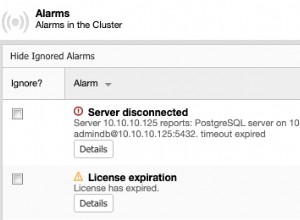
Não é possivel? Desafio aceito. :)
WITH x(employee, department) AS (
VALUES
(1::int, 2::int)
,(3, 4)
,(5, 6)
-- ... more combinations
)
SELECT x.employee, x.department, count(i.employee) AS ct
FROM x
LEFT JOIN items i ON i.employee = x.employee
AND i.department = x.department
AND i.available
GROUP BY x.employee, x.department;
Isso lhe dará exatamente o que você está pedindo. Se
employee e department não são inteiros, convertidos para o tipo correspondente. Por comentário de @ypercube:count() precisa estar em uma coluna não nula de
items , então obtemos 0 para critérios inexistentes, não 1 . Além disso, puxe critérios adicionais para o
LEFT JOIN condição (i.available neste caso), para não excluir critérios inexistentes. Desempenho
Respondendo a pergunta adicional no comentário.
Isso deve funcionar muito bem. Com listas de critérios mais longas,
(LEFT) JOIN é provavelmente o método mais rápido. Se você precisar dele o mais rápido possível, certifique-se de criar uma multicolumn índice Curti:
CREATE INDEX items_some_name_idx ON items (employee, department);
Se
(employee, department) deve ser a PRIMARY KEY ou você deve ter um UNIQUE restrição nas duas colunas, isso também funcionaria.