Construindo alta disponibilidade, um passo de cada vez
Quando se trata de infraestrutura de banco de dados, todos nós a queremos. Todos nós nos esforçamos para construir uma configuração altamente disponível. Redundância é a chave. Começamos a implementar a redundância no nível mais baixo e continuamos subindo a pilha. Começa com hardware - fontes de alimentação redundantes, refrigeração redundante, discos hot-swap. Camada de rede - vários NICs unidos e conectados a diferentes switches que usam roteadores redundantes. Para armazenamento, usamos discos definidos em RAID, o que oferece melhor desempenho, mas também redundância. Então, no nível de software, usamos tecnologias de clustering:vários nós de banco de dados trabalhando juntos para implementar a redundância:MySQL Cluster, Galera Cluster.
Tudo isso não é bom se você tiver tudo em um único datacenter:quando um datacenter ficar inativo, ou parte dos serviços (mas importantes) ficar offline, ou mesmo se você perder a conectividade com o datacenter, seu serviço ficará inativo - não importa a quantidade de redundância nos níveis mais baixos. E sim, essas coisas acontecem.
- A interrupção do serviço S3 causou estragos na região US-East-1 em fevereiro de 2017
- Interrupção do serviço EC2 e RDS na região leste dos EUA em abril de 2011
- EC2, EBS e RDS foram interrompidos na região UE-Oeste em agosto de 2011
- A falta de energia derrubou a Rackspace Texas DC em junho de 2009
- Falha no UPS fez com que centenas de servidores ficassem off-line na Rackspace London DC em janeiro de 2010
Esta não é uma lista completa de falhas, é apenas o resultado de uma rápida pesquisa no Google. Estes servem como exemplos de que as coisas podem e vão dar errado se você colocar todos os ovos na mesma cesta. Mais um exemplo seria o furacão Sandy, que causou um enorme êxodo de dados do Leste dos EUA para os DC's do Oeste dos EUA - naquela época você dificilmente poderia criar instâncias no Oeste dos EUA, pois todos corriam para mover sua infraestrutura para a outra costa na expectativa que North Virginia DC será seriamente afetada pelo clima.
Portanto, as configurações de vários datacenters são obrigatórias se você deseja criar um ambiente de alta disponibilidade. Nesta postagem do blog, discutiremos como construir essa infraestrutura usando o Galera Cluster for MySQL/MariaDB.
Conceitos do Galera
Antes de olharmos para soluções específicas, vamos gastar algum tempo explicando dois conceitos que são muito importantes em configurações de Galera multi-DC altamente disponíveis.
Quórum
A alta disponibilidade requer recursos - ou seja, você precisa de vários nós no cluster para torná-lo altamente disponível. Um cluster pode tolerar a perda de alguns de seus membros, mas apenas até certo ponto. Além de uma certa taxa de falha, você pode estar olhando para um cenário de cérebro dividido.
Vamos dar um exemplo com uma configuração de 2 nós. Se um dos nós cair, como o outro pode saber que seu par caiu e não é uma falha de rede? Nesse caso, o outro nó também pode estar funcionando, atendendo ao tráfego. Não há uma boa maneira de lidar com esse caso... É por isso que a tolerância a falhas geralmente começa a partir de três nós. O Galera usa um cálculo de quorum para determinar se é seguro para o cluster manipular o tráfego ou se deve interromper as operações. Após uma falha, todos os nós restantes tentam se conectar uns aos outros e determinar quantos deles estão ativos. Em seguida, ele é comparado ao estado anterior do cluster e, desde que mais de 50% dos nós estejam ativos, o cluster pode continuar operando.
Isso resulta no seguinte:
cluster de 2 nós - sem tolerância a falhas
cluster de 3 nós - até 1 falha
cluster de 4 nós - até 1 falha (se dois nós falhassem, apenas 50% do cluster estaria disponível, você precisa de mais de 50% de nós para sobreviver)
cluster de 5 nós - até 2 falhas
cluster de 6 nós - até 2 falhas
Você provavelmente vê o padrão - você deseja que seu cluster tenha um número ímpar de nós - em termos de alta disponibilidade, não faz sentido passar de 5 para 6 nós no cluster. Se você deseja uma melhor tolerância a falhas, deve optar por 7 nós.
Segmentos
Normalmente, em um cluster Galera, toda a comunicação segue o padrão de todos para todos. Cada nó conversa com todos os outros nós do cluster.
