O desempenho de consulta ruim é o problema mais comum com o qual os DBAs precisam lidar. Existem várias maneiras de coletar, processar e analisar os dados relacionados ao desempenho da consulta - abordamos uma das ferramentas mais populares, pt-query-digest, em alguns de nossos posts anteriores:
Torne-se uma série de blogs MySQL DBA
- Analisando sua carga de trabalho SQL usando pt-query-digest
- Análise de carga de trabalho SQL detalhada usando pt-query-digest
No entanto, quando você usa o ClusterControl, isso nem sempre é necessário. Você pode usar os dados disponíveis no ClusterControl para resolver seu problema. Nesta postagem do blog, veremos como o ClusterControl pode ajudá-lo a resolver problemas relacionados ao desempenho da consulta.
Pode acontecer que uma consulta não possa ser concluída em tempo hábil. A consulta pode estar travada devido a alguns problemas de bloqueio, pode não ser ideal ou não indexada corretamente ou pode ser muito pesada para ser concluída em um período de tempo razoável. Lembre-se de que algumas junções não indexadas podem examinar facilmente bilhões de linhas se você tiver um grande banco de dados de produção. O que quer que tenha acontecido, a consulta provavelmente está usando alguns dos recursos - seja CPU ou E/S para uma consulta não otimizada ou até mesmo bloqueios de linha. Esses recursos também são necessários para outras consultas e isso pode atrasar seriamente as coisas. Uma das tarefas muito simples, mas importantes, seria identificar a consulta incorreta e interrompê-la.
Isso é feito facilmente a partir da interface do ClusterControl. Vá para a guia Query Monitor -> seção Running Queries - você deve ver uma saída semelhante à captura de tela abaixo.
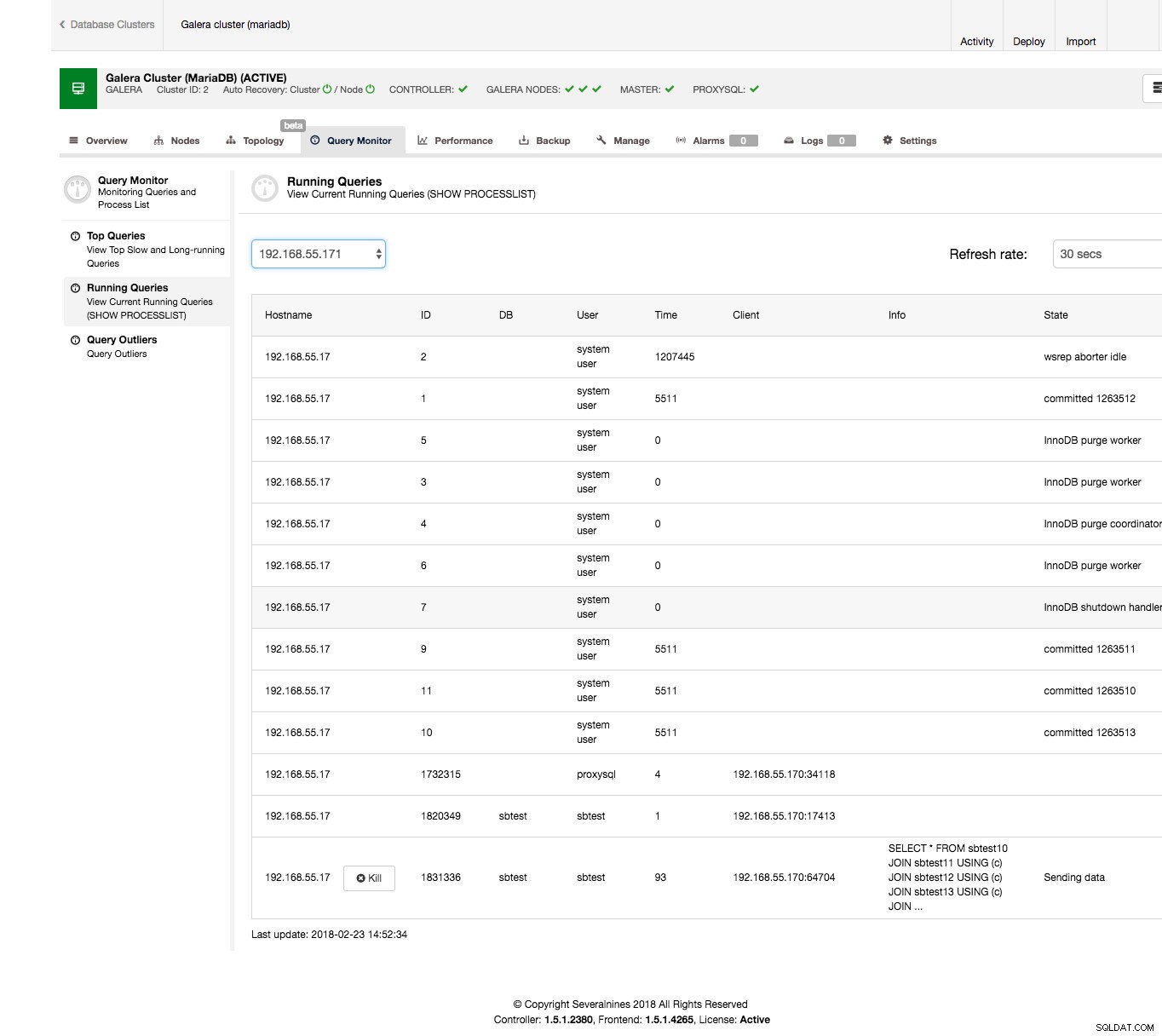
