviamente, é possível codificar o aplicativo para que ele esteja ciente das falhas da instância. Essa é uma maneira complicada e inflexível de lidar com alterações de topologia. Aí vem o proxy do banco de dados - uma camada intermediária entre o aplicativo e o banco de dados. Um proxy pode ocultar a complexidade de sua camada de banco de dados do aplicativo - tudo o que o aplicativo faz é conectar-se ao proxy e o proxy cuidará do resto. O proxy roteará as consultas para uma instância do banco de dados, manipulará as alterações de topologia e roteará novamente conforme necessário. Um proxy também pode ser usado para implementar a divisão de leitura e gravação, liberando o aplicativo de mais um caso complexo para cobrir. Isso cria outro desafio - qual proxy usar? Como configurá-lo? Como monitorá-lo? Como torná-lo altamente disponível, para que não se torne um SPOF?
ClusterControl pode ajudar aqui. Ele pode ser usado para implantar diferentes proxies para formar uma camada de proxy:ProxySQL, HAProxy e MaxScale. Ele pré-configura os proxies para garantir que eles tratem o tráfego corretamente. Também facilita a implementação de quaisquer alterações de configuração se você precisar personalizar a configuração de proxy para seu aplicativo. A divisão de leitura-gravação pode ser configurada usando qualquer um dos proxies que o ClusterControl suporta. O ClusterControl também monitora os proxies e os recupera em caso de falhas. A camada de proxy pode se tornar um único ponto de falha, pois a recuperação automatizada pode não ser suficiente - para resolver isso, o ClusterControl pode implantar o Keepalived e configurar o IP virtual para automatizar o failover.
Backups