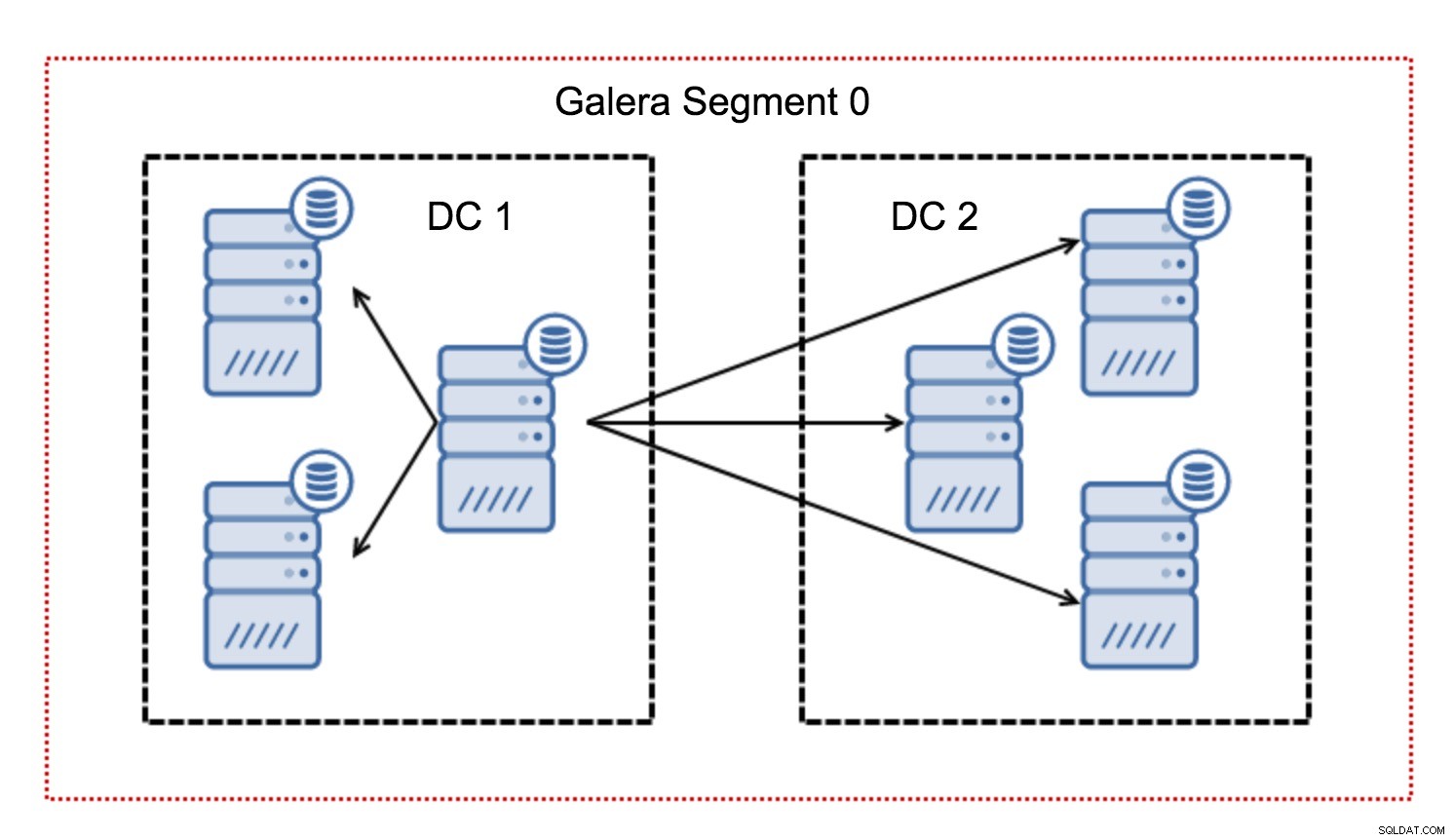
Como você deve saber, cada conjunto de gravação no Galera deve ser certificado por todos os nós do cluster - portanto, cada gravação que ocorreu em um nó deve ser transferida para todos os nós do cluster. Isso funciona bem em um ambiente de baixa latência. Mas se estamos falando de configurações multi-DC, precisamos considerar uma latência muito maior do que em uma rede local. Para torná-lo mais suportável em clusters que abrangem redes de longa distância, a Galera introduziu segmentos.
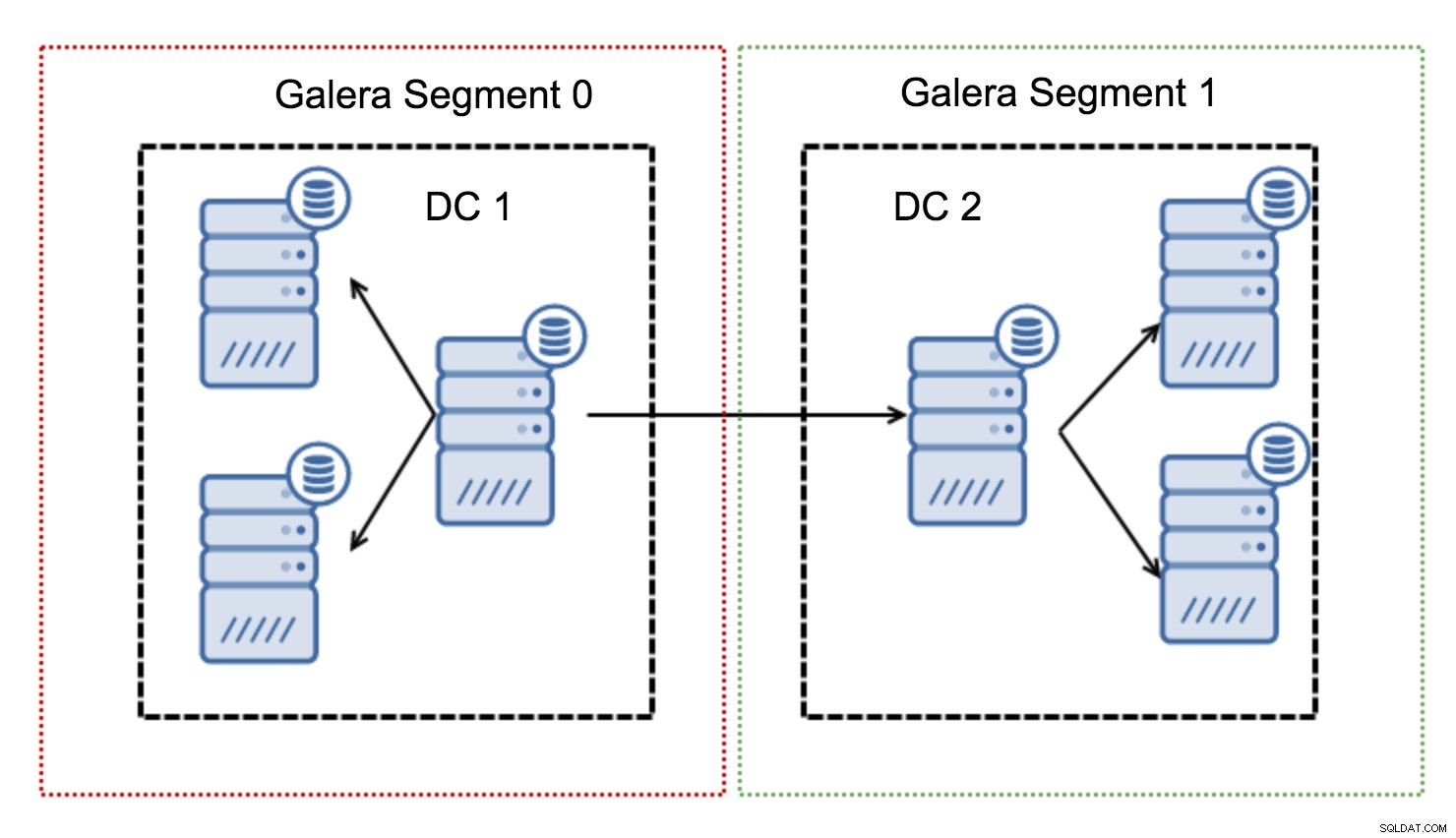
Eles funcionam contendo o tráfego Galera dentro de um grupo de nós (segmento). Todos os nós dentro de um único segmento agem como se estivessem em uma rede local - eles assumem uma comunicação para todos. Para tráfego de segmento cruzado, as coisas são diferentes - em cada um dos segmentos, um nó “relay” é escolhido, todo o tráfego de segmento cruzado passa por esses nós. Quando um nó de retransmissão fica inativo, outro nó é eleito. Isso não reduz muito a latência - afinal, a latência da WAN permanecerá a mesma, não importa se você fizer uma conexão com um host remoto ou com vários hosts remotos, mas considerando que os links WAN tendem a ser limitados em largura de banda e pode haver um cobrar pela quantidade de dados transferidos, essa abordagem permite limitar a quantidade de dados trocados entre segmentos. Outra opção de economia de tempo e custo é o fato de que os nós no mesmo segmento são priorizados quando um doador é necessário - novamente, isso limita a quantidade de dados transferidos pela WAN e, provavelmente, acelera o SST como uma rede local quase sempre será mais rápido que um link WAN.
Agora que tiramos alguns desses conceitos do caminho, vamos ver alguns outros aspectos importantes das configurações multi-DC para o cluster Galera.