Como você pode ver, temos uma pilha de consultas travadas. Normalmente, a consulta ofensiva é aquela que leva muito tempo, você pode querer eliminá-la. Você também pode querer investigá-lo mais para ter certeza de escolher o correto. No nosso caso, vemos claramente um SELECT … FOR UPDATE que une algumas tabelas e que está no estado ‘Enviando dados’, o que significa que está processando os dados, nos últimos 90 segundos.
Outro tipo de pergunta que um DBA pode precisar responder é - quais consultas levam mais tempo para serem executadas? Essa é uma pergunta comum, pois essas consultas podem ser um fruto fácil - elas podem ser otimizáveis, e quanto mais tempo de execução uma determinada consulta for responsável em todo um mix de consultas, maior será o ganho de sua otimização. É uma equação simples - se uma consulta é responsável por 50% do tempo total de execução, torná-la 10x mais rápida dará um resultado muito melhor do que otimizar uma consulta que é responsável por apenas 1% do tempo total de execução.
O ClusterControl pode ajudá-lo a responder a essas perguntas, mas primeiro precisamos garantir que o Query Monitor esteja ativado. Você pode alternar o Query Monitor para ON na página Query Monitor. Além disso, você pode configurar a opção "Long Query Time" e "Log queries not using indexes" em Settings para se adequar à sua carga de trabalho:
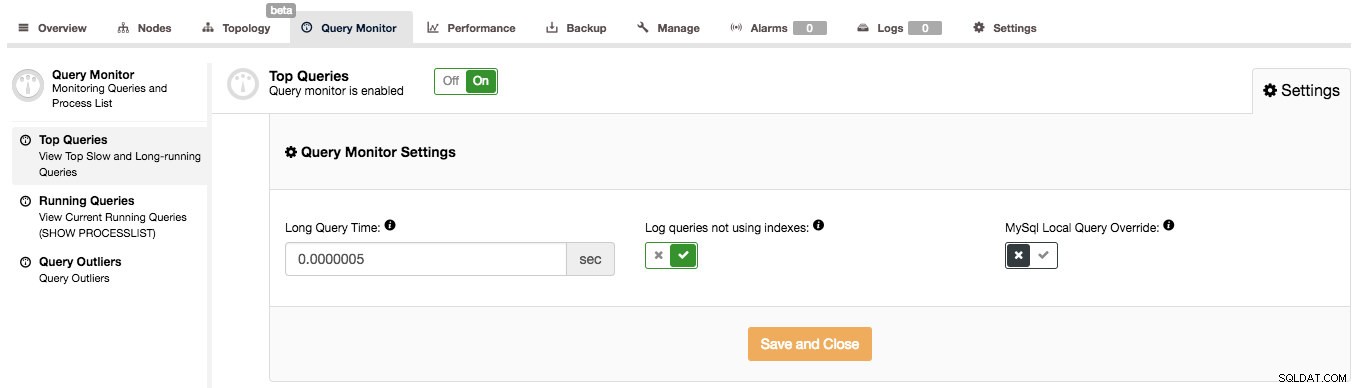
O Monitor de Consultas no ClusterControl funciona em dois modos, dependendo se você tem o Esquema de Desempenho disponível com os dados necessários nas consultas em execução ou não. Se estiver disponível (e isso é verdade por padrão no MySQL 5.6 e mais recente), o Performance Schema será usado para coletar dados de consulta, minimizando o impacto no sistema. Caso contrário, o log de consulta lenta será usado e todas as configurações visíveis na captura de tela acima serão usadas. Esses são muito bem explicados na interface do usuário, então não há necessidade de fazer isso aqui. Quando o Query Monitor usa o Performance Schema, essas configurações não são usadas (exceto para ativar/desativar o Query Monitor para ativar/desativar a coleta de dados).