Mesmo que você não precise implementar a alta disponibilidade, provavelmente ainda precisará se preocupar com seus dados. O backup é uma obrigação para quase todos os bancos de dados de produção. Nada mais do que um backup pode salvá-lo de um DROP TABLE ou DROP SCHEMA acidental (bem, talvez um escravo de replicação atrasado, mas apenas por algum período de tempo). O MySQL oferece vários métodos de fazer backups - mysqldump, xtrabackup, diferentes tipos de instantâneos (alguns disponíveis apenas com um determinado hardware ou provedor de nuvem). Não é fácil projetar a estratégia de backup correta, decidir quais ferramentas usar e, em seguida, fazer o script de todo o processo para que ele seja executado corretamente. Também não é ciência de foguetes e requer planejamento e testes cuidadosos. Uma vez que um backup é feito, você não terminou. Tem certeza de que o backup pode ser restaurado e os dados não são lixo? Verificar seus backups é demorado e talvez não seja a coisa mais interessante que você terá em sua lista de tarefas. Mas ainda é importante e precisa ser feito regularmente.
O ClusterControl possui ampla funcionalidade de backup e restauração. Ele suporta mysqldump para backup lógico e Percona Xtrabackup para backup físico - essas ferramentas podem ser usadas em quase todos os ambientes, na nuvem ou no local. É possível construir uma estratégia de backup com uma mistura de backups lógicos e físicos, incrementais ou completos, de forma online.
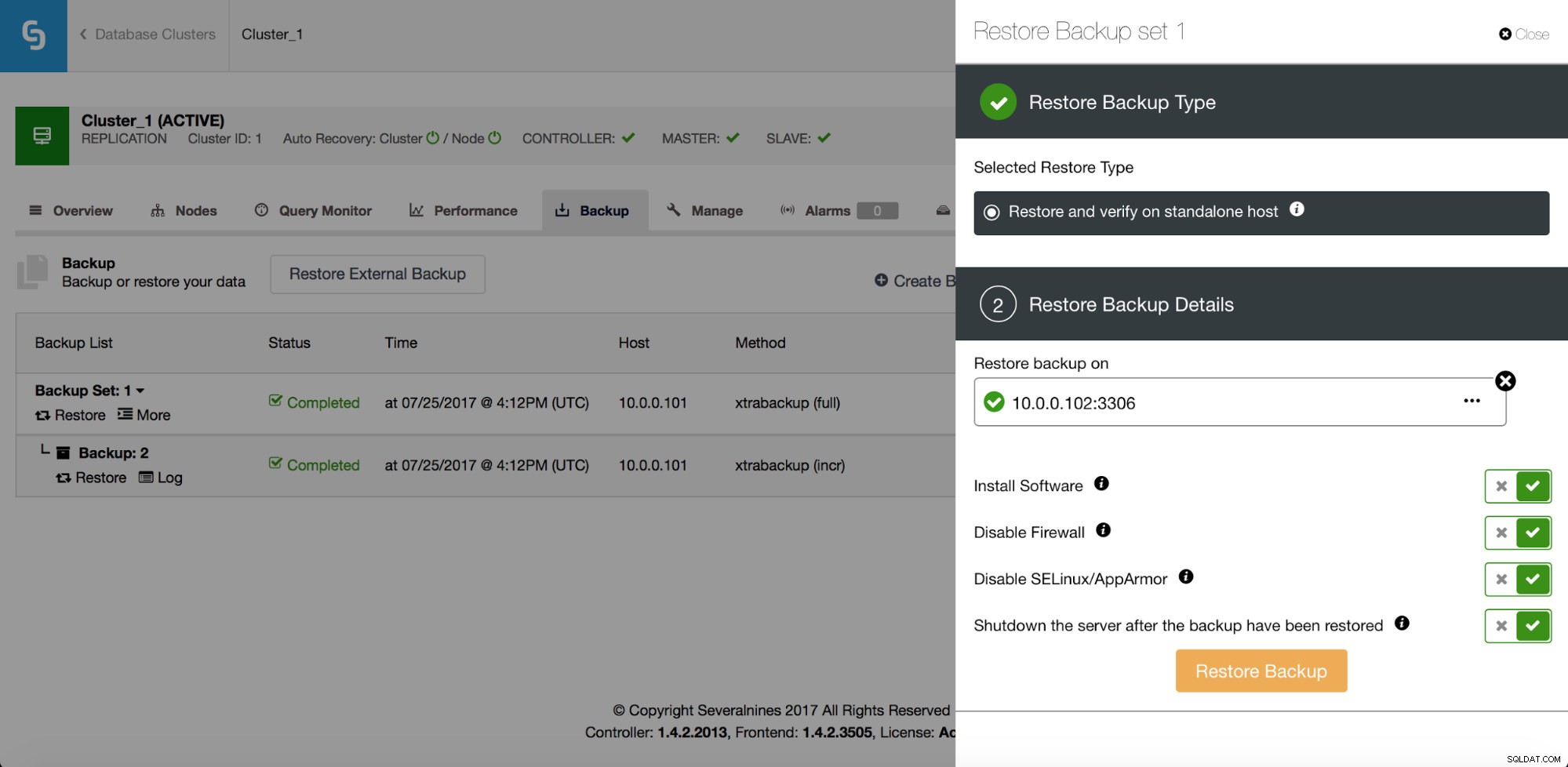
Além da recuperação, ele também tem opções para verificar um backup - por exemplo, restaurá-lo em um host separado para verificar se o processo de backup funciona bem ou não.
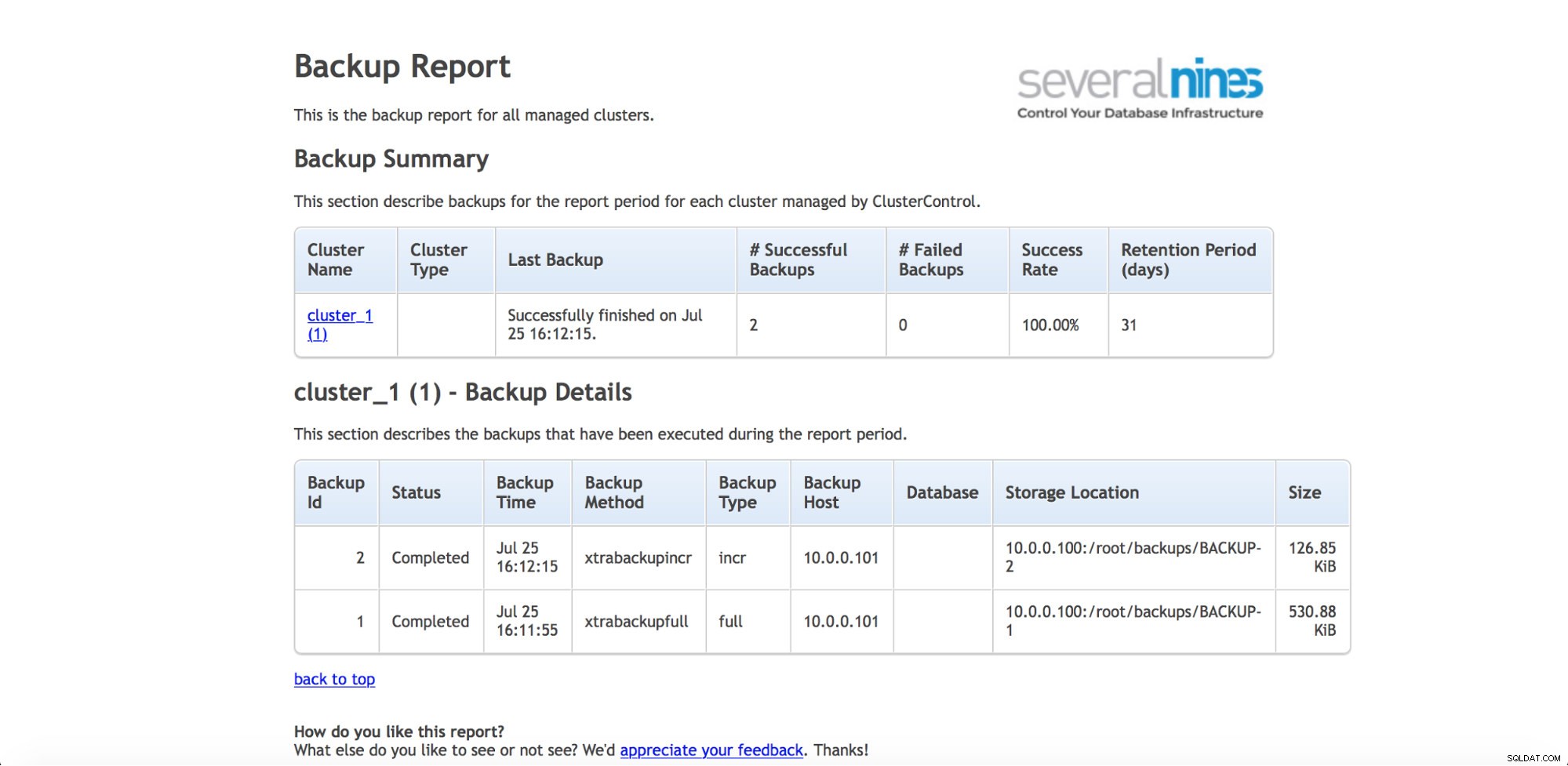
Se você deseja ficar de olho nos backups regularmente (e provavelmente gostaria de fazer isso), o ClusterControl tem a capacidade de gerar relatórios operacionais. O relatório de backup ajuda a rastrear os backups executados e informa se houve algum problema ao fazê-los.