Problemas que você está prestes a enfrentar
Ao trabalhar em ambientes que abrangem WAN, há alguns problemas que você precisa levar em consideração ao projetar seu ambiente.
Cálculo de Quórum
Na seção anterior, descrevemos como um cálculo de quorum se parece no cluster Galera - em resumo, você deseja ter um número ímpar de nós para maximizar a capacidade de sobrevivência. Tudo isso ainda é verdade em configurações multi-DC, mas mais alguns elementos são adicionados à mistura. Em primeiro lugar, você precisa decidir se deseja que o Galera lide automaticamente com uma falha do datacenter. Isso determinará quantos datacenters você usará. Vamos imaginar dois DCs - se você dividir seus nós 50% - 50%, se um datacenter cair, o segundo não terá 50%+1 nós para manter seu estado "primário". Se você dividir seus nós de forma desigual, usando a maioria deles no datacenter “principal”, quando esse datacenter cair, o DC “backup” não terá 50% + 1 nós para formar um quorum. Você pode atribuir pesos diferentes aos nós, mas o resultado será exatamente o mesmo - não há como fazer failover automático entre dois DCs sem intervenção manual. Para implementar o failover automatizado, você precisa de mais de dois DCs. Novamente, idealmente um número ímpar - três datacenters é uma configuração perfeitamente adequada. Em seguida, a pergunta é - quantos nós você precisa ter? Você deseja que eles sejam distribuídos uniformemente pelos datacenters. O resto é apenas uma questão de quantos nós com falha sua configuração precisa lidar.
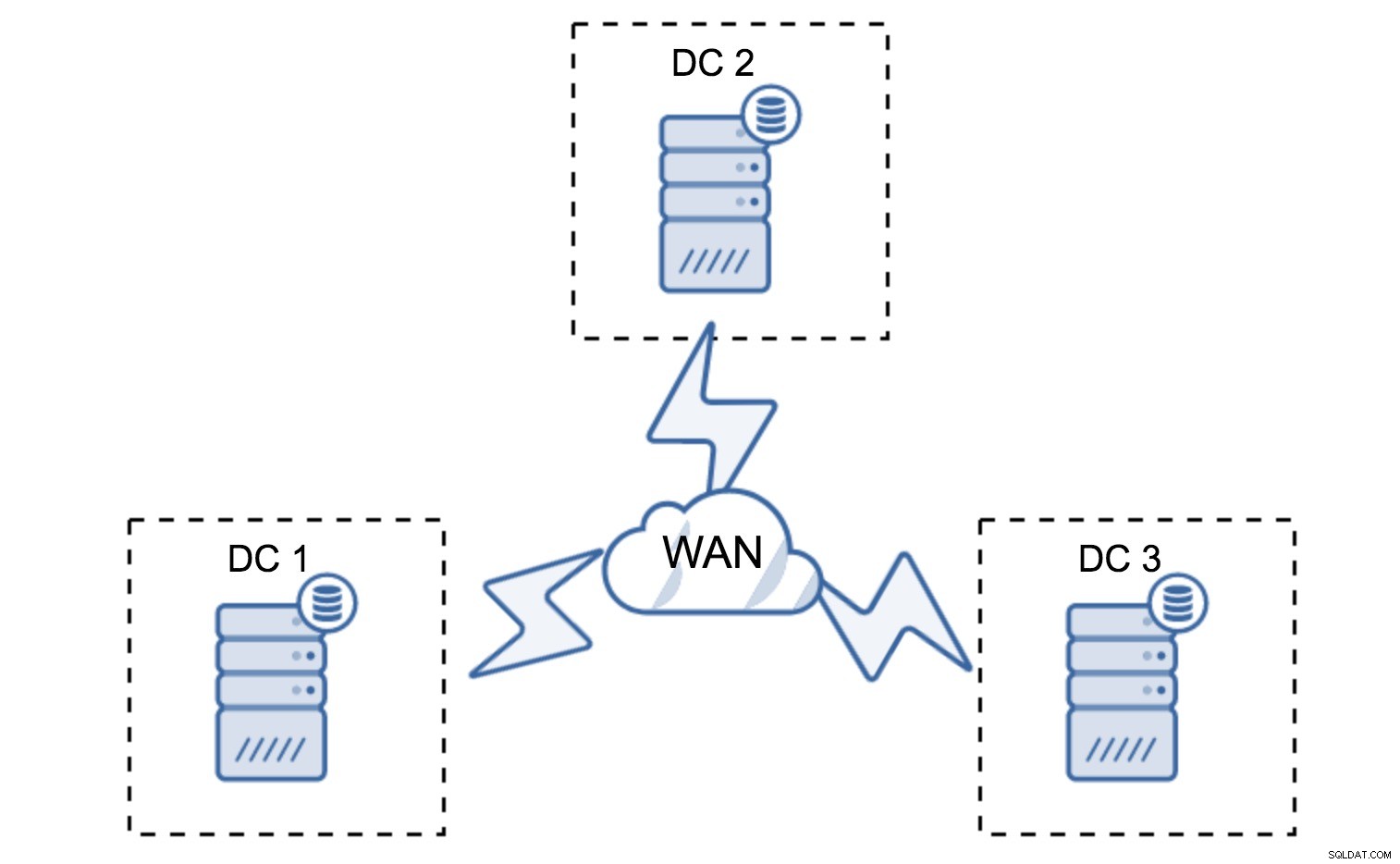
A configuração mínima usará um nó por datacenter - porém, tem sérias desvantagens. Cada transferência de estado exigirá a movimentação de dados pela WAN e isso resultará em mais tempo necessário para concluir o SST ou em custos mais altos.
