Quando você está trabalhando em um projeto que consiste em muitos microsserviços, provavelmente também incluirá vários bancos de dados.
Por exemplo, você pode ter um banco de dados MySQL e um banco de dados PostgreSQL, ambos rodando em servidores separados.
Normalmente, para juntar os dados dos dois bancos de dados, você teria que introduzir um novo microsserviço que juntaria os dados. Mas isso aumentaria a complexidade do sistema.
Neste tutorial, usaremos Materialize para unir MySQL e Postgres em uma visualização materializada ao vivo. Assim, poderemos consultar isso diretamente e obter resultados de ambos os bancos de dados em tempo real usando SQL padrão.
Materialize é um banco de dados de streaming disponível na origem escrito em Rust que mantém os resultados de uma consulta SQL (uma exibição materializada) na memória à medida que os dados mudam.
O tutorial inclui um projeto de demonstração que você pode começar usando
docker-compose . O projeto de demonstração que usaremos monitorará os pedidos em nosso site simulado. Gerará eventos que poderão, posteriormente, ser usados para enviar notificações quando um carrinho for abandonado por muito tempo.
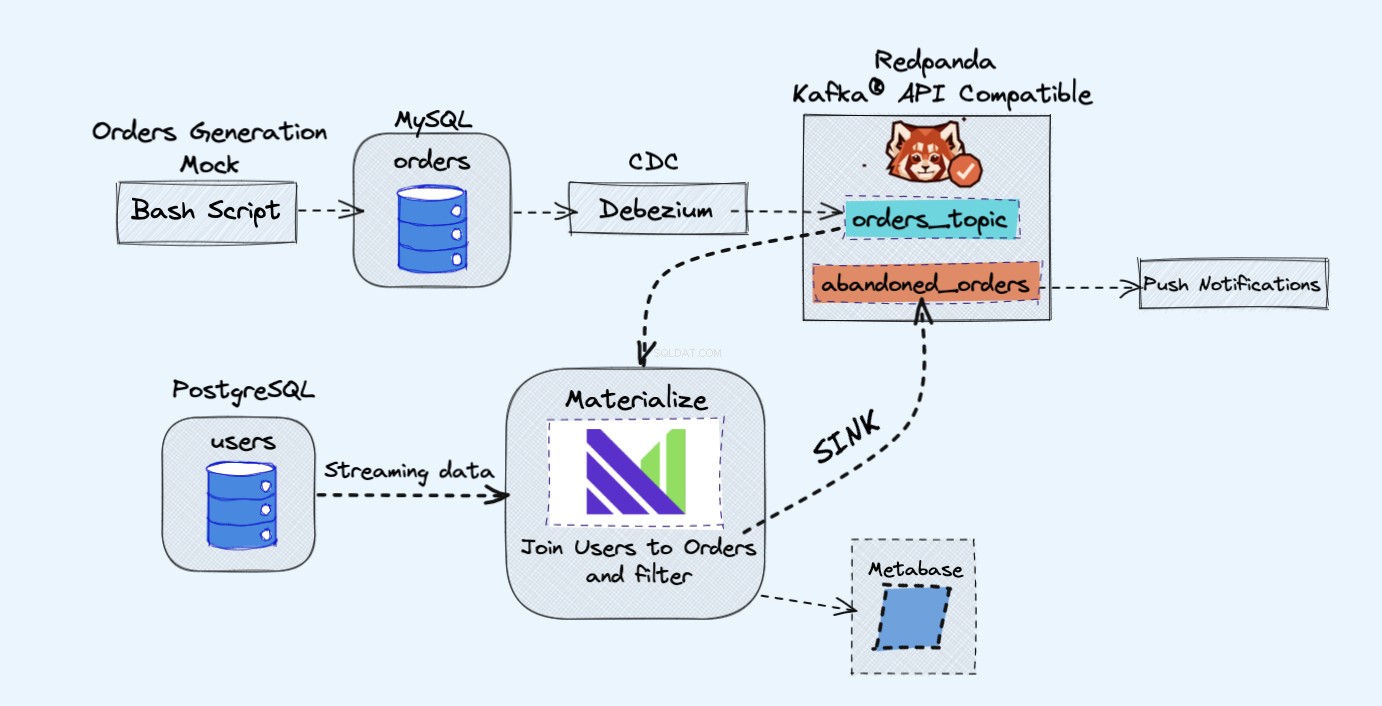
A arquitetura do projeto de demonstração é a seguinte:
Pré-requisitos
Todos os serviços que usaremos na demonstração serão executados dentro de contêineres do Docker, dessa forma você não precisará instalar nenhum serviço adicional em seu laptop ou servidor em vez do Docker e do Docker Compose.
