Tive o prazer de participar do PGDay UK na semana passada – um evento muito legal, espero ter a chance de voltar no próximo ano. Houve muitas palestras interessantes, mas a que mais me chamou a atenção foi a Performace para consultas com agrupamento de Alexey Bashtanov.
Já dei um bom número de palestras semelhantes orientadas para o desempenho no passado, então sei como é difícil apresentar resultados de benchmark de maneira compreensível e interessante, e Alexey fez um bom trabalho, eu acho. Portanto, se você lida com agregação de dados (ou seja, BI, análise ou cargas de trabalho semelhantes), recomendo passar pelos slides e, se tiver a chance de participar da palestra em alguma outra conferência, recomendo fazê-lo.
Mas há um ponto em que discordo da conversa, no entanto. Em vários lugares, a palestra sugeriu que você geralmente deveria preferir HashAggregate, porque as ordenações são lentas.
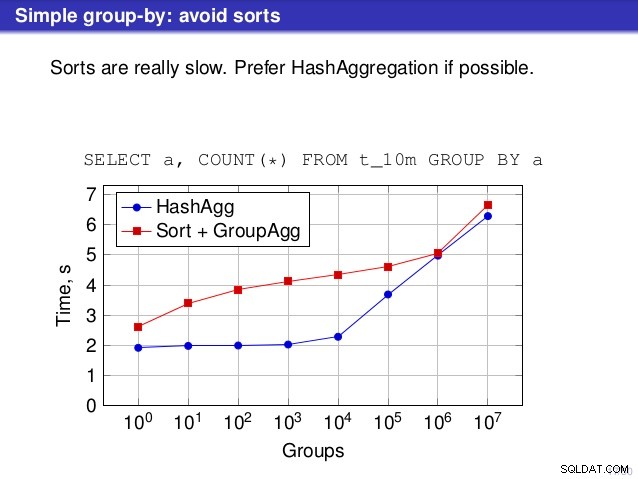
Eu considero isso um pouco enganoso, porque uma alternativa ao HashAggregate é GroupAggregate, não Sort. Portanto, a recomendação pressupõe que cada GroupAggregate tenha uma classificação aninhada, mas isso não é bem verdade. GroupAggregate requer entrada classificada, e uma classificação explícita não é a única maneira de fazer isso - também temos nós IndexScan e IndexOnlyScan, que eliminam os custos de classificação e mantêm os outros benefícios associados aos caminhos classificados (especialmente IndexOnlyScan).
Deixe-me demonstrar como (IndexOnlyScan+GroupAggregate) funciona em comparação com HashAggregate e (Sort+GroupAggregate) – o script que usei para as medições está aqui. Ele constrói quatro tabelas simples, cada uma com 100 milhões de linhas e um número diferente de grupos na coluna “branch_id” (determinando o tamanho da tabela de hash). O menor tem 10k grupos
-- table with 10k groups create table t_10000 (branch_id bigint, amount numeric); insert into t_10000 select mod(i, 10000), random() from generate_series(1,100000000) s(i);
e três mesas adicionais têm grupos de 100k, 1M e 5M. Vamos executar esta consulta simples agregando os dados:
SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1
e então convença o banco de dados a usar três planos diferentes:
1) HashAggregate
SET enable_sort = off;
SET enable_hashagg = on;
EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1;
QUERY PLAN
----------------------------------------------------------------------------
HashAggregate (cost=2136943.00..2137067.99 rows=9999 width=40)
Group Key: branch_id
-> Seq Scan on t_10000 (cost=0.00..1636943.00 rows=100000000 width=19)
(3 rows) 2) GroupAggregate (com uma classificação)
SET enable_sort = on;
SET enable_hashagg = off;
EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1;
QUERY PLAN
-------------------------------------------------------------------------------
GroupAggregate (cost=16975438.38..17725563.37 rows=9999 width=40)
Group Key: branch_id
-> Sort (cost=16975438.38..17225438.38 rows=100000000 width=19)
Sort Key: branch_id
-> Seq Scan on t_10000 (cost=0.00..1636943.00 rows=100000000 ...)
(5 rows) 3) GroupAggregate (com um IndexOnlyScan)
SET enable_sort = on;
SET enable_hashagg = off;
CREATE INDEX ON t_10000 (branch_id, amount);
EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1;
QUERY PLAN
--------------------------------------------------------------------------
GroupAggregate (cost=0.57..3983129.56 rows=9999 width=40)
Group Key: branch_id
-> Index Only Scan using t_10000_branch_id_amount_idx on t_10000
(cost=0.57..3483004.57 rows=100000000 width=19)
(3 rows) Resultados
Depois de medir os tempos para cada plano em todas as tabelas, os resultados ficam assim:
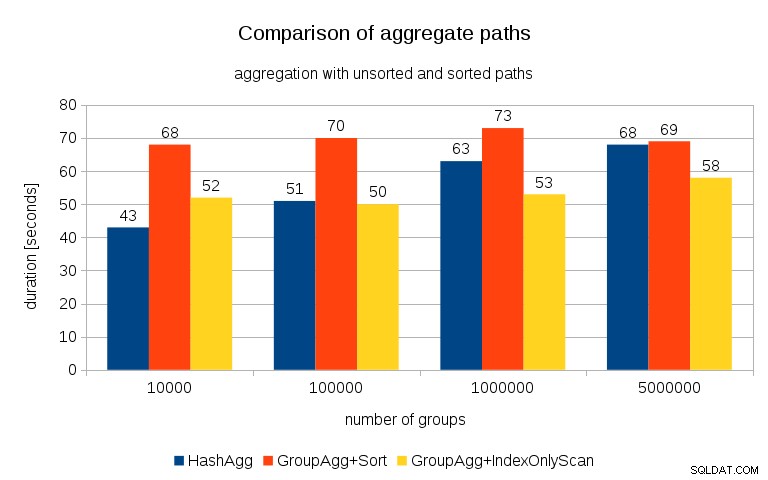
Para tabelas de hash pequenas (que cabem no cache L3, que é de 16 MB neste caso), o caminho HashAggregate é claramente mais rápido do que os dois caminhos classificados. Mas logo o GroupAgg+IndexOnlyScan fica tão rápido ou ainda mais rápido – isso se deve à eficiência do cache, a principal vantagem do GroupAggregate. Enquanto HashAggregate precisa manter toda a tabela de hash na memória de uma só vez, GroupAggregate precisa apenas manter o último grupo. E quanto menos memória você usa, maior a probabilidade de encaixar isso no cache L3, que é aproximadamente uma ordem de magnitude mais rápido em comparação com a RAM normal (para os caches L1/L2, a diferença é ainda maior).