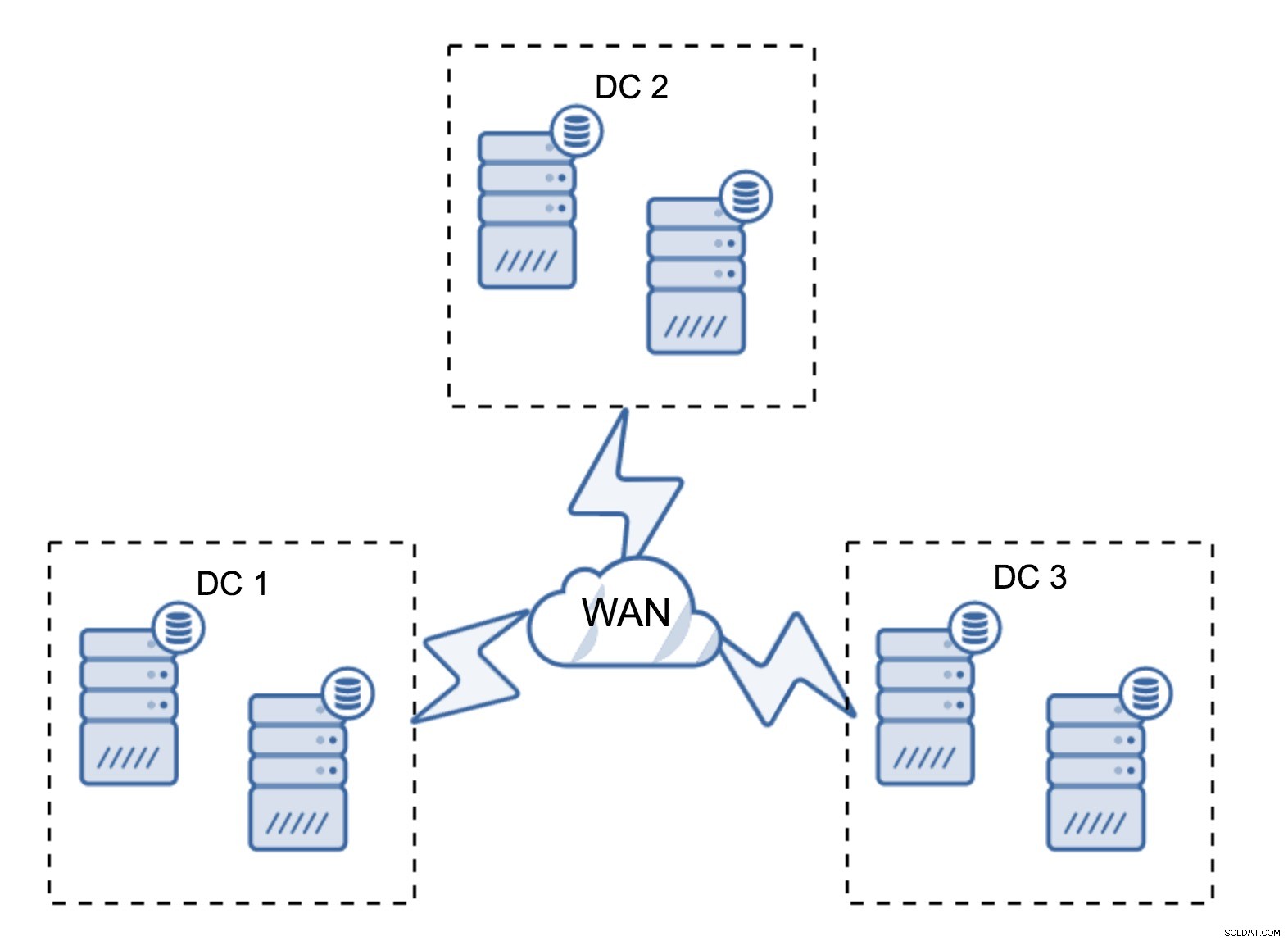
Uma configuração bastante típica é ter seis nós, dois por datacenter. Essa configuração parece inesperada, pois possui um número par de nós. Mas, quando você pensa nisso, pode não ser um problema tão grande:é bastante improvável que três nós caiam ao mesmo tempo, e essa configuração sobreviverá a uma falha de até dois nós. Um datacenter inteiro pode ficar offline e dois DCs restantes continuarão as operações. Ele também tem uma enorme vantagem sobre a configuração mínima - quando um nó fica offline, sempre há um segundo nó no datacenter que pode servir como doador. Na maioria das vezes, a WAN não será usada para SST.