Caso você não tenha o Docker e o Docker Compose já instalados, você pode seguir as instruções oficiais de como fazer isso aqui:
- Instalar o Docker
- Instalar o Docker Compose
Visão geral
Conforme mostrado no diagrama acima, teremos os seguintes componentes:
- Um serviço simulado para gerar pedidos continuamente.
- Os pedidos serão armazenados em um banco de dados MySQL .
- À medida que as gravações do banco de dados ocorrem, o Debezium transmite as alterações do MySQL para um Redpanda tópico.
- Teremos também um Postgres banco de dados onde podemos obter nossos usuários.
- Incluiremos este tópico Redpanda em Materialize diretamente junto com os usuários do banco de dados Postgres.
- No Materialize, juntaremos nossos pedidos e usuários, faremos algumas filtragens e criaremos uma visualização materializada que mostra as informações do carrinho abandonado.
- Em seguida, criaremos um coletor para enviar os dados do carrinho abandonado para um novo tópico do Redpanda.
- No final, usaremos a Metabase para visualizar os dados.
- Você pode, mais tarde, usar as informações desse novo tópico para enviar notificações aos seus usuários e lembrá-los de que eles têm um carrinho abandonado.
Como uma nota lateral aqui, você estaria perfeitamente bem usando Kafka em vez de Redpanda. Eu gosto da simplicidade que o Redpanda traz para a mesa, pois você pode executar uma única instância do Redpanda em vez de todos os componentes do Kafka.
Como executar a demonstração
Primeiro, comece clonando o repositório:
git clone https://github.com/bobbyiliev/materialize-tutorials.git
Depois disso, você pode acessar o diretório:
cd materialize-tutorials/mz-join-mysql-and-postgresql
Vamos começar executando primeiro o contêiner Redpanda:
docker-compose up -d redpanda
Construa as imagens:
docker-compose build
Por fim, inicie todos os serviços:
docker-compose up -d
Para iniciar a CLI do Materialize, você pode executar o seguinte comando:
docker-compose run mzcli
Este é apenas um atalho para um contêiner do Docker com
postgres-client pré-instalado. Se você já tem o psql você pode executar psql -U materialize -h localhost -p 6875 materialize em vez de. Como criar uma fonte Kafka Materialize
Agora que você está na CLI do Materialize, vamos definir os
orders tabelas no mysql.shop banco de dados como fontes do Redpanda:CREATE SOURCE orders
FROM KAFKA BROKER 'redpanda:9092' TOPIC 'mysql.shop.orders'
FORMAT AVRO USING CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081'
ENVELOPE DEBEZIUM;
Se você verificar as colunas disponíveis dos
orders source executando a seguinte instrução:SHOW COLUMNS FROM orders;
Você poderá ver que, como o Materialize está extraindo os dados do esquema de mensagem do registro Redpanda, ele conhece os tipos de coluna a serem usados para cada atributo:
name | nullable | type
--------------+----------+-----------
id | f | bigint
user_id | t | bigint
order_status | t | integer
price | t | numeric
created_at | f | text
updated_at | t | timestamp
Como criar visualizações materializadas
Em seguida, criaremos nossa primeira Visualização Materializada, para obter todos os dados dos
orders Fonte Redpanda:CREATE MATERIALIZED VIEW orders_view AS
SELECT * FROM orders;
CREATE MATERIALIZED VIEW abandoned_orders AS
SELECT
user_id,
order_status,
SUM(price) as revenue,
COUNT(id) AS total
FROM orders_view
WHERE order_status=0
GROUP BY 1,2;
Agora você pode usar
SELECT * FROM abandoned_orders; para ver os resultados:SELECT * FROM abandoned_orders;
Para obter mais informações sobre como criar visualizações materializadas, confira a seção Visualizações materializadas da documentação Materialize.
Como criar uma fonte Postgres
Existem duas maneiras de criar uma fonte Postgres no Materialize:
- Usando o Debezium como fizemos com a fonte MySQL.
- Usando o Postgres Materialize Source, que permite conectar o Materialize diretamente ao Postgres para que você não precise usar o Debezium.
Para esta demonstração, usaremos o Postgres Materialize Source apenas como uma demonstração de como usá-lo, mas fique à vontade para usar o Debezium.