Ao confirmar que o Query Monitor está habilitado no ClusterControl, você pode ir para Query Monitor -> Top Queries, onde será apresentada uma tela semelhante à abaixo:
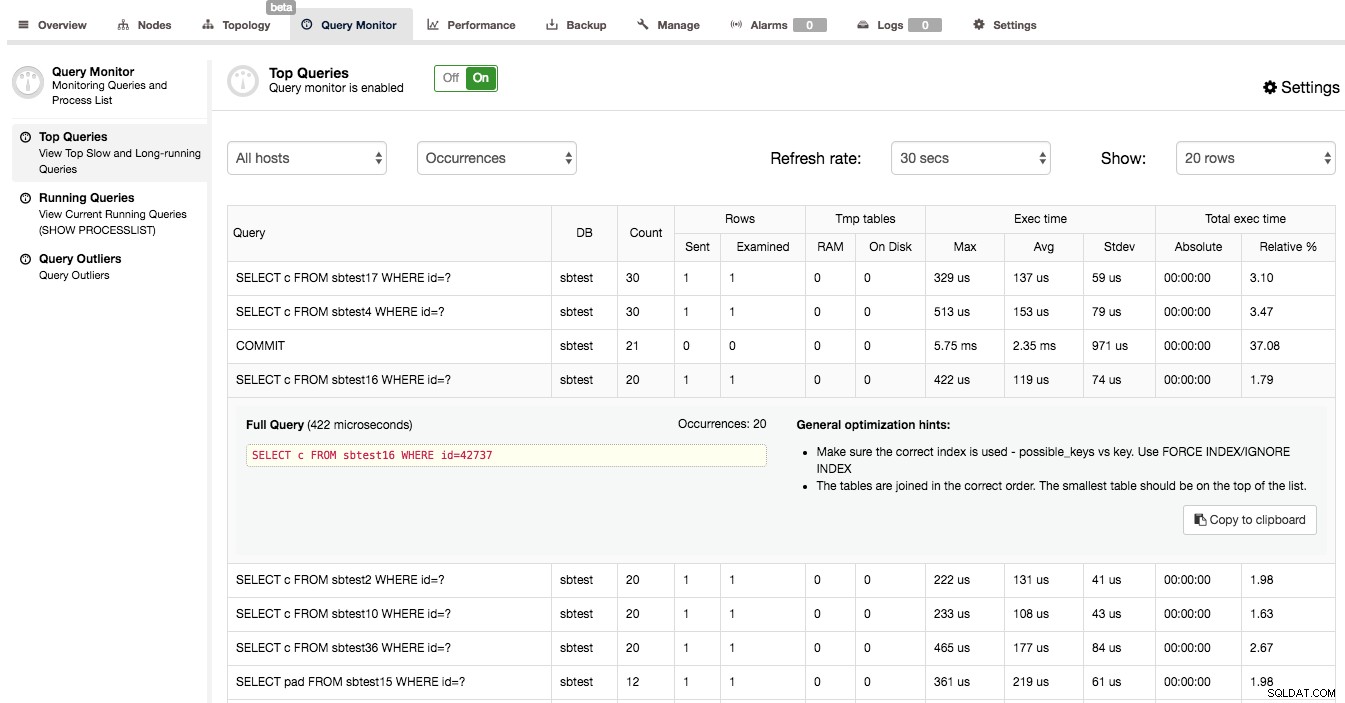
O que você pode ver aqui é uma lista das consultas mais caras (em termos de tempo de execução) que atingem nosso cluster. Cada um deles tem mais alguns detalhes - quantas vezes foi executado, quantas linhas foram examinadas ou enviadas ao cliente, como o tempo de execução variou, quanto tempo o cluster gastou na execução de um determinado tipo de consulta. As consultas são agrupadas por tipo de consulta e esquema.
Você pode se surpreender ao descobrir que o principal local onde o tempo de execução é gasto é uma consulta 'COMMIT'. Na verdade, isso é bastante típico para consultas OLTP rápidas executadas no cluster Galera. A confirmação de uma transação é um processo caro porque a certificação precisa acontecer. Isso faz com que COMMIT seja uma das consultas mais demoradas no conjunto de consultas.