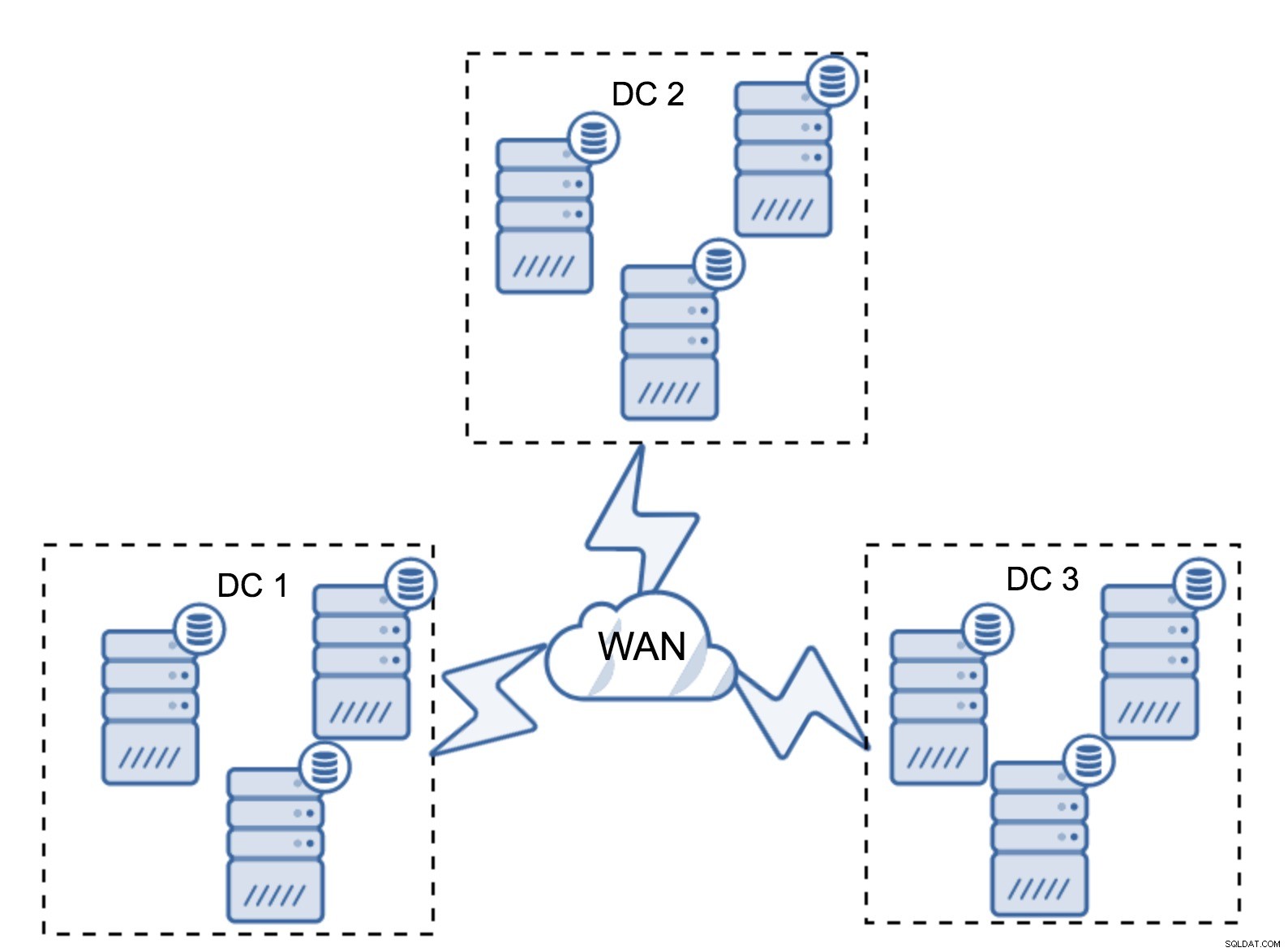
Claro, você pode aumentar o número de nós para três por cluster, nove no total. Isso oferece uma capacidade de sobrevivência ainda melhor:até quatro nós podem falhar e o cluster ainda sobreviverá. Por outro lado, você deve ter em mente que, mesmo com o uso de segmentos, mais nós significa maior sobrecarga de operações e você pode escalar o cluster Galera apenas até certo ponto.
Pode acontecer que não haja necessidade de um terceiro datacenter porque, digamos, sua aplicação está localizada em apenas dois deles. Claro, o requisito de três datacenters ainda é válido, então você não vai contorná-lo, mas não há problema em usar um Galera Arbitrator (garbd) em vez de servidores de banco de dados totalmente carregados.
