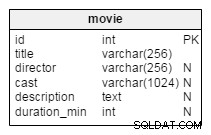
Quando você adiciona um
order by para um agregado usado como uma função de janela, esse agregado se transforma em uma "contagem em execução" (ou qualquer agregado que você use). A
count(*) retornará o número de linhas até a "atual" com base na ordem especificada. A consulta a seguir mostra os diferentes resultados para agregados usados com um
order by . Com sum() em vez de count() é um pouco mais fácil de ver (na minha opinião). with test (id, num, x) as (
values
(1, 4, 1),
(2, 4, 1),
(3, 5, 2),
(4, 6, 2)
)
select id,
num,
x,
count(*) over () as total_rows,
count(*) over (order by id) as rows_upto,
count(*) over (partition by x order by id) as rows_per_x,
sum(num) over (partition by x) as total_for_x,
sum(num) over (order by id) as sum_upto,
sum(num) over (partition by x order by id) as sum_for_x_upto
from test;
vai resultar em:
id | num | x | total_rows | rows_upto | rows_per_x | total_for_x | sum_upto | sum_for_x_upto
---+-----+---+------------+-----------+------------+-------------+----------+---------------
1 | 4 | 1 | 4 | 1 | 1 | 8 | 4 | 4
2 | 4 | 1 | 4 | 2 | 2 | 8 | 8 | 8
3 | 5 | 2 | 4 | 3 | 1 | 11 | 13 | 5
4 | 6 | 2 | 4 | 4 | 2 | 11 | 19 | 11
Há mais exemplos no manual Postgres