Guia de DevOps para gerenciamento de banco de dados de vários novesSaiba mais sobre o que você precisa saber para automatizar e gerenciar seus bancos de dados de código abertoBaixe gratuitamente
Monitoramento e tendências

Nenhuma implantação está pronta para produção sem o monitoramento adequado dos serviços. Você quer ter certeza de que será alertado se alguns serviços ficarem indisponíveis para que você possa tomar uma ação, investigar ou iniciar procedimentos de recuperação. Claro, você também quer ter uma solução de tendências também. Não é demais enfatizar o quão importante é ter dados de monitoramento para avaliar o estado da infraestrutura ou para qualquer investigação, seja post-mortem ou monitoramento em tempo real do estado dos serviços. As métricas não são iguais em importância - se você não estiver muito familiarizado com um determinado produto de banco de dados, provavelmente não saberá quais são as métricas mais importantes a serem coletadas e observadas. Claro, você pode coletar tudo, mas quando se trata de revisar dados, dificilmente é possível passar por centenas de métricas por host - você precisa saber em qual delas deve se concentrar.
O mundo do código aberto está cheio de ferramentas projetadas para monitorar e coletar métricas de diferentes bancos de dados - a maioria delas exigiria que você as integrasse à sua infraestrutura geral de monitoramento, plataforma de chatops ou ferramentas de suporte oncall (como PagerDuty). Também pode ser necessário instalar e integrar vários componentes - armazenamento (algum tipo de banco de dados de séries temporais), camada de apresentação e ferramentas de coleta de dados.
O ClusterControl é uma abordagem um pouco diferente, pois é um único produto com monitoramento em tempo real, tendências e painéis que mostram os detalhes mais importantes. Os orientadores de banco de dados, que podem ser desde simples conselhos de configuração, avisos sobre limites ou regras mais complexas para previsões, geralmente produzem recomendações abrangentes.
Capacidade de expansão

Os bancos de dados tendem a crescer em tamanho e não é improvável que cresçam em termos de volumes de transações ou número de usuários. A capacidade de expandir ou aumentar pode ser crítica para a produção. Mesmo que você faça um ótimo trabalho ao estimar seus requisitos de hardware no início do ciclo de vida do produto, provavelmente terá que lidar com uma fase de crescimento - desde que seu produto seja bem-sucedido (mas é para isso que todos planejamos, certo ?). Você precisa ter os meios para escalar facilmente sua infraestrutura para lidar com a carga de entrada. Para serviços sem estado, como servidores da Web, isso é bastante fácil - você só precisa provisionar mais instâncias usando a imagem ou código de produção mais recente de sua ferramenta de controle de versão. Para serviços com estado, como bancos de dados, é mais complicado. Você precisa provisionar novas instâncias usando seus dados de produção atuais, configurar a replicação ou alguma forma de cluster entre as instâncias atuais e as novas. Esse pode ser um processo complexo e, para acertar, você precisa ter um conhecimento mais aprofundado do modelo de cluster ou replicação escolhido.
ClusterControl, como o nome sugere, fornece suporte extensivo para a criação de configurações de banco de dados em cluster ou replicadas. Os métodos usados são testados em batalha através de milhares de implantações. Ele vem com uma interface de linha de comando (CLI) para que possa ser facilmente integrado aos sistemas de gerenciamento de configuração. No entanto, lembre-se de que talvez você não queira fazer alterações em seu pool de bancos de dados com muita frequência - o provisionamento de uma nova instância leva tempo e adiciona alguma sobrecarga nos bancos de dados existentes. Portanto, você pode querer ficar um pouco “superprovisionado” para ter algum tempo para ativar uma nova instância antes que seu cluster fique sobrecarregado.
Em suma, há várias etapas que você ainda precisa seguir após a implantação inicial, para garantir que seu ambiente esteja pronto para produção. Com as ferramentas certas, é muito mais fácil chegar lá.