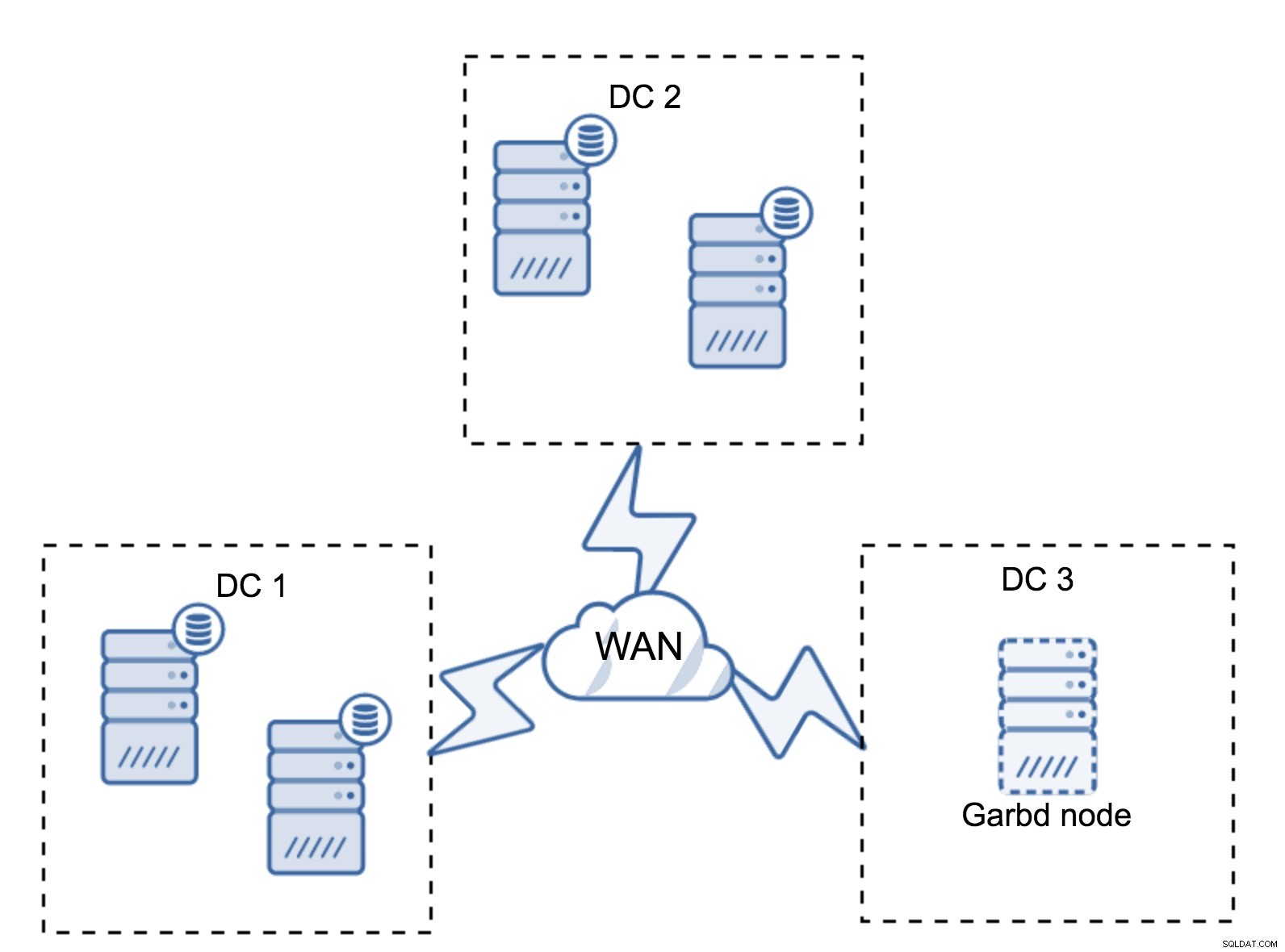
Garbd pode ser instalado em nós menores, até mesmo em servidores virtuais. Não requer hardware poderoso, não armazena dados nem aplica nenhum dos conjuntos de gravação. Mas ele vê todo o tráfego de replicação e participa do cálculo de quorum. Graças a isso, você pode implantar configurações como quatro nós, dois por DC + garbd no terceiro - você tem cinco nós no total e esse cluster pode aceitar até duas falhas. Isso significa que ele pode aceitar o desligamento completo de um dos datacenters.
Qual opção é melhor para você? Não existe a melhor solução para todos os casos, tudo depende dos seus requisitos de infraestrutura. Felizmente, existem diferentes opções para escolher:mais ou menos nós, 3 DC ou 2 DC completos e garbd no terceiro - é bem provável que você encontre algo adequado para você.
Latência da rede
Ao trabalhar com configurações multi-DC, você deve ter em mente que a latência da rede será significativamente maior do que o esperado de um ambiente de rede local. Isso pode reduzir seriamente o desempenho do cluster Galera ao compará-lo com uma instância autônoma do MySQL ou uma configuração de replicação do MySQL. O requisito de que todos os nós tenham que certificar um conjunto de gravação significa que todos os nós precisam recebê-lo, não importa o quão longe estejam. Com a replicação assíncrona, não há necessidade de esperar antes de uma confirmação. É claro que a replicação tem outros problemas e desvantagens, mas a latência não é a principal. O problema é especialmente visível quando seu banco de dados possui pontos de acesso - linhas, que são atualizadas com frequência (contadores, filas, etc). Essas linhas não podem ser atualizadas mais de uma vez por viagem de ida e volta da rede. Para clusters espalhados pelo mundo, isso pode significar facilmente que você não poderá atualizar uma única linha com mais frequência do que 2 a 3 vezes por segundo. Se isso se tornar uma limitação para você, pode significar que o cluster Galera não é adequado para sua carga de trabalho específica.
Camada proxy no cluster Galera Multi-DC
Não basta ter o cluster Galera abrangendo vários datacenters, você ainda precisa do seu aplicativo para acessá-los. Um dos métodos populares para ocultar a complexidade da camada de banco de dados de um aplicativo é utilizar um proxy. Os proxies são usados como um ponto de entrada para os bancos de dados, eles rastreiam o estado dos nós do banco de dados e devem sempre direcionar o tráfego apenas para os nós disponíveis. Nesta seção, tentaremos propor um design de camada proxy que possa ser usado para um cluster multi-DC Galera. Usaremos o ProxySQL, que oferece bastante flexibilidade no manuseio de nós de banco de dados, mas você pode usar outro proxy, desde que possa rastrear o estado dos nós do Galera.
Onde localizar os proxies?
Em resumo, existem dois padrões comuns aqui:você pode implantar o ProxySQL em nós separados ou pode implantá-los nos hosts do aplicativo. Vamos dar uma olhada nos prós e contras de cada uma dessas configurações.