Ao clicar em uma consulta, você pode ver a consulta completa, tempo máximo de execução, número de ocorrências, algumas dicas gerais de otimização e uma saída EXPLAIN para ela - bastante útil para identificar se algo está errado com ela. Em nosso exemplo, verificamos um SELECT … FOR UPDATE com um alto número de linhas examinadas. Como esperado, esta consulta é um exemplo de SQL terrível - um JOIN que não usa nenhum índice. Você pode ver na saída EXPLAIN que nenhum índice é usado, nem um único foi considerado possível de usar. Não é à toa que essa consulta afetou seriamente o desempenho do nosso cluster.
Outra maneira de obter algumas informações sobre o desempenho da consulta é examinar o Query Monitor -> Query Outliers. Esta é basicamente uma lista de consultas cujo desempenho difere significativamente de sua média.
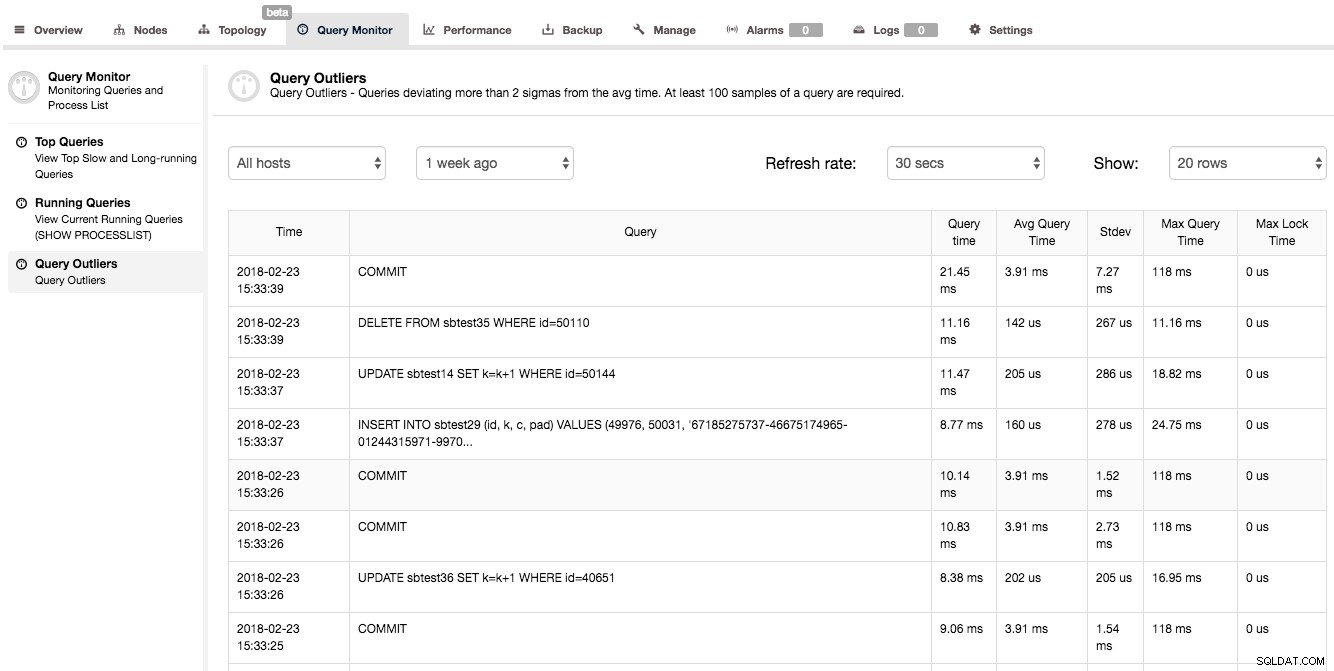
Como você pode ver na captura de tela acima, a segunda consulta levou 0,01116s (o tempo é mostrado em milissegundos), onde o tempo médio de execução para essa consulta é muito menor (0,000142s). Também temos algumas informações estatísticas adicionais sobre o desvio padrão e o tempo máximo de execução da consulta. Essa lista de consultas pode parecer pouco útil - não é verdade. Quando você vê uma consulta nesta lista, significa que algo estava diferente do habitual - a consulta não foi concluída no tempo normal. Pode ser uma indicação de alguns problemas de desempenho em seu sistema e um sinal de que você deve investigar outras métricas e verificar se algo mais aconteceu naquele momento.
As pessoas tendem a se concentrar em alcançar o desempenho máximo, esquecendo que não basta ter alto rendimento - também tem que ser consistente. Os usuários gostam que o desempenho seja estável - você pode extrair mais transações por segundo do seu sistema, mas se isso significar que algumas transações começarão a parar por segundos, não vale a pena. Observar o histograma de consulta no ClusterControl ajuda a identificar esses problemas de consistência em sua combinação de consultas.
Feliz monitoramento de consultas!
PS.:Para começar a usar o ClusterControl, clique aqui!