Para criar um Postgres Materialize Source execute a seguinte instrução:
CREATE MATERIALIZED SOURCE "mz_source" FROM POSTGRES
CONNECTION 'user=postgres port=5432 host=postgres dbname=postgres password=postgres'
PUBLICATION 'mz_source';
Um resumo rápido da afirmação acima:
MATERIALIZED:Materializa os dados da fonte PostgreSQL. Todos os dados são retidos na memória e tornam as fontes diretamente selecionáveis.mz_source:o nome da fonte PostgreSQL.CONNECTION:os parâmetros de conexão do PostgreSQL.PUBLICATION:A publicação do PostgreSQL, contendo as tabelas a serem transmitidas para o Materialize.
Uma vez que criamos a fonte do PostgreSQL, para podermos consultar as tabelas do PostgreSQL, precisaríamos criar views que representassem as tabelas originais da publicação upstream.
No nosso caso, temos apenas uma tabela chamada
users então a declaração que precisaríamos executar é:CREATE VIEWS FROM SOURCE mz_source (users);
Para ver as visualizações disponíveis, execute a seguinte instrução:
SHOW FULL VIEWS;
Feito isso, você pode consultar as novas visualizações diretamente:
SELECT * FROM users;
Em seguida, vamos em frente e criar mais algumas visualizações.
Como criar uma pia Kafka
Os coletores permitem que você envie dados do Materialize para uma fonte externa.
Para esta demonstração, usaremos o Redpanda.
O Redpanda é compatível com a API Kafka e o Materialize pode processar dados dele da mesma forma que processaria dados de uma fonte Kafka.
Vamos criar uma visualização materializada, que conterá todos os pedidos não pagos de alto volume:
CREATE MATERIALIZED VIEW high_value_orders AS
SELECT
users.id,
users.email,
abandoned_orders.revenue,
abandoned_orders.total
FROM users
JOIN abandoned_orders ON abandoned_orders.user_id = users.id
GROUP BY 1,2,3,4
HAVING revenue > 2000;
Como você pode ver, aqui estamos nos juntando aos
users view que está ingerindo os dados diretamente de nossa fonte Postgres e o abandond_orders view que está ingerindo os dados do tópico Redpanda, juntos. Vamos criar um Sink onde enviaremos os dados da view materializada acima:
CREATE SINK high_value_orders_sink
FROM high_value_orders
INTO KAFKA BROKER 'redpanda:9092' TOPIC 'high-value-orders-sink'
FORMAT AVRO USING
CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081';
Agora, se você se conectar ao contêiner Redpanda e usar o
rpk topic consume comando, você poderá ler os registros do tópico. No entanto, por enquanto, não poderemos visualizar os resultados com
rpk porque é formatado em AVRO. O Redpanda provavelmente implementaria isso no futuro, mas, no momento, podemos transmitir o tópico de volta ao Materialize para confirmar o formato. Primeiro, obtenha o nome do tópico que foi gerado automaticamente:
SELECT topic FROM mz_kafka_sinks;
Saída:
topic
-----------------------------------------------------------------
high-volume-orders-sink-u12-1637586945-13670686352905873426
Para obter mais informações sobre como os nomes dos tópicos são gerados, confira a documentação aqui.
Em seguida, crie uma nova Fonte Materializada a partir deste tópico Redpanda:
CREATE MATERIALIZED SOURCE high_volume_orders_test
FROM KAFKA BROKER 'redpanda:9092' TOPIC ' high-volume-orders-sink-u12-1637586945-13670686352905873426'
FORMAT AVRO USING CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081';
Certifique-se de alterar o nome do tópico de acordo!
Por fim, consulte esta nova visão materializada:
SELECT * FROM high_volume_orders_test LIMIT 2;
Agora que você tem os dados no tópico, pode fazer com que outros serviços se conectem a eles e os consumam e acionem emails ou alertas, por exemplo.
Como conectar a metabase
Para acessar a instância Metabase, visite
https://localhost:3030 se você estiver executando a demonstração localmente ou https://your_server_ip:3030 se você estiver executando a demonstração em um servidor. Em seguida, siga as etapas para concluir a configuração da Metabase. Certifique-se de selecionar Materialize como a fonte dos dados.
Uma vez pronto, você poderá visualizar seus dados como faria com um banco de dados PostgreSQL padrão.
Como interromper a demonstração
Para interromper todos os serviços, execute o seguinte comando:
docker-compose down
Conclusão
Como você pode ver, este é um exemplo muito simples de como usar o Materialize. Você pode usar o Materialize para ingerir dados de várias fontes e depois transmiti-los para vários destinos.
Recursos úteis:
CREATE SOURCE: PostgreSQLCREATE SOURCECREATE VIEWSSELECT