Camada proxy como um conjunto separado de hosts
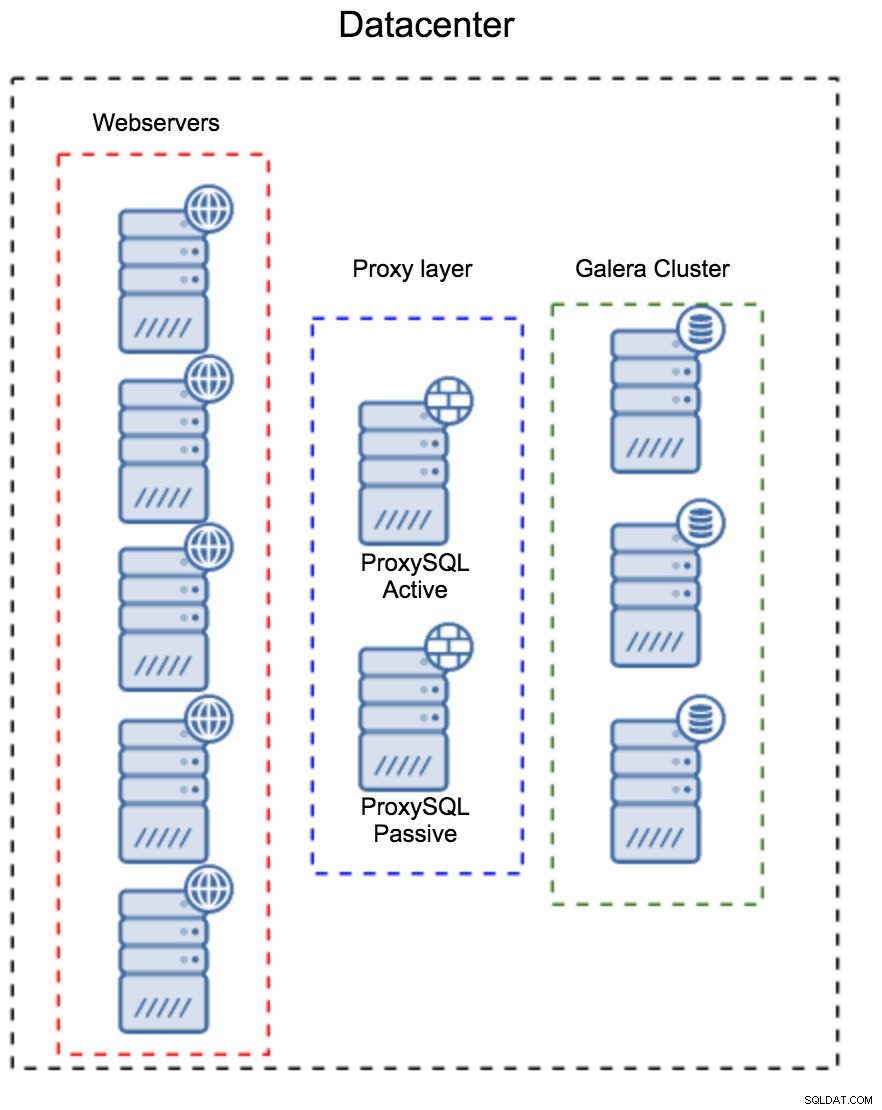
O primeiro padrão é construir uma camada de proxy usando hosts dedicados separados. Você pode implantar o ProxySQL em alguns hosts e usar o IP virtual e keepalived para manter a alta disponibilidade. Um aplicativo usará o VIP para se conectar ao banco de dados e o VIP garantirá que as solicitações sempre sejam roteadas para um ProxySQL disponível. O principal problema com essa configuração é que você usa no máximo uma das instâncias do ProxySQL - todos os nós de espera não são usados para rotear o tráfego. Isso pode forçá-lo a usar um hardware mais poderoso do que você normalmente usa. Por outro lado, é mais fácil manter a configuração - você terá que aplicar as alterações de configuração em todos os nós ProxySQL, mas haverá apenas alguns deles. Você também pode utilizar a opção do ClusterControl para sincronizar os nós. Essa configuração terá que ser duplicada em cada datacenter que você usar.
Proxy instalado em instâncias do aplicativo
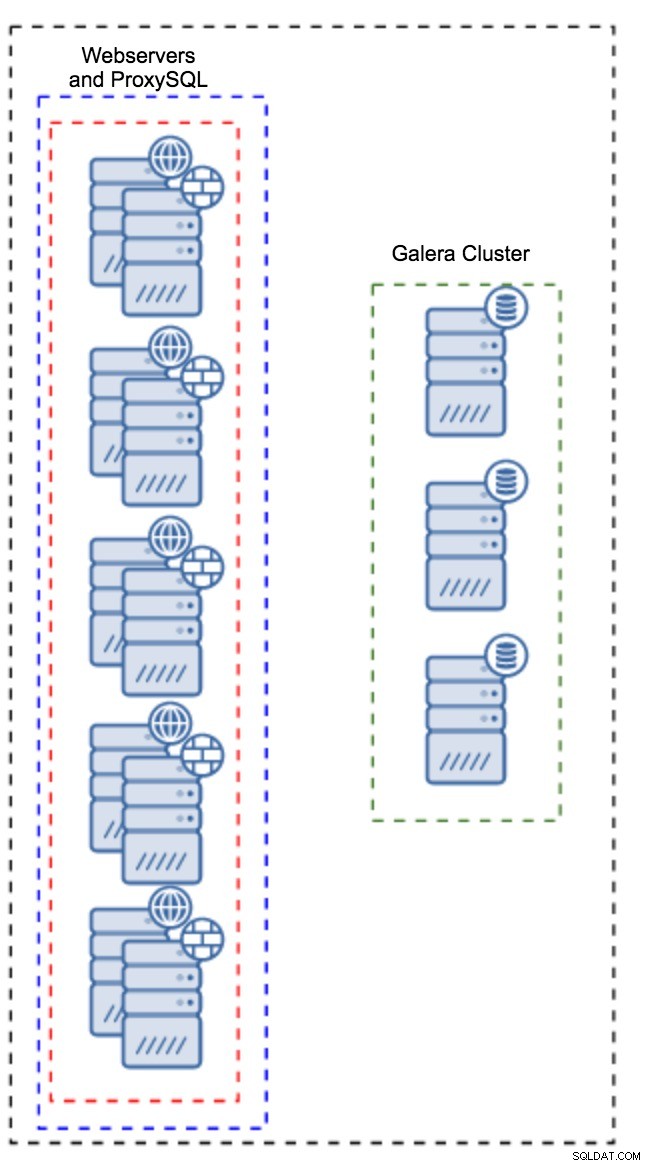
Em vez de ter um conjunto separado de hosts, o ProxySQL também pode ser instalado nos hosts do aplicativo. O aplicativo se conectará diretamente ao ProxySQL no host local, ele pode até usar o soquete unix para minimizar a sobrecarga da conexão TCP. A principal vantagem dessa configuração é que você tem um grande número de instâncias do ProxySQL e a carga é distribuída uniformemente entre elas. Se um ficar inativo, apenas esse host do aplicativo será afetado. Os nós restantes continuarão a funcionar. O problema mais sério a enfrentar é o gerenciamento de configuração. Com um grande número de nós ProxySQL, é crucial criar um método automatizado para manter suas configurações sincronizadas. Você pode usar o ClusterControl ou uma ferramenta de gerenciamento de configuração como o Puppet.