Portanto, embora haja uma sobrecarga considerável associada ao IndexOnlyScan (para o caso de 10k, é cerca de 20% mais lento que o caminho HashAggregate), à medida que a tabela de hash cresce, a taxa de acertos do cache L3 cai rapidamente e a diferença eventualmente torna o GroupAggregate mais rápido. E, eventualmente, até o GroupAggregate+Sort fica no mesmo nível do caminho HashAggregate.
Você pode argumentar que seus dados geralmente têm um número bastante baixo de grupos e, portanto, a tabela de hash sempre caberá no cache L3. Mas considere que o cache L3 é compartilhado por todos os processos em execução na CPU e também por todas as partes do plano de consulta. Portanto, embora atualmente tenhamos ~ 20 MB de cache L3 por soquete, sua consulta receberá apenas uma parte disso, e esse bit será compartilhado por todos os nós em sua consulta (possivelmente bastante complexa).
Atualização de 26/07/2016 :Como apontado nos comentários de Peter Geoghegan, a forma como os dados foram gerados provavelmente resulta em correlação – não os valores (ou melhor, hashes dos valores), mas alocações de memória. Repeti as consultas com dados devidamente randomizados, ou seja, fazendo
insert into t_10000 select (10000*random())::bigint, random() from generate_series(1,100000000) s(i);
ao invés de
insert into t_10000 select mod(i, 10000), random() from generate_series(1,100000000) s(i);
e os resultados ficam assim:
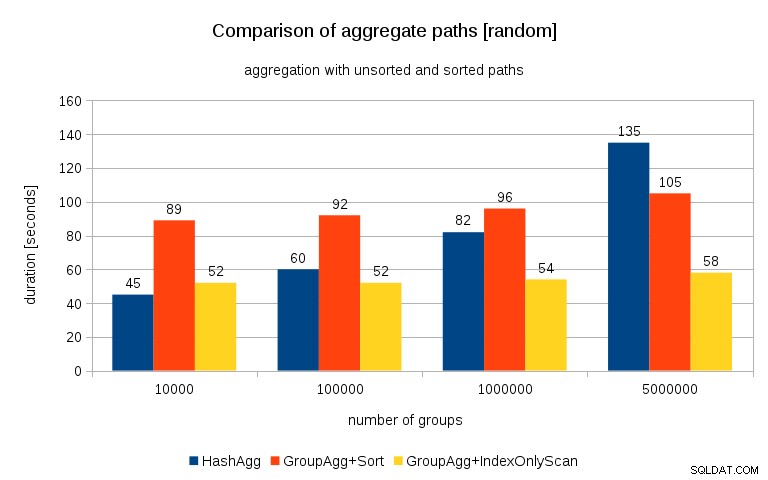
Comparando isso com o gráfico anterior, acho bem claro que os resultados são ainda mais a favor dos caminhos classificados, principalmente para o conjunto de dados com grupos de 5 milhões. O conjunto de dados de 5 milhões também mostra que GroupAgg com uma classificação explícita pode ser mais rápido que HashAgg.
Resumo
Embora HashAggregate seja provavelmente mais rápido que GroupAggregate com um Sort explícito (estou hesitante em dizer que é sempre o caso), usar GroupAggregate com IndexOnlyScan mais rápido pode facilmente torná-lo muito mais rápido que HashAggregate.
Claro, você não pode escolher o plano exato diretamente – o planejador deve fazer isso por você. Mas você afeta o processo de seleção (a) criando índices e (b) configurando
work_mem . É por isso que às vezes diminui work_mem (e maintenance_work_mem ) resultam em melhor desempenho. No entanto, índices adicionais não são gratuitos – eles custam tempo de CPU (ao inserir novos dados) e espaço em disco. Para IndexOnlyScans, os requisitos de espaço em disco podem ser bastante significativos porque o índice precisa incluir todas as colunas referenciadas pela consulta, e o IndexScan regular não forneceria o mesmo desempenho, pois gera muitas E/S aleatórias na tabela (eliminando todas as os ganhos potenciais).
Outro recurso interessante é a estabilidade do desempenho - observe como os tempos do HashAggregate mudam dependendo do número de grupos, enquanto os caminhos do GroupAggregate têm o mesmo desempenho.