Ajuste do Galera em um ambiente WAN
Os padrões do Galera são projetados para rede local e se você deseja usá-lo em um ambiente WAN, alguns ajustes são necessários. Vamos discutir alguns dos ajustes básicos que você pode fazer. Lembre-se de que o ajuste preciso requer dados de produção e tráfego - você não pode apenas fazer algumas alterações e supor que elas são boas, você deve fazer um benchmarking adequado.
Configuração do sistema operacional
Vamos começar com a configuração do sistema operacional. Nem todas as modificações propostas aqui são relacionadas à WAN, mas é sempre bom lembrar qual é um bom ponto de partida para qualquer instalação do MySQL.
vm.swappiness = 1Swappiness controla o quão agressivo o sistema operacional usará swap. Ele não deve ser definido como zero porque em kernels mais recentes, ele impede que o sistema operacional use swap e pode causar sérios problemas de desempenho.
/sys/block/*/queue/scheduler = deadline/noopO agendador para o dispositivo de bloco, que o MySQL usa, deve ser definido como deadline ou noop. A escolha exata depende dos benchmarks, mas ambas as configurações devem fornecer desempenho semelhante, melhor que o agendador padrão, CFQ.
Para MySQL, você deve considerar o uso de EXT4 ou XFS, dependendo do kernel (o desempenho desses sistemas de arquivos muda de uma versão do kernel para outra). Realize alguns benchmarks para encontrar a melhor opção para você.
Além disso, você pode querer examinar as configurações de rede sysctl. Não vamos discuti-los em detalhes (você pode encontrar a documentação aqui), mas a ideia geral é aumentar os buffers, backlogs e timeouts, para facilitar a acomodação de stalls e links WAN instáveis.
net.core.optmem_max = 40960
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.core.rmem_default = 16777216
net.core.wmem_default = 16777216
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 87380 16777216
net.core.netdev_max_backlog = 50000
net.ipv4.tcp_max_syn_backlog = 30000
net.ipv4.tcp_congestion_control = htcp
net.ipv4.tcp_mtu_probing = 1
net.ipv4.tcp_max_tw_buckets = 2000000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_slow_start_after_idle = 0Além do ajuste do SO, você deve considerar ajustar as configurações relacionadas à rede Galera.
evs.suspect_timeout
evs.inactive_timeoutVocê pode querer considerar alterar os valores padrão dessas variáveis. Ambos os tempos limite controlam como o cluster remove nós com falha. O tempo limite suspeito ocorre quando todos os nós não podem alcançar o membro inativo. O tempo limite inativo define um limite rígido de quanto tempo um nó pode permanecer no cluster se não estiver respondendo. Normalmente, você descobrirá que os valores padrão funcionam bem. Mas em alguns casos, especialmente se você executar seu cluster Galera por WAN (por exemplo, entre regiões da AWS), aumentar essas variáveis pode resultar em um desempenho mais estável. Sugerimos definir ambos como PT1M, para tornar menos provável que a instabilidade do link WAN jogue um nó fora do cluster.
evs.send_window
evs.user_send_windowEssas variáveis, evs.send_window e evs.user_send_window , defina quantos pacotes podem ser enviados via replicação ao mesmo tempo (evs.send_window ) e quantos deles podem conter dados (evs.user_send_window ). Para conexões de alta latência, pode valer a pena aumentar significativamente esses valores (512 ou 1024, por exemplo).
evs.inactive_check_periodA variável acima também pode ser alterada. evs.inactive_check_period , por padrão, é definido como um segundo, o que pode ser muito frequente para uma configuração de WAN. Sugerimos configurá-lo para PT30S.
gcs.fc_factor
gcs.fc_limitAqui, queremos minimizar as chances de que o controle de fluxo seja ativado, portanto, sugerimos definir gcs.fc_factor para 1 e aumente gcs.fc_limit para, por exemplo, 260.
gcs.max_packet_sizeComo estamos trabalhando com o link WAN, onde a latência é significativamente maior, queremos aumentar o tamanho dos pacotes. Um bom ponto de partida seria 2097152.
Como mencionamos anteriormente, é praticamente impossível fornecer uma receita simples sobre como definir esses parâmetros, pois depende de muitos fatores - você terá que fazer seus próprios benchmarks, usando dados o mais próximo possível de seus dados de produção, antes de pode dizer que seu sistema está sintonizado. Dito isto, essas configurações devem fornecer um ponto de partida para o ajuste mais preciso.
É isso por enquanto. Galera funciona muito bem em ambientes WAN, então experimente e conte-nos como